Azure HDInsight kümelerinde Apache Hive çoğaltmasını kullanma
Veritabanları ve ambarlar bağlamında çoğaltma, varlıkları bir ambardan diğerine çoğaltma işlemidir. Yineleme, veritabanının tamamına veya tablo veya bölüm gibi daha küçük bir düzeye uygulanabilir. Amaç, temel varlık her değiştiğinde değişen bir çoğaltmaya sahip olmaktır. Apache Hive'da çoğaltma olağanüstü durum kurtarmaya odaklanır ve tek yönlü birincil kopya çoğaltması sunar. HDInsight kümelerinde Hive Çoğaltma, Hive meta veri depolarını ve ilişkili temel alınan veri göllerini Azure Data Lake Storage 2. Nesil tek yönlü olarak çoğaltmak için kullanılabilir.
Hive Çoğaltma, daha iyi işlevsellik sağlayan ve daha hızlı ve daha az kaynak kullanımlı olan yeni sürümlerle yıllar içinde gelişti. Bu makalede hem HDInsight 3.6 hem de HDInsight 4.0 küme türlerinde desteklenen Hive Çoğaltması (Replv2) ele alınacaktır.
replv2'nin avantajları
Hive ReplicationV2 (Replv2 olarak da adlandırılır), Hive IMPORT-EXPORT kullanan hive çoğaltmasının ilk sürümüne göre aşağıdaki avantajlara sahiptir:
- Olay tabanlı artımlı çoğaltma
- Belirli bir noktaya çoğaltma
- Azaltılmış bant genişliği gereksinimleri
- Ara kopya sayısında azalma
- Çoğaltma durumu korunur
- Kısıtlanmış çoğaltma
- Merkez-Uç modeli desteği
- ACID tabloları desteği (HDInsight 4.0'da)
Çoğaltma aşamaları
Hive olay tabanlı çoğaltma, birincil ve ikincil kümeler arasında yapılandırılır. Bu çoğaltma iki ayrı aşamadan oluşur: önyükleme ve artımlı çalıştırmalar.
Önyükleme
Bootstrapping, veritabanlarının temel durumunu birincilden ikincile çoğaltmak için bir kez çalışacak şekilde tasarlanmıştır. Önyüklemeyi, çoğaltmanın etkinleştirilmesi gereken hedeflenen veritabanında tabloların bir alt kümesini içerecek şekilde yapılandırabilirsiniz.
Artımlı çalıştırmalar
Önyüklemeden sonra, artımlı çalıştırmalar birincil kümede otomatik hale gelir ve bu artımlı çalıştırmalar sırasında oluşturulan olaylar ikincil kümede yeniden oynatılır. İkincil küme birincil kümeye yetiştiğinde, ikincil birincil kümenin olaylarıyla tutarlı hale gelir.
Çoğaltma komutları
Hive, olay akışını düzenlemeye yönelik bir dizi REPL komutu sunar: DUMP, LOADve STATUS . komutu, DUMP birincil kümedeki tüm DDL/DML olaylarının yerel günlüğünü oluşturur. komutu LOAD , ayıklanan çoğaltma dökümü çıkışına günlüğe kaydedilen meta verileri ve verileri serbestçe kopyalamaya yönelik bir yaklaşımdır ve hedef kümede yürütülür. Komut, STATUS en son çoğaltma yükünün başarıyla çoğaltıldığı en son olay kimliğini sağlamak için hedef kümeden çalışır.
Çoğaltma kaynağını ayarlama
Çoğaltmaya başlamadan önce, çoğaltılacak veritabanının çoğaltma kaynağı olarak ayarlandığından emin olun. parametresinin DESC DATABASE EXTENDED <db_name>repl.source.for ilke adıyla ayarlı olup olmadığını belirlemek için komutunu kullanabilirsiniz.
