Etkileşimli geliştirme sırasında Azure bulut depolamasından verilere erişme
ŞUNLAR IÇIN GEÇERLIDIR:  Python SDK'sı azure-ai-ml v2 (geçerli)
Python SDK'sı azure-ai-ml v2 (geçerli)
Makine öğrenmesi projesi genellikle keşif veri analizi (EDA), veri ön işleme (temizleme, özellik mühendisliği) ile başlar ve hipotezleri doğrulamak için ML modellerinin prototiplerini oluşturur. Bu prototip oluşturma projesi aşaması doğası gereği oldukça etkileşimlidir ve kendisini bir Jupyter not defterinde veya Python etkileşimli konsoluna sahip bir IDE'de geliştirmeye ödünç verir. Bu makalede şunları nasıl yapacağınızı öğreneceksiniz:
- Azure Machine Learning Datastores URI'sinden bir dosya sistemiymiş gibi verilere erişin.
- Python kitaplığını kullanarak
mltableverileri Pandas'a dönüştürin. - Python kitaplığını kullanarak
mltableAzure Machine Learning veri varlıklarını Pandas'ta gerçekleştirme. - Yardımcı programıyla açık bir indirme yoluyla verileri gerçekleştirin
azcopy.
Ön koşullar
- Azure Machine Learning çalışma alanı. Daha fazla bilgi için bkz . Portalda veya Python SDK'sı (v2) ile Azure Machine Learning çalışma alanlarını yönetme.
- Azure Machine Learning Veri Deposu. Daha fazla bilgi için bkz . Veri depoları oluşturma.
Bahşiş
Bu makaledeki kılavuzda etkileşimli geliştirme sırasında veri erişimi açıklanmaktadır. Python oturumu çalıştırabilen tüm konaklar için geçerlidir. Bu, yerel makinenizi, bulut VM'nizi, GitHub Codespace'ı vb. içerebilir. Tam olarak yönetilen ve önceden yapılandırılmış bir bulut iş istasyonu olan Azure Machine Learning işlem örneği kullanmanızı öneririz. Daha fazla bilgi için bkz . Azure Machine Learning işlem örneği oluşturma.
Önemli
Python ortamınızda en son azure-fsspec ve mltable python kitaplıklarının yüklü olduğundan emin olun:
pip install -U azureml-fsspec mltable
Dosya sistemi gibi bir veri deposu URI'sinden verilere erişme
Azure Machine Learning veri deposu, mevcut bir Azure depolama hesabına başvurudur. Veri deposu oluşturmanın ve kullanmanın avantajları şunlardır:
- Farklı depolama türleriyle (Blob/Dosyalar/ADLS) etkileşime geçmek için yaygın, kullanımı kolay bir API.
- Ekip işlemlerinde kullanışlı veri depolarının kolay bulunması.
- Verilere erişmek için hem kimlik bilgisi tabanlı (örneğin SAS belirteci) hem de kimlik tabanlı (Microsoft Entra Id veya Manged identity kullanın) erişiminin destekleniyor.
- Kimlik bilgileri tabanlı erişim için bağlantı bilgileri, betiklerde anahtar kullanımını geçersiz kılmak için güvenli hale getirilir.
- Studio kullanıcı arabiriminde verilere göz atın ve veri deposu URI'lerini kopyalayıp yapıştırın.
Datastore URI'si, Azure depolama hesabınızdaki bir depolama konumuna (yol) başvuru olan Tekdüzen Kaynak Tanımlayıcısı'dır. Veri deposu URI'sinde şu biçim vardır:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Bu Datastore URI'leri, Dosya Sistemi belirtiminin (fsspec): yerel, uzak ve katıştırılmış dosya sistemlerine ve bayt depolamaya yönelik birleşik bir python arabiriminin bilinen bir uygulamasıdır.
Pip paketi ve bağımlılık azureml-dataprep paketini yükleyebilirsinizazureml-fsspec. Ardından Azure Machine Learning Veri Deposu fsspec uygulamasını kullanabilirsiniz.
Azure Machine Learning Veri Deposu uygulaması, Azure Machine Learning veri deposunun fsspec kullandığı kimlik bilgilerini/kimlik geçişini otomatik olarak işler. Bir işlem örneğinde hem betiklerinizde hesap anahtarı açığa çıkarma hem de ek oturum açma yordamları kullanmaktan kaçınabilirsiniz.
