Azure Machine Learning SDK'sı ile makine öğrenmesi işlem hatları oluşturma ve çalıştırma
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Bu makalede, Azure Machine Learning SDK'sını kullanarak makine öğrenmesi işlem hatları oluşturmayı ve çalıştırmayı öğreneceksiniz. Çeşitli ML aşamalarını bir araya getiren bir iş akışı oluşturmak için ML işlem hatlarını kullanın. Daha sonra erişmek veya başkalarıyla paylaşmak için bu işlem hattını yayımlayın. Modelinizin gerçek dünyada nasıl performans sergilediğini görmek ve veri kayma durumunu algılamak için ML işlem hatlarını izleyin. ML işlem hatları, çeşitli işlemleri kullanarak, yeniden çalıştırmak yerine adımları yeniden kullanarak ve ML iş akışlarını başkalarıyla paylaşarak toplu puanlama senaryoları için idealdir.
Bu makale bir öğretici değildir. İlk işlem hattınızı oluşturma yönergeleri için bkz . Öğretici: Toplu puanlama için Azure Machine Learning işlem hattı oluşturma veya Python'da Azure Machine Learning işlem hattında otomatik ML kullanma.
ML görevlerinin CI/CD otomasyonu için Azure pipeline adlı farklı bir işlem hattı türü kullanabilirsiniz ancak bu işlem hattı türü çalışma alanınızda depolanmaz. Bu farklı işlem hatlarını karşılaştırın.
Oluşturduğunuz ML işlem hatları Azure Machine Learning çalışma alanınızın üyeleri tarafından görülebilir.
ML işlem hatları işlem hedeflerinde yürütülür (bkz . Azure Machine Learning'de işlem hedefleri nelerdir). İşlem hatları, desteklenen Azure Depolama konumlarına veri okuyabilir ve bu konumlardan veri yazabilir.
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun. Azure Machine Learning'in ücretsiz veya ücretli sürümünü deneyin.
Önkoşullar
Azure Machine Learning çalışma alanı. Çalışma alanı kaynakları oluşturun.
Geliştirme ortamınızı Azure Machine Learning SDK'sını yükleyecek şekilde yapılandırın veya SDK'nın zaten yüklü olduğu bir Azure Machine Learning işlem örneği kullanın.
Çalışma alanınızı ekleyerek başlayın:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Makine öğrenmesi kaynaklarını ayarlama
ML işlem hattını çalıştırmak için gereken kaynakları oluşturun:
İşlem hattı adımlarında gereken verilere erişmek için kullanılan bir veri deposu ayarlayın.
Bir nesneyi, veri
Datasetdeposunda bulunan veya veri deposunda erişilebilen kalıcı verilere işaret etmek için yapılandırın. İşlem hattı adımları arasında geçirilen geçici veriler için birOutputFileDatasetConfignesne yapılandırın.İşlem hattı adımlarınızın çalıştırılacağı işlem hedeflerini ayarlayın.
Veri deposu ayarlama
Veri deposu, işlem hattının erişecek verilerini depolar. Her çalışma alanının varsayılan veri deposu vardır. Daha fazla veri deposu kaydedebilirsiniz.
Çalışma alanınızı oluşturduğunuzda Azure Dosyalar ve Azure Blob depolama alanı çalışma alanına eklenir. Azure Blob depolamaya bağlanmak için varsayılan bir veri deposu kaydedilir. Daha fazla bilgi edinmek için bkz. Azure Dosyalar, Azure Blobları veya Azure Disklerinin ne zaman kullanılacağına karar verme.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
Adımlar genellikle verileri tüketir ve çıkış verileri üretir. Bir adım model, model ve bağımlı dosyalar içeren bir dizin veya geçici veriler gibi veriler oluşturabilir. Bu veriler daha sonra işlem hattındaki diğer adımlar için kullanılabilir. İşlem hattınızı verilerinize bağlama hakkında daha fazla bilgi edinmek için Verilere Erişme ve Veri Kümelerini Kaydetme makalelerine bakın.
ve OutputFileDatasetConfig nesneleriyle Dataset verileri yapılandırma
İşlem hattına veri sağlamanın tercih edilen yolu bir Dataset nesnesidir. Dataset nesnesi, veri deposunda veya Web URL'sinde bulunan veya erişilebilen verileri gösterir. Dataset sınıfı soyut olduğundan, sınırlandırılmış veri sütunları içeren bir veya daha fazla dosyadan oluşturulan bir FileDataset (bir veya daha fazla dosyaya başvuran) veya TabularDataset bir örneğini oluşturacaksınız.
from_files veya from_delimited_files gibi yöntemler kullanarak oluşturursunuzDataset.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Ara veriler (veya bir adımın çıktısı) bir OutputFileDatasetConfig nesnesiyle temsil edilir. output_data1 bir adımın çıktısı olarak oluşturulur. İsteğe bağlı olarak, bu veriler çağrılarak register_on_completeveri kümesi olarak kaydedilebilir. Bir adımda bir OutputFileDatasetConfig oluşturur ve bunu başka bir adıma giriş olarak kullanırsanız, adımlar arasındaki bu veri bağımlılığı işlem hattında örtük bir yürütme sırası oluşturur.
OutputFileDatasetConfig nesneleri bir dizin döndürür ve varsayılan olarak çıktıyı çalışma alanının varsayılan veri deposuna yazar.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Önemli
kullanılarak OutputFileDatasetConfig depolanan ara veriler Azure tarafından otomatik olarak silinmez.
İşlem hattı çalıştırmasının sonunda ara verileri program aracılığıyla silmeniz, kısa bir veri saklama ilkesine sahip bir veri deposu kullanmanız veya düzenli olarak el ile temizleme yapmanız gerekir.
İpucu
Yalnızca elinizde işe uygun dosyaları karşıya yükleyin. Veri dizinindeki dosyalarda yapılan her değişiklik, yeniden kullanım belirtilmiş olsa bile işlem hattının bir sonraki çalıştırılması sırasında adımı yeniden çalıştırma nedeni olarak görülür.
İşlem hedefi ayarlama
Azure Machine Learning'de işlem (veya işlem hedefi) terimi, makine öğrenmesi işlem hattınızdaki hesaplama adımlarını uygulayan makineleri veya kümeleri ifade eder. İşlem hedeflerinin tam listesi için model eğitimi için işlem hedeflerine ve bunları oluşturma ve çalışma alanınıza ekleme için İşlem hedefleri oluşturma bölümüne bakın. İster modeli eğitiyor ister işlem hattı adımı çalıştırıyor olun işlem hedefi oluşturma ve ekleme işlemi aynıdır. İşlem hedefinizi oluşturup ekledikten sonra işlem hattı adımınızda nesnesini kullanınComputeTarget.
Önemli
İşlem hedeflerinde yönetim işlemlerinin uzak işlerin içinden gerçekleştirilmesi desteklenmez. Makine öğrenmesi işlem hatları uzak iş olarak gönderildiğinden işlem hattının içinden işlem hedeflerinde yönetim işlemlerini kullanmayın.
Azure Machine Learning işlem
Adımlarınızı çalıştırmak için bir Azure Machine Learning işlem oluşturabilirsiniz. Diğer işlem hedeflerinin kodu, türüne bağlı olarak biraz farklı parametrelerle benzerdir.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Eğitim çalıştırmasının ortamını yapılandırma
Sonraki adım, uzaktan eğitim çalıştırmasının eğitim adımları için gereken tüm bağımlılıklara sahip olduğundan emin olmaktır. Bağımlılıklar ve çalışma zamanı bağlamı, bir RunConfiguration nesne oluşturulup yapılandırılarak ayarlanır.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
Yukarıdaki kodda bağımlılıkları işlemek için iki seçenek gösterilmektedir. ile birlikte gösterildiği gibi yapılandırma, USE_CURATED_ENV = Trueseçilmiş bir ortamı temel alır. Seçilmiş ortamlar, ortak bağımlı kitaplıklarla "önceden hazırlanmış"dır ve çevrimiçi hale getirmek daha hızlı olabilir. Seçilen ortamların Microsoft Container Registry'de önceden oluşturulmuş Docker görüntüleri vardır. Daha fazla bilgi için bkz . Azure Machine Learning'in seçilmiş ortamları.
olarak değiştirirseniz USE_CURATED_ENVFalse izlediğiniz yol, bağımlılıklarınızı açıkça ayarlama desenini gösterir. Bu senaryoda yeni bir özel Docker görüntüsü oluşturulur ve kaynak grubunuzdaki bir Azure Container Registry'ye kaydedilir (bkz . Azure'da özel Docker kapsayıcı kayıt defterlerine giriş). Bu görüntüyü oluşturmak ve kaydetmek birkaç dakika sürebilir.
İşlem hattı adımlarınızı oluşturma
İşlem kaynağını ve ortamını oluşturduktan sonra işlem hattınızın adımlarını tanımlamaya hazır olursunuz. Paketin başvuru belgelerinde azureml.pipeline.steps görebileceğiniz gibi Azure Machine Learning SDK'sı aracılığıyla kullanılabilecek birçok yerleşik adım vardır. En esnek sınıf, Python betiği çalıştıran PythonScriptStep'tir.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Yukarıdaki kod tipik bir ilk işlem hattı adımını gösterir. Veri hazırlama kodunuz bir alt dizindedir (bu örnekte dizininde "prepare.py""./dataprep.src"). İşlem hattı oluşturma işleminin bir parçası olarak, bu dizin daraltılır ve öğesine compute_target yüklenir ve adım değeri script_nameolarak belirtilen betiği çalıştırır.
Değerler, arguments adımın girişlerini ve çıkışlarını belirtir. Yukarıdaki örnekte temel veriler veri kümesidir my_dataset . Kod bunu olarak as_download()belirttiğinden ilgili veriler işlem kaynağına indirilir. Betik prepare.py , eldeki göreve uygun olan veri dönüştürme görevlerini gerçekleştirir ve veri output_data1çıkışını türünde OutputFileDatasetConfigolarak öğesine yapar. Daha fazla bilgi için bkz. ML işlem hattı adımlarına ve arasında veri taşıma (Python).
Adım, tarafından compute_targettanımlanan makinede yapılandırması aml_run_configkullanılarak çalıştırılır.
Gereksiz yeniden çalıştırmaların ortadan kaldırılması çeviklik sunduğundan, işlem hatlarını işbirliğine dayalı bir ortamda kullanırken önceki sonuçların (allow_reuse) yeniden kullanılması önemlidir. Script_name, girişler ve bir adımın parametreleri aynı kaldığında yeniden kullanma varsayılan davranıştır. Yeniden kullanılmasına izin verildiğinde, önceki çalıştırmanın sonuçları hemen bir sonraki adıma gönderilir. olarak ayarlanırsa allow_reuseFalse, işlem hattı yürütmesi sırasında bu adım için her zaman yeni bir çalıştırma oluşturulur.
Tek bir adımla işlem hattı oluşturmak mümkündür, ancak neredeyse her zaman genel işleminizi birkaç adıma bölmeyi seçersiniz. Örneğin, veri hazırlama, eğitim, model karşılaştırma ve dağıtım için adımlarınız olabilir. Örneğin, yukarıda belirtilenlerden data_prep_step sonra bir sonraki adımın eğitim olabileceğini düşünebilirsiniz:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Yukarıdaki kod, veri hazırlama adımındaki koda benzer. Eğitim kodu, veri hazırlama kodundan ayrı bir dizindedir. OutputFileDatasetConfig Veri hazırlama adımının çıkışı, output_data1 eğitim adımının girişi olarak kullanılır. Daha sonraki bir karşılaştırma veya dağıtım adımı için sonuçları tutmak üzere yeni OutputFileDatasetConfig bir nesne training_results oluşturulur.
Diğer kod örnekleri için bkz . İki aşamalı ml işlem hattı oluşturma ve çalıştırma tamamlandıktan sonra verileri veri depolarına geri yazma.
Adımlarınızı tanımladıktan sonra, bu adımların bazılarını veya tümünü kullanarak işlem hattını oluşturursunuz.
Not
Adımları tanımlarken veya işlem hattını oluştururken Azure Machine Learning'e hiçbir dosya veya veri yüklenmez. Experiment.submit() çağrısı yaptığınızda dosyalar karşıya yüklenir.
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Veri kümesi kullanma
Azure Blob depolama, Azure Dosyalar, Azure Data Lake Storage 1. Nesil, Azure Data Lake Storage 2. Nesil, Azure SQL Veritabanı ve PostgreSQL için Azure Veritabanı herhangi bir işlem hattı adımına giriş olarak kullanılabilir. Çıktıyı bir DataTransferStep, DatabricksStep dosyasına yazabilir veya belirli bir veri deposuna veri yazmak istiyorsanız OutputFileDatasetConfig kullanın.
Önemli
OutputFileDatasetConfig kullanarak çıkış verilerini geriye veri deposuna yazma işlemi yalnızca Azure Blob, Azure Dosya paylaşımı, ADLS 1. Nesil ve 2. Nesil veri depolarında desteklenir.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
Ardından Run.input_datasets sözlüğü kullanarak işlem hattınızdaki veri kümesini alırsınız.
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Çizgi Run.get_context() vurgulamak için değer. Bu işlev geçerli deneysel çalıştırmayı temsil eden bir Run alır. Yukarıdaki örnekte bunu kayıtlı bir veri kümesini almak için kullanırız. Nesnesinin Run bir diğer yaygın kullanımı da hem denemenin kendisini hem de denemenin bulunduğu çalışma alanını almaktır:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Verileri geçirmenin ve verilere erişmenin alternatif yolları da dahil olmak üzere daha fazla ayrıntı için bkz. ML işlem hattı adımlarına ve arasında veri taşıma (Python).
Önbelleğe Alma & yeniden kullan
İşlem hatlarınızın davranışını iyileştirmek ve özelleştirmek için önbelleğe alma ve yeniden kullanma ile ilgili birkaç şey yapabilirsiniz. Örneğin, şunları yapabilirsiniz:
- Adım tanımı sırasında ayar
allow_reuse=Falseyaparak adım çalıştırma çıkışının varsayılan yeniden kullanılmasını kapatın. gereksiz çalıştırmaların ortadan kaldırılması çeviklik sunduğundan, işlem hatlarını işbirliğine dayalı bir ortamda kullanırken yeniden kullanmak önemlidir. Ancak yeniden kullanımdan çıkabilirsiniz. - ile bir çalıştırmadaki tüm adımlar için çıkış yeniden oluşturmayı zorlama
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)
Varsayılan olarak, allow_reuse adımlar için etkindir ve source_directory adım tanımında belirtilen karmadır. Bu nedenle, belirli bir adımın betiği aynı kalırsa (script_namegirişler ve parametreler) ve içindeki başka source_directory hiçbir şey değişmediyse, önceki adım çalıştırmasının çıktısı yeniden kullanılır, iş işleme gönderilmez ve önceki çalıştırmanın sonuçları hemen sonraki adıma sunulur.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Not
Veri girişlerinin adları değişirse, temel alınan veriler değişmese bile adım yeniden çalıştırılır. Giriş verileridata.as_input(name=...) () alanını açıkça ayarlamanız name gerekir. Bu değeri açıkça ayarlamazsanız, name alan rastgele bir guid olarak ayarlanır ve adımın sonuçları yeniden kullanılmaz.
İşlem hattını gönderme
İşlem hattını gönderdiğinizde, Azure Machine Learning her adım için bağımlılıkları denetler ve belirttiğiniz kaynak dizinin anlık görüntüsünü karşıya yükler. Kaynak dizin belirtilmezse, geçerli yerel dizin karşıya yüklenir. Anlık görüntü, çalışma alanınızdaki denemenin bir parçası olarak da depolanır.
Önemli
Gereksiz dosyaların anlık görüntüye eklenmesini önlemek için dizinde bir yoksayma dosyası (.gitignore veya .amlignore) oluşturun. Dışlanacak dosyaları ve dizinleri bu dosyaya ekleyin. Bu dosyanın içinde kullanılacak söz dizimi hakkında daha fazla bilgi için bkz. söz dizimi ve desenleri..gitignore Dosya .amlignore aynı söz dizimini kullanır. Her iki dosya da varsa, .amlignore dosya kullanılır ve .gitignore dosya kullanılmaz.
Daha fazla bilgi için bkz . Anlık görüntüler.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
bir işlem hattını ilk çalıştırdığınızda Azure Machine Learning:
Proje anlık görüntüsünü çalışma alanıyla ilişkilendirilmiş Blob depolama alanından işlem hedefine indirir.
İşlem hattındaki her adıma karşılık gelen bir Docker görüntüsü oluşturur.
Kapsayıcı kayıt defterinden işlem hedefine her adım için Docker görüntüsünü indirir.
ve
OutputFileDatasetConfignesnelerineDataseterişimi yapılandırılır. Erişim modu içinas_mount()FUSE, sanal erişim sağlamak için kullanılır. Bağlama desteklenmiyorsa veya kullanıcı erişimi olarakas_upload()belirttiyse, veriler bunun yerine işlem hedefine kopyalanır.Adım tanımında belirtilen işlem hedefinde adımı çalıştırır.
Günlükler, stdout ve stderr, ölçümler ve adım tarafından belirtilen çıkış gibi yapıtlar oluşturur. Bu yapıtlar daha sonra karşıya yüklenir ve kullanıcının varsayılan veri deposunda tutulur.
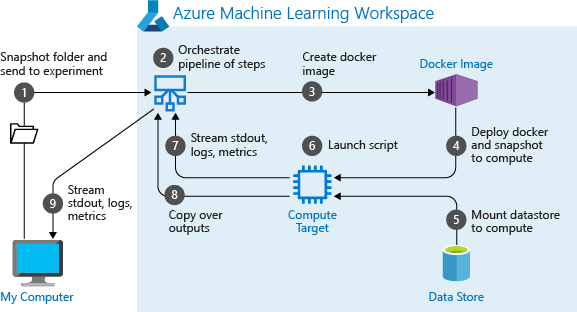
Daha fazla bilgi için deneme sınıfı başvurusuna bakın.
Çıkarım zamanında değişen bağımsız değişkenler için işlem hattı parametrelerini kullanma
Bazen, işlem hattı içindeki tek tek adımlara yönelik bağımsız değişkenler geliştirme ve eğitim dönemiyle ilgilidir: eğitim hızları ve ivme gibi şeyler ya da veri ya da yapılandırma dosyalarına giden yollar. Ancak bir model dağıtıldığında, çıkarım yaptığınız bağımsız değişkenleri dinamik olarak geçirmek istersiniz (yani, yanıtlamak için modeli oluşturduğunuz sorgu!). Bu tür bağımsız değişken işlem hattı parametreleri yapmalısınız. Bunu Python'da yapmak için aşağıdaki kod parçacığında gösterildiği gibi sınıfını kullanın azureml.pipeline.core.PipelineParameter :
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Python ortamları işlem hattı parametreleriyle nasıl çalışır?
Daha önce Eğitim çalıştırmasının ortamını yapılandırma bölümünde açıklandığı gibi, ortam durumu ve Python kitaplığı bağımlılıkları bir Environment nesne kullanılarak belirtilir. Genel olarak, var olan Environment bir sürümü adına ve isteğe bağlı olarak bir sürüme başvurarak belirtebilirsiniz:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Ancak, işlem hattı adımlarınız için çalışma zamanında değişkenleri dinamik olarak ayarlamak üzere nesneleri kullanmayı PipelineParameter seçerseniz, var olan Environmentbir öğesine başvurma tekniğini kullanamazsınız. Bunun yerine, nesneleri kullanmak PipelineParameter istiyorsanız, öğesinin environmentRunConfiguration alanını bir Environment nesne olarak ayarlamanız gerekir. Böyle bir Environment öğesinin dış Python paketlerine bağımlılıklarının düzgün ayarlandığından emin olmak sizin sorumluluğunuzdadır.
İşlem hattının sonuçlarını görüntüleme
Stüdyoda tüm işlem hatlarınızın ve bunların çalıştırma ayrıntılarının listesine bakın:
Azure Machine Learning stüdyosu oturum açın.
Çalışma alanınızı görüntüleyin.
Sol tarafta İşlem Hatları'nı seçerek tüm işlem hattı çalıştırmalarınızı görebilirsiniz.
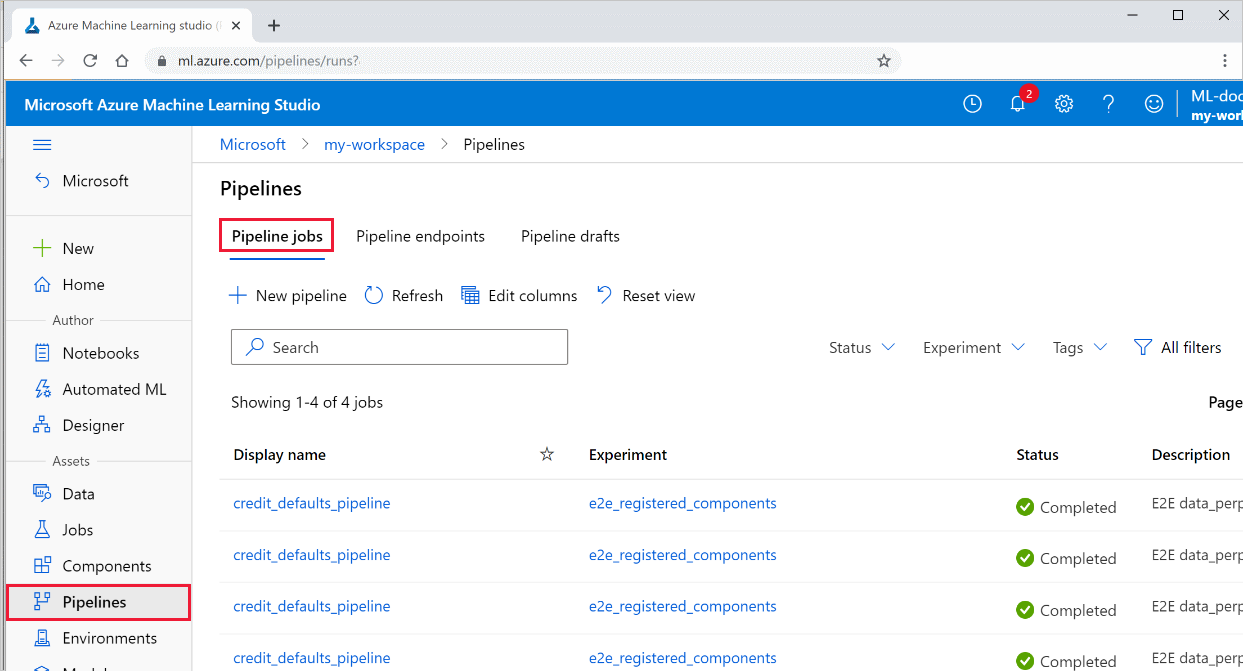
Çalıştırma sonuçlarını görmek için belirli bir işlem hattı seçin.
Git izleme ve tümleştirme
Kaynak dizinin yerel git deposu olduğu bir eğitim çalıştırması başlattığınızda, depo hakkındaki bilgiler çalıştırma geçmişinde depolanır. Daha fazla bilgi için bkz . Azure Machine Learning için Git tümleştirmesi.
Sonraki adımlar
- İşlem hattınızı iş arkadaşlarınızla veya müşterilerinizle paylaşmak için bkz . Makine öğrenmesi işlem hatlarını yayımlama
- Makine öğrenmesi işlem hatlarını daha fazla keşfetmek için GitHub'da bu Jupyter not defterlerini kullanın
- azureml-pipelines-core paketi ve azureml-pipelines-steps paketi için SDK başvuru yardımına bakın
- İşlem hatlarında hata ayıklama ve sorun giderme hakkında ipuçları için nasıl yapılır bölümüne bakın=
- Not defterlerini çalıştırmayı öğrenmek için bkz. Hizmeti keşfetmek için Jupyter not defterlerini kullanma.