Python ile AutoML eğitimini ayarlama
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Bu kılavuzda, Azure Machine Learning otomatik ML kullanarak Azure Machine Learning Python SDK'sı ile otomatik makine öğrenmesi olan AutoML eğitim çalıştırmasını ayarlamayı öğrenin. Otomatik ML sizin için bir algoritma ve hiper parametre seçer ve dağıtıma hazır bir model oluşturur. Bu kılavuzda, otomatik ML denemelerini yapılandırmak için kullanabileceğiniz çeşitli seçeneklerin ayrıntıları sağlanır.
Uçtan uca bir örnek için bkz . Öğretici: AutoML- regresyon modelini eğitme.
Kod yok deneyimini tercih ediyorsanız, Azure Machine Learning stüdyosu kod içermeyen AutoML eğitimi de ayarlayabilirsiniz.
Ön koşullar
Bu makale için,
Azure Machine Learning çalışma alanı. Çalışma alanını oluşturmak için bkz . Çalışma alanı kaynakları oluşturma.
Azure Machine Learning Python SDK'sı yüklü. SDK'yı yüklemek için
SDK'yı otomatik olarak yükleyen ve ML iş akışları için önceden yapılandırılmış bir işlem örneği oluşturun. Daha fazla bilgi için bkz . Azure Machine Learning işlem örneği oluşturma ve yönetme.
SDK'nın
automlvarsayılan yüklemesini içeren paketi kendiniz yükleyin.
Önemli
Bu makaledeki Python komutları en son
azureml-train-automlpaket sürümünü gerektirir.- En son
azureml-train-automlpaketi yerel ortamınıza yükleyin. - En son
azureml-train-automlpaketle ilgili ayrıntılar için sürüm notlarına bakın.
Uyarı
Python 3.8 ile
automluyumlu değildir.
Deneme türünüzü seçme
Denemenize başlamadan önce, çözdüğünüz makine öğrenmesi sorununun türünü belirlemeniz gerekir. Otomatik makine öğrenmesi classification, regressionve forecastinggörev türlerini destekler. Görev türleri hakkında daha fazla bilgi edinin.
Dekont
Doğal dil işleme (NLP) görevleri için destek: görüntü sınıflandırması (çok sınıflı ve çok etiketli) ve adlandırılmış varlık tanıma genel önizlemede kullanılabilir. Otomatik ML'deki NLP görevleri hakkında daha fazla bilgi edinin.
Bu önizleme özellikleri hizmet düzeyi sözleşmesi olmadan sağlanır. Bazı özellikler desteklenmeyebilir veya sınırlı işlevlere sahip olabilir. Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
Aşağıdaki kod, deneme türünü olarak classificationbelirtmek için oluşturucudaki AutoMLConfig parametresini kullanırtask.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Veri kaynağı ve biçimi
Otomatik makine öğrenmesi yerel masaüstünüzde veya Azure Blob Depolama gibi bulutta duran verilerinizi destekler. Veriler bir Pandas DataFrame veya Azure Machine Learning TabularDataset içinde okunabilir. Veri kümeleri hakkında daha fazla bilgi edinin.
Makine öğrenmesinde eğitim verileri için gereksinimler:
- Veriler tablo biçiminde olmalıdır.
- Tahmin edilecek değer olan hedef sütun verilerde olmalıdır.
Önemli
Otomatik ML denemeleri, kimlik tabanlı veri erişimi kullanan veri kümeleriyle eğitimi desteklemez.
Uzak denemeler için eğitim verilerine uzak işlemden erişilebilir olmalıdır. Otomatik ML, uzak işlem üzerinde çalışırken yalnızca Azure Machine Learning TabularDatasets'i kabul eder .
Azure Machine Learning veri kümeleri şu işlevleri kullanıma sunar:
- Statik dosyalardan veya URL kaynaklarından çalışma alanınıza kolayca veri aktarabilirsiniz.
- Verilerinizin bulut bilişim kaynaklarında çalıştırılan eğitim betikleri tarafından kullanılabilmesini sağlama. Uzak işlem hedefinize veri bağlamak için sınıfını kullanma
Datasetörneği için bkz. Veri kümeleriyle eğitme.
Aşağıdaki kod, web URL'sinden bir TabularDataset oluşturur. Yerel dosyalar ve veri depoları gibi diğer kaynaklardan veri kümeleri oluşturma hakkında kod örnekleri için bkz . TabularDataset oluşturma.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
Yerel işlem denemeleri için daha hızlı işleme süreleri için pandas veri çerçevelerini öneririz.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Eğitim, doğrulama ve test verileri
Ayrı eğitim verileri ve doğrulama veri kümelerini doğrudan oluşturucuda AutoMLConfig belirtebilirsiniz. AutoML denemeleriniz için eğitim, doğrulama, çapraz doğrulama ve test verilerini yapılandırma hakkında daha fazla bilgi edinin.
Bir veya n_cross_validation parametresini açıkça belirtmezsenizvalidation_data, otomatik ML doğrulamanın nasıl gerçekleştirildiğini belirlemek için varsayılan teknikleri uygular. Bu belirleme, veri kümesindeki parametrenize training_data atanan satır sayısına bağlıdır.
| Eğitim veri boyutu | Doğrulama tekniği |
|---|---|
| 20.000'den büyük satır | Eğit/doğrulama veri bölme uygulanır. Varsayılan değer, doğrulama kümesi olarak ilk eğitim veri kümesinin %10'unu almaktır. Buna karşılık, bu doğrulama kümesi ölçüm hesaplaması için kullanılır. |
| 20.000'den küçük satır | Çapraz doğrulama yaklaşımı uygulanır. Varsayılan katlama sayısı satır sayısına bağlıdır. Veri kümesi 1.000 satırdan azsa 10 kat kullanılır. Satırlar 1.000 ile 20.000 arasındaysa üç kat kullanılır. |
Bahşiş
Otomatik ML'nin sizin için oluşturduğu modelleri değerlendirmek için test verilerini (önizleme) karşıya yükleyebilirsiniz. Bu özellikler deneysel önizleme özellikleridir ve herhangi bir zamanda değişebilir. Şunları nasıl yapacağınızı öğrenin:
- Test verilerini AutoMLConfig nesnenize geçirin.
- Denemeniz için oluşturulan otomatik ML modellerini test edin.
Kod içermeyen bir deneyimi tercih ediyorsanız, studio kullanıcı arabirimiyle AutoML'yi ayarlama başlığındaki 12. adıma bakın
Büyük veriler
Otomatik ML, küçük sanal makinelerde büyük veriler için başarıyla model oluşturabilen büyük veriler üzerinde eğitim için sınırlı sayıda algoritmayı destekler. Otomatik ML buluşsal yöntemleri, bu büyük veri algoritmalarının uygulanması gerekip gerekmediğini belirlemek için veri boyutu, sanal makine bellek boyutu, deneme zaman aşımı ve özellik belirleme ayarları gibi özelliklere bağlıdır. Otomatik ML'de hangi modellerin desteklendiği hakkında daha fazla bilgi edinin.
Regresyon için, Çevrimiçi Gradyan Azalma Regresörü ve Hızlı Doğrusal Regresör
Sınıflandırma için, Ortalama Perceptron Sınıflandırıcısı ve Doğrusal SVM Sınıflandırıcısı; burada Doğrusal SVM sınıflandırıcısı hem büyük veri hem de küçük veri sürümlerine sahiptir.
Bu buluşsal yöntemleri geçersiz kılmak istiyorsanız aşağıdaki ayarları uygulayın:
| Görev | Ayar | Notlar |
|---|---|---|
| Veri akışı algoritmalarını engelleme | blocked_models ögesini AutoMLConfig seçin ve kullanmak istemediğiniz modelleri listeleyin. |
Çalıştırma hatasına veya uzun çalışma süresine neden olur |
| Veri akışı algoritmalarını kullanma | allowed_models ögesini AutoMLConfig seçin ve kullanmak istediğiniz modelleri listeleyin. |
|
| Veri akışı algoritmalarını kullanma (studio kullanıcı arabirimi denemeleri) |
Kullanmak istediğiniz büyük veri algoritmaları dışındaki tüm modelleri engelleyin. |
Deneme çalıştırmak için işlem
Ardından modelin nerede eğitileceğini belirleyin. Otomatik ml eğitim denemesi aşağıdaki işlem seçeneklerinde çalıştırılabilir.
Yerel bir işlem seçin: Senaryonuz küçük verileri ve kısa trenleri (çocuk çalıştırması başına saniye veya birkaç dakika) kullanan ilk keşifler veya tanıtımlar hakkındaysa, yerel bilgisayarınızda eğitim daha iyi bir seçim olabilir. Kurulum süresi yoktur, altyapı kaynakları (bilgisayarınız veya VM'niz) doğrudan kullanılabilir. Yerel işlem örneği için bu not defterine bakın.
Bir uzak ML işlem kümesi seçin: Üretim eğitiminde olduğu gibi daha büyük veri kümeleriyle eğitim veriyorsanız ve daha uzun eğitimlere ihtiyaç duyan modeller oluşturuyorsanız, uzak işlem çok daha iyi uçtan uca zaman performansı sağlar çünkü
AutoMLkümenin düğümleri arasında trenleri paralelleştirir. Uzaktan işlemde, iç altyapının başlangıç süresi alt çalıştırma başına yaklaşık 1,5 dakika ve VM'ler henüz çalışır durumda değilse küme altyapısı için ek dakika ekler.Azure Machine Learning Yönetilen İşlem , Azure sanal makine kümelerinde makine öğrenmesi modellerini eğitme olanağı sağlayan yönetilen bir hizmettir. İşlem örneği, işlem hedefi olarak da desteklenir.Azure aboneliğinizdeki bir Azure Databricks kümesi . Daha fazla ayrıntı için bkz. Otomatik ML için Azure Databricks kümesi ayarlama. Azure Databricks içeren not defteri örnekleri için bu GitHub sitesine bakın.
İşlem hedefinizi seçerken şu faktörleri göz önünde bulundurun:
| Artılar (Avantajlar) | Eksiler (Handikaplar) | |
|---|---|---|
| Yerel işlem hedefi | ||
| Uzak ML işlem kümeleri |
Deneme ayarlarınızı yapılandırma
Otomatik ML denemenizi yapılandırmak için kullanabileceğiniz çeşitli seçenekler vardır. Bu parametreler bir AutoMLConfig nesne örneği oluşturarak ayarlanır. Parametrelerin tam listesi için bkz. AutoMLConfig sınıfı .
Aşağıdaki örnek bir sınıflandırma görevi içindir. Denemede birincil ölçüm olarak ağırlıklı AUC kullanılır ve deneme zaman aşımı 30 dakika ve 2 çapraz doğrulama katlama olarak ayarlanmıştır.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Ek kurulum gerektiren tahmin görevlerini de yapılandırabilirsiniz. Daha fazla ayrıntı için Zaman serisi tahmini için AutoML'yi ayarlama makalesine bakın.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Desteklenen modeller
Otomatik makine öğrenmesi, otomasyon ve ayarlama işlemi sırasında farklı modelleri ve algoritmaları dener. Kullanıcı olarak algoritmayı belirtmenize gerek yoktur.
Uygulanacak algoritmaların veya modellerin listesini üç farklı task parametre değeri belirler. allowed_models Dahil etmek veya dışlamak için kullanılabilir modellerle yinelemeleri daha fazla değiştirmek için veya blocked_models parametrelerini kullanın.
Aşağıdaki tabloda, desteklenen modeller görev türüne göre özetlenmektedir.
Dekont
Otomatik ML tarafından oluşturulan modellerinizi bir ONNX modeline dışarı aktarmayı planlıyorsanız, yalnızca * (yıldız) ile belirtilen algoritmalar ONNX biçimine dönüştürülebilir. Modelleri ONNX'e dönüştürme hakkında daha fazla bilgi edinin.
Ayrıca, ONNX'in şu anda yalnızca sınıflandırma ve regresyon görevlerini desteklediğini unutmayın.
Birincil ölçüm
parametresi, primary_metric iyileştirme için model eğitimi sırasında kullanılacak ölçümü belirler. Seçebileceğiniz kullanılabilir ölçümler, seçtiğiniz görev türüne göre belirlenir.
İyileştirme için otomatik ML için birincil ölçüm seçmek birçok faktöre bağlıdır. Öncelikle iş gereksinimlerinizi en iyi şekilde temsil eden bir ölçüm seçmenizi öneririz. Ardından ölçümün veri kümesi profilinize (veri boyutu, aralık, sınıf dağıtımı vb.) uygun olup olmadığını göz önünde bulundurun. Aşağıdaki bölümlerde, görev türüne ve iş senaryosuna göre önerilen birincil ölçümler özetlenmiştir.
Otomatik makine öğrenmesi sonuçlarını anlama bölümünde bu ölçümlerin belirli tanımları hakkında bilgi edinin.
Sınıflandırma senaryoları için ölçümler
, recall_score_weighted, norm_macro_recallve precision_score_weighted gibi accuracyeşik bağımlı ölçümler, küçük, çok büyük sınıf dengesizliği (sınıf dengesizliği) olan veya beklenen ölçüm değeri 0,0 veya 1,0'a çok yakın olan veri kümeleri için iyileştirilmeyebilir. Bu gibi durumlarda, AUC_weighted birincil ölçüm için daha iyi bir seçim olabilir. Otomatik ML tamamlandıktan sonra, iş gereksinimlerinize en uygun ölçümü temel alarak kazanan modeli seçebilirsiniz.
| Ölçüm | Örnek kullanım örnekleri |
|---|---|
accuracy |
Görüntü sınıflandırması, Yaklaşım analizi, Değişim sıklığı tahmini |
AUC_weighted |
Sahtekarlık algılama, Görüntü sınıflandırma, Anomali algılama/istenmeyen posta algılama |
average_precision_score_weighted |
Duygu analizi |
norm_macro_recall |
Değişim sıklığı tahmini |
precision_score_weighted |
Regresyon senaryoları için ölçümler
r2_scoreve normalized_mean_absolute_errornormalized_root_mean_squared_error tümü tahmin hatalarını en aza indirmeye çalışıyor. r2_score ve normalized_root_mean_squared_error her ikisi de hataların ortalama mutlak değerini azaltırken normalized_mean_absolute_error ortalama hata karesini en aza indirir. Mutlak değer, hataları hem tüm büyüklüklerde hem de kare olarak değerlendirir ve daha büyük mutlak değerlere sahip hatalar için çok daha büyük bir cezaya sahip olur. Daha büyük hataların daha fazla cezalandırılıp cezalandırılmayacağına bağlı olarak, hata karesini veya mutlak hatayı iyileştirmeyi seçebilirsiniz.
ile normalized_root_mean_squared_error arasındaki r2_score temel fark, normalleştirilmeleri ve anlamlarıdır. normalized_root_mean_squared_error kök ortalaması hata karesi aralığına göre normalleştirilmiştir ve tahmin için ortalama hata büyüklüğü olarak yorumlanabilir. r2_score ortalama hata karesi, veri varyansı tahminiyle normalleştirilir. Model tarafından yakalanabilecek varyasyonun oranıdır.
Dekont
r2_score ve normalized_root_mean_squared_error ayrıca birincil ölçümlerle benzer şekilde davranır. Sabit bir doğrulama kümesi uygulanırsa, bu iki ölçüm aynı hedefi, ortalama kare hatasını en iyi duruma getirir ve aynı model tarafından iyileştirilir. Yalnızca bir eğitim kümesi mevcut olduğunda ve çapraz doğrulama uygulandığında, için normalleştirici normalized_root_mean_squared_error eğitim kümesi aralığı olarak sabitlendiğinden bunlar biraz farklı olabilir, ancak her katlama için varyans olduğu için için normalleştiricisi r2_score her katlama için farklılık gösterebilir.
Derece, tam değer yerine ilgi çekiciyse, spearman_correlation gerçek değerler ve tahminler arasındaki derece bağıntısını ölçen daha iyi bir seçim olabilir.
Ancak, şu anda regresyon için birincil ölçümler göreli farkı gidermiyor. r2_scorenormalized_mean_absolute_errornormalized_root_mean_squared_error Bu iki veri noktası regresyon için aynı veri kümesine veya zaman serisi tanımlayıcısı tarafından belirtilen aynı zaman serisine aitse, 20 bin ABD doları tutarında tahmin hatasını 30 bin ABD doları maaşa sahip bir çalışan için 20 milyon ABD doları alan bir çalışan için aynı şekilde değerlendirin. Gerçekte, $20 milyon maaştan yalnızca 20 bin ABD doları indirim tahmin etmek çok yakındır (küçük bir %0,1 göreli fark), 30 bin ABD doları olan $20k kapalı ise yakın değildir (büyük bir %67 göreli fark). Göreli fark sorununu çözmek için, bir model kullanılabilir birincil ölçümlerle eğitilebilir ve ardından en iyi mean_absolute_percentage_error veya root_mean_squared_log_errorile modeli seçebilir.
| Ölçüm | Örnek kullanım örnekleri |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Fiyat tahmini (ev/ürün/ipucu), Puan tahminlerini gözden geçirme |
r2_score |
Havayolu gecikmesi, Maaş tahmini, Hata çözümleme süresi |
normalized_mean_absolute_error |
Zaman serisi tahmin senaryoları için ölçümler
Öneriler, regresyon senaryolarında belirtilenlere benzer.
| Ölçüm | Örnek kullanım örnekleri |
|---|---|
normalized_root_mean_squared_error |
Fiyat tahmini (tahmin), Stok iyileştirme, Talep tahmini |
r2_score |
Fiyat tahmini (tahmin), Stok iyileştirme, Talep tahmini |
normalized_mean_absolute_error |
Veri özellik kazandırma
Her otomatik ML denemesinde verileriniz, farklı ölçeklerdeki özelliklere duyarlı olan belirli algoritmalara yardımcı olmak için otomatik olarak ölçeklendirilir ve normalleştirilir. Bu ölçeklendirme ve normalleştirme özellik geliştirme olarak adlandırılır. Daha fazla ayrıntı ve kod örneği için bkz . AutoML'de Özellik Kazandırma.
Dekont
Otomatik makine öğrenmesi özellik geliştirme adımları (özellik normalleştirme, eksik verileri işleme, metni sayısala dönüştürme vb.) temel alınan modelin bir parçası haline gelir. Modeli tahminler için kullanırken, eğitim sırasında uygulanan özellik geliştirme adımları giriş verilerinize otomatik olarak uygulanır.
Nesnenizde AutoMLConfig denemelerinizi yapılandırırken ayarını featurizationetkinleştirebilir/devre dışı bırakabilirsiniz. Aşağıdaki tabloda AutoMLConfig nesnesinde özellik özelliği için kabul edilen ayarlar gösterilmektedir.
| Özellik Kazandırma Yapılandırması | Tanım |
|---|---|
"featurization": 'auto' |
Ön işlemenin bir parçası olarak veri korumaları ve özellik geliştirme adımlarının otomatik olarak gerçekleştirildiğini gösterir. Varsayılan ayar. |
"featurization": 'off' |
Özellik geliştirme adımının otomatik olarak yapılmaması gerektiğini gösterir. |
"featurization": 'FeaturizationConfig' |
Özelleştirilmiş özellik geliştirme adımının kullanılması gerektiğini gösterir. Özellik geliştirmeyi özelleştirmeyi öğrenin. |
Grup yapılandırması
Grup modelleri varsayılan olarak etkinleştirilir ve AutoML çalıştırmasında son çalıştırma yinelemeleri olarak görünür. Şu anda VotingEnsemble ve StackEnsemble desteklenmektedir.
Oylama, ağırlıklı ortalamaları kullanan geçici oylama uygular. Yığma uygulaması, ilk katmanın oylama grubuyla aynı modellere sahip olduğu ve ikinci katman modelinin ise ilk katmandaki modellerin en uygun bileşimini bulmak için kullanıldığı iki katmanlı bir uygulama kullanır.
ONNX modelleri kullanıyorsanız veya model açıklaması etkinleştirilmişse, yığınlama devre dışı bırakılır ve yalnızca oylama kullanılır.
Grup eğitimi ve enable_stack_ensemble boole parametreleri kullanılarak enable_voting_ensemble devre dışı bırakılabilir.
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Varsayılan grup davranışını değiştirmek için, bir AutoMLConfig nesnede olduğu gibi kwargs sağlanabilir birden çok varsayılan bağımsız değişken vardır.
Önemli
Aşağıdaki parametreler AutoMLConfig sınıfının açık parametreleri değildir.
ensemble_download_models_timeout_sec: VotingEnsemble ve StackEnsemble model oluşturma sırasında, önceki alt çalıştırmalara ait birden çok uygun model indirilir. Şu hatayla karşılaşırsanız:AutoMLEnsembleException: Could not find any models for running ensembling, modellerin indirilmesi için daha fazla zaman sağlamanız gerekebilir. Bu modelleri paralel olarak indirmek için varsayılan değer 300 saniyedir ve maksimum zaman aşımı sınırı yoktur. Daha fazla zaman gerekiyorsa bu parametreyi 300 saniyeden daha yüksek bir değerle yapılandırın.Dekont
Zaman aşımına ulaşılırsa ve indirilen modeller varsa, benzerlik indirdiği kadar çok modelle devam eder. Tüm modellerin bu zaman aşımı içinde bitmesi için indirilmesi gerekmez. Aşağıdaki parametreler yalnızca StackEnsemble modelleri için geçerlidir:
stack_meta_learner_type: meta-öğrenen, tek tek heterojen modellerin çıkışı üzerinde eğitilmiş bir modeldir. Varsayılan meta öğrenenlerLogisticRegressionsınıflandırma görevlerine (veyaLogisticRegressionCVçapraz doğrulama etkinse) veElasticNetregresyon/tahmin görevlerine (veyaElasticNetCVçapraz doğrulama etkinse) yöneliktir. Bu parametre şu dizelerden biri olabilir:LogisticRegression,LogisticRegressionCV,LightGBMClassifier,ElasticNet, ,ElasticNetCV,LightGBMRegressorveyaLinearRegression.stack_meta_learner_train_percentage: meta-öğreniciyi eğitmek için ayrılacak eğitim kümesinin oranını (eğitim ve doğrulama türü seçerken) belirtir. Varsayılan değer0.2olarak belirlenmiştir.stack_meta_learner_kwargs: meta öğrenicinin başlatıcısına geçirmek için isteğe bağlı parametreler. Bu parametreler ve parametre türleri, ilgili model oluşturucusundan parametreleri ve parametre türlerini yansıtır ve model oluşturucusna iletilir.
Aşağıdaki kod, bir AutoMLConfig nesnede özel grup davranışı belirtme örneğini gösterir.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Çıkış ölçütü
Denemenizi sonlandırmak için AutoMLConfig'inizde tanımlayabileceğiniz birkaç seçenek vardır.
| Ölçüt | açıklama |
|---|---|
| Ölçüt yok | Herhangi bir çıkış parametresi tanımlamazsanız deneme, birincil ölçümünüzde başka bir ilerleme kaydedilmeden devam eder. |
| Bir süre sonra | Denemenizin kaç dakika içinde çalışmaya devam etmesi gerektiğini tanımlamak için ayarlarınızda kullanın experiment_timeout_minutes . Deneme zaman aşımı hatalarını önlemeye yardımcı olmak için en az 15 dakika veya sütun boyutuna göre satırınız 10 milyonu aşarsa 60 dakika olur. |
| Bir puana ulaşıldı | Belirtilen birincil ölçüm puanına ulaşıldıktan sonra kullan experiment_exit_score işlemi denemeyi tamamlar. |
Denemeyi çalıştırma
Uyarı
Aynı yapılandırma ayarları ve birincil ölçümle bir denemeyi birden çok kez çalıştırırsanız, büyük olasılıkla her denemenin son ölçüm puanında ve oluşturulan modellerde çeşitleme görürsünüz. Otomatik ML'nin kullandığı algoritmalar, deneme tarafından elde edilen modellerde ve doğruluk gibi önerilen modelin son ölçüm puanında küçük farklılıklara neden olabilecek doğal rastgeleliğe sahiptir. Büyük olasılıkla aynı model adına sahip ancak kullanılan farklı hiper parametrelere sahip sonuçlar görürsünüz.
Otomatik ML için, denemeleri çalıştırmak için kullanılan bir içindeki adlandırılmış nesne olan bir Workspace nesne oluşturursunuzExperiment.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Çalıştırmak ve model oluşturmak için denemeyi gönderin. AutoMLConfig modeli oluşturmak için submit yöntemine geçirin.
run = experiment.submit(automl_config, show_output=True)
Dekont
Bağımlılıklar ilk olarak yeni bir makineye yüklenir. Çıkışın gösterilmesi 10 dakika kadar sürebilir.
Ayarı show_output , True konsolunda çıkışın gösterilmesiyle sonuçlanıyor.
Kümelerde birden çok alt çalıştırma
Otomatik ML denemesi alt çalıştırmaları, zaten başka bir deneme çalıştıran bir kümede gerçekleştirilebilir. Ancak zamanlama, kümenin kaç düğümü olduğuna ve bu düğümlerin farklı bir deneme çalıştırmak için kullanılabilir olup olduğuna bağlıdır.
Kümedeki her düğüm, tek bir eğitim çalıştırması gerçekleştirebilen tek bir sanal makine (VM) görevi görür; otomatik ML için bu, alt çalıştırma anlamına gelir. Tüm düğümler meşgulse yeni deneme kuyruğa alınır. Ancak ücretsiz düğümler varsa, yeni deneme otomatik ML alt çalıştırmalarını kullanılabilir düğümlerde/VM'lerde paralel olarak çalıştırır.
Alt çalıştırmaları yönetmeye ve ne zaman gerçekleştirilebileceklerini yönetmeye yardımcı olmak için deneme başına ayrılmış bir küme oluşturmanızı ve denemenizin sayısını max_concurrent_iterations kümedeki düğüm sayısıyla eşleştirmenizi öneririz. Bu şekilde, kümenin tüm düğümlerini istediğiniz eş zamanlı alt çalıştırma/yineleme sayısıyla aynı anda kullanırsınız.
Nesnenizde AutoMLConfig yapılandırınmax_concurrent_iterations. Yapılandırılmamışsa, deneme başına varsayılan olarak yalnızca bir eş zamanlı alt çalıştırmaya/yinelemeye izin verilir.
İşlem örneği söz konusu olduğunda, max_concurrent_iterations işlem örneği VM'sindeki çekirdek sayısıyla aynı olacak şekilde ayarlanabilir.
Modelleri ve ölçümleri keşfetme
Otomatik ML, eğitim sonuçlarınızı izlemeniz ve değerlendirmeniz için seçenekler sunar.
Not defterindeyseniz eğitim sonuçlarınızı bir pencere öğesinde veya satır içinde görüntüleyebilirsiniz. Daha fazla ayrıntı için bkz . Otomatik makine öğrenmesi çalıştırmalarını izleme.
Her çalıştırma için sağlanan performans grafiklerinin ve ölçümlerin tanımları ve örnekleri için bkz . Otomatik makine öğrenmesi denemesi sonuçlarını değerlendirme.
Özellik geliştirme özeti almak ve belirli bir modele hangi özelliklerin eklendiğini anlamak için bkz . Özellik geliştirme şeffaflığı.
Özel kod çözümüyle print_model()hiper parametreleri, ölçeklendirme ve normalleştirme tekniklerini ve belirli bir otomatik ML çalıştırmasına uygulanan algoritmayı görüntüleyebilirsiniz.
Bahşiş
Otomatik ML, Otomatik ML tarafından eğitilen modeller için oluşturulan model eğitim kodunu da görüntülemenizi sağlar. Bu işlev genel önizleme aşamasındadır ve istediğiniz zaman değişebilir.
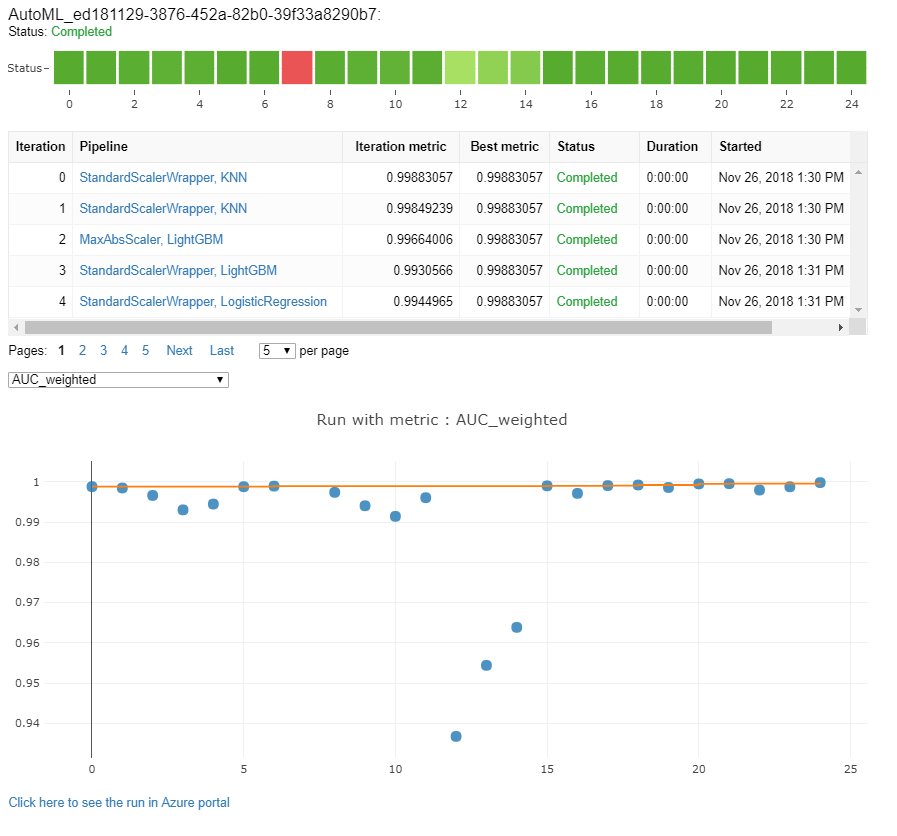
Otomatik makine öğrenmesi çalıştırmalarını izleme
Otomatik ML çalıştırmaları için, önceki bir çalıştırmadaki grafiklere erişmek için değerini uygun deneme adıyla değiştirin <<experiment_name>> :
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
Test modelleri (önizleme)
Önemli
Otomatik ML tarafından oluşturulan modelleri değerlendirmek için modellerinizi test veri kümesiyle test etmek bir önizleme özelliğidir. Bu özellik deneysel bir önizleme özelliğidir ve herhangi bir zamanda değişebilir.
Uyarı
Bu özellik aşağıdaki otomatik ML senaryolarında kullanılamaz
veya test_size parametrelerinin test_dataAutoMLConfigiçine geçirilmesi, deneme tamamlandıktan sonra otomatik ML'nin önerdiği en iyi modeli değerlendirmek için sağlanan test verilerini kullanan bir uzaktan test çalıştırmasını otomatik olarak tetikler. Bu uzaktan test çalıştırması, en iyi model belirlendikten sonra denemenin sonunda yapılır. Test verilerini içine AutoMLConfiggeçirmeyi öğrenin.
Test işi sonuçlarını alma
Azure Machine Learning stüdyosu veya aşağıdaki kodla uzaktan test işinden tahminleri ve ölçümleri alabilirsiniz.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
Model test işi, çalışma alanıyla oluşturulan varsayılan veri deposunda depolanan predictions.csv dosyasını oluşturur. Bu veri deposu aynı aboneliğe sahip tüm kullanıcılar tarafından görülebilir. Test işi için kullanılan veya test işi tarafından oluşturulan bilgilerden herhangi birinin özel kalması gerekiyorsa, senaryolar için test işleri önerilmez.
Mevcut otomatik ML modelini test etme
Oluşturulan diğer otomatik ML modellerini, en iyi işi veya alt işi test etmek için, ana AutoML çalıştırması tamamlandıktan sonra modeli test etmek için kullanın ModelProxy() . ModelProxy() zaten tahminleri ve ölçümleri döndürür ve çıkışları almak için daha fazla işlem gerektirmez.
Dekont
ModelProxy deneysel bir önizleme sınıfıdır ve istediğiniz zaman değişebilir.
Aşağıdaki kod, ModelProxy.test() yöntemini kullanarak herhangi bir çalıştırmadan modeli test etme işlemini gösterir. test() yönteminde, yalnızca parametresiyle test çalıştırmasının tahminlerini görmek isteyip istemediğinizi include_predictions_only belirtme seçeneğiniz vardır.
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Modelleri kaydetme ve dağıtma
Bir modeli test ettikten ve üretimde kullanmak istediğinizi onayladıktan sonra, daha sonra kullanmak üzere kaydedebilir ve
Modeli otomatik ml çalıştırmasından kaydetmek için yöntemini kullanın register_model() .
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Dağıtım yapılandırması oluşturma ve kayıtlı bir modeli web hizmetine dağıtma hakkında ayrıntılı bilgi için bkz . Modelin nasıl ve nereye dağıtılacağı.
Bahşiş
Kayıtlı modeller için tek tıklamayla dağıtım Azure Machine Learning stüdyosu aracılığıyla kullanılabilir. Kayıtlı modellerin stüdyodan nasıl dağıtılacağına bakın.
Model yorumlanabilirliği
Model yorumlanabilirliği, modellerinizin neden tahminde bulunup oluşturmadığınızı ve temel alınan özellik önem değerlerini anlamanıza olanak tanır. SDK, yerel ve dağıtılmış modeller için hem eğitim hem de çıkarım zamanında model yorumlanabilirliği özelliklerini etkinleştirmeye yönelik çeşitli paketler içerir.
Yorumlanabilirlik özelliklerinin özellikle otomatik ML denemeleri içinde nasıl etkinleştirileceğine bakın.
Otomatik makine öğrenmesi dışında SDK'nın diğer alanlarında model açıklamalarının ve özellik öneminin nasıl etkinleştirilebileceği hakkında genel bilgi için yorumlanabilirlik kavram makalesine bakın.
Dekont
ForecastTCN modeli şu anda Açıklama İstemcisi tarafından desteklenmiyor. Bu model en iyi model olarak döndürülürse bir açıklama panosu döndürmez ve isteğe bağlı açıklama çalıştırmalarını desteklemez.
Sonraki adımlar
Modelin nasıl ve nereye dağıtılacağı hakkında daha fazla bilgi edinin.
Otomatik makine öğrenmesi ile regresyon modelini eğitme hakkında daha fazla bilgi edinin.
Otomatik ML denemelerinin sorunlarını giderme.