Örneğin, Pandas'ta Datastore URI'lerini doğrudan kullanabilirsiniz. Bu örnekte CSV dosyasının nasıl okunduğu gösterilmektedir:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Bahşiş
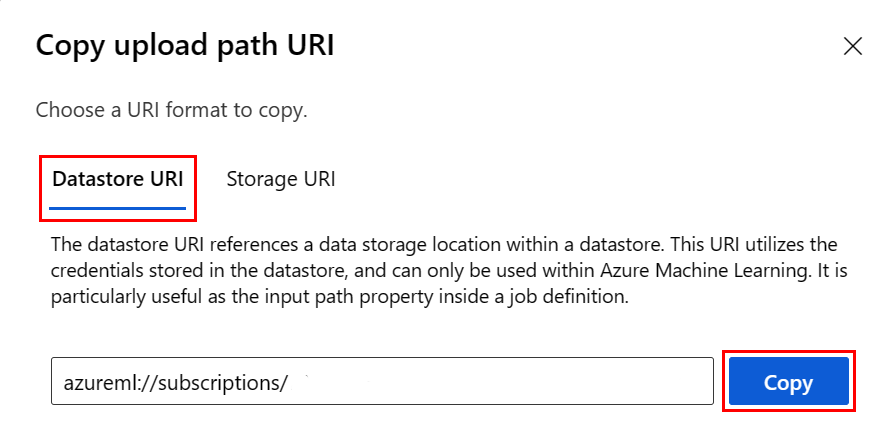
Veri deposu URI biçimini anımsamak yerine, aşağıdaki adımları izleyerek veri deposu URI'sini Studio kullanıcı arabiriminden kopyalayıp yapıştırabilirsiniz:
- Sol taraftaki menüden Veri'yi ve ardından Veri Depoları sekmesini seçin.
- Veri deposu adınızı ve ardından Gözat'ı seçin.
- Pandas'ta okumak istediğiniz dosyayı/klasörü bulun ve yanındaki üç noktayı (...) seçin. Menüden URI Kopyala'yı seçin. Not defterinize/betiğinize kopyalamak için Datastore URI'sini seçebilirsiniz.
Ayrıca, , opengibi dosya sistemi benzeri komutları existslsglobişlemek için bir Azure Machine Learning dosya sistemi örneği de oluşturabilirsiniz.
- yöntemi belirli
ls()bir dizindeki dosyaları listeler. Dosyaları listelemek için ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) kullanabilirsiniz. Göreli yollarda hem '.' hem de '..' destekliyoruz. - yöntemi '
glob()*' ve '**' globbing'i destekler. - yöntemi,
exists()belirtilen bir dosyanın geçerli kök dizinde var olup olmadığını gösteren bir Boole değeri döndürür. open()yöntemi, python dosyalarıyla çalışmayı bekleyen diğer tüm kitaplıklara geçirilebilen dosya benzeri bir nesne döndürür. Kodunuz, normal bir Python dosya nesnesiymiş gibi bu nesneyi de kullanabilir. Bu dosya benzeri nesneler, bu örnekte gösterildiği gibi bağlamlarınwithkullanımına saygı gösterir:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
AzureMachineLearningFileSystem aracılığıyla dosyaları karşıya yükleme
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath yerel yoldur ve rpath uzak yoldur.
Içinde belirttiğiniz rpath klasörler henüz yoksa, sizin için klasörleri oluştururuz.
Üç 'üzerine yazma' modunu destekliyoruz:
- APPEND: Hedef yolda aynı ada sahip bir dosya varsa, bu, özgün dosyayı korur
- FAIL_ON_FILE_CONFLICT: Hedef yolda aynı ada sahip bir dosya varsa, bu bir hata oluşturur
- MERGE_WITH_OVERWRITE: Hedef yolda aynı ada sahip bir dosya varsa, bu, var olan dosyanın üzerine yeni dosyayla yazar
AzureMachineLearningFileSystem aracılığıyla dosyaları indirme
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Örnekler
Bu örneklerde, yaygın senaryolarda dosya sistemi belirtimi kullanımının kullanımı gösterilmektedir.
Pandas'ta tek bir CSV dosyasını okuma
Pandas'ta gösterildiği gibi tek bir CSV dosyasını okuyabilirsiniz:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Csv dosyalarının bir klasörünü Pandas'a okuma
Pandas read_csv() yöntemi, CSV dosyalarının bir klasörünü okumayı desteklemez. Csv yollarını glob yapmalı ve Pandas concat() yöntemiyle bir veri çerçevesine birleştirmelisiniz. Sonraki kod örneğinde, Azure Machine Learning dosya sistemiyle bu birleştirmenin nasıl gerçekleştirilmesi gösterilmektedir:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
CSV dosyalarını Dask'a okuma
Bu örnekte CSV dosyasının Dask veri çerçevesine nasıl okunduğu gösterilmektedir:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Pandas'ta parquet dosyalarının bir klasörünü okuma
ETL işleminin bir parçası olarak Parquet dosyaları genellikle bir klasöre yazılır ve bu klasör daha sonra ilerleme, işlemeler vb. ETL ile ilgili dosyaları yayabilir. Bu örnekte, bir ETL işleminden oluşturulan dosyalar (ile _başlayan dosyalar) gösterilir ve bu dosyalar verilerden oluşan bir parquet dosyası oluşturur.
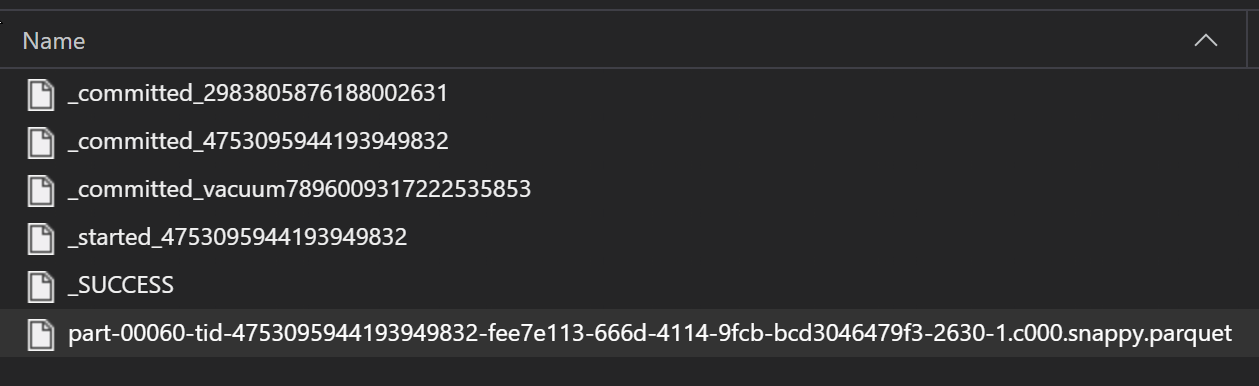
Bu senaryolarda, klasördeki parquet dosyalarını yalnızca okuyacak ve ETL işlem dosyalarını yoksayacaksınız. Bu kod örneği, glob desenlerinin bir klasördeki yalnızca parquet dosyalarını nasıl okuyabildiğini gösterir:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Azure Databricks dosya sisteminizden verilere erişme (dbfs)
Dosya sistemi belirtimi (fsspec), Databricks Dosya Sistemi () dahil olmak üzere bilinen bir dizi uygulamaya sahiptirdbfs.
Verilerinize dbfs erişmek için aşağıdakiler gerekir:
- Örnek adı biçimindedir
adb-<some-number>.<two digits>.azuredatabricks.net. Bu değeri Azure Databricks çalışma alanınızın URL'sinde bulabilirsiniz. - Kişisel Erişim Belirteci (PAT); PAT oluşturma hakkında daha fazla bilgi için bkz. Azure Databricks kişisel erişim belirteçlerini kullanarak kimlik doğrulaması
Bu değerlerle, PAT belirteci için işlem örneğinizde bir ortam değişkeni oluşturmanız gerekir:
export ADB_PAT=<pat_token>
Bu örnekte gösterildiği gibi Pandas'taki verilere erişebilirsiniz:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Ile resim okuma pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
PyTorch özel veri kümesi örneği
Bu örnekte, görüntüleri işlemek için bir PyTorch özel veri kümesi oluşturacaksınız. Şu genel yapıya sahip bir ek açıklama dosyası (CSV biçiminde) olduğunu varsayıyoruz:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Alt klasörler bu görüntüleri etiketlerine göre depolar:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Özel bir PyTorch Veri Kümesi sınıfı, burada gösterildiği gibi , __len__ve __getitem__olmak üzere üç işlev __init__uygulamalıdır:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
Ardından burada gösterildiği gibi veri kümesinin örneğini oluşturabilirsiniz:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Kitaplığı kullanarak mltable verileri Pandas'a dönüştürme
Kitaplık, mltable bulut depolamadaki verilere erişmeye de yardımcı olabilir. Pandas'a mltable veri okuma şu genel biçime sahiptir:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Desteklenen yollar
Kitaplık, mltable farklı yol türlerinden tablosal verilerin okunmasını destekler:
| Konum | Örnekler |
|---|---|
| Yerel bilgisayarınızdaki bir yol | ./home/username/data/my_data |
| Ortak http(ler) sunucusundaki yol | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure Depolama'da yol | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Uzun formlu bir Azure Machine Learning veri deposu | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Dekont
mltableAzure Depolama ve Azure Machine Learning veri depolarında yollar için kullanıcı kimlik bilgisi geçişi yapar. Temel alınan depolamadaki verilere erişme izniniz yoksa verilere erişemezsiniz.
Dosyalar, klasörler ve globlar
mltable şu kaynaklardan okumayı destekler:
- dosyalar - örneğin:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - klasör - örneğin
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - glob desenleri - örneğin
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - dosya, klasör ve/veya globbing desenlerinin birleşimi
mltable esneklik, yerel ve bulut depolama kaynaklarının bir bileşiminden ve dosya/klasör/glob birleşimlerinden tek bir veri çerçevesi halinde veri gerçekleştirmeye olanak tanır. Örnek:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Desteklenen dosya biçimleri
mltable aşağıdaki dosya biçimlerini destekler:
- Sınırlandırılmış Metin (örneğin: CSV dosyaları):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - JSON çizgileri biçimi:
mltable.from_json_lines_files(paths=[path])
Örnekler
CSV dosyasını okuma
Bu kod parçacığındaki yer tutucuları (<>) belirli ayrıntılarınızla güncelleştirin:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Klasördeki parquet dosyalarını okuma
Bu örnekte, yalnızca parquet dosyalarının okunmasını sağlamak için joker karakterler gibi glob desenlerinin nasıl mltable kullanılacağı gösterilmektedir.
Bu kod parçacığındaki yer tutucuları (<>) belirli ayrıntılarınızla güncelleştirin:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Veri varlıklarını okuma
Bu bölümde, Pandas'taki Azure Machine Learning veri varlıklarınıza nasıl erişin olduğu gösterilmektedir.
Tablo varlığı
Daha önce Azure Machine Learning'de bir tablo varlığı (bir mltableveya V1 TabularDataset) oluşturduysanız, şu kodla bu tablo varlığını Pandas'a yükleyebilirsiniz:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Dosya varlığı
Bir dosya varlığı (örneğin csv dosyası) kaydettiyseniz, bu varlığı şu kodla pandas veri çerçevesinde okuyabilirsiniz:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Klasör varlığı
Örneğin, CSV dosyası içeren bir klasör gibi bir klasör varlığı (uri_folder veya V1 FileDataset) kaydettiyseniz, bu varlığı şu kodla pandas veri çerçevesine okuyabilirsiniz:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Pandas ile büyük veri hacimlerini okuma ve işleme hakkında bir not
Bahşiş
Pandas, büyük veri kümelerini işlemek için tasarlanmamıştır. Pandas yalnızca işlem örneğinin belleğine sığabilecek verileri işleyebilir.
Büyük veri kümeleri için Azure Machine Learning tarafından yönetilen Spark kullanılmasını öneririz. Bu, PySpark Pandas API'sini sağlar.
Uzak zaman uyumsuz bir işe ölçeklendirmeden önce büyük bir veri kümesinin daha küçük bir alt kümesinde hızla yineleme yapmak isteyebilirsiniz. mltabletake_random_sample yöntemini kullanarak büyük veri örnekleri almak için yerleşik işlevsellik sağlar:
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
Bu işlemlerle büyük verilerin alt kümelerini de alabilirsiniz:
Yardımcı programını kullanarak azcopy verileri indirme
azcopy Yardımcı programını kullanarak verileri ana bilgisayarınızın yerel SSD'sine (yerel makine, bulut VM, Azure Machine Learning İşlem Örneği) yerel dosya sistemine indirin. azcopy Azure Machine Learning işlem örneğine önceden yüklenmiş olan yardımcı programı bunu halleder. Azure Machine Learning işlem örneği veya Veri Bilimi Sanal Makinesi (DSVM) kullanmıyorsanız yüklemeniz azcopygerekebilir. Daha fazla bilgi için bkz . azcopy .
Dikkat
İşlem örneğindeki konuma veri indirmelerini /home/azureuser/cloudfiles/code önermeyiz. Bu konum, verileri değil not defterini ve kod yapıtlarını depolamak için tasarlanmıştır. Bu konumdan veri okumak, eğitim sırasında önemli bir performans yükü doğuracaktır. Bunun yerine, işlem düğümünün home/azureuseryerel SSD'si olan içindeki veri depolamasını öneririz.
Bir terminal açın ve yeni bir dizin oluşturun, örneğin:
mkdir /home/azureuser/data
Aşağıdakini kullanarak azcopy'de oturum açın:
azcopy login
Ardından, depolama URI'sini kullanarak verileri kopyalayabilirsiniz
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST