Hızlı Başlangıç: Azure portalını kullanarak Azure HDInsight'ta Apache Kafka kümesi oluşturma
Apache Kafka açık kaynaklı, dağıtılmış bir akış platformudur. Yayımla-abone ol ileti kuyruğuna benzer işlevler sağladığı için genellikle ileti aracısı olarak kullanılır.
Bu Hızlı Başlangıçta, Azure portalını kullanarak Apache Kafka kümesi oluşturmayı öğreneceksiniz. Ayrıca Apache Kafka kullanarak ileti göndermek ve almak için verilen yardımcı programları kullanmayı da öğrenirsiniz. Kullanılabilir yapılandırmaların ayrıntılı açıklamaları için bkz . HDInsight'ta kümeleri ayarlama. Küme oluşturmak için portalın kullanımıyla ilgili ek bilgi için bkz . Portalda küme oluşturma.
Uyarı
HDInsight kümeleri için faturalama, kullansanız da kullanmasanız da dakikada bir eşit olarak dağıtılır. Kullanmayı bitirdikten sonra kümenizi sildiğinizden emin olun. Bkz . HDInsight kümesini silme.
Apache Kafka API'sine yalnızca aynı sanal ağ içindeki kaynaklar tarafından erişilebilir. Bu Hızlı Başlangıçta kümeye doğrudan SSH kullanarak erişebilirsiniz. Diğer hizmetleri, ağları veya sanal makineleri Apache Kafka'ya bağlamak için önce bir sanal ağ oluşturmanız e sonra ağ içinde kaynakları oluşturmanız gerekir. Daha fazla bilgi için Sanal ağ kullanarak Apache Kafka'ya bağlanma belgesine bakın. HDInsight için sanal ağları planlama hakkında daha fazla genel bilgi için bkz . Azure HDInsight için sanal ağ planlama.
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Önkoşullar
Bir SSH istemcisi. Daha fazla bilgi için bkz. SSH kullanarak HDInsight'a (Apache Hadoop) bağlanma.
Apache Kafka kümesi oluşturma
HDInsight'ta Apache Kafka kümesi oluşturmak için aşağıdaki adımları kullanın:
Azure Portal’ında oturum açın.
Üstteki menüden + Kaynak oluştur'u seçin.
HDInsight> kümesi oluşturma sayfasına gitmek için Analiz Azure HDInsight'ı seçin.
Temel Bilgiler sekmesinden aşağıdaki bilgileri sağlayın:
Özellik Açıklama Abonelik Açılan listeden küme için kullanılan Azure aboneliğini seçin. Kaynak grubu Bir kaynak grubu oluşturun veya mevcut bir kaynak grubunu seçin. Kaynak grubu, Azure bileşenleri için bir kapsayıcıdır. Bu durumda, kaynak grubu HDInsight kümesini ve bağımlı Azure Depolama hesabını içermektedir. Küme adı Genel olarak benzersiz bir ad girin. Ad, harf, sayı ve kısa çizgi içeren en fazla 59 karakterden oluşabilir. Adın ilk ve son karakterleri, kısa çizgi olamaz. Bölge Açılan listeden kümenin oluşturulduğu bölgeyi seçin. Daha iyi performans için size daha yakın bir bölge seçin. Küme türü Liste açmak için Küme türünü seçin'i seçin. Listeden küme türü olarak Kafka'yı seçin. Sürüm Küme türü için varsayılan sürüm belirtilir. Farklı bir sürüm belirtmek istiyorsanız açılan listeden öğesini seçin. Küme oturum açma kullanıcı adı ve parolası Varsayılan oturum açma adı şeklindedir admin. Parola en az 10 karakter uzunluğunda olmalı ve en az bir basamak, bir büyük harf ve bir küçük harf, bir alfasayısal olmayan karakter (karakterler' ` "hariç) içermelidir. gibiPass@word1yaygın parolalar sağlamadığınızdan emin olun.Secure Shell (SSH) kullanıcı adı Varsayılan kullanıcı adıdır sshuser. SSH kullanıcı adı için başka bir ad sağlayabilirsiniz.SSH için küme oturum açma parolasını kullanma SSH kullanıcısı için küme oturum açma kullanıcısına sağladığınız parolayla aynı parolayı kullanmak için bu onay kutusunu seçin. 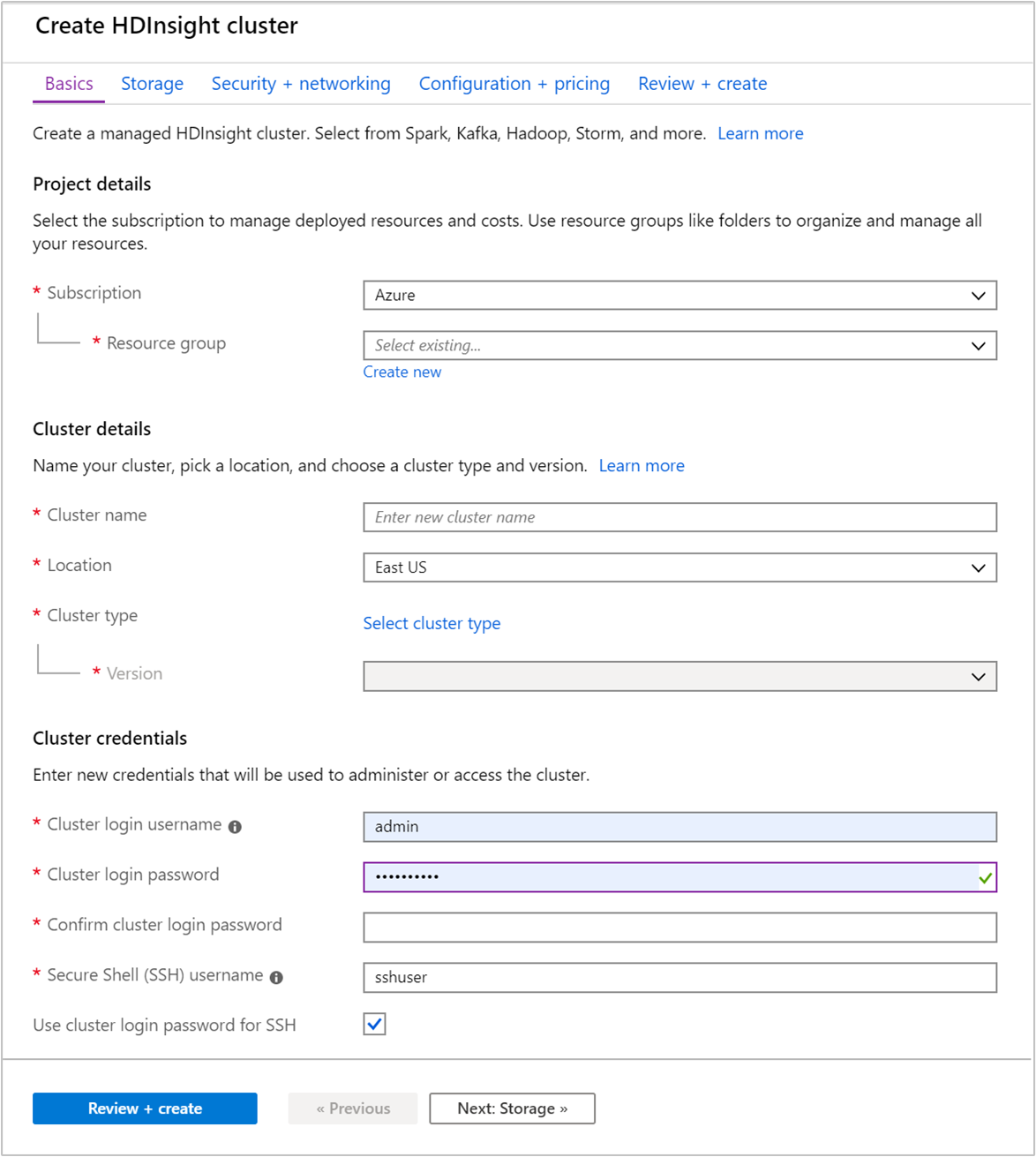
Her Azure bölgesi (konum) hata etki alanları sağlar. Hata etki alanı, bir Azure veri merkezinde temel donanımlardan oluşan mantıksal bir gruplandırmadır. Her hata etki alanı ortak bir güç kaynağı ve ağ anahtarına sahiptir. Bir HDInsight kümesi içindeki düğümleri uygulayan sanal makineler ve yönetilen diskler, bu hata etki alanlarına dağıtılır. Bu mimari, fiziksel donanım hatalarının olası etkisini sınırlar.
Verilerin yüksek kullanılabilirliği için, üç hata etki alanı içeren bir bölge (konum) seçin. Bir bölgedeki hata etki alanlarının sayısı hakkında bilgi almak için Linux sanal makinelerinin kullanılabilirliği belgesine bakın.
Depolama ayarlarına ilerlemek için Sonraki: Depolama >> sekmesini seçin.
Depolama sekmesinde aşağıdaki değerleri sağlayın:
Özellik Açıklama Birincil depolama türü Azure Depolama varsayılan değerini kullanın. Seçim yöntemi Listeden seç varsayılan değerini kullanın. Birincil depolama hesabı Mevcut bir depolama hesabını seçmek için açılan listeyi kullanın veya Yeni oluştur'u seçin. Yeni bir hesap oluşturursanız, adın uzunluğu 3 ile 24 karakter arasında olmalıdır ve yalnızca sayı ve küçük harf içerebilir Kapsayıcı Otomatik doldurulan değeri kullanın. 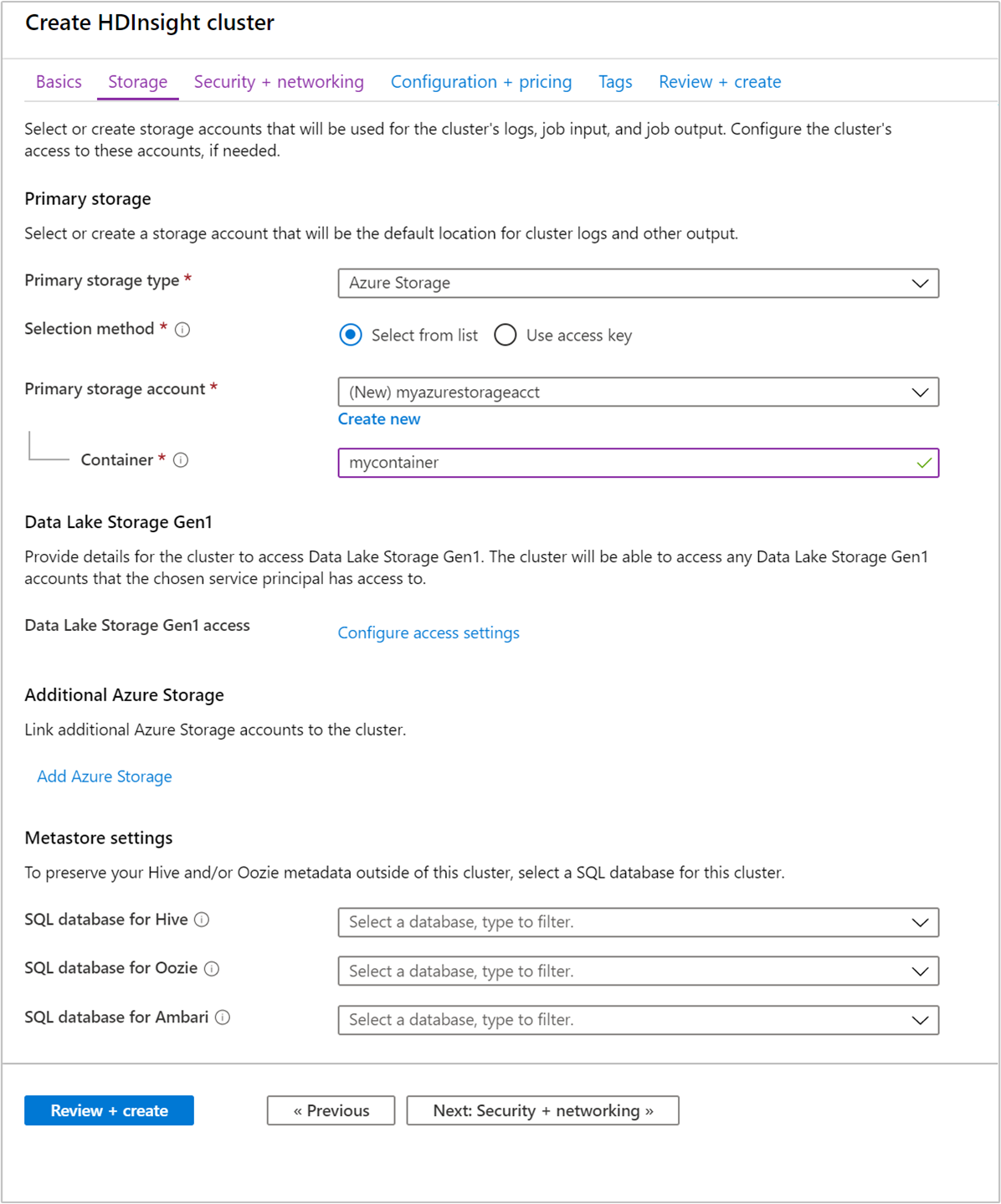
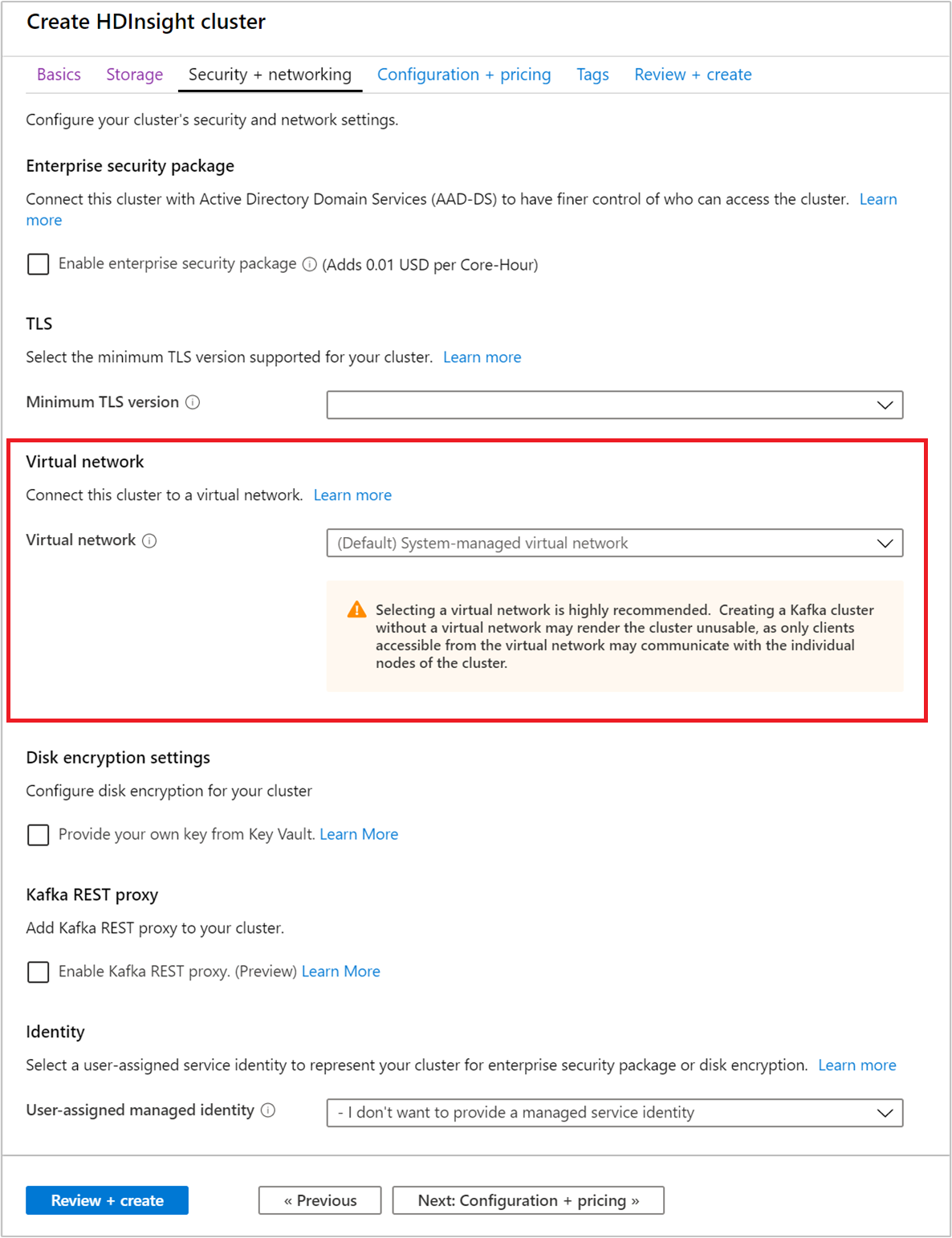
Güvenlik + ağ sekmesini seçin.
Bu Hızlı Başlangıç için varsayılan güvenlik ayarlarını değiştirmeyin. Kurumsal Güvenlik paketi hakkında daha fazla bilgi edinmek için Microsoft Entra Domain Services kullanarak Kurumsal Güvenlik Paketi ile HDInsight kümesi yapılandırma bölümünü ziyaret edin. Apache Kafka Disk Şifrelemesi için kendi anahtarınızı kullanmayı öğrenmek için Müşteri tarafından yönetilen anahtar disk şifrelemesi adresini ziyaret edin
Kümenizi bir sanal ağa bağlamak istiyorsanız, aşağı açılan Sanal ağ listesinden bir sanal ağ seçin.
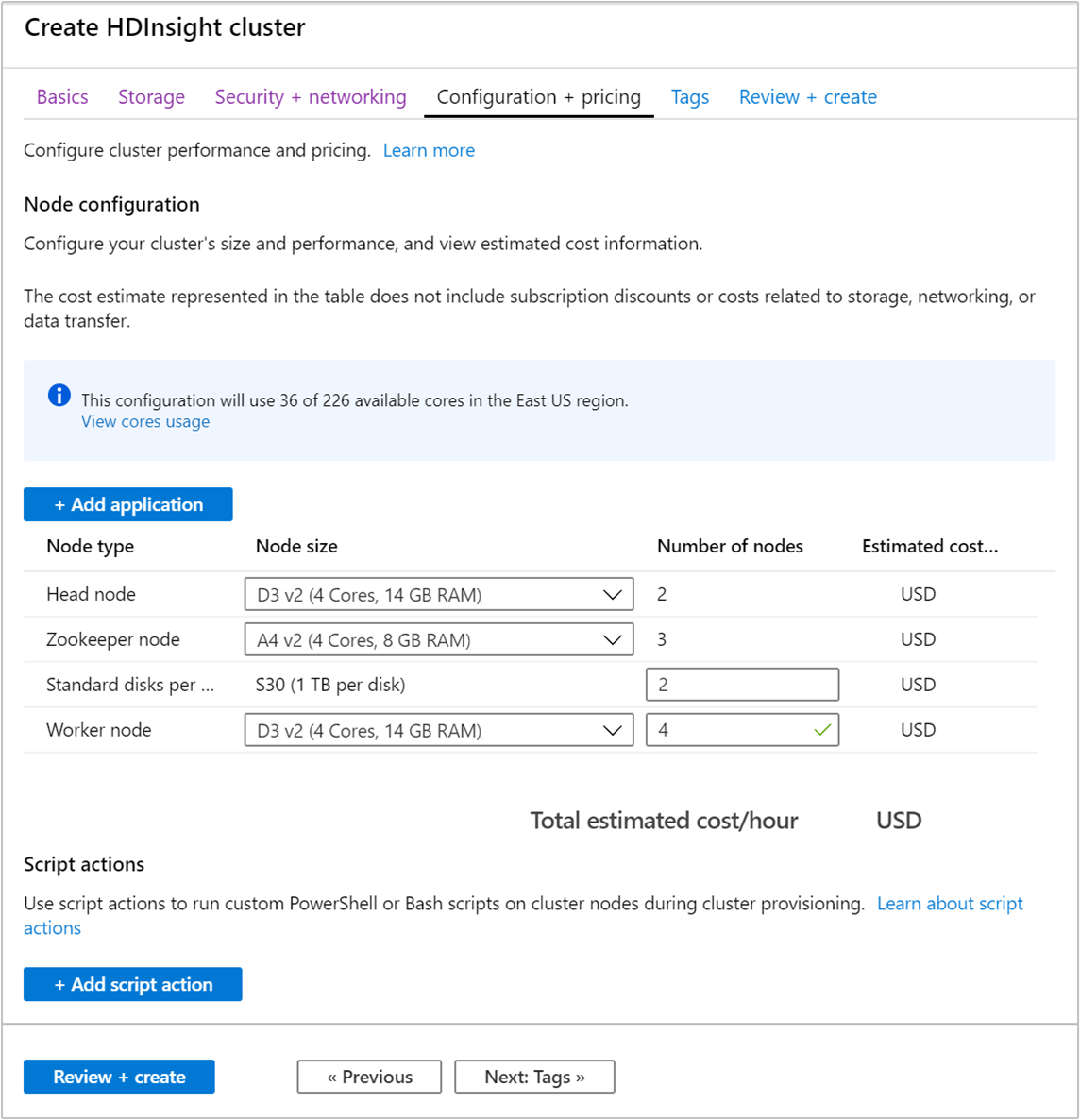
Yapılandırma + fiyatlandırma sekmesini seçin.
HDInsight'ta Apache Kafka'nın kullanılabilirliğini garanti etmek için Çalışan düğümü için düğüm sayısı girdisi 3 veya daha büyük olarak ayarlanmalıdır. Varsayılan değer 4 şeklindedir.
Çalışan düğümü başına Standart diskler girdisi, HDInsight üzerinde Apache Kafka'nın ölçeklenebilirliğini yapılandırıyor. HDInsight üzerinde Apache Kafka, veri depolamak için kümedeki sanal makinelerin yerel diskini kullanır. Apache Kafka yoğun G/Ç kullandığından yüksek aktarım hızı ve düğüm başına daha fazla depolama alanı sağlamak için Azure Yönetilen Diskler kullanılır. Yönetilen diskin türü Standart (HDD) veya Premium (SSD) olabilir. Disk türü, çalışan düğümler (Apache Kafka aracıları) tarafından kullanılan sanal makine boyutuna bağlıdır. Premium diskler otomatik olarak DS ve GS serisi sanal makinelerle kullanılır. Diğer tüm VM türleri standart disk kullanır.
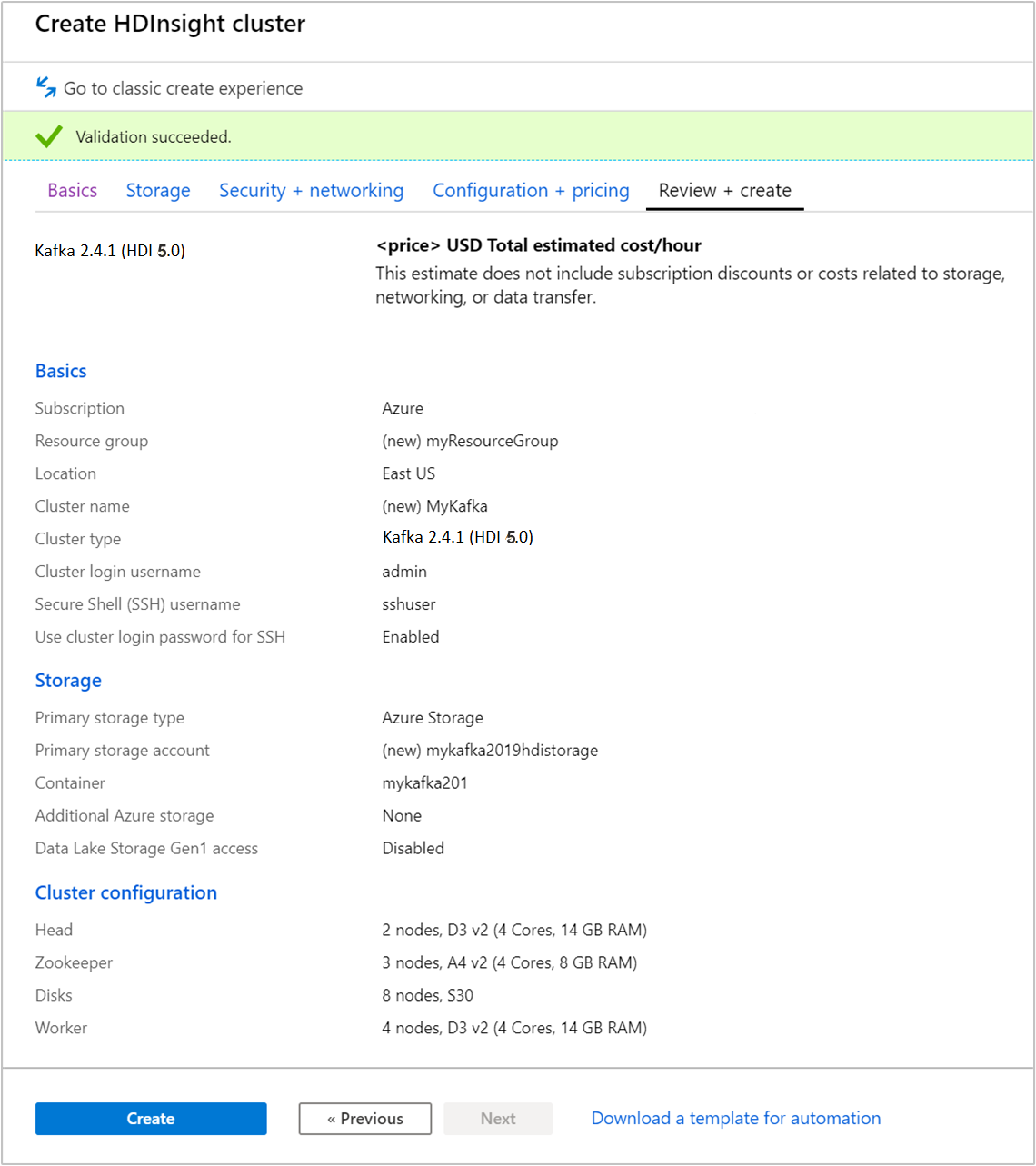
Gözden Geçir ve oluştur sekmesini seçin.
Küme yapılandırmasını gözden geçirin. Yanlış ayarları değiştirin. Son olarak Oluştur'u seçerek kümeyi oluşturun.
Kümenin oluşturulması 20 dakika sürebilir.
Kümeye bağlanma
Kümenize bağlanmak için ssh komutunu kullanın. CLUSTERNAME değerini kümenizin adıyla değiştirerek aşağıdaki komutu düzenleyin ve komutunu girin:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netİstendiğinde, SSH kullanıcısının parolasını girin.
Bağlandığında, aşağıdaki metne benzer bilgiler görürsünüz:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Apache Zookeeper ve Aracı konak bilgilerini alma
Kafka ile çalışırken Apache Zookeeper ve Broker konaklarını bilmeniz gerekir. Bu konaklar Apache Kafka API'si ve Kafka ile gönderilen yardımcı programların birçoğu ile birlikte kullanılır.
Bu bölümde konak bilgilerini kümedeki Apache Ambari REST API'sinden alırsınız.
Bir komut satırı JSON işlemcisi olan jq'yi yükleyin. Bu yardımcı program JSON belgelerini ayrıştırmak için kullanılır ve konak bilgilerini ayrıştırmada yararlıdır. SSH bağlantısını açın, yüklemek
jqiçin aşağıdaki komutu girin:sudo apt -y install jqParola değişkenini ayarlayın. değerini küme oturum açma parolası ile değiştirin
PASSWORDve komutunu girin:export PASSWORD='PASSWORD'Doğru büyük/küçük harfe ayrılmış küme adını ayıklayın. Küme adının gerçek büyük/küçük harfle oluşturulması, kümenin nasıl oluşturulduğuna bağlı olarak beklediğinizden farklı olabilir. Bu komut gerçek büyük/küçük harfe sahip olur ve bir değişkende depolar. Aşağıdaki komutu girin:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Not
Bu işlemi küme dışından yapıyorsanız, küme adını depolamak için farklı bir yordam vardır. Azure portalından küme adını küçük harfle alın. Ardından, aşağıdaki komutta küme adını
<clustername>yerine yazın ve yürütür:export clusterName='<clustername>'.Zookeeper konak bilgileriyle bir ortam değişkeni ayarlamak için aşağıdaki komutu kullanın. komutu tüm Zookeeper konaklarını alır, ardından yalnızca ilk iki girdiyi döndürür. Bunun nedeni, bir ana bilgisayarın ulaşılamaz olması durumunda yedeklilik istemenizdir.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Not
Bu komut Ambari erişimi gerektirir. Kümeniz bir NSG'nin arkasındaysa Ambari'ye erişebilen bir makineden bu komutu çalıştırın.
Ortam değişkeninin düzgün şekilde ayarlandığını doğrulamak için aşağıdaki komutu kullanın:
echo $KAFKAZKHOSTSBu komutun aşağıdaki metne benzer bilgiler döndürmesi gerekir:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Bir ortam değişkenini Apache Kafka aracı konak bilgileriyle ayarlamak için aşağıdaki komutu kullanın:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Not
Bu komut Ambari erişimi gerektirir. Kümeniz bir NSG'nin arkasındaysa Ambari'ye erişebilen bir makineden bu komutu çalıştırın.
Ortam değişkeninin düzgün şekilde ayarlandığını doğrulamak için aşağıdaki komutu kullanın:
echo $KAFKABROKERSBu komutun aşağıdaki metne benzer bilgiler döndürmesi gerekir:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Apache Kafka konularını yönetme
Kafka, veri akışlarını konular içinde depolar. Konuları yönetmek için kafka-topics.sh yardımcı programını kullanabilirsiniz.
Bir konu oluşturmak için, SSH bağlantısında aşağıdaki komutu kullanın:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSBu komut, içinde depolanan konak bilgilerini kullanarak Aracıya
$KAFKABROKERSbağlanır. Daha sonra test adlı bir Apache Kafka konusu oluşturur.Bu konuda depolanan veriler, sekiz bölüm halinde bölümlenir.
Her bölüm, kümedeki üç çalışan düğümü arasında çoğaltılır.
Üç hata etki alanı sağlayan bir Azure bölgesinde kümeyi oluşturduysanız, 3 çoğaltma katsayısını kullanın. Aksi takdirde 4 çoğaltma katsayısını kullanın.
Üç hata etki alanı içeren bölgelerde 3 çoğaltma katsayısı, çoğaltmaların hata etki alanları arasında yayılmasına olanak sağlar. İki hata etki alanı içeren bölgelerde dört çoğaltma katsayısı, çoğaltmaların etki alanları arasında eşit şekilde yayılmasına olanak sağlar.
Bir bölgedeki hata etki alanlarının sayısı hakkında bilgi almak için Linux sanal makinelerinin kullanılabilirliği belgesine bakın.
Apache Kafka, Azure hata etki alanları ile uyumlu değildir. Konular için bölüm çoğaltmaları oluşturulurken, çoğaltmalar yüksek kullanılabilirlik için düzgün şekilde dağıtılmayabilir.
Yüksek kullanılabilirlik sağlamak için Apache Kafka bölüm yeniden dengeleme aracını kullanın. Bu araç, Apache Kafka kümenizin baş düğümüyle kurulan bir SSH bağlantısından çalıştırılmalıdır.
Apache Kafka verilerinizin en yüksek kullanılabilirliğe sahip olması için aşağıdaki durumlarda konunuz için bölüm çoğaltmalarını yeniden dengelemeniz gerekir:
Yeni bir konu veya bölüm oluşturduğunuzda
Bir kümenin ölçeğini artırdığınızda
Konuları listelemek için aşağıdaki komutu kullanın:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSBu komut, Apache Kafka kümesinde bulunan konuları listeler.
Bir konuyu silmek için aşağıdaki komutu kullanın:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSBu komut,
topicnameadlı konuyu siler.Uyarı
Daha önce oluşturulan
testkonusunu silerseniz, yeniden oluşturmanız gerekir. Bu belgenin ilerleyen kısmındaki adımlarda kullanılacaktır.
kafka-topics.sh yardımcı programı ile kullanılabilen komutlar hakkında daha fazla bilgi için aşağıdaki komutu kullanın:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Kayıt oluşturma ve kullanma
Kafka, kayıtları başlıklar halinde depolar. Kayıtlar, Üreticiler tarafından oluşturulur ve tüketiciler tarafından kullanılır. Üreticiler ve tüketiciler, Kafka aracısı hizmetiyle iletişim kurar. HDInsight kümenizdeki her çalışan düğümü bir Apache Kafka aracı konağıdır.
Daha önce oluşturduğunuz test konu başlığında kayıtları depolamak ve ardından bir tüketici kullanarak bunları okumak için aşağıdaki adımları kullanın:
Konuya kayıtlar yazmak için SSH bağlantısından
kafka-console-producer.shyardımcı programını kullanın:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testBu komuttan sonra boş bir satıra ulaşırsınız.
Boş satıra bir metin iletisi yazın ve Enter tuşuna basın. Bu şekilde birkaç ileti girin ve sonra normal isteme geri dönmek için Ctrl + C tuşlarını kullanın. Her satır, Apache Kafka konusuna ayrı bir kayıt olarak gönderilir.
Konudan kayıtları okumak için SSH bağlantısından
kafka-console-consumer.shyardımcı programını kullanın:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningBu komutla, kayıtlar konu başlığından alınır ve görüntülenir.
--from-beginningkullanılması, tüketiciye akışın başından başlamasını söyler, böylece tüm kayıtlar alınır.Kafka’nın eski bir sürümünü kullanıyorsanız
--bootstrap-server $KAFKABROKERSdeğerini--zookeeper $KAFKAZKHOSTSile değiştirin.Tüketiciyi durdurmak için Ctrl + C tuşlarını kullanın.
Ayrıca programlı olarak üretici ve tüketici de oluşturabilirsiniz. Bu API'yi kullanma örneği için HDInsight ile Apache Kafka Üretici ve Tüketici API'sine bakın.
Kaynakları temizleme
Bu hızlı başlangıç tarafından oluşturulan kaynakları temizlemek için kaynak grubunu silebilirsiniz. Kaynak grubunun silinmesi, ilişkili HDInsight kümesini ve kaynak grubuyla ilişkili diğer tüm kaynakları da siler.
Azure portalını kullanarak kaynak grubunu kaldırmak için:
- Azure portalında sol taraftaki menüyü genişleterek hizmet menüsünü açın ve sonra Kaynak Grupları'nı seçerek kaynak gruplarınızın listesini görüntüleyin.
- Silinecek kaynak grubunu bulun ve sonra listenin sağ tarafındaki Daha fazla düğmesine (...) sağ tıklayın.
- Kaynak grubunu sil'i seçip onaylayın.
Uyarı
HDInsight'ta Apache Kafka kümesi silindiğinde Kafka'da depolanan tüm veriler silinir.