Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Apache Spark Streaming, HDInsight Spark kümelerinde veri akışı işleme sağlar. Bir düğüm hatası oluşsa bile herhangi bir giriş olayının tam olarak bir kez işlendiğini garanti eder. Spark Stream, Azure Event Hubs da dahil olmak üzere çok çeşitli kaynaklardan giriş verileri alan uzun süre çalışan bir iştir. Ayrıca: Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ, ham TCP yuvaları veya Apache Hadoop YARN dosya sistemlerinin izlenmesinden. Spark Stream, yalnızca olay odaklı bir işlemden farklı olarak verileri zaman pencerelerine toplu olarak işler. Örneğin, 2 saniyelik bir dilim alır ve sonra her bir veri kümesini eşleştirme, azaltma, birleştirme ve ayıklama işlemlerini kullanarak dönüştürür. Ardından Spark Stream dönüştürülen verileri dosya sistemlerine, veritabanlarına, panolara ve konsola yazar.
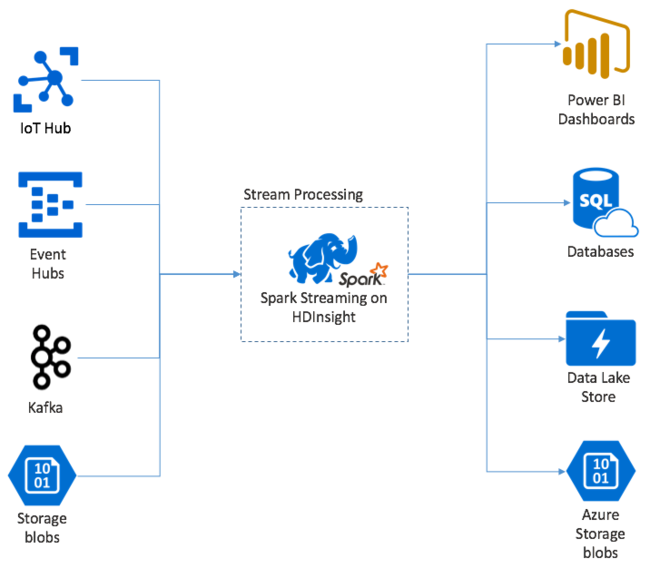
Spark Streaming uygulamalarının, işleme için bu toplu işlemi göndermeden önce olayların her micro-batch birini toplamak için saniyenin bir bölümünü beklemesi gerekir. Buna karşılık, olay temelli bir uygulama her olayı hemen işler. Spark Akışı gecikme süresi genellikle birkaç saniyenin altındadır. Mikro toplu iş yaklaşımının avantajları, daha verimli veri işleme ve daha basit toplama hesaplamalarıdır.
DStream ile tanışın
Spark Streaming, DStream adı verilen ayrık bir akış kullanarak gelen verilerin sürekli akışını temsil eder. DStream, Event Hubs veya Kafka gibi giriş kaynaklarından oluşturulabilir. Veya başka bir DStream'e dönüştürmeler uygulayarak.
DStream, ham olay verilerinin üzerinde bir soyutlama katmanı sağlar.
Tek bir olayla başlayın, örneğin bağlı bir termostattan sıcaklık okuması. Bu olay Spark Akış uygulamanıza ulaştığında, olay birden çok düğümde çoğaltıldığı güvenilir bir şekilde depolanır. Bu hataya dayanıklılık, tek bir düğümün başarısız olmasının olayınızın kaybolmasına neden olmamasını sağlar. Spark çekirdeği, verileri kümedeki birden çok düğüme dağıtan bir veri yapısı kullanır. Burada her düğüm genellikle en iyi performans için kendi bellek içi verilerini tutar. Bu veri yapısı dayanıklı dağıtılmış veri kümesi (RDD) olarak adlandırılır.
Her RDD, toplu iş aralığı adı verilen kullanıcı tanımlı bir zaman çerçevesi üzerinden toplanan olayları temsil eder. Her toplu iş aralığı geçtikten sonra, bu aralıktan gelen tüm verileri içeren yeni bir RDD oluşturulur. Sürekli RDD kümesi bir DStream içinde toplanır. Örneğin, parti aralığı bir saniye uzunluğundaysa, DStream'iniz her saniye, o saniyede alınan tüm verileri içeren bir RDD içeren bir parti yayar. DStream işlenirken sıcaklık olayı bu toplu işlemlerden birinde görünür. Spark Akış uygulaması olayları içeren toplu işlemleri işler ve sonuçta her RDD'de depolanan veriler üzerinde işlem yapar.

Spark Akış uygulamasının yapısı
Spark Akış uygulaması, alma kaynaklarından veri alan uzun süre çalışan bir uygulamadır. Verileri işlemek için dönüştürmeler uygular ve ardından verileri bir veya daha fazla hedefe gönderir. Spark Akış uygulamasının yapısı statik ve dinamik bir parçaya sahiptir. Statik bölüm, verilerin nereden geldiğini, veriler üzerinde hangi işlemenin yapılacağı tanımlar. Ve sonuçların nereye gitmesi gerektiği. Dinamik bölüm, uygulamayı süresiz olarak çalıştırarak durdurma sinyali bekliyor.
Örneğin, aşağıdaki basit uygulama TCP yuvası üzerinden bir metin satırı alır ve her sözcüğün kaç kez göründüğünü sayar.
Uygulamayı tanımlama
Uygulama mantığı tanımının dört adımı vardır:
- StreamingContext oluşturun.
- StreamingContext'ten bir DStream oluşturun.
- DStream'e dönüştürmeleri uygulama.
- Sonuçların çıkışını elde edin.
Bu tanım statiktir ve uygulamayı çalıştırana kadar hiçbir veri işlenmez.
Bir StreamingContext oluşturun
SparkContext'ten kümenize işaret eden bir StreamingContext oluşturun. StreamingContext oluştururken, toplu iş boyutunu saniye cinsinden belirtirsiniz, örneğin:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
DStream oluşturma
StreamingContext örneğiyle, giriş kaynağınız için bir giriş DStream'i oluşturun. Bu durumda uygulama, varsayılan ekli depolama alanında yeni dosyaların görünümünü izliyor.
val lines = ssc.textFileStream("/uploads/Test/")
Dönüştürmeleri uygulama
DStream üzerinde dönüşümler uygulayarak işlemeyi uygularsınız. Bu uygulama dosyadan bir kerede bir satır metin alır ve her satırı sözcüklere böler. Ardından, her sözcüğün kaç kez göründüğünü saymak için bir harita azaltma deseni kullanır.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Çıktı sonuçları
Çıkış işlemlerini uygulayarak dönüştürme sonuçlarını hedef sistemlere gönderme. Bu durumda, her hesaplama çalışmasının sonucu konsol çıkışına yazdırılır.
wordCounts.print()
Uygulamayı çalıştırma
Akış uygulamasını başlatın ve sonlandırma sinyali alınana kadar çalıştırın.
ssc.start()
ssc.awaitTermination()
Spark Stream API'sinin ayrıntıları için bkz . Apache Spark Akış Programlama Kılavuzu.
Aşağıdaki örnek uygulama bağımsızdır, bu nedenle jupyter notebook içinde çalıştırabilirsiniz. Bu örnek, DummySource sınıfında bir sayacın değerini ve geçerli saati beş saniyede bir milisaniye cinsinden veren bir sahte veri kaynağı oluşturur. Yeni bir StreamingContext nesnesinin toplu iş aralığı 30 saniyedir. Bir parti oluşturulduğunda akış uygulaması üretilen RDD'yi inceler. Ardından RDD'yi Spark DataFrame'e dönüştürür ve DataFrame üzerinden geçici bir tablo oluşturur.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Yukarıdaki uygulamayı başlattıktan sonra yaklaşık 30 saniye bekleyin. Daha sonra, toplu işte mevcut olan geçerli değer kümesini görmek için DataFrame'i düzenli aralıklarla sorgulayabilirsiniz, örneğin bu SQL sorgusunu kullanarak:
%%sql
SELECT * FROM demo_numbers
Sonuçta elde edilen çıkış aşağıdaki çıkış gibi görünür:
| değer | zaman |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
DummySource her 5 saniyede bir değer oluşturduğundan ve uygulama her 30 saniyede bir toplu değer yaydığından toplam altı değer vardır.
Kayan pencereler
DStream'inizde bir süre boyunca toplu hesaplamalar yapmak için (örneğin, son iki saniye içinde ortalama bir sıcaklık elde etmek için Spark Streaming'e dahil edilen sliding window işlemleri kullanın. Kayan pencerenin süresi (pencere uzunluğu) ve pencerenin içeriğinin değerlendirildiği aralık (slayt aralığı) vardır.
Kayan pencereler çakışabilir, örneğin, iki saniye uzunluğunda bir pencere tanımlayabilirsiniz. Bu pencere her saniye kayar. Bu eylem, her toplama hesaplaması gerçekleştirdiğinizde pencerenin önceki pencerenin son bir saniyesine ait verileri içereceği anlamına gelir. Ve sonraki bir saniye içinde tüm yeni veriler.
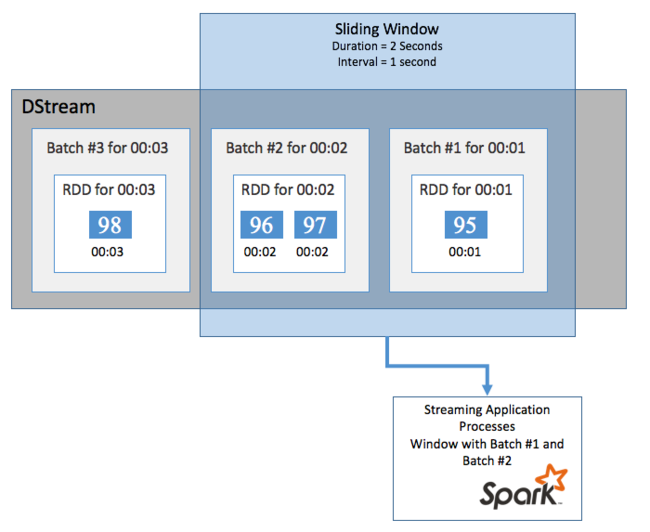
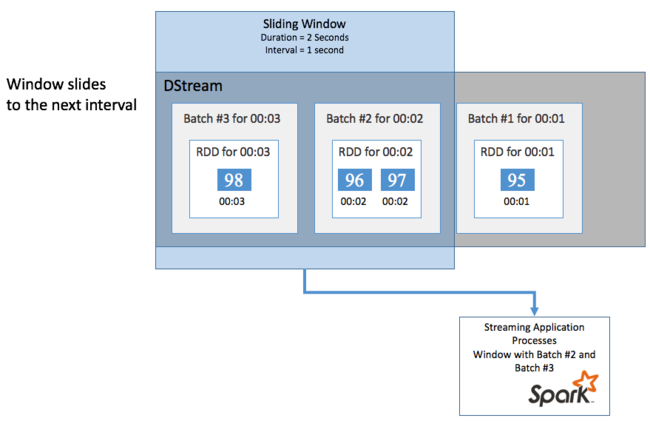
Aşağıdaki örnek, toplu işleri bir dakikalık süre ve bir dakikalık slayt içeren bir pencerede toplamak için DummySource kullanan kodu güncelleştirir.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
İlk dakikadan sonra 12 giriş vardır: pencere içinde toplanan iki serinin her birinden altı giriş.
| değer | zaman |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
Spark Akış API'sinde kullanılabilen kayan pencere işlevleri arasında window, countByWindow, reduceByWindow ve countByValueAndWindow bulunur. Bu işlevlerle ilgili ayrıntılar için bkz . DStreams'de Dönüşümler.
Kontrol noktası kaydetme
Spark Streaming, dayanıklılık ve hataya dayanıklılık sağlamak için, düğüm hataları karşısında bile akış işlemenin kesintisiz devam etmesini sağlamak için denetim noktalarına dayanır. Spark, dayanıklı depolama (Azure Depolama veya Data Lake Storage) için denetim noktaları oluşturur. Bu denetim noktaları, yapılandırma ve uygulama tarafından tanımlanan işlemler gibi akış uygulaması meta verilerini depolar. Ayrıca, kuyruğa alınmış ancak henüz işlenmemiş toplu işlemler. Bazen denetim noktaları, Spark tarafından yönetilen RDD'lerde bulunan verilerin durumunu daha hızlı bir şekilde yeniden oluşturmak amacıyla verileri RDD'lere kaydetmeyi de içerir.
Spark Streaming uygulamalarını dağıtma
Genellikle bir Spark Akış Uygulamasını yerel olarak bir JAR dosyası olarak oluşturursunuz. Ardından JAR dosyasını varsayılan ekli depolama alanına kopyalayarak HDInsight üzerinde Spark'a dağıtın. Post işlemi kullanarak uygulamanızı kümenizden edinebileceğiniz LIVY REST API'leriyle başlatabilirsiniz. POST'un gövdesi, JAR'ınızın yolunu sağlayan bir JSON belgesi içerir. Ana yöntemi akış uygulamasını tanımlayıp çalıştıran sınıfın adı ve isteğe bağlı olarak işin kaynak gereksinimleri (yürütücü sayısı, bellek ve çekirdek sayısı gibi). Ayrıca, uygulama kodunuzun gerektirdiği tüm yapılandırma ayarları.
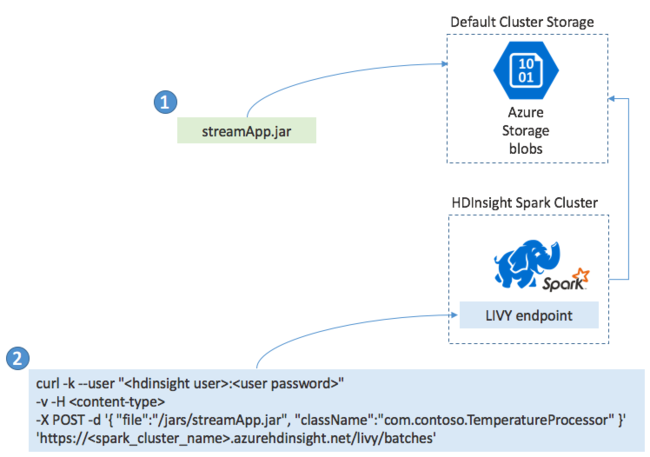
Tüm uygulamaların durumu, LIVY uç noktasına yönelik get isteğiyle de denetlenebilir. Son olarak, LIVY uç noktasına bir DELETE isteği vererek çalışan bir uygulamayı sonlandırabilirsiniz. LIVY API'siyle ilgili ayrıntılar için bkz Apache LIVY ile Uzak İşler