İlke zamanlanmışsa ve repl.source.for parametresi ayarlanmadıysa, önce kullanarak ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>')bu parametreyi ayarlamanız gerekir.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Meta verileri veri gölüne döküm etme
komutuREPL DUMP [database name]. => location / event_id, bootstrap aşamasında ilgili meta verileri Azure Data Lake Storage 2. Nesil dökümü için kullanılır. , event_id ilgili meta verilerin Azure Data Lake Storage 2. Nesil yerleştirildiği en düşük olayı belirtir.
repl dump tpcds_orc;
Örnek çıkış:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Hedef kümeye veri yükleme
REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } komutu, hem bootstrap hem de çoğaltmanın artımlı aşamaları için hedef kümeye veri yüklemek için kullanılır. [database name], kaynakla aynı veya hedef kümedeki farklı bir ad olabilir. , [location] önceki REPL DUMP komutun çıkışındaki konumu temsil eder. Bu, hedef kümenin kaynak kümeyle konuşabilmesi gerektiği anlamına gelir. Yan WITH tümcesi öncelikle hedef kümenin yeniden başlatılmasını önlemek için eklenerek çoğaltmaya izin verildi.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Son çoğaltılan olay kimliğinin çıktısını alma
REPL STATUS [database name] Komut hedef kümelerde yürütülür ve son çoğaltılan event_idçıktısını alır. Komutu, kullanıcıların hedef kümelerinin hangi duruma çoğaltıldığını bilmesini de sağlar. Artımlı çoğaltma için sonraki REPL DUMP komutu oluşturmak için bu komutun çıktısını kullanabilirsiniz.
repl status tpcds_orc;
Örnek çıkış:
| last_repl_id |
|---|
| 2925 |
İlgili verileri ve meta verileri veri gölüne döküm etme
REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } komutu, ilgili meta verileri ve verileri Azure Data Lake Depolama'e dökümü yapmak için kullanılır. Bu komut artımlı aşamada kullanılır ve kaynak ambarda çalıştırılır. FROM [event-id] artımlı aşama için gereklidir ve değeri event-id hedef ambarda REPL STATUS [database name] komutu çalıştırılarak türetilebilir.
repl dump tpcds_orc from 2925;
Örnek çıkış:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
Hive çoğaltma işlemi
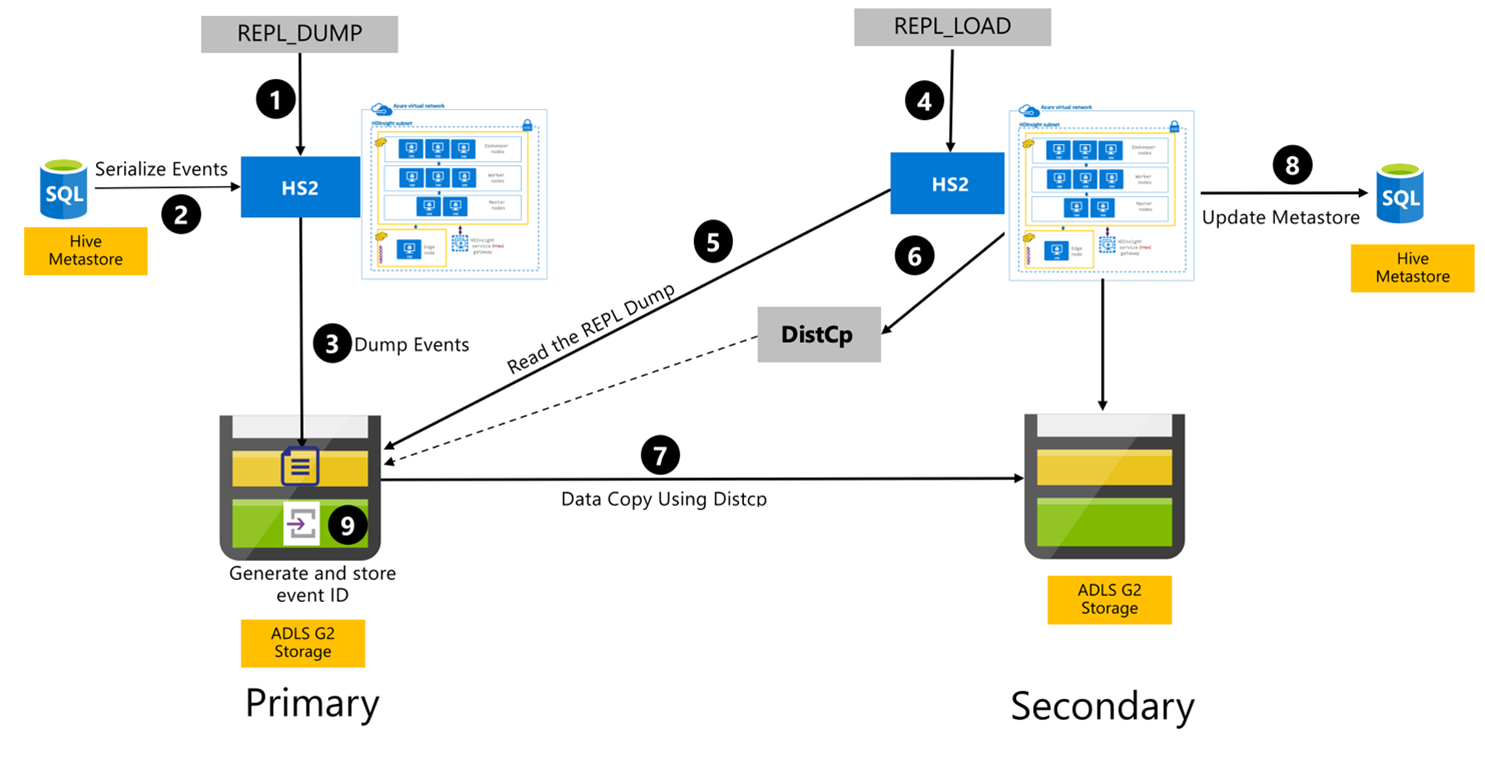
Aşağıdaki adımlar, Hive Çoğaltma işlemi sırasında gerçekleşen sıralı olaylardır.
Çoğaltılan tabloların belirli bir ilke için çoğaltma kaynağı olarak ayarlandığından emin olun.
Komut
REPL_DUMP, veritabanı adı, olay kimliği aralığı ve Azure Data Lake Storage 2. Nesil depolama URL'si gibi ilişkili kısıtlamalarla birincil kümeye verilir.Sistem, meta veri deposundan en son olana kadar izlenen tüm olayların dökümünü serileştirir. Bu döküm, tarafından
REPL_DUMPbelirtilen URL'deki birincil kümedeki Azure Data Lake Storage 2. Nesil depolama hesabında depolanır.Birincil küme, çoğaltma meta verilerini birincil kümenin Azure Data Lake Storage 2. Nesil depolama alanında kalıcı hale getirme. Yol, Ambari'deki Hive Yapılandırma Kullanıcı Arabirimi'nde yapılandırılabilir. İşlem, meta verilerin depolandığı yolu ve en son izlenen DML/DDL olayının kimliğini sağlar.
Komut
REPL_LOADikincil kümeden verilir. Komut, 3. Adımda yapılandırılan yolu gösterir.İkincil küme, 3. Adımda oluşturulan izlenen olaylarla meta veri dosyasını okur. İkincil kümenin, izlenen olayların
REPL_DUMPdepolandığı birincil kümenin Azure Data Lake Storage 2. Nesil depolamasına ağ bağlantısı olduğundan emin olun.İkincil küme dağıtılmış kopya (
DistCP) işlemini oluşturur.İkincil küme, birincil kümenin depolama alanından verileri kopyalar.
İkincil kümedeki meta veri deposu güncelleştirilir.
İzlenen son olay kimliği birincil meta veri deposunda depolanır.
Artımlı çoğaltma aynı işlemi izler ve giriş olarak son çoğaltılan olay kimliğini gerektirir. Bu, son çoğaltma olayından sonra artımlı bir kopyaya yol açar. Artımlı çoğaltmalar normalde gerekli kurtarma noktası hedeflerine (RPO) ulaşmak için önceden belirlenmiş bir sıklık ile otomatikleştirilmiştir.
Çoğaltma desenleri
Çoğaltma normalde birincil ve ikincil arasında tek yönlü bir şekilde yapılandırılır ve burada birincil istekler okuma ve yazma için uygun olur. İkincil küme yalnızca okuma isteklerini karşılar. Olağanüstü durum olduğunda ikincilde yazma işlemlerine izin verilir, ancak ters çoğaltmanın birincile geri yapılandırılması gerekir.
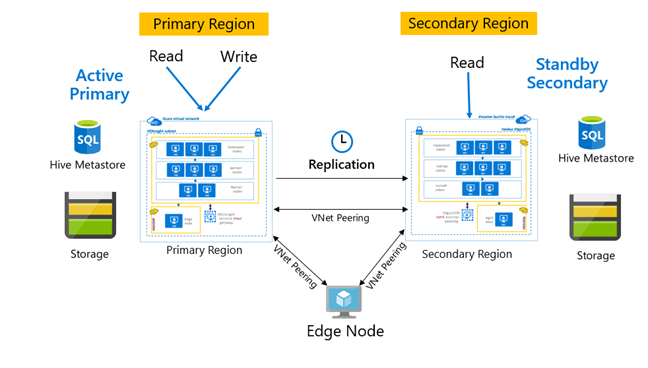
Birincil – İkincil, Merkez ve Uç ve Geçiş gibi Hive çoğaltması için uygun birçok desen vardır.
HDInsight Etkin Birincil – Bekleme İkincil yaygın bir iş sürekliliği ve olağanüstü durum kurtarma (BCDR) desenidir ve HiveReplicationV2, sanal ağ eşlemesi ile bölgesel olarak ayrılmış HDInsight Hadoop kümeleriyle bu düzeni kullanabilir. Çoğaltma otomasyonu betiklerini barındırmak için her iki kümeyle eşlenen ortak bir sanal makine kullanılabilir. Olası HDInsight BCDR desenleri hakkında daha fazla bilgi için HDInsight iş sürekliliği belgelerine bakın.
Kurumsal Güvenlik Paketi ile Hive çoğaltması
Kurumsal Güvenlik Paketi ile HDInsight Hadoop kümelerinde Hive çoğaltması planlandığı durumlarda Ranger meta veri deposu ve Microsoft Entra Domain Services için çoğaltma mekanizmalarını dikkate alsanız iyi olur.
Birden çok bölgede Microsoft Entra kiracısı başına birden fazla Microsoft Entra Domain Services çoğaltma kümesi oluşturmak için Microsoft Entra Domain Services çoğaltma kümeleri özelliğini kullanın. Her çoğaltma kümesinin kendi bölgelerindeki HDInsight sanal ağlarıyla eşlenmesi gerekir. Bu yapılandırmada, yapılandırma, kullanıcı kimliği ve kimlik bilgileri, gruplar, grup ilkesi nesneleri, bilgisayar nesneleri ve diğer değişiklikler de dahil olmak üzere Microsoft Entra Domain Services'da yapılan değişiklikler, Microsoft Entra Domain Services çoğaltması kullanılarak yönetilen etki alanındaki tüm çoğaltma kümelerine uygulanır.
Ranger ilkeleri, Ranger İçeri-Dışarı Aktarma işlevi kullanılarak düzenli aralıklarla yedeklenebilir ve birincil ilkeden ikincilye çoğaltılabilir. İkincil kümede uygulamak istediğiniz yetkilendirme düzeyine bağlı olarak Ranger ilkelerinin tümünü veya bir alt kümesini çoğaltmayı seçebilirsiniz.
Örnek kod
Aşağıdaki kod dizisi, bootstrapping ve artımlı çoğaltmanın adlı tpcds_orcörnek tabloda nasıl uygulanabileceğini gösteren bir örnek sağlar.
Tabloyu bir çoğaltma ilkesinin kaynağı olarak ayarlayın.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Birincil kümede Bootstrap dökümü.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Örnek çıkış:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 İkincil kümede bootstrap yükü.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';REPLİkincil kümedeki durumu denetleyin.repl status tpcds_orc;last_repl_id 2925 Birincil kümedeki artımlı döküm.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Örnek çıkış:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 İkincil kümede artımlı yük.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';İkincil kümedeki durumu denetleyin
REPL.repl status tpcds_orc;last_repl_id 2960
Sonraki adımlar
Bu makalede ele alınan öğeler hakkında daha fazla bilgi edinmek için bkz:
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin