Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Kümelerde büyük veri kümelerinin dağıtılmış işlenmesi ve analizine yönelik ilk açık kaynak çerçeve Apache Hadoop’tu. Hadoop ekosistemi Apache Hive, Apache HBase, Spark, Kafka ve diğerleri dahil olmak üzere ilgili yazılım ve yardımcı programları içerir.
Azure HDInsight, kuruluşlar için bulutta tam olarak yönetilen, tam spektrumlu bir açık kaynak analiz hizmetidir. Azure HDInsight'taki Apache Hadoop küme türü, toplu verileri paralel olarak işlemek ve çözümlemek için Apache Hadoop Dağıtılmış Dosya Sistemi 'ni (HDFS), Apache Hadoop YARN kaynak yönetimini ve basit bir MapReduce programlama modelini kullanmanıza olanak tanır. HDInsight'taki Hadoop kümeleri Azure Data Lake Storage 2. Nesil ile uyumludur.
HDInsight üzerindeki kullanılabilir Hadoop teknolojisi yığını bileşenlerini görmek için, bkz. HDInsight ile sağlanan bileşenler ve sürümler. HDInsight'ta Hadoop hakkında daha fazla bilgi edinmek için bkz. HDInsight için Azure özellikleri sayfası.
MapReduce nedir?
Apache Hadoop MapReduce , çok büyük miktarlarda veri işleyen işler yazmaya yönelik bir yazılım çerçevesidir. Giriş verileri bağımsız öbeklere ayrılır. Her öbek, kümenizdeki düğümler arasında paralel olarak işlenir. MapReduce işi iki işlevden oluşur:
Eşleyici: Giriş verilerini tüketir, analiz eder (genellikle filtreleme ve sıralama işlemleriyle) ve tupler (anahtar-değer çiftleri) üretir
Azaltıcı: Eşleyici tarafından yayılan demetleri tüketir ve Eşleyici verilerinden daha küçük, birleşik bir sonuç oluşturan bir özet işlemi gerçekleştirir
Aşağıdaki diyagramda, temel bir sözcük sayımı için MapReduce işine dair bir örnek gösterilmiştir.
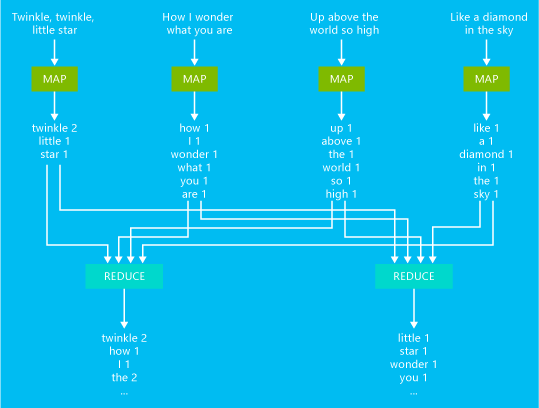
Bu işin çıktısı, metinde her sözcüğün kaç kez oluştuğunun bir sayısıdır.
- Eşleyici giriş metnindeki her satırı giriş olarak alır ve sözcüklere ayırır. Bir sözcük ortaya çıktığında ve ardından 1 ile geldiğinde bir anahtar/değer çifti üretir. Çıkış, azaltıcıya gönderilmeden önce sıralanır.
- Azaltıcı işlev, her sözcük için bu tek tek sayıları toplar ve sözcüğü ve onun oluşumlarının toplamını içeren tek bir anahtar/değer çifti yayar.
MapReduce çeşitli dillerde uygulanabilir. Java en yaygın uygulamadır ve bu belgede tanıtım amacıyla kullanılır.
Geliştirme dilleri
Java ve Java Sanal Makinesi'ni temel alan diller veya çerçeveler doğrudan bir MapReduce işi olarak çalıştırılabilir. Bu belgede kullanılan örnek bir Java MapReduce uygulamasıdır. C#, Python veya tek başına yürütülebilir dosyalar gibi Java dışı diller Hadoop akışını kullanmalıdır.
Hadoop akışı, STDIN ve STDOUT üzerinden eşleyici ve azaltıcı ile iletişim kurar. Eşleyici ve azaltıcı STDIN'den bir kerede bir satır okur ve çıkışı STDOUT'a yazar. Eşleyici ve azaltıcı tarafından okunan veya yayılan her satır, sekme karakteriyle ayrılmış bir anahtar/değer çifti biçiminde olmalıdır:
[key]\t[value]
Daha fazla bilgi için Hadoop Akış sayfasına bakın.
HDInsight ile Hadoop akışı kullanma örnekleri için aşağıdaki belgeye bakın:
Nereden başlarım?
- Hızlı Başlangıç: Azure portalını kullanarak Azure HDInsight'ta Apache Hadoop kümesi oluşturma
- Öğretici: HDInsight'ta Apache Hadoop işleri gönderme
- HDInsight üzerinde Apache Hadoop için Java MapReduce programları geliştirme
- Apache Hive'ı Ayıklama, Dönüştürme ve Yükleme (ETL) aracı olarak kullanma
- Büyük ölçekte ayıklama, dönüştürme ve yükleme (ETL)
- Veri analizi işlem hattını kullanıma hazır hale getirme