Görüntü işleme modellerini eğitmek için AutoML'yi ayarlama
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Bu makalede, otomatik ML ile görüntü verileri üzerinde görüntü işleme modellerini eğitmeyi öğreneceksiniz. Azure Machine Learning CLI uzantısı v2 veya Azure Machine Learning Python SDK v2'yi kullanarak modelleri eğitebilirsiniz.
Otomatikleştirilmiş ML, görüntü sınıflandırma, nesne algılama ve örnek kesimleme gibi görüntü işleme görevleri için model eğitimini destekler. Görüntü işleme görevleri için AutoML modelleri yazma, şu anda Azure Machine Learning Python SDK aracılığıyla desteklenmektedir. Sonuçta elde edilen deneme denemelerine, modellere ve çıkışlara Azure Machine Learning stüdyosu kullanıcı arabiriminden erişilebilir. Görüntü verilerinde görüntü işleme görevleri için otomatik ml hakkında daha fazla bilgi edinin.
Önkoşullar
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
- Azure Machine Learning çalışma alanı. Çalışma alanını oluşturmak için bkz . Çalışma alanı kaynakları oluşturma.
- CLI'yı (v2) yükleyip ayarlayın ve uzantıyı yüklediğinizden
mlemin olun.
Görev türünüzü seçin
Görüntüler için otomatik ML aşağıdaki görev türlerini destekler:
| Görev türü | AutoML İşi söz dizimi |
|---|---|
| görüntü sınıflandırması | CLI v2: image_classification SDK v2: image_classification() |
| görüntü sınıflandırması çok etiketli | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| görüntü nesnesi algılama | CLI v2: image_object_detection SDK v2: image_object_detection() |
| görüntü örneği segmentasyonu | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
Bu görev türü gerekli bir parametredir ve anahtarı kullanılarak task ayarlanabilir.
Örneğin:
task: image_object_detection
Eğitim ve doğrulama verileri
Görüntü işleme modelleri oluşturmak için, model eğitimi için giriş olarak etiketlenmiş görüntü verilerini biçiminde MLTablegetirmeniz gerekir. Eğitim verilerinden JSONL biçiminde bir MLTable oluşturabilirsiniz.
Eğitim verileriniz farklı bir biçimdeyse (pascal VOC veya COCO gibi), verileri JSONL'ye dönüştürmek için örnek not defterlerine dahil edilen yardımcı betikleri uygulayabilirsiniz. Otomatik ML ile görüntü işleme görevleri için verileri hazırlama hakkında daha fazla bilgi edinin.
Not
AutoML işi gönderebilmek için eğitim verilerinin en az 10 görüntüsü olmalıdır.
Uyarı
MLTable Bu özellik için yalnızca SDK ve CLI kullanılarak JSONL biçiminde veri oluşturulması desteklenir. MLTable Kullanıcı arabirimi aracılığıyla oluşturma şu anda desteklenmiyor.
JSONL şema örnekleri
TabularDataset'in yapısı, eldeki göreve bağlıdır. Görüntü işleme görev türleri için aşağıdaki alanlardan oluşur:
| Alan | Açıklama |
|---|---|
image_url |
StreamInfo nesnesi olarak dosya yolu içerir |
image_details |
Görüntü meta verileri bilgileri yükseklik, genişlik ve biçimden oluşur. Bu alan isteğe bağlıdır ve bu nedenle mevcut olabilir veya olmayabilir. |
label |
Görev türüne göre resim etiketinin json gösterimi. |
Aşağıdaki kod, görüntü sınıflandırması için örnek bir JSONL dosyasıdır:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Aşağıdaki kod, nesne algılama için örnek bir JSONL dosyasıdır:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Verileri kullanma
Verileriniz JSONL biçiminde olduğunda, aşağıda gösterildiği gibi eğitim ve doğrulama MLTable oluşturabilirsiniz.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Otomatik ML, görüntü işleme görevleri için eğitim veya doğrulama veri boyutuna herhangi bir kısıtlama getirmez. Maksimum veri kümesi boyutu yalnızca veri kümesinin arkasındaki depolama katmanıyla sınırlıdır (Örnek: blob deposu). En az sayıda resim veya etiket yoktur. Ancak çıkış modelinin yeterince eğitildiğinden emin olmak için etiket başına en az 10-15 örnekle başlamanızı öneririz. Toplam etiket/sınıf sayısı ne kadar yüksekse etiket başına o kadar fazla örneğe ihtiyacınız olur.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
Eğitim verileri gerekli bir parametredir ve anahtarı kullanılarak training_data geçirilir. İsteğe bağlı olarak anahtarla validation_data doğrulama verileri olarak başka bir MLtable belirtebilirsiniz. Doğrulama verileri belirtilmezse, bağımsız değişkeni farklı bir değerle geçirmediğiniz validation_data_size sürece eğitim verilerinizin %20'si varsayılan olarak doğrulama için kullanılır.
Hedef sütun adı gerekli bir parametredir ve denetimli ML görevi için hedef olarak kullanılır. Anahtarı kullanılarak geçirilir target_column_name . Örneğin,
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Deneme çalıştırmak için işlem
Model eğitimi gerçekleştirmek için otomatik ML için bir işlem hedefi sağlayın. Görüntü işleme görevleri için otomatik ML modelleri GPU SKU'ları gerektirir ve NC ile ND ailelerini destekler. Daha hızlı eğitim için NCsv3 serisini (v100 GPU ile) öneririz. Çok GPU'lu VM SKU'su olan bir işlem hedefi, eğitimi hızlandırmak için birden çok GPU kullanır. Ayrıca, birden çok düğüme sahip bir işlem hedefi ayarladığınızda, modeliniz için hiper parametreleri ayarlarken paralellik aracılığıyla daha hızlı model eğitimi gerçekleştirebilirsiniz.
Not
İşlem hedefiniz olarak bir işlem örneği kullanıyorsanız, birden çok AutoML işinin aynı anda çalıştırılmadığından emin olun. Ayrıca, iş sınırlarınızda bunun max_concurrent_trials 1 olarak ayarlandığından emin olun.
İşlem hedefi parametresi kullanılarak compute geçirilir. Örnek:
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
compute: azureml:gpu-cluster
Denemeleri yapılandırma
Görüntü işleme görevleri için tek tek denemeler, el ile süpürmeler veya otomatik süpürmeler başlatabilirsiniz. İlk taban çizgisi modelini almak için otomatik süpürme ile başlamanızı öneririz. Ardından, belirli modeller ve hiper parametre yapılandırmalarıyla tek tek denemeleri deneyebilirsiniz. Son olarak, el ile yapılan süpürmelerle, daha umut verici modellerin ve hiper parametre yapılandırmalarının yakınında birden çok hiper parametre değerini keşfedebilirsiniz. Bu üç adımlı iş akışı (otomatik süpürme, bireysel denemeler, el ile süpürmeler) hiper parametre alanının tamamında arama yapmaktan kaçınarak hiper parametre sayısında katlanarak artar.
Otomatik süpürmeler birçok veri kümesi için rekabetçi sonuçlar verebilir. Ayrıca, model mimarileri hakkında gelişmiş bilgi gerektirmezler, hiper parametre bağıntılarını dikkate alır ve farklı donanım kurulumlarında sorunsuz çalışırlar. Tüm bu nedenler, bunları deneme sürecinizin ilk aşaması için güçlü bir seçenek haline getirir.
Birincil ölçüm
AutoML eğitim işi, model iyileştirme ve hiper parametre ayarlama için birincil ölçümü kullanır. Birincil ölçüm aşağıda gösterildiği gibi görev türüne bağlıdır; diğer birincil ölçüm değerleri şu anda desteklenmemektedir.
- Görüntü sınıflandırma doğruluğu
- Görüntü sınıflandırma multilabel için birleşim üzerinde kesişim
- Görüntü nesnesi algılama için ortalama ortalama duyarlık
- Görüntü örneği segmentasyonu için ortalama ortalama duyarlık
İş sınırları
AutoML Görüntü eğitim işinizde harcanan kaynakları, aşağıdaki örnekte açıklandığı gibi sınır ayarlarında ve iş için belirterek timeout_minutesmax_trials max_concurrent_trials denetleyebilirsiniz.
| Parametre | Ayrıntı |
|---|---|
max_trials |
Süpürme için en fazla deneme sayısı parametresi. 1 ile 1000 arasında bir tamsayı olmalıdır. Belirli bir model mimarisi için yalnızca varsayılan hiper parametreleri keşfederken bu parametreyi 1 olarak ayarlayın. Varsayılan değer 1 şeklindedir. |
max_concurrent_trials |
Eşzamanlı olarak çalışabilecek en fazla deneme sayısı. Belirtilirse, 1 ile 100 arasında bir tamsayı olmalıdır. Varsayılan değer 1 şeklindedir. NOT: max_concurrent_trials dahili olarak eşlenir max_trials . Örneğin, kullanıcı ayarlarsamax_concurrent_trials=4max_trials=2, değerler dahili olarak max_concurrent_trials=2olarak max_trials=2güncelleştirilir. |
timeout_minutes |
Denemenin sona ermesi için dakika cinsinden süre. Belirtilmemişse, varsayılan deneme timeout_minutes yedi gündür (en fazla 60 gün) |
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Model hiper parametreleri otomatik olarak süpürme (AutoMode)
Önemli
Bu özellik şu anda genel önizlemededir. Bu önizleme sürümü hizmet düzeyi sözleşmesi olmadan sağlanır. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir. Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
Bir veri kümesi için en iyi model mimarisini ve hiper parametreleri tahmin etmek zordur. Ayrıca bazı durumlarda hiper parametreleri ayarlamak için ayrılan insan süresi sınırlı olabilir. Görüntü işleme görevleri için istediğiniz sayıda deneme belirtebilirsiniz ve sistem süpürme için hiper parametre alanının bölgesini otomatik olarak belirler. Hiper parametre arama alanı, örnekleme yöntemi veya erken sonlandırma ilkesi tanımlamanız gerekmez.
AutoMode'un tetiklenmesi
içinde 1'den limits büyük bir değere ayarlayıp max_trials arama alanını, örnekleme yöntemini ve sonlandırma ilkesini belirtmeyerek otomatik süpürme çalıştırabilirsiniz. Bu işlevi AutoMode olarak adlandırıyoruz; lütfen aşağıdaki örne bakın.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
limits:
max_trials: 10
max_concurrent_trials: 2
10 ile 20 arasında bir dizi deneme, büyük olasılıkla birçok veri kümesinde iyi sonuç verir. AutoML işinin zaman bütçesi yine de ayarlanabilir, ancak bunu yalnızca her denemenin uzun sürmesi durumunda yapmanızı öneririz.
Uyarı
Kullanıcı arabirimi aracılığıyla otomatik süpürme başlatma şu anda desteklenmiyor.
Bireysel denemeler
Tek tek denemelerde, model mimarisini ve hiper parametreleri doğrudan denetlersiniz. Model mimarisi parametresi aracılığıyla model_name geçirilir.
Desteklenen model mimarileri
Aşağıdaki tabloda, her görüntü işleme görevi için desteklenen eski modeller özetlenmektedir. Yalnızca bu eski modellerin kullanılması, eski çalışma zamanını kullanarak çalıştırmaları tetikler (her bir çalıştırma veya deneme sürümü bir komut işi olarak gönderilir). HuggingFace ve MMDetection desteği için lütfen aşağıya bakın.
| Görev | model mimarileri | Dize değişmez değer söz dizimidefault_model* * ile belirtilir |
|---|---|---|
| Resim sınıflandırması (çok sınıflı ve çok etiketli) |
MobileNet: Mobil uygulamalar için hafif modeller ResNet: Artık ağlar ResNeSt: Dikkat ağlarını bölme SE-ResNeXt50: Sıkma ve Uyarma ağları ViT: Görüntü transformatör ağları |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (küçük) vitb16r224* (taban) vitl16r224 (büyük) |
| Nesne algılama | YOLOv5: Bir aşamalı nesne algılama modeli Daha hızlı RCNN ResNet FPN: İki aşamalı nesne algılama modeli RetinaNet ResNet FPN: Odak Kaybı ile adres sınıfı dengesizliği Not: YOLOv5 model boyutları için hiper parametreye bakın model_size. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Örneği segmentlere ayırma | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Desteklenen model mimarileri - HuggingFace ve MMDetection (önizleme)
Azure Machine Learning işlem hatlarında çalışan yeni arka uçla, transformatör kitaplığının parçası olan HuggingFace Hub'daki herhangi bir görüntü sınıflandırma modelini (microsoft/beit-base-patch16-224 gibi) ve MMDetection Sürüm 3.1.0 Model Hayvanat Bahçesi'nden (örneğinatss_r50_fpn_1x_coco) herhangi bir nesne algılama veya örnek segmentasyonu modelini kullanabilirsiniz.
HuggingFace Transfomers ve MMDetection 3.1.0 modellerini desteklemenin yanı sıra azureml kayıt defterindeki bu kitaplıklardan seçilen modellerin listesini de sunuyoruz. Bu seçilmiş modeller kapsamlı bir şekilde test edilmiştir ve etkili bir eğitim sağlamak için kapsamlı karşılaştırmadan seçilen varsayılan hiper parametreleri kullanır. Aşağıdaki tabloda bu seçilmiş modeller özetlenmiştir.
| Görev | model mimarileri | Dize değişmez değer söz dizimi |
|---|---|---|
| Resim sınıflandırması (çok sınıflı ve çok etiketli) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Nesne Algılama | Seyrek R-CNN Deforme Edilebilir DETR VFNet YOLOF Swin |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Örnek Segmentasyonu | Swin | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Seçilen modellerin listesini sürekli güncelleştiriyoruz. Python SDK'sını kullanarak belirli bir görev için seçilen modellerin en güncel listesini alabilirsiniz:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Çıktı:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Herhangi bir HuggingFace veya MMDetection modeli kullanıldığında işlem hattı bileşenleri kullanılarak çalıştırmalar tetiklenir. Hem eski hem de HuggingFace/MMdetection modelleri kullanılıyorsa, tüm çalıştırmalar/denemeler bileşenler kullanılarak tetiklenir.
Model mimarisini denetlemeye ek olarak, model eğitimi için kullanılan hiper parametreleri de ayarlayabilirsiniz. Kullanıma sunulan hiper parametrelerin çoğu modelden bağımsız olsa da hiper parametrelerin göreve veya modele özgü olduğu örnekler vardır. Bu örnekler için kullanılabilir hiper parametreler hakkında daha fazla bilgi edinin.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
Belirli bir mimari için varsayılan hiper parametre değerlerini kullanmak istiyorsanız (örneğin yolov5), training_parameters bölümündeki model_name anahtarını kullanarak bunu belirtebilirsiniz. Örneğin,
training_parameters:
model_name: yolov5
Model hiper parametreleri el ile süpürme
Görüntü işleme modellerini eğitirken, model performansı büyük ölçüde seçilen hiper parametre değerlerine bağlıdır. Çoğu zaman, en iyi performansı elde etmek için hiper parametreleri ayarlamak isteyebilirsiniz. Görüntü işleme görevleri için hiper parametreleri süpürerek modeliniz için en uygun ayarları bulabilirsiniz. Bu özellik, Azure Machine Learning'deki hiper parametre ayarlama özelliklerini uygular. Hiper parametreleri ayarlamayı öğrenin.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Parametre arama alanını tanımlama
Parametre alanını süpürmek için model mimarilerini ve hiper parametreleri tanımlayabilirsiniz. Tek bir model mimarisi veya birden çok mimari belirtebilirsiniz.
- Her görev türü için desteklenen model mimarilerinin listesi için bkz . Bireysel denemeler .
- Bkz. Her görüntü işleme görev türü için görüntü işleme görevleri hiper parametreleri için hiper parametreler.
- Ayrık ve sürekli hiper parametreler için desteklenen dağıtımlarla ilgili ayrıntılara bakın.
Süpürme için örnekleme yöntemleri
Hiper parametreleri süpürürken, tanımlanan parametre alanını süpürmek için kullanılacak örnekleme yöntemini belirtmeniz gerekir. Şu anda parametresiyle sampling_algorithm aşağıdaki örnekleme yöntemleri desteklenmektedir:
| Örnekleme türü | AutoML İşi söz dizimi |
|---|---|
| Rastgele Örnekleme | random |
| Kılavuz Örnekleme | grid |
| Bayes örneklemesi | bayesian |
Not
Şu anda yalnızca rastgele ve kılavuz örnekleme koşullu hiper parametre alanlarını destekler.
Erken sonlandırma ilkeleri
Kötü performans gösteren denemeleri otomatik olarak erken sonlandırma ilkesiyle sonlandırabilirsiniz. Erken sonlandırma işlem verimliliğini artırarak daha az umut verici denemelere harcanabilecek işlem kaynaklarının tasarrufunu sağlar. Görüntüler için otomatik ML, parametresini early_termination kullanarak aşağıdaki erken sonlandırma ilkelerini destekler. Sonlandırma ilkesi belirtilmezse, tüm denemeler tamamlanmak üzere çalıştırılır.
| Erken sonlandırma ilkesi | AutoML İşi söz dizimi |
|---|---|
| Eşkıya ilkesi | CLI v2: bandit SDK v2: BanditPolicy() |
| Ortanca durdurma ilkesi | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Kesme seçimi ilkesi | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
Hiper parametre taramanız için erken sonlandırma ilkesini yapılandırma hakkında daha fazla bilgi edinin.
Not
Eksiksiz bir süpürme yapılandırma örneği için lütfen bu öğreticiye bakın.
Aşağıdaki örnekte gösterildiği gibi süpürmeyle ilgili tüm parametreleri yapılandırabilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Sabit ayarlar
Aşağıdaki örnekte gösterildiği gibi parametre alanı süpürme sırasında değişmeyen sabit ayarları veya parametreleri geçirebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Veri artırma
Genel olarak derin öğrenme modeli performansı genellikle daha fazla veriyle iyileştirebilir. Veri artırma, veri kümesinin veri boyutunu ve değişkenliğini artırmaya yönelik pratik bir tekniktir. Bu teknik, fazla uygunluğu önlemeye ve modelin görünmeyen verilerde genelleştirme özelliğini geliştirmeye yardımcı olur. Otomatik ML, modele giriş görüntüleri beslemeden önce görüntü işleme görevine göre farklı veri artırma teknikleri uygular. Şu anda veri büyütme işlemlerini denetlemek için kullanıma sunulan bir hiper parametre yoktur.
| Görev | Etkilenen veri kümesi | Uygulanan veri artırma teknikleri |
|---|---|---|
| Görüntü sınıflandırması (çok sınıflı ve çok etiketli) | Antrenman Doğrulama ve Test |
Rastgele yeniden boyutlandırma ve kırpma, yatay çevirme, renk dalgalanması (parlaklık, karşıtlık, doygunluk ve ton), kanal açısından ImageNet'in ortalama ve standart sapması kullanılarak normalleştirme Kırpmayı yeniden boyutlandırma, ortalama, normalleştirme |
| Nesne algılama, örnek segmentasyonu | Antrenman Doğrulama ve Test |
Sınırlayıcı kutuların çevresinde rastgele kırpma, genişletme, yatay çevirme, normalleştirme, yeniden boyutlandırma Normalleştirme, yeniden boyutlandırma |
| Yolov5 kullanarak nesne algılama | Antrenman Doğrulama ve Test |
Mozaik, rastgele afin (döndürme, çeviri, ölçek, kesme), yatay çevirme Letterbox yeniden boyutlandırma |
Şu anda yukarıda tanımlanan artırmalar, görüntü işi için Otomatik ML için varsayılan olarak uygulanır. Büyütmeler üzerinde denetim sağlamak amacıyla görüntüler için otomatik ML, belirli büyütmeleri kapatmak için iki bayrağın altında yer alır. Şu anda bu bayraklar yalnızca nesne algılama ve örnek segmentasyon görevleri için desteklenmektedir.
- apply_mosaic_for_yolo: Bu bayrak yalnızca Yolo modeline özgüdür. False olarak ayarlandığında, eğitim zamanında uygulanan mozaik veri artırma özelliği kapatılır.
- apply_automl_train_augmentations: Bu bayrağı false olarak ayarlamak, nesne algılama ve örnek segmentasyonu modelleri için eğitim süresince uygulanan artırmayı kapatır. Artırmalar için yukarıdaki tabloda yer alan ayrıntılara bakın.
- olmayan nesne algılama modeli ve örnek segmentasyonu modelleri için bu bayrak yalnızca ilk üç artırmayı kapatır. Örneğin: Sınırlayıcı kutuların çevresinde rastgele kırpma, genişletme, yatay çevirme. Bu bayrak ne olursa olsun, normalleştirme ve yeniden boyutlandırma artırmaları uygulanmaya devam eder.
- Yolo modeli için bu bayrak rastgele benek ve yatay çevirme büyütmelerini kapatır.
Bu iki bayrak, training_parameters altında advanced_settings aracılığıyla desteklenir ve aşağıdaki şekilde denetlenebilir.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Bu iki bayrağın birbirinden bağımsız olduğunu ve aşağıdaki ayarlar kullanılarak birlikte de kullanılabildiğini unutmayın.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
Denemelerimizde bu büyütmelerin modelin daha iyi genelleştirilmesine yardımcı olduğunu bulduk. Bu nedenle, bu artırmalar kapatıldığında, kullanıcıların daha iyi sonuçlar elde etmek için bunları diğer çevrimdışı artırmalarla birleştirmelerini öneririz.
Artımlı eğitim (isteğe bağlı)
Eğitim işi tamamlandıktan sonra eğitilen model denetim noktasını yükleyerek modeli daha fazla eğitmeyi seçebilirsiniz. Artımlı eğitim için aynı veri kümesini veya farklı bir veri kümesini kullanabilirsiniz. Modelden memnunsanız eğitimi durdurmayı ve geçerli modeli kullanmayı seçebilirsiniz.
Denetim noktasını iş kimliği aracılığıyla geçirme
Denetim noktasını yüklemek istediğiniz iş kimliğini geçirebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
AutoML işini gönderme
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
AutoML işinizi göndermek için .yml dosyanızın, çalışma alanı adınızın, kaynak grubunuzun ve abonelik kimliğinizin yolunu içeren aşağıdaki CLI v2 komutunu çalıştırırsınız.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Çıkışlar ve değerlendirme ölçümleri
Otomatik ML eğitim işleri, puanlama dosyası ve ortam dosyası gibi çıkış modeli dosyaları, değerlendirme ölçümleri, günlükler ve dağıtım yapıtları oluşturur. Bu dosyalar ve ölçümler, alt işlerin çıkışlar, günlükler ve ölçümler sekmesinden görüntülenebilir.
Her iş için sağlanan performans grafiklerinin ve ölçümlerin tanımları ve örnekleri için bkz . Otomatik makine öğrenmesi denemesi sonuçlarını değerlendirme.
Modeli kaydetme ve dağıtma
İş tamamlandıktan sonra, en iyi deneme sürümünden oluşturulan modeli kaydedebilirsiniz (en iyi birincil ölçümle sonuçlanan yapılandırma). modeli indirdikten sonra veya ilgili jobid ile azureml yolunu belirterek kaydedebilirsiniz. Not: Aşağıda açıklanan çıkarım ayarlarını değiştirmek istediğinizde modeli indirmeniz, settings.json değiştirmeniz ve güncelleştirilmiş model klasörünü kullanarak kaydolmanız gerekir.
En iyi deneme sürümünü edinin
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
CLI example not available, please use Python SDK.
modeli kaydetme
Azureml yolunu veya yerel olarak indirdiğiniz yolu kullanarak modeli kaydedin.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Kullanmak istediğiniz modeli kaydettikten sonra yönetilen çevrimiçi uç nokta deploy-managed-online-endpoint kullanarak dağıtabilirsiniz
Çevrimiçi uç noktayı yapılandırma
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Uç noktayı oluşturma
Daha önce oluşturulan öğesini MLClient kullanarak çalışma alanında Uç Nokta'yı oluştururuz. Bu komut uç nokta oluşturmayı başlatır ve uç nokta oluşturma işlemi devam ederken bir onay yanıtı döndürür.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Çevrimiçi dağıtımı yapılandırma
Dağıtım, gerçek çıkarım yapan modeli barındırmak için gereken bir kaynak kümesidir. sınıfını ManagedOnlineDeployment kullanarak uç noktamız için bir dağıtım oluşturacağız. Dağıtım kümeniz için GPU veya CPU VM SKU'larını kullanabilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Dağıtımı oluşturma
Daha önce oluşturulan öğesini MLClient kullanarak şimdi dağıtımı çalışma alanında oluşturacağız. Bu komut dağıtım oluşturma işlemini başlatır ve dağıtım oluşturma işlemi devam ederken bir onay yanıtı döndürür.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
güncelleştirme trafiği:
Varsayılan olarak geçerli dağıtım %0 trafik alacak şekilde ayarlanmıştır. geçerli dağıtımın alması gereken trafik yüzdesini ayarlayabilirsiniz. Tek uç noktası olan tüm dağıtımların trafik yüzdelerinin toplamı %100'ü aşmamalıdır.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Alternatif olarak modeli Azure Machine Learning stüdyosu kullanıcı arabiriminden dağıtabilirsiniz. Otomatik ML işinin Modeller sekmesinde dağıtmak istediğiniz modele gidin ve Dağıt'ı seçip Gerçek zamanlı uç noktaya dağıt'ı seçin.
 .
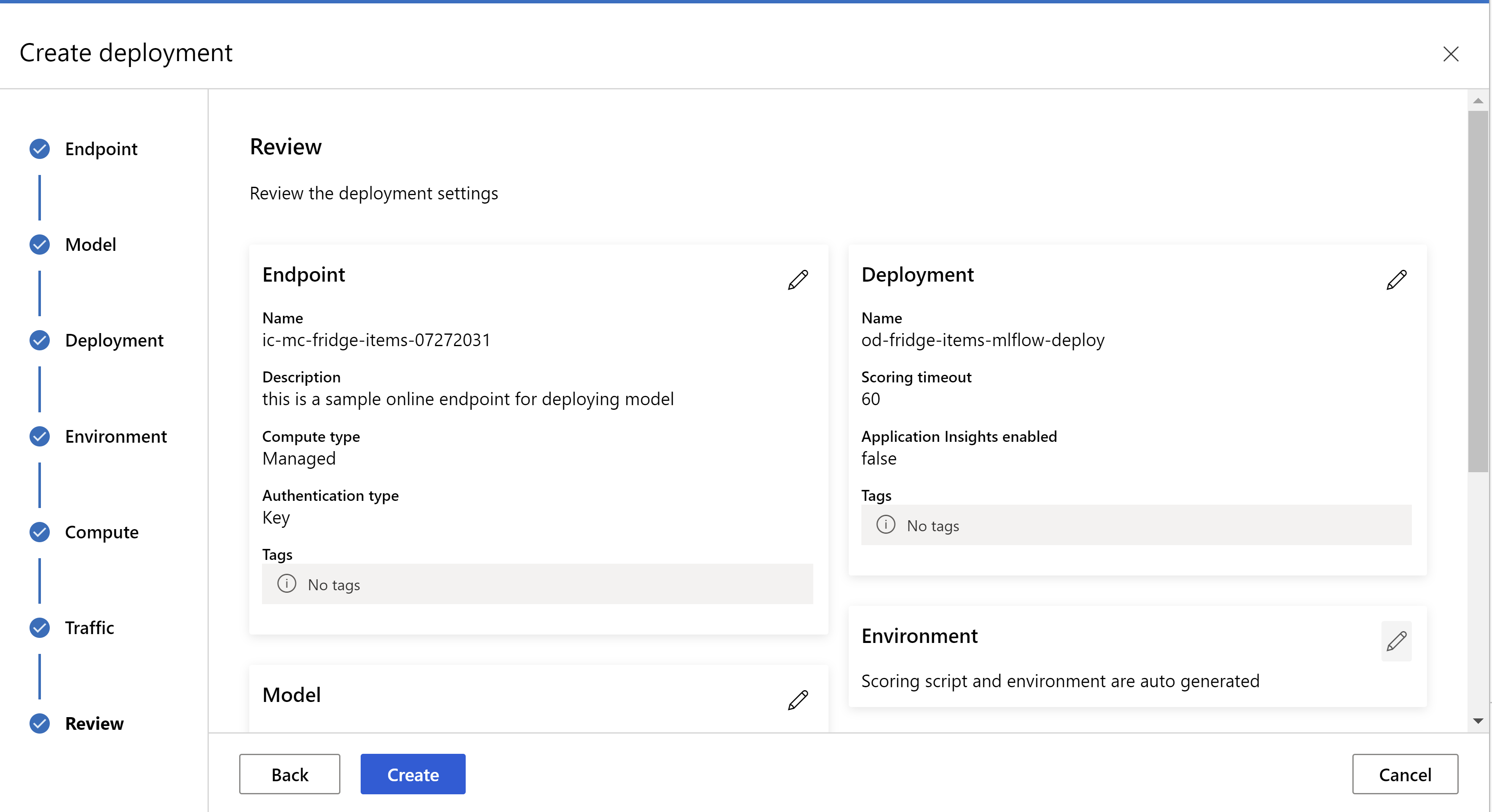
.
gözden geçirme sayfanız böyle görünür. örnek türünü, örnek sayısını seçebilir ve geçerli dağıtım için trafik yüzdesini ayarlayabiliriz.
 .
.
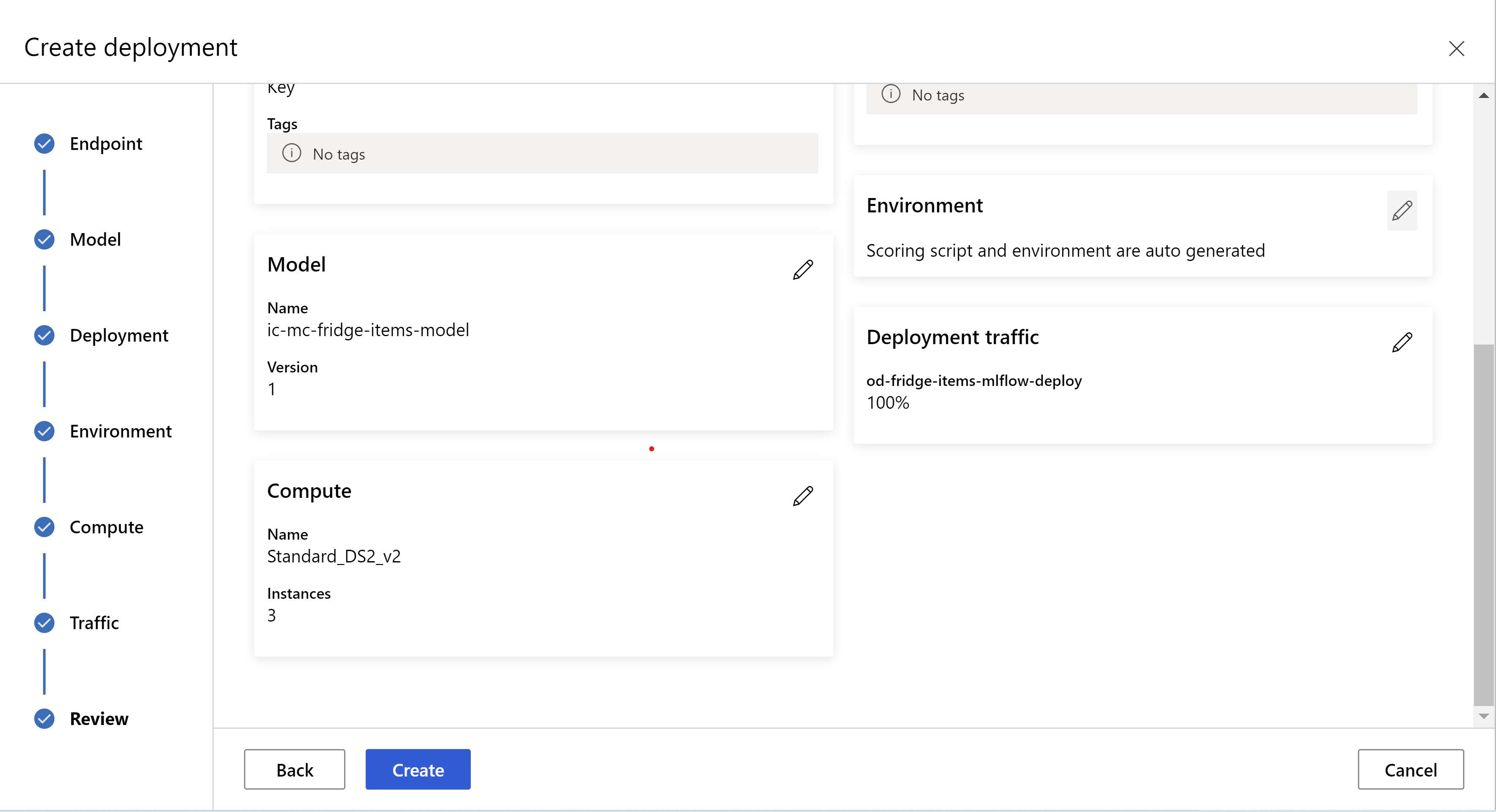 .
.
Çıkarım ayarlarını güncelleştirme
Önceki adımda en iyi modelden bir dosya mlflow-model/artifacts/settings.json indirdik. modeli kaydetmeden önce çıkarım ayarlarını güncelleştirmek için kullanılabilir. En iyi performans için eğitimle aynı parametrelerin kullanılması önerilir.
Görevlerin (ve bazı modellerin) her biri bir parametre kümesine sahiptir. Varsayılan olarak, eğitim ve doğrulama sırasında kullanılan parametreler için aynı değerleri kullanırız. Modeli çıkarım için kullanırken ihtiyacımız olan davranışa bağlı olarak, bu parametreleri değiştirebiliriz. Aşağıda her görev türü ve modeli için parametrelerin listesini bulabilirsiniz.
| Görev | Parametre adı | Varsayılan |
|---|---|---|
| Görüntü sınıflandırması (çok sınıflı ve çok etiketli) | valid_resize_sizevalid_crop_size |
Kategori 256 224 |
| Nesne algılama | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0,5 100 |
kullanarak nesne algılama yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 orta 0,1 0,5 |
| Örneği segmentlere ayırma | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0,5 100 0,5 100 False JPG |
Göreve özgü hiper parametrelerle ilgili ayrıntılı bir açıklama için otomatik makine öğrenmesindeki görüntü işleme görevleri için hiper parametreler konusuna bakın.
Döşeme kullanmak ve döşeme davranışını denetlemek istiyorsanız, aşağıdaki parametreler kullanılabilir: tile_grid_size, tile_overlap_ratio ve tile_predictions_nms_thresh. Bu parametreler hakkında daha fazla bilgi için AutoML kullanarak küçük bir nesne algılama modeli eğitme konusuna bakın.
Dağıtımı test etme
Dağıtımı test etmek ve modelden algılamaları görselleştirmek için bu Dağıtımı test etme bölümünü gözden geçirin.
Tahminler için açıklamalar oluşturma
Önemli
Bu ayarlar şu anda genel önizleme aşamasındadır. Hizmet düzeyi sözleşmesi olmadan sağlanır. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir. Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
Uyarı
Model Açıklanabilirliği yalnızca çok sınıflı sınıflandırma ve çok etiketli sınıflandırma için desteklenir.
Görüntüler için AutoML ile Açıklanabilir Yapay Zeka (XAI) kullanmanın avantajlarından bazıları:
- Karmaşık görüntü modeli tahminlerinde saydamlığı artırır
- Kullanıcıların, model tahminlerine katkıda bulunan giriş görüntüsündeki önemli özellikleri/pikselleri anlamasına yardımcı olur
- Modellerin sorunlarını gidermeye yardımcı olur
- Yanlılıkların keşfedilmesine yardımcı olur
Açıklama
Açıklamalar, modelin tahminine katkısını temel alarak giriş görüntüsündeki her piksele verilen özellik öznitelikleri veya ağırlıklardır. Her ağırlık negatif (tahminle negatif bağıntılı) veya pozitif (tahminle pozitif bağıntılı) olabilir. Bu atıflar, tahmin edilen sınıfa göre hesaplanır. Çok sınıflı sınıflandırma için örnek başına tam olarak bir ilişkilendirme [3, valid_crop_size, valid_crop_size] matrisi, çok etiketli sınıflandırma için ise her örnek için tahmin edilen her etiket/sınıf için boyut [3, valid_crop_size, valid_crop_size] ilişkilendirme matrisi oluşturulur.
Dağıtılan uç nokta üzerindeki Görüntüler için AutoML'de Açıklanabilir Yapay Zeka'yı kullanan kullanıcılar, her görüntü için açıklamaların görselleştirmelerini (giriş görüntüsünde yer alan öznitelikler) ve/veya öznitelikleri (çok boyutlu boyut [3, valid_crop_size, valid_crop_size]dizisi) alabilir. Görselleştirmelerin dışında, kullanıcılar açıklamalar üzerinde daha fazla denetim elde etmek için ilişkilendirme matrisleri de alabilir (atıfları kullanarak özel görselleştirmeler oluşturma veya ilişkilendirme segmentlerini inceleme gibi). Tüm açıklama algoritmaları, ilişkilendirme oluşturmak için boyutu valid_crop_size kırpılmış kare görüntüleri kullanır.
Açıklamalar çevrimiçi uç noktadan veya toplu iş uç noktasından oluşturulabilir. Dağıtım tamamlandıktan sonra bu uç nokta, tahminlerin açıklamalarını oluşturmak için kullanılabilir. Çevrimiçi dağıtımlarda, açıklamalar oluştururken zaman aşımı sorunlarını önlemek için parametresini 'a ManagedOnlineDeployment geçirip request_settings = OnlineRequestSettings(request_timeout_ms=90000) en yüksek değerine ayarladığınızdan request_timeout_ms emin olun (model kaydetme ve dağıtma bölümüne bakın). Daha fazla zaman tüketmek gibi xrai açıklanabilirlik (XAI) yöntemlerinden bazıları (özellikle tahmin edilen her etiket için atıflar ve/veya görselleştirmeler oluşturmamız gerektiğinden çok etiketli sınıflandırma için). Bu nedenle, daha hızlı açıklamalar için herhangi bir GPU örneğini öneririz. Açıklama oluşturmaya yönelik giriş ve çıkış şeması hakkında daha fazla bilgi için şema belgelerine bakın.
Görüntüler için AutoML'de aşağıdaki son durum bilgisi açıklanabilirlik algoritmalarını destekliyoruz:
- XRAI (xrai)
- Tümleşik Gradyanlar (integrated_gradients)
- Destekli GradCAM (guided_gradcam)
- Destekli BackPropagation (guided_backprop)
Aşağıdaki tabloda XRAI ve Tümleşik Gradyanlar için açıklanabilirlik algoritmasına özgü ayarlama parametreleri açıklanmaktadır. Destekli geriözelleştirme ve kılavuzlu gradcam için herhangi bir ayarlama parametresi gerekmez.
| XAI algoritması | Algoritmaya özgü parametreler | Varsayılan Değerler |
|---|---|---|
xrai |
1. n_steps: Yaklaşık oluşturma yöntemi tarafından kullanılan adım sayısı. Daha fazla sayıda adım, atıfların (açıklamalar) daha iyi tahmin edilmesine yol açar. n_steps aralığı [2, inf) ancak 50 adımdan sonra ilişkilendirmelerin performansı yakınsanmaya başlar. Optional, Int 2. xrai_fast: XRAI'nin daha hızlı sürümünün kullanılıp kullanılmaymayacağı. ise True, açıklamalar için hesaplama süresi daha hızlıdır ancak daha az doğru açıklamaya (atıflar) yol açar Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: Yaklaşık oluşturma yöntemi tarafından kullanılan adım sayısı. Daha fazla sayıda adım, daha iyi atıflara (açıklamalar) yol açar. n_steps aralığı [2, inf) ancak 50 adımdan sonra ilişkilendirmelerin performansı yakınsanmaya başlar.Optional, Int 2. approximation_method: İntegrali yaklaşık olarak belirleme yöntemi. Kullanılabilir yaklaşık tahmin yöntemleri ve gausslegendreşeklindedirriemann_middle.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Dahili XRAI algoritması tümleşik gradyanları kullanır. Bu nedenle, n_steps parametre hem tümleşik gradyanlar hem de XRAI algoritmaları için gereklidir. Daha fazla sayıda adım açıklamaları tahmin etmek için daha fazla zaman tüketir ve çevrimiçi uç noktada zaman aşımı sorunlarına neden olabilir.
Daha iyi açıklamalar için XRAI > Destekli GradCAM > Tümleşik Gradyanlar > Destekli BackPropagation algoritmaları kullanmanızı öneririz, ancak belirtilen sırada daha hızlı açıklamalar için Destekli BackPropagation > Destekli GradCAM > Tümleşik Gradyanları > XRAI önerilir.
Çevrimiçi uç noktaya örnek bir istek aşağıdaki gibi görünür. Bu istek olarak ayarlandığında Trueaçıklamalar model_explainability oluşturur. aşağıdaki istek, 50 adımlı XRAI algoritmasının daha hızlı sürümünü kullanarak görselleştirmeler ve atıflar oluşturur.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Açıklama oluşturma hakkında daha fazla bilgi için bkz . Otomatik makine öğrenmesi örnekleri için GitHub not defteri deposu.
Görselleştirmeleri Yorumlama
Dağıtılan uç nokta, her ikisi de model_explainability visualizations olarak ayarlanmışsa base64 kodlanmış görüntü dizesini Truedöndürür. Base64 dizesinin kodunu not defterlerinde açıklandığı gibi çözebilirsiniz veya tahminde base64 görüntü dizelerinin kodunu çözmek ve görselleştirmek için aşağıdaki kodu kullanın.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
Aşağıdaki resimde örnek giriş görüntüsü için açıklamaların görselleştirmesi açıklanmaktadır.

Kodu çözülen base64 şekli, 2 x 2 kılavuz içinde dört görüntü bölümü vardır.
- Sol üst köşedeki görüntü (0, 0) kırpılan giriş resmidir
- Sağ üst köşedeki görüntü (0, 1), tahmin edilen sınıftaki beyaz piksellerin katkısının en yüksek, mavi piksellerin ise en düşük olduğu renk ölçeği bgyw (mavi yeşil sarı beyaz) üzerindeki ilişkilendirmelerin ısı haritasıdır.
- Sol alt köşedeki görüntü (1, 0) kırpılan giriş görüntüsünde ilişkilendirmelerin ısı haritası karıştırıldı
- Sağ alt köşedeki resim (1, 1), ilişkilendirme puanlarına göre piksellerin ilk yüzde 30'unu içeren kırpılmış giriş resmidir.
Atıfları Yorumlama
Dağıtılan uç nokta, hem attributions hem de model_explainability olarak ayarlanmışsa Trueilişkilendirmeleri döndürür. Daha fazla ayrıntı için çok sınıflı sınıflandırma ve çok etiketli sınıflandırma not defterlerine bakın.
Bu atıflar, kullanıcılara özel görselleştirmeler oluşturmaları veya piksel düzeyi atf puanlarını incelemeleri için daha fazla denetim sağlar. Aşağıdaki kod parçacığı, ilişkilendirme matrisi kullanarak özel görselleştirmeler oluşturmanın bir yolunu açıklar. Çok sınıflı sınıflandırma ve çok etiketli sınıflandırma için ilişkilendirme şeması hakkında daha fazla bilgi için şema belgelerine bakın.
Açıklamaları oluşturmak için seçilen modelin tam valid_resize_size ve valid_crop_size değerlerini kullanın (varsayılan değerler sırasıyla 256 ve 224'tür). Aşağıdaki kod, özel görselleştirmeler oluşturmak için Captum görselleştirme işlevini kullanır. Kullanıcılar görselleştirme oluşturmak için başka herhangi bir kitaplığı kullanabilir. Daha fazla ayrıntı için lütfen captum görselleştirme yardımcı programlarına bakın.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Büyük veri kümeleri
Büyük veri kümeleri üzerinde eğitmek için AutoML kullanıyorsanız yararlı olabilecek bazı deneysel ayarlar vardır.
Önemli
Bu ayarlar şu anda genel önizleme aşamasındadır. Hizmet düzeyi sözleşmesi olmadan sağlanır. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir. Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
Çoklu GPU ve çok düğümlü eğitim
Varsayılan olarak, her model tek bir VM'de eğitilir. Modelin eğitimi çok fazla zaman alıyorsa, birden çok GPU içeren VM'lerin kullanılması yardımcı olabilir. Modeli büyük veri kümelerinde eğitme süresi, kullanılan GPU sayısına göre kabaca doğrusal oranda azaltılmalıdır. (Örneğin, bir model, bir GPU'ya sahip bir VM'de olduğu gibi iki GPU'ya sahip bir VM'de kabaca iki kat hızlı eğitmelidir.) Birden çok GPU'ya sahip bir VM'de modeli eğitmek için gereken süre hala yüksekse, her modeli eğitmek için kullanılan VM sayısını artırabilirsiniz. Çoklu GPU eğitimine benzer şekilde, modeli büyük veri kümelerinde eğitme süresi de kullanılan VM sayısına göre kabaca doğrusal oranda azaltılmalıdır. Bir modeli birden çok VM arasında eğitirken, en iyi sonuçlar için InfiniBand'i destekleyen bir işlem SKU'su kullandığınızdan emin olun. AutoML işinin özelliğini ayarlayarak node_count_per_trial tek bir modeli eğitmek için kullanılan VM sayısını yapılandırabilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
properties:
node_count_per_trial: "2"
Depolama alanından görüntü dosyalarını akışla aktarma
Varsayılan olarak, model eğitimi öncesinde tüm görüntü dosyaları diske indirilir. Görüntü dosyalarının boyutu kullanılabilir disk alanından büyükse, iş başarısız olur. Tüm görüntüleri diske indirmek yerine, eğitim sırasında ihtiyaç duyulan görüntü dosyalarını Azure depolamadan akışla aktarmayı seçebilirsiniz. Görüntü dosyaları Azure depolamadan doğrudan sistem belleğine aktarılır ve disk atlanır. Aynı zamanda, depolamaya yönelik istek sayısını en aza indirmek için depolama alanından mümkün olduğunca çok dosya diskte önbelleğe alınır.
Not
Akış etkinleştirildiyse, maliyeti ve gecikme süresini en aza indirmek için Azure depolama hesabının işlemle aynı bölgede bulunduğundan emin olun.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Örnek not defterleri
Otomatik makine öğrenimi örnekleri için GitHub not defteri deposundaki ayrıntılı kod örneklerini ve kullanım örneklerini inceleyin. Görüntü işleme modelleri oluşturmaya özgü örnekler için 'automl-image-' ön ekine sahip klasörleri denetleyin.
Kod örnekleri
Otomatik makine öğrenmesi örnekleri için azureml-examples deposunda ayrıntılı kod örneklerini ve kullanım örneklerini gözden geçirin.
Sonraki adımlar
- Öğretici: AutoML ve Python ile nesne algılama modelini eğitme.