Azure HDInsight iş sürekliliği mimarileri
Bu makalede, Azure HDInsight için göz önünde bulundurabileceğiniz iş sürekliliği mimarilerine birkaç örnek verilmiştir. Olağanüstü durum sırasında azaltılmış işlevselliğe dayanıklılık, bir uygulamadan diğerine değişen bir iş kararıdır. Bazı uygulamaların kullanım dışı olması veya belirli bir süre boyunca sınırlı işlevsellik veya gecikmeli işleme ile kısmen kullanılabilir olması kabul edilebilir. Diğer uygulamalar için azaltılmış işlevler kabul edilemez olabilir.
Not
Bu makalede sunulan mimariler hiçbir şekilde kapsamlı değildir. Beklenen iş sürekliliği, operasyonel karmaşıklık ve sahip olma maliyetiyle ilgili hedef belirlemeler yaptıktan sonra kendi benzersiz mimarilerinizi tasarlamanız gerekir.
Apache Hive ve Etkileşimli Sorgu
HDInsight Hive ve Etkileşimli sorgu kümelerinde iş sürekliliği için Hive Çoğaltma V2 önerilir. Tek başına Hive kümesinin çoğaltılması gereken kalıcı bölümleri, Depolama Katmanı ve Hive meta veri deposu'dur. Kurumsal Güvenlik Paketi ile çok kullanıcılı bir senaryoda hive kümeleri için Microsoft Entra Domain Services ve Ranger Meta veri deposu gerekir.
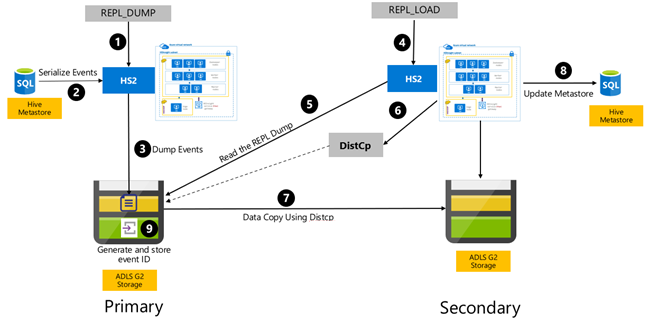
Hive olay tabanlı çoğaltma, birincil ve ikincil kümeler arasında yapılandırılır. Bu iki ayrı aşamadan oluşur: önyükleme ve artımlı çalıştırmalar:
Bootstrapping, Birincilden ikincilye Hive meta veri deposu bilgileri de dahil olmak üzere hive ambarın tamamını çoğaltır.
Artımlı çalıştırmalar birincil kümede otomatik hale gelir ve artımlı çalıştırmalar sırasında oluşturulan olaylar ikincil kümede yeniden oynatılır. İkincil küme, birincil kümeden oluşturulan olayları yakalar ve ikincil kümenin çoğaltma çalıştırmasından sonra birincil kümenin olaylarıyla tutarlı olmasını sağlar.
İkincil küme yalnızca dağıtılmış kopyayı çalıştırmak için çoğaltma sırasında gereklidir, DistCpancak depolama ve meta veri depolarının kalıcı olması gerekir. Çoğaltmadan önce isteğe bağlı olarak betikli ikincil kümeyi çalıştırmayı, çoğaltma betiğini çalıştırmayı ve başarılı çoğaltmadan sonra bu kümeyi yıkmayı seçebilirsiniz.
İkincil küme genellikle salt okunurdur. İkincil kümeyi okuma-yazma yapabilirsiniz, ancak bu, değişiklikleri ikincil kümeden birincil kümeye çoğaltmayı içeren ek karmaşıklık ekler.
Hive olay tabanlı çoğaltma RPO & RTO
RPO: Veri kaybı, birincilden ikincilye son başarılı artımlı çoğaltma olayıyla sınırlıdır.
RTO: Hata ile ikincil ile yukarı ve aşağı akış işlemlerinin sürdürülmesi arasındaki süre.
Apache Hive ve Etkileşimli Sorgu mimarileri
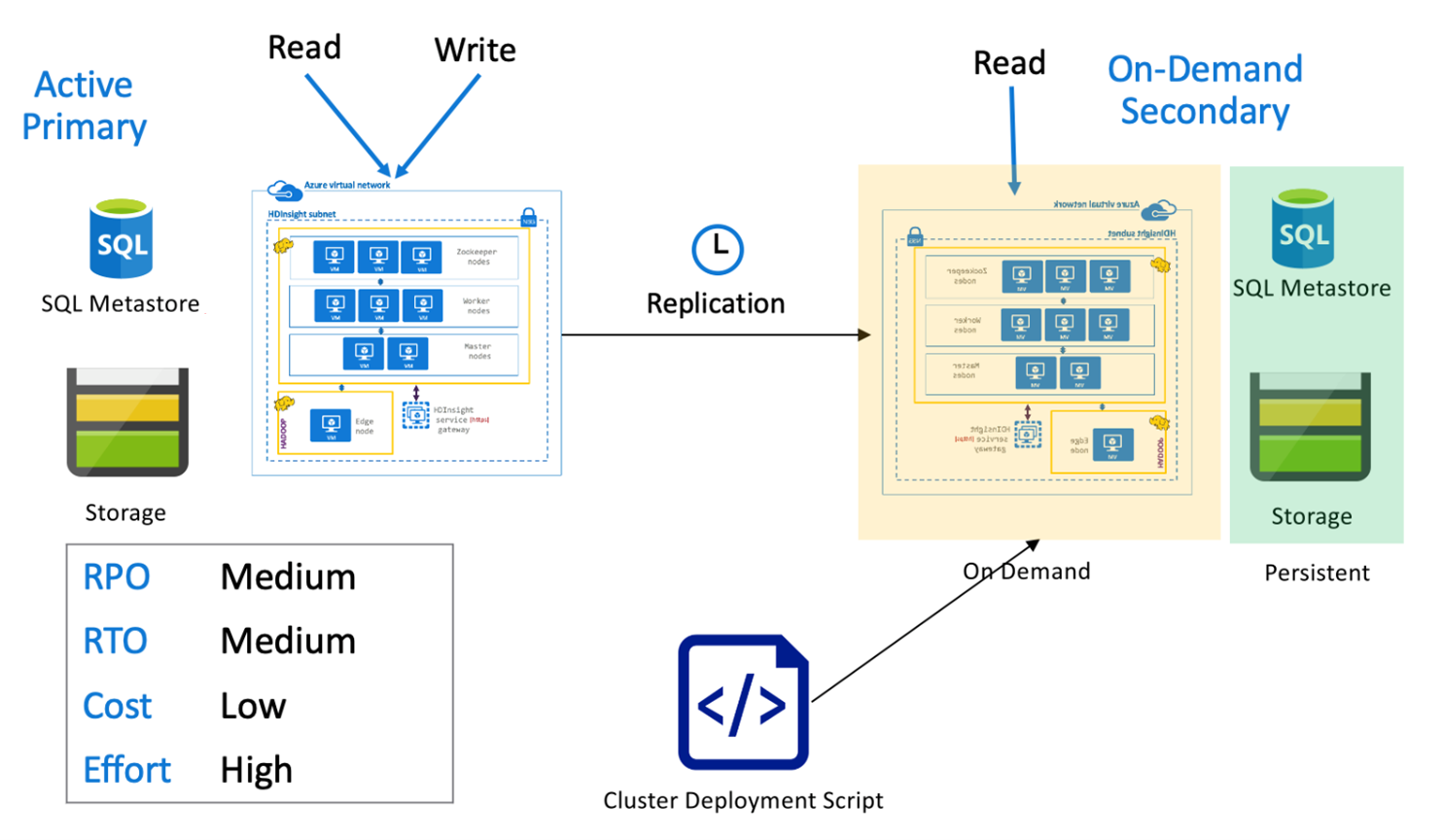
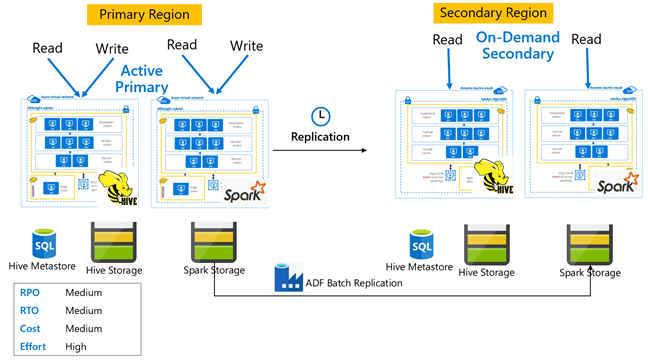
İsteğe bağlı ikincil ile Hive etkin birincil
İsteğe bağlı ikincil mimariye sahip etkin bir birincilde, normal işlemler sırasında ikincil bölgede hiçbir küme sağlanmamışken uygulamalar etkin birincil bölgeye yazar. sql meta veri deposu ve ikincil bölgedeki Depolama kalıcıdır, HDInsight kümesi ise yalnızca zamanlanmış Hive çoğaltması çalıştırılmadan önce betiklenir ve isteğe bağlı olarak dağıtılır.
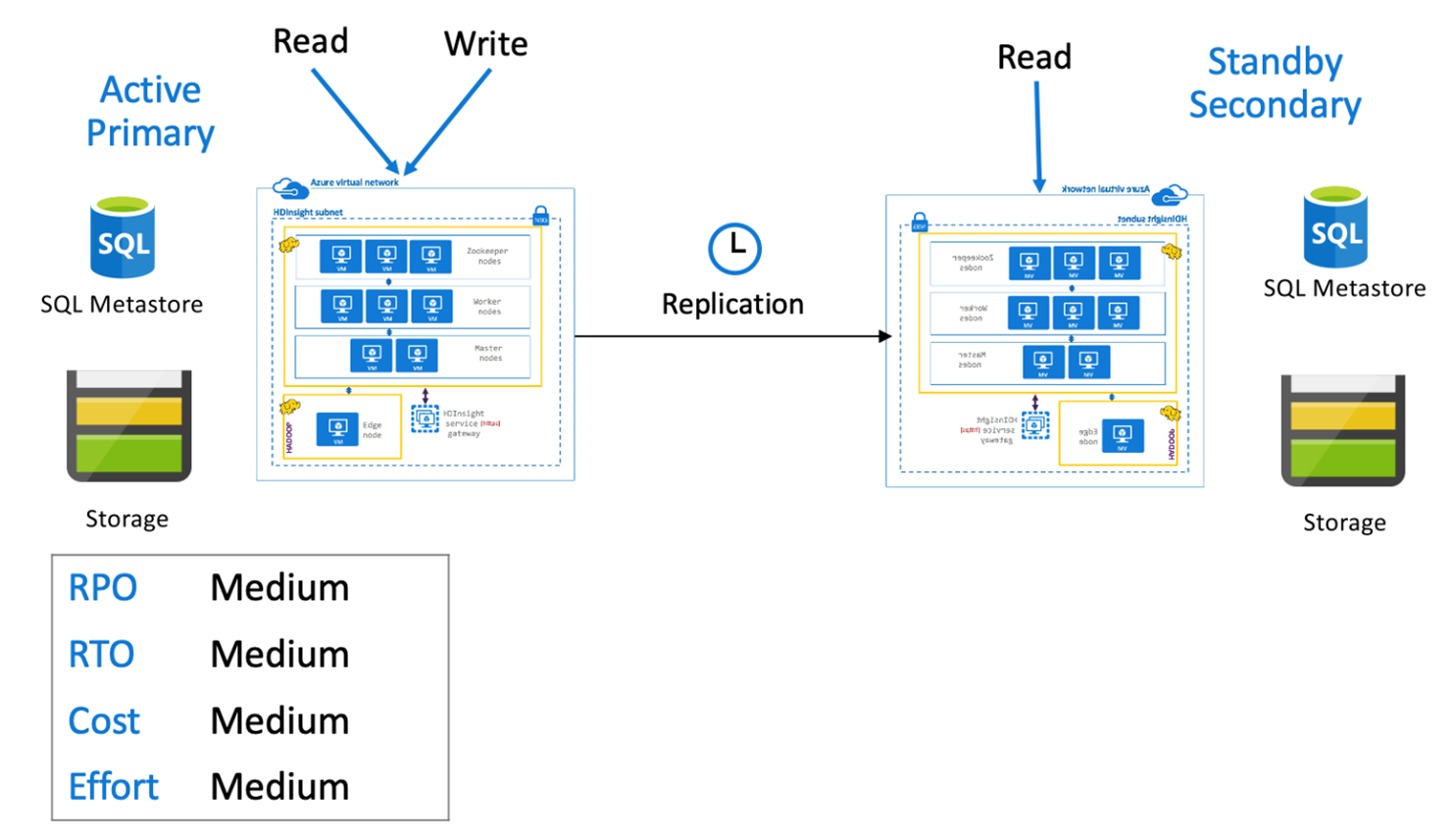
Bekleme ikincilli Hive etkin birincil
Bekleme ikincilli etkin bir birincilde, uygulamalar etkin birincil bölgeye yazarken, hazır bekleyen ölçeklendirilen ikincil küme salt okunur modda normal işlemler sırasında çalışır. Normal işlemler sırasında bölgeye özgü okuma işlemlerini ikincil olarak boşaltmayı seçebilirsiniz.
Hive çoğaltması ve kod örnekleri hakkında daha fazla bilgi için Bkz. Azure HDInsight kümelerinde Apache Hive çoğaltması
Apache Spark
Spark iş yükleri bir Hive bileşeni içerebilir veya içermeyebilir. Spark SQL iş yüklerinin Hive'dan veri okumasını ve yazmasını sağlamak için HDInsight Spark kümeleri aynı bölgedeki Hive/Etkileşimli sorgu kümelerinden Hive özel meta veri depolarını paylaşır. Bu tür senaryolarda, Spark iş yüklerinin bölgeler arası çoğaltması da Hive meta veri depolarının ve depolamanın çoğaltılmasıyla birlikte olmalıdır. Bu bölümdeki yük devretme senaryoları her ikisi için de geçerlidir:
- HdInsight Etkileşimli Sorgu kümesi kullanarak Hive Warehouse Bağlan or(HWC) Kurulumu kullanan ACID tablolarında Spark SQL.
- HDInsight Hadoop kümesi kullanan ACID olmayan tablolarda Spark SQL iş yükü.
Spark'ın tek başına modda çalıştığı senaryolar için, azure Data Factory'nin DistCPkullanılarak seçilen verilerin ve depolanan Spark Jar'larının (Livy işleri için) birincil bölgeden ikincil bölgeye düzenli olarak çoğaltılması gerekir.
Spark not defterlerini ve kitaplıklarını birincil veya ikincil kümelere kolayca dağıtabilecekleri depolamak için sürüm denetim sistemlerini kullanmanızı öneririz. Not defteri tabanlı ve not defteri tabanlı olmayan çözümlerin birincil veya ikincil çalışma alanına doğru veri bağlamalarını yüklemeye hazır olduğundan emin olun.
HDInsight'ın yerel olarak sağladığının ötesinde müşteriye özgü kitaplıklar varsa, bunların izlenmesi ve bekleme ikincil kümesine düzenli aralıklarla yüklenmesi gerekir.
Apache Spark çoğaltma RPO & RTO
RPO: Veri kaybı, birincilden ikincilye son başarılı artımlı çoğaltma (Spark ve Hive) ile sınırlıdır.
RTO: Hata ile ikincil ile yukarı ve aşağı akış işlemlerinin sürdürülmesi arasındaki süre.
Apache Spark mimarileri
İsteğe bağlı ikincil ile Spark etkin birincil
Uygulamalar, normal işlemler sırasında ikincil bölgede hiçbir küme sağlanmamışken birincil bölgedeki Spark ve Hive Kümelerini okur ve yazar. SQL Meta Veri Deposu, Hive Depolama ve Spark Depolama ikincil bölgede kalıcıdır. Spark ve Hive kümeleri betiklenir ve isteğe bağlı olarak dağıtılır. Hive çoğaltma, Hive Depolama ve Hive meta veri depolarını çoğaltmak için kullanılırken Azure Data Factory'ler DistCP tek başına Spark depolamayı kopyalamak için kullanılabilir. Bağımlılık DistCp işlemi nedeniyle hive kümelerinin her Hive çoğaltması çalışmadan önce dağıtılması gerekir.
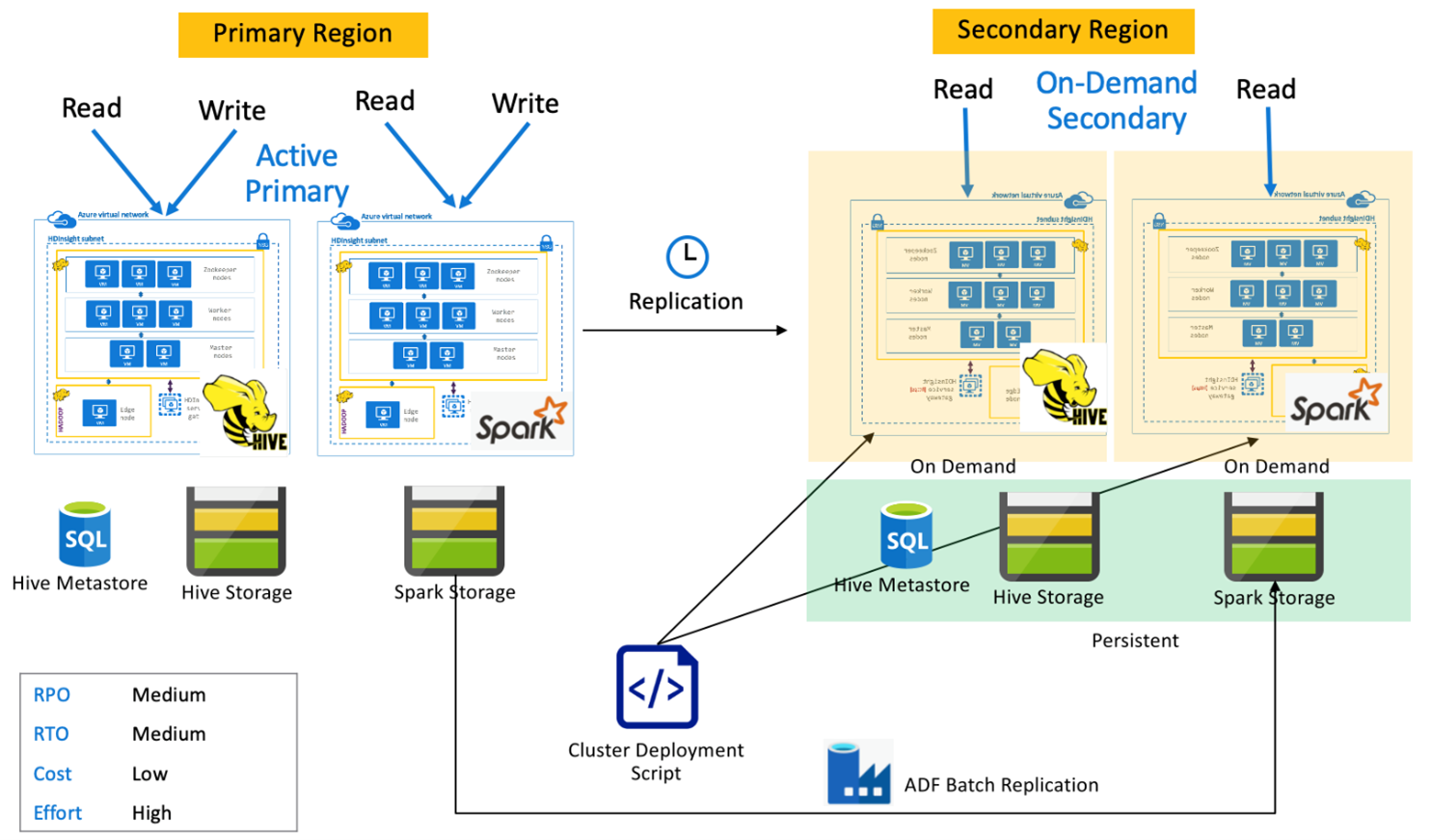
Hazır bekleyen ikincil ile Spark etkin birincil
Uygulamalar birincil bölgedeki Spark ve Hive kümelerini okur ve yazarken, salt okunur modda bekleyen ölçeklendirilen Hive ve Spark kümeleri normal işlemler sırasında ikincil bölgede çalıştırılır. Normal işlemler sırasında bölgeye özgü Hive ve Spark okuma işlemlerini ikincil olarak boşaltmayı seçebilirsiniz.
Apache HBase
HBase Dışarı Aktarma ve HBase Çoğaltma, HDInsight HBase kümeleri arasında iş sürekliliğini etkinleştirmenin yaygın yollarıdır.
HBase Dışarı Aktarma, birincil HBase kümesindeki tabloları temel alınan Azure Data Lake Depolama 2. Nesil depolama alanına aktarmak için HBase Dışarı Aktarma Yardımcı Programı'nı kullanan bir toplu çoğaltma işlemidir. Dışarı aktarılan verilere ikincil HBase kümesinden erişilebilir ve ikincil kümede önceden bulunması gereken tablolara aktarılabilir. HBase Dışarı Aktarma tablo düzeyi ayrıntı düzeyi sunarken, artımlı güncelleştirme durumlarında, dışarı aktarma otomasyonu altyapısı her çalıştırmaya eklenecek artımlı satır aralığını denetler. Daha fazla bilgi için bkz . HDInsight HBase Yedekleme ve Çoğaltma.
HBase Çoğaltma, tam otomatik bir şekilde HBase kümeleri arasında neredeyse gerçek zamanlı çoğaltma kullanır. Çoğaltma tablo düzeyinde yapılır. Tüm tablolar veya belirli tablolar çoğaltma için hedeflenebilir. HBase çoğaltması nihai olarak tutarlıdır; başka bir deyişle birincil bölgedeki bir tabloda yapılan son düzenlemeler tüm ikinciller tarafından hemen kullanılamayabilir. İkincillerin sonunda birincil değerle tutarlı hale gelmesi garanti edilir. HBase çoğaltması aşağıdakiler durumunda iki veya daha fazla HDInsight HBase kümesi arasında ayarlanabilir:
- Birincil ve ikincil aynı sanal ağda yer alır.
- Birincil ve ikincil, aynı bölgedeki farklı eşlenmiş sanal ağlarda bulunur.
- Birincil ve ikincil, farklı bölgelerdeki farklı eşlenmiş sanal ağlarda bulunur.
Daha fazla bilgi için bkz . Azure sanal ağlarında Apache HBase küme çoğaltmasını ayarlama.
HBase kümelerinin yedeklerini gerçekleştirmenin hbase klasörünü kopyalama, tabloları ve Anlık Görüntüleri kopyalama gibi birkaç farklı yolu vardır.
HBase RPO & RTO
HBase Dışarı Aktarma
- RPO: Veri Kaybı, birincilden ikincil tarafından son başarılı toplu artımlı içeri aktarma işlemiyle sınırlıdır.
- RTO: Birincil hata ile ikincilde G/Ç işlemlerinin yeniden başlatılması arasındaki süre.
HBase Çoğaltma
- RPO: Veri Kaybı, ikincilde alınan son WalEdit Gönderisi ile sınırlıdır.
- RTO: Birincil hata ile ikincilde G/Ç işlemlerinin yeniden başlatılması arasındaki süre.
HBase mimarileri
HBase çoğaltması üç modda ayarlanabilir: Öncü-Takipçi, Öncü-Öncü ve Döngüsel.
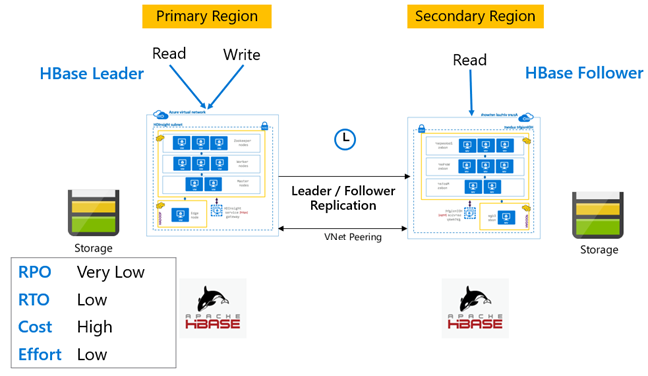
HBase Çoğaltma: Öncü – Takipçi modeli
Bu bölgeler arası kurulumda, çoğaltma birincil bölgeden ikincil bölgeye tek yönlüdür. Tek yönlü çoğaltma için birincil tablolardaki tüm tablolar veya belirli tablolar tanımlanabilir. Normal işlemler sırasında, ikincil küme kendi bölgesinde okuma istekleri sunmak için kullanılabilir.
İkincil küme, kendi tablolarını barındırabilen ve bölgesel uygulamalardan okuma ve yazma işlemleri yapabilecek normal bir HBase kümesi olarak çalışır. Ancak, çoğaltılan tablolarda veya ikincil tablolarda yerel olarak yapılan yazma işlemleri birincil tabloya geri çoğaltılmaz.
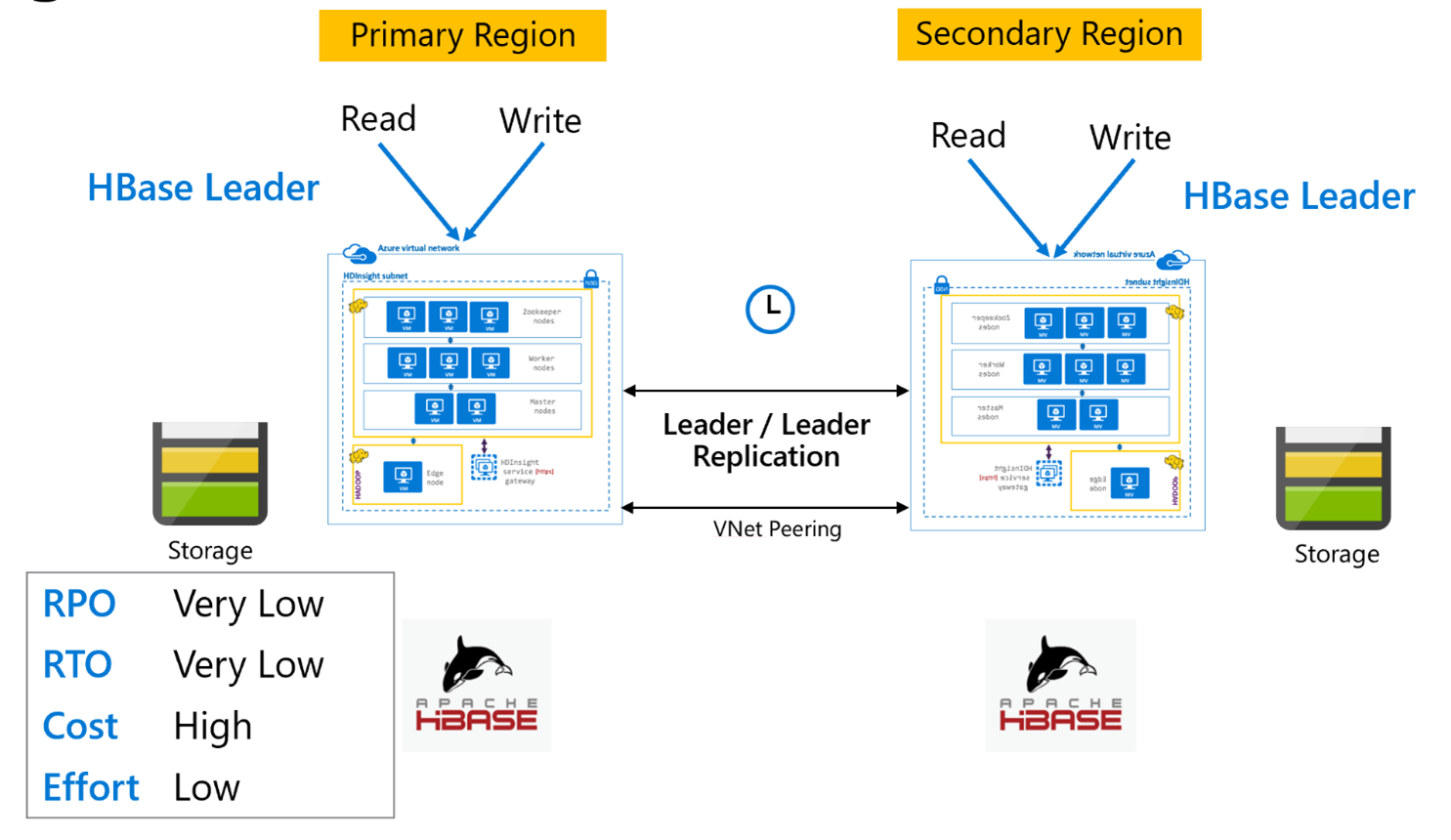
HBase Çoğaltma: Öncü – Öncü modeli
Bu bölgeler arası kurulum, tek yönlü kuruluma çok benzer, ancak çoğaltma birincil bölge ile ikincil bölge arasında çift yönlü olarak gerçekleşir. Uygulamalar her iki kümeyi de okuma-yazma modlarında kullanabilir ve güncelleştirmeler aralarında zaman uyumsuz olarak değiş tokuş olur.
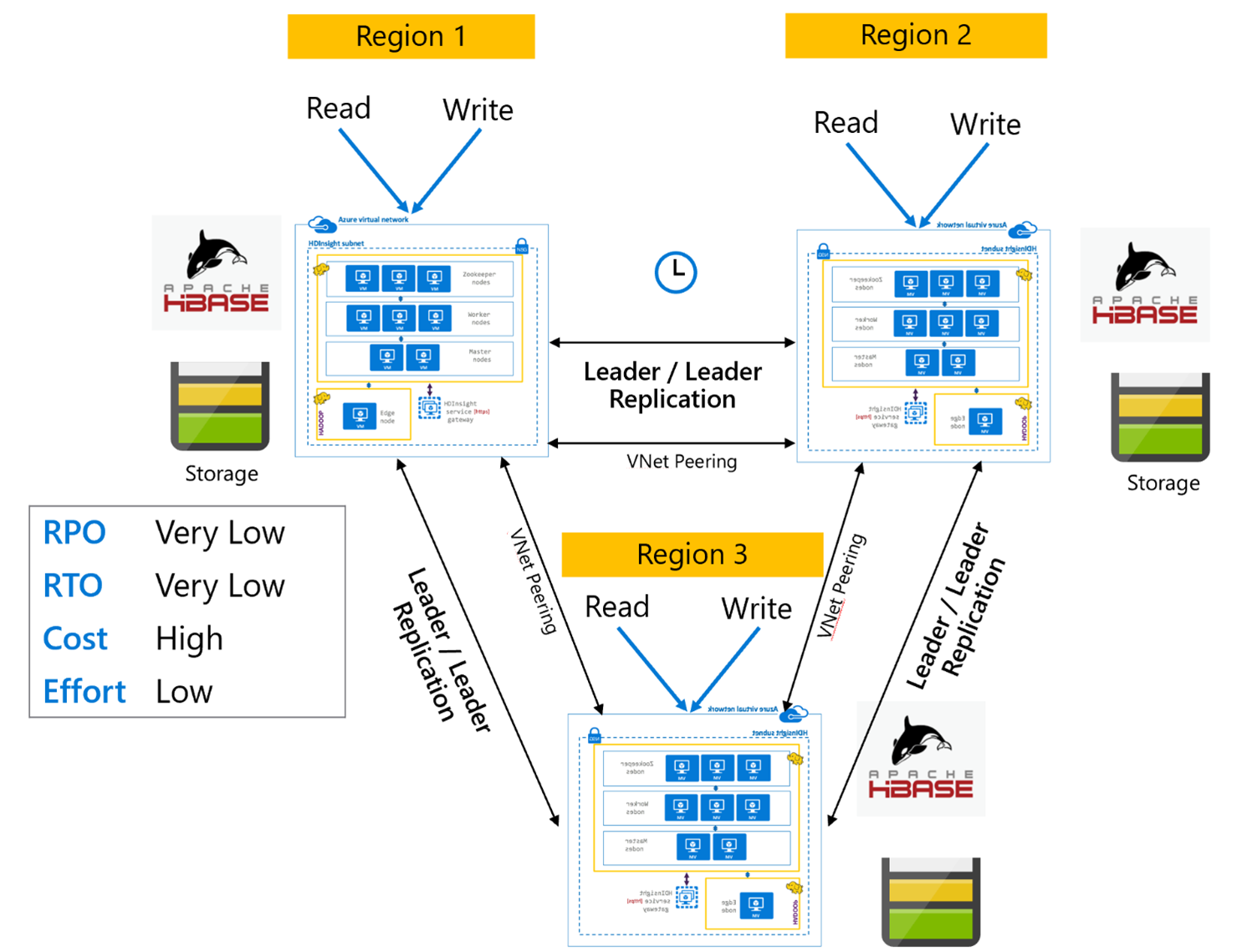
HBase Çoğaltma: Çok Bölgeli veya Döngüsel
Çok Bölgeli/Döngüsel çoğaltma modeli, HBase Çoğaltma'nın bir uzantısıdır ve bölgeye özgü HBase kümelerini okuyan ve yazan birden çok uygulamayla genel olarak yedekli bir HBase mimarisi oluşturmak için kullanılabilir. Kümeler, iş gereksinimlerine bağlı olarak Öncü/Öncü veya Öncü/Takipçi'nin çeşitli bileşimlerinde ayarlanabilir.
Apache Kafka
Bölgeler arası kullanılabilirliği etkinleştirmek için HDInsight 4.0, farklı bir bölgede birincil Kafka kümesinin ikincil çoğaltmasını korumak için kullanılabilen Kafka MirrorMaker'ı destekler. MirrorMaker, üst düzey bir tüketici üretici çifti olarak çalışır, birincil kümedeki belirli bir konudan tüketir ve ikincil kümede aynı ada sahip bir konuya üretir. MirrorMaker kullanarak yüksek kullanılabilirlik olağanüstü durum kurtarma için kümeler arası çoğaltma, Üreticilerin ve Tüketicilerin çoğaltma kümesine yük devretmesi gerektiği varsayımıyla birlikte gelir. Daha fazla bilgi için bkz . HDInsight üzerinde Kafka ile Apache Kafka konularını çoğaltmak için MirrorMaker kullanma
Çoğaltma başlatıldığında konu ömrüne bağlı olarak, MirrorMaker konu çoğaltması kaynak ve çoğaltma konuları arasında farklı uzaklıklara yol açabilir. HDInsight Kafka kümeleri, tek tek küme düzeyinde yüksek kullanılabilirlik özelliği olan konu bölümü çoğaltmasını da destekler.
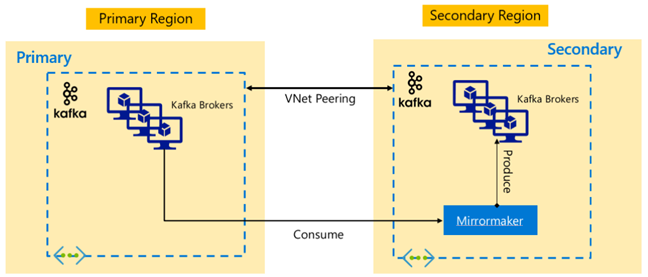
Apache Kafka mimarileri
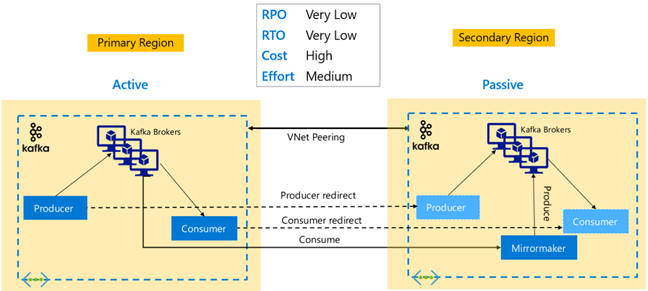
Kafka Çoğaltma: Etkin – Pasif
Active-Passive kurulumu, Etkin'den Pasif'e zaman uyumsuz tek yönlü yansıtmayı etkinleştirir. Üreticilerin ve Tüketicilerin Etkin ve Pasif kümenin varlığından haberdar olmaları ve Etkin'in başarısız olması durumunda Pasif kümeye yük devretmeye hazır olmaları gerekir. Aşağıda Aktif-Pasif kurulumun bazı avantajları ve dezavantajları yer almaktadır.
Avantajlar:
- Kümeler arasındaki ağ gecikme süresi Etkin kümenin performansını etkilemez.
- Tek yönlü çoğaltmanın basitliği.
Dezavantajlar:
- Pasif küme az kullanılabilir durumda kalabilir.
- Uygulama üreticilerine ve tüketicilerine yük devretme farkındalığını eklemede tasarım karmaşıklığı.
- Etkin kümenin başarısızlığı sırasında olası veri kaybı.
- Etkin ve Pasif kümeler arasındaki konular arasında nihai tutarlılık.
- Birincil'e yeniden çalışma, konu başlıklarında ileti tutarsızlığıyla sonuçlanabilir.
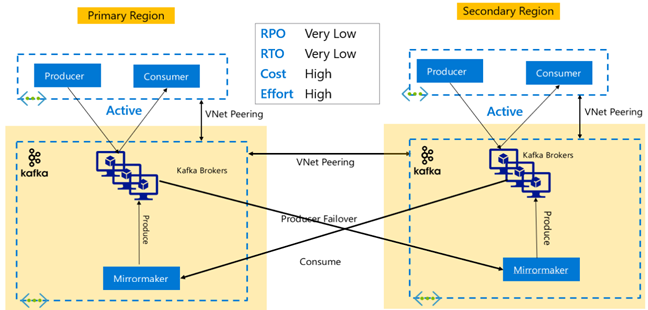
Kafka Çoğaltma: Etkin – Etkin
Etkin-Etkin kurulum, MirrorMaker ile çift yönlü zaman uyumsuz çoğaltma ile bölgesel olarak ayrılmış, sanal ağ eşlenmiş iki HDInsight Kafka kümesi içerir. Bu tasarımda, birincil tüketici tarafından tüketilen iletiler de ikincil ve tam tersi tüketicilerin kullanımına sunulur. Aşağıda, Active-Active kurulumunun bazı avantajları ve dezavantajları yer almaktadır.
Avantajlar:
- Yinelenen durumları nedeniyle yük devretmeler ve yeniden çalışma işlemleri daha kolay yürütülür.
Dezavantajlar:
- Kurulum, yönetim ve izleme, Active-Passive'den daha karmaşıktır.
- Döngüsel çoğaltma sorununun çözülmesi gerekir.
- Çift yönlü çoğaltma, bölgesel veri çıkış maliyetlerinin daha yüksek olmasını sağlar.
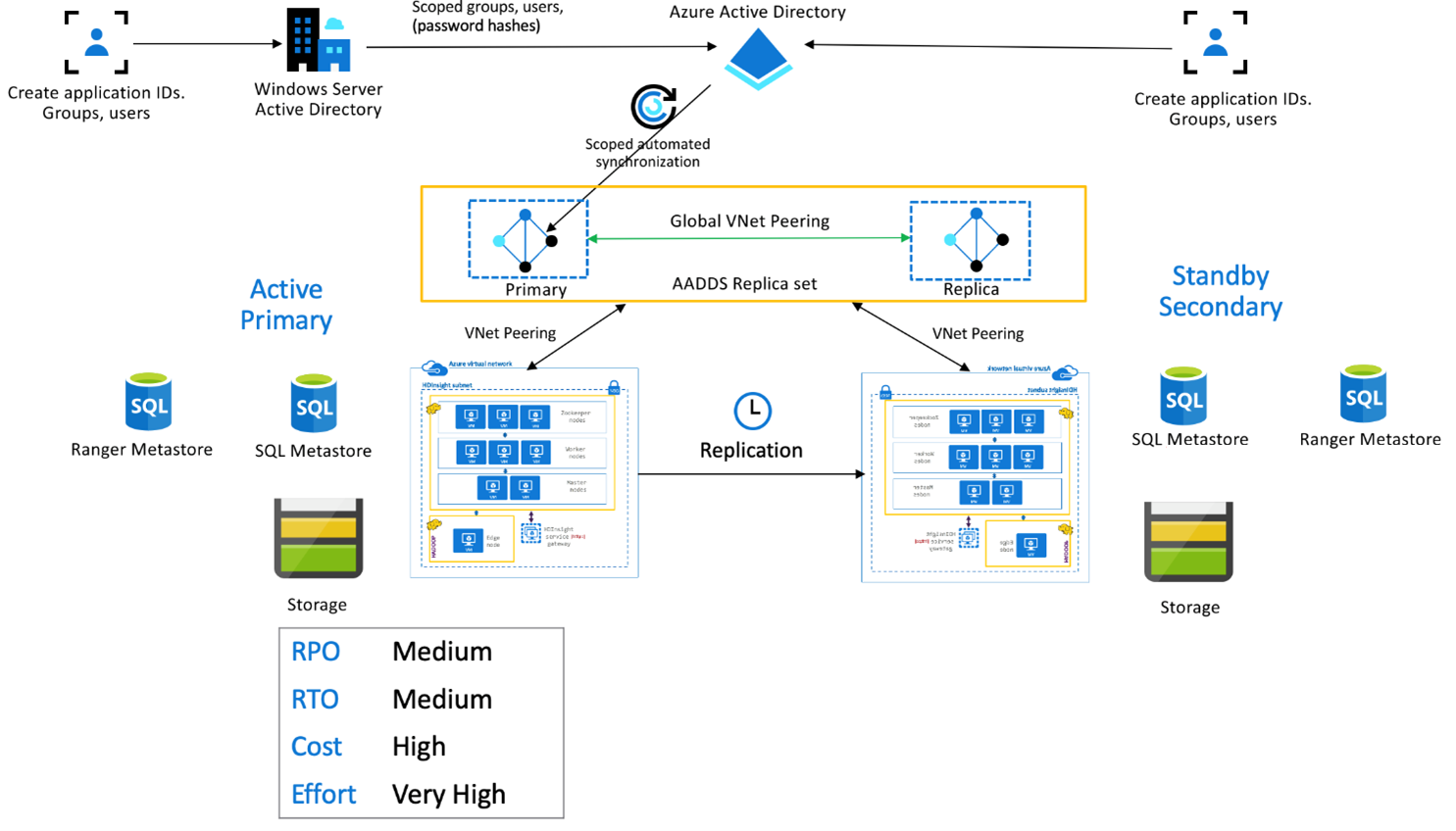
HDInsight Kurumsal Güvenlik Paketi
Bu kurulum, kullanıcıların her iki kümede de kimlik doğrulaması yapabilmesini sağlamak için hem birincil hem de ikincil hem de Microsoft Entra Domain Services çoğaltma kümelerinde çok kullanıcılı işlevselliği etkinleştirmek için kullanılır. Normal işlemler sırasında, kullanıcıların Okuma işlemleriyle kısıtlandığından emin olmak için Ranger ilkelerinin İkincil'de ayarlanması gerekir. Aşağıdaki mimaride, ESP özellikli Hive Active Primary – Bekleme İkincil ayarlamanın nasıl görünebileceği açıklanmaktadır.
Ranger Meta Veri Deposu çoğaltması:
Ranger Meta veri deposu, veri yetkilendirmesini denetlemek için Ranger ilkelerini kalıcı olarak depolamak ve sunmak için kullanılır. Birincil ve ikincil olarak bağımsız Ranger ilkelerini korumanızı ve ikincili okuma amaçlı çoğaltma olarak korumanızı öneririz.
Ranger ilkelerini birincil ve ikincil arasında eşitlenmiş durumda tutmak gerekiyorsa Ranger ilkelerini düzenli aralıklarla yedeklemek ve birincilden ikincilye aktarmak için Ranger İçeri/Dışarı Aktarma kullanın.
Ranger ilkelerinin birincil ve ikincil arasında çoğaltılması, ikincilin yazma özelliğinin etkin hale gelmesine neden olabilir ve bu da ikincilde veri tutarsızlıklarına yol açan yanlışlıkla yazma işlemlerine yol açabilir.
Sonraki adımlar
Bu makalede ele alınan öğeler hakkında daha fazla bilgi edinmek için bkz: