Veri kayma (önizleme) kullanımdan kaldırılacak ve model izleyicisi tarafından değiştirilecek
Veri kayma (önizleme) 01.09.2025'te kullanımdan kaldırılacak ve veri kayma görevleriniz için Model İzleyici'yi kullanmaya başlayabilirsiniz. Değiştirme, özellik boşluklarını ve el ile değiştirme adımlarını anlamak için lütfen aşağıdaki içeriği kontrol edin.
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Python SDK azureml v1
Veri kaymayı izlemeyi ve kayma yüksek olduğunda uyarılar ayarlamayı öğrenin.
Not
Azure Machine Learning model izleme (v2), sinyalleri ve ölçümleri izlemeye yönelik ek işlevlerin yanı sıra veri kayma için gelişmiş özellikler sağlar. Azure Machine Learning'de (v2) model izleme özellikleri hakkında daha fazla bilgi edinmek için bkz . Azure Machine Learning ile model izleme.
Azure Machine Learning veri kümesi izleyicileri (önizleme) ile şunları yapabilirsiniz:
- Zaman içinde nasıl değiştiğini anlamak için verilerinizdeki kaymayı analiz edin.
- Eğitim ve hizmet veri kümeleri arasındaki farklar için model verilerini izleyin. Dağıtılan modellerden model verileri toplayarak başlayın.
- Herhangi bir temel ve hedef veri kümesi arasındaki farklar için yeni verileri izleyin.
- İstatistiksel özelliklerin zaman içinde nasıl değiştiğini izlemek için verilerdeki özelliklerin profilini oluşturma.
- Olası sorunlara yönelik erken uyarılar için veri kayarak uyarıları ayarlayın.
- Verilerin çok fazla kaydığını saptadığınızda yeni bir veri kümesi sürümü oluşturun.
İzleyiciyi oluşturmak için bir Azure Machine Learning veri kümesi kullanılır. Veri kümesi bir zaman damgası sütunu içermelidir.
Veri kayma ölçümlerini Python SDK'sı ile veya Azure Machine Learning stüdyosu görüntüleyebilirsiniz. Diğer ölçümler ve içgörüler, Azure Machine Learning çalışma alanıyla ilişkili Azure Uygulaması lication Insights kaynağı aracılığıyla sağlanır.
Önemli
Veri kümeleri için veri kayması algılaması şu anda genel önizleme aşamasındadır. Önizleme sürümü bir hizmet düzeyi sözleşmesi olmadan sağlanır ve üretim iş yükleri için önerilmez. Bazı özellikler desteklenmiyor olabileceği gibi özellikleri sınırlandırılmış da olabilir. Daha fazla bilgi için bkz. Microsoft Azure Önizlemeleri Ek Kullanım Koşulları.
Önkoşullar
Veri kümesi izleyicileri oluşturmak ve bunlarla çalışmak için şunları yapmanız gerekir:
- Azure aboneliği. Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun. Azure Machine Learning'in ücretsiz veya ücretli sürümünü bugün deneyin.
- Azure Machine Learning çalışma alanı.
- Azureml-datasets paketini içeren Python için Azure Machine Learning SDK'sı yüklüdür.
- Verilerdeki dosya yolunda, dosya adında veya sütununda belirtilen bir zaman damgası ile yapılandırılmış (tablosal) veriler.
Önkoşullar (Model İzleyicisine Geçiş)
Model İzleyici'ye geçiş yaparken lütfen Azure Machine Learning model izleme önkoşulları makalesinde belirtildiği gibi önkoşulları denetleyin.
Veri kayma nedir?
Model doğruluğu, büyük ölçüde veri kaydığı için zaman içinde düşer. Makine öğrenmesi modellerinde veri kayması, model giriş verilerinde model performansında düşüşe yol açan değişikliktir. Veri kaymasını izleme, bu model performans sorunlarının algılanmasında yardımcı olur.
Veri kayma nedenleri şunlardır:
- Yukarı akış işlemi, ölçü birimlerini inçten santimetreye değiştiren bir algılayıcının değiştirilmesi gibi değişir.
- Bozuk bir algılayıcının her zaman 0 okuması gibi veri kalitesi sorunları.
- Mevsimlerle değişen ortalama sıcaklık gibi verilerdeki doğal kayma.
- Özellikler arasındaki ilişkide değişiklik yapın veya vardiyayı birlikte sabitler.
Azure Machine Learning, karşılaştırılan veri kümelerinin karmaşıklığını soyutlayan tek bir ölçümü hesaplayarak kayma algılamayı basitleştirir. Bu veri kümelerinin yüzlerce özelliği ve on binlerce satırı olabilir. Kayma algılandıktan sonra, hangi özelliklerin kaymaya neden olduğunu detaya gidin. Ardından, kaymanın kök nedeninin hatalarını ayıklamak ve yalıtmak için özellik düzeyi ölçümlerini incelersiniz.
Bu yukarıdan aşağıya yaklaşım, geleneksel kural tabanlı teknikler yerine verileri izlemeyi kolaylaştırır. İzin verilen veri aralığı veya izin verilen benzersiz değerler gibi kural tabanlı teknikler zaman alabilir ve hataya açık olabilir.
Azure Machine Learning'de veri kayma durumunu algılamak ve uyarmak için veri kümesi izleyicilerini kullanırsınız.
Veri kümesi izleyicileri
Veri kümesi izleyicisi ile yapabilecekleri:
- Bir veri kümesindeki yeni verilerde veri kaymasını algılama ve bu veri kaymalarına karşı uyarı verme.
- Kayma için geçmiş verileri analiz etme.
- Zaman içinde yeni verilerin profilini oluşturma.
Veri kayma algoritması, verilerdeki değişikliğin genel bir ölçüsünü ve hangi özelliklerin daha fazla araştırmadan sorumlu olduğunu gösterir. Veri kümesi izleyicileri, veri kümesindeki timeseries yeni verilerin profilini oluşturarak başka birçok ölçüm oluşturur.
özel uyarı, Azure Uygulaması lication Insights aracılığıyla izleyici tarafından oluşturulan tüm ölçümlerde ayarlanabilir. Veri kümesi izleyicileri, olası nedenleri belirleyerek veri sorunlarını hızla yakalamak ve sorunun hatalarını ayıklama süresini kısaltmak için kullanılabilir.
Kavramsal olarak, Azure Machine Learning'de veri kümesi izleyicilerini ayarlamak için üç birincil senaryo vardır.
| Senaryo | Açıklama |
|---|---|
| Modelin eğitim verilerinden sapma için veri sunmasını izleme | Sunum verileri eğitim verilerinden kaydığında model doğruluğu azaldığından, bu senaryonun sonuçları modelin doğruluğu için bir ara sunucuyu izleme olarak yorumlanabilir. |
| Önceki bir zaman aralığından sapma için bir zaman serisi veri kümesini izleyin. | Bu senaryo daha geneldir ve model oluşturmanın yukarı veya aşağı akışında yer alan veri kümelerini izlemek için kullanılabilir. Hedef veri kümesinin zaman damgası sütunu olmalıdır. Temel veri kümesi, hedef veri kümesiyle ortak özelliklere sahip olan herhangi bir tablosal veri kümesi olabilir. |
| Geçmiş veriler üzerinde analiz gerçekleştirme. | Bu senaryo, geçmiş verileri anlamak ve veri kümesi izleyicileri için ayarlardaki kararları bilgilendirmek için kullanılabilir. |
Veri kümesi izleyicileri aşağıdaki Azure hizmetlerine bağlıdır.
| Azure hizmeti | Açıklama |
|---|---|
| Dataset | Drift, eğitim verilerini almak ve model eğitimi için verileri karşılaştırmak için Machine Learning veri kümelerini kullanır. Veri profili oluşturma, bildirilen ölçümlerden min, max, distinct values, distinct values count gibi bazı ölçümler oluşturmak için kullanılır. |
| Azure Machine Learning işlem hattı ve işlem | Kayma hesaplama işi bir Azure Machine Learning işlem hattında barındırılır. İş, isteğe bağlı olarak veya kayma izleyicisi oluşturma zamanında yapılandırılmış bir işlemde çalışacak şekilde zamanlamaya göre tetiklenir. |
| Application Insights | Drift, ölçümleri makine öğrenmesi çalışma alanına ait Application Insights'a yayar. |
| Azure blob depolama | Kayma, ölçümleri json biçiminde Azure blob depolamaya yayar. |
Temel ve hedef veri kümeleri
Veri kayma için Azure Machine Learning veri kümelerini izlersiniz. Veri kümesi izleyicisi oluşturduğunuzda aşağıdakilere başvurursunuz:
- Temel veri kümesi - genellikle modelin eğitim veri kümesidir.
- Hedef veri kümesi (genellikle model giriş verileri) zaman içinde temel veri kümenizle karşılaştırılır. Bu karşılaştırma, hedef veri kümenizin bir zaman damgası sütunu belirtmiş olması gerektiği anlamına gelir.
İzleyici, temel ve hedef veri kümelerini karşılaştırır.
Model İzleyicisi'ne geçiş
Model İzleyici'de ilgili kavramları aşağıdaki gibi bulabilir ve üretim verilerinizi Azure Machine Learning'e getirerek model izlemeyi ayarlama makalesinde daha fazla ayrıntı bulabilirsiniz:
- Başvuru veri kümesi: Veri kayması algılaması için temel veri kümenize benzer şekilde, yakın zamanda geçmiş üretim çıkarım veri kümesi olarak ayarlanır.
- Üretim çıkarım verileri: Veri kayması algılamadaki hedef veri kümenize benzer şekilde, üretim çıkarım verileri üretimde dağıtılan modellerden otomatik olarak toplanabilir. Depoladığınız çıkarım verileri de olabilir.
Hedef veri kümesi oluşturma
Hedef veri kümesinin timeseries , verilerdeki bir sütundan veya dosyaların yol deseninden türetilmiş bir sanal sütundan zaman damgası sütununu belirterek bu veri kümesinde ayarlanan özellik gerekir. Veri kümesini Python SDK veya Azure Machine Learning stüdyosu aracılığıyla bir zaman damgasıyla oluşturun. Veri kümesine özellik eklemek timeseries için "zaman damgasını" temsil eden bir sütun belirtilmelidir. Verileriniz '{y/MM/dd}' gibi zaman bilgileriyle klasör yapısına bölümlenmişse, yol deseni ayarı aracılığıyla bir sanal sütun oluşturun ve zaman serisi API'sinin işlevselliğini etkinleştirmek için bunu "bölüm zaman damgası" olarak ayarlayın.
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
sınıf with_timestamp_columns() yöntemi, Dataset veri kümesi için zaman damgası sütununu tanımlar.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
İpucu
Veri kümelerinin özelliklerini kullanmanın timeseries tam örneği için örnek not defterine veya veri kümeleri SDK'sı belgelerine bakın.

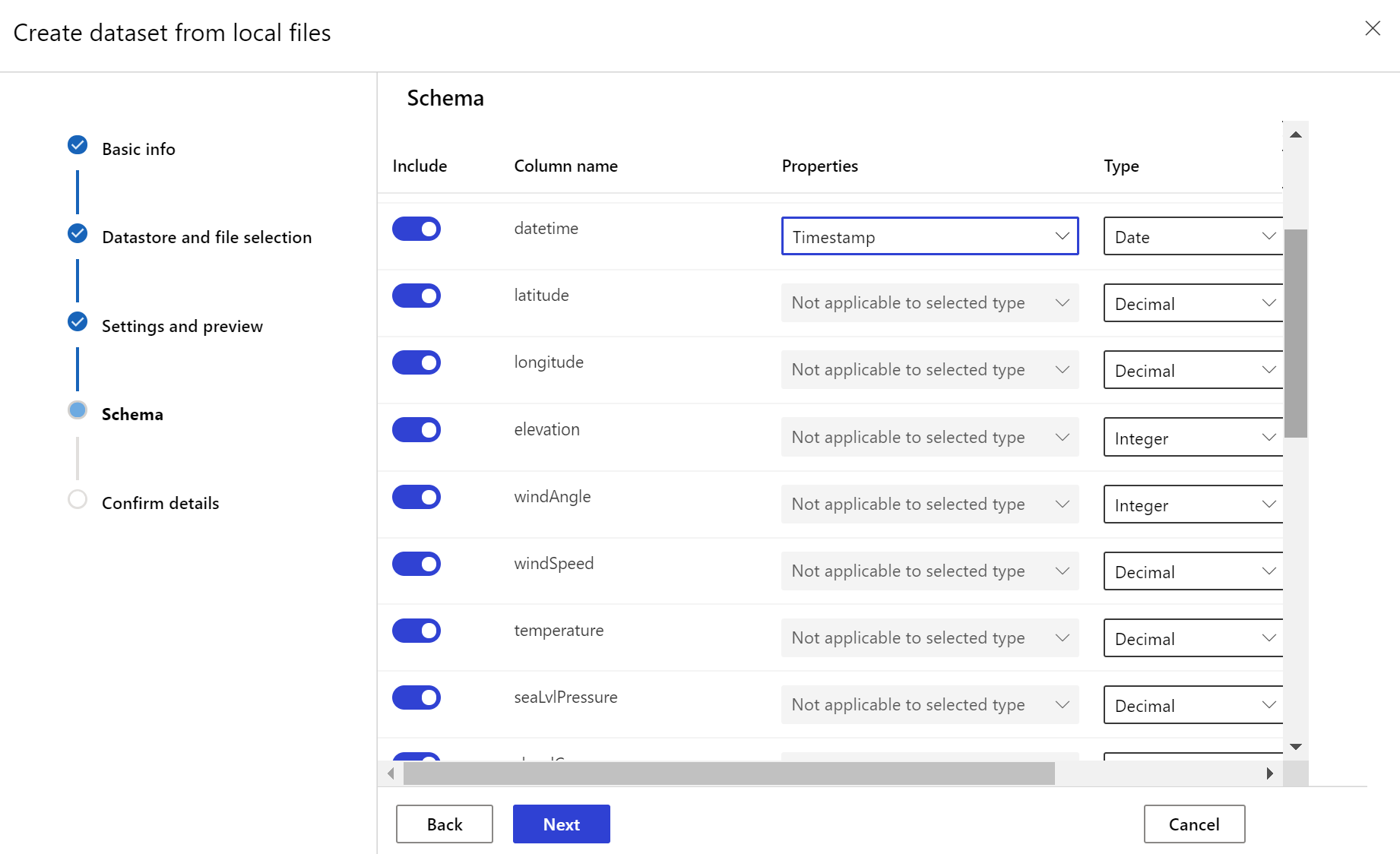
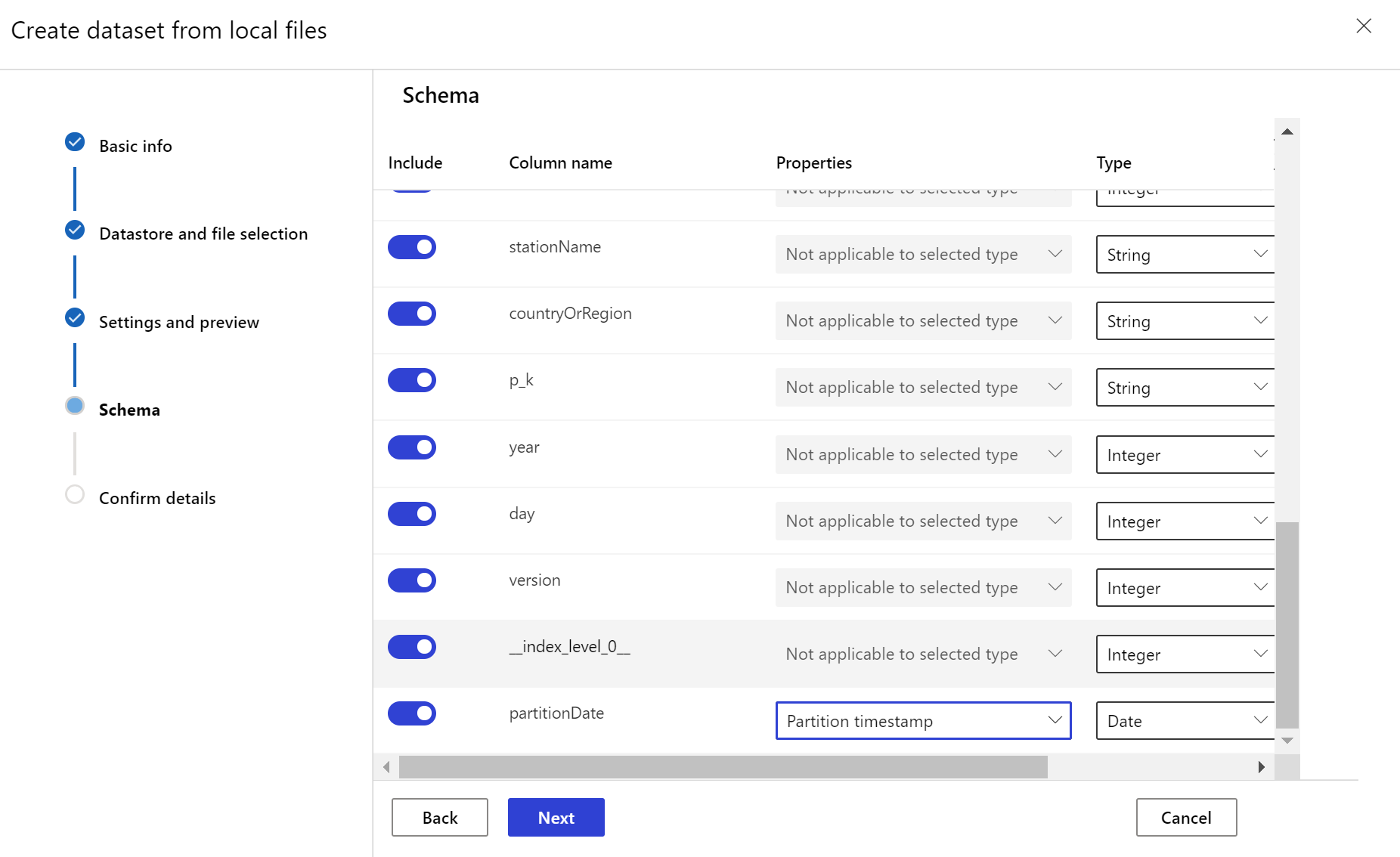
Veri kümesi izleyicisi oluşturma
Yeni bir veri kümesindeki veri kayma durumunu algılamak ve uyarı vermek için bir veri kümesi izleyicisi oluşturun. Python SDK'sını veya Azure Machine Learning stüdyosu kullanın.
Daha sonra açıklandığı gibi, veri kümesi izleyicisi belirlenen sıklıkta (günlük, haftalık, aylık) çalışır. Son çalıştırmadan bu yana hedef veri kümesinde kullanılabilen yeni verileri analiz eder. Bazı durumlarda, en son verilerin bu şekilde analiz edilmesi yeterli olmayabilir:
- Yukarı akış kaynağındaki yeni veriler bozuk bir veri işlem hattı nedeniyle geciktirildi ve veri kümesi izleyicisi çalıştığında bu yeni veriler kullanılamıyordu.
- Zaman serisi veri kümesinde yalnızca geçmiş verileri vardı ve zaman içinde veri kümesindeki kayma desenlerini analiz etmek istiyorsunuz. Örneğin: Mevsimsel desenleri belirlemek için hem kış hem de yaz mevsimlerinde bir web sitesine akan trafiği karşılaştırın.
- Veri Kümesi İzleyicileri'ni yeni kullanıyorsunuz. Gelecek günleri izlemek üzere ayarlamadan önce özelliğin mevcut verilerinizle nasıl çalıştığını değerlendirmek istiyorsunuz. Bu tür senaryolarda, temel veri kümesiyle karşılaştırmak için belirli bir hedef veri kümesi ayarlanmış tarih aralığına sahip isteğe bağlı bir çalıştırma gönderebilirsiniz.
Backfill işlevi, belirtilen başlangıç ve bitiş tarihi aralığı için bir geri doldurma işi çalıştırır. Bir geri doldurma işi, veri doğruluğunu ve eksiksizliğini sağlamanın bir yolu olarak veri kümesindeki beklenen eksik veri noktalarını doldurur.
Not
Azure Machine Learning model izlemesi el ile doldurma işlevini desteklemez. Model izleyicisini belirli bir zaman aralığı için yeniden uygulamak istiyorsanız, bu belirli bir zaman aralığı için başka bir model izleyicisi oluşturabilirsiniz.
ŞUNUN IÇIN GEÇERLIDIR: Python SDK azureml v1
Tüm ayrıntılar için veri kaymayla ilgili Python SDK başvuru belgelerine bakın.
Aşağıdaki örnekte Python SDK'sını kullanarak bir veri kümesi izleyicisinin nasıl oluşturulacağı gösterilmektedir:
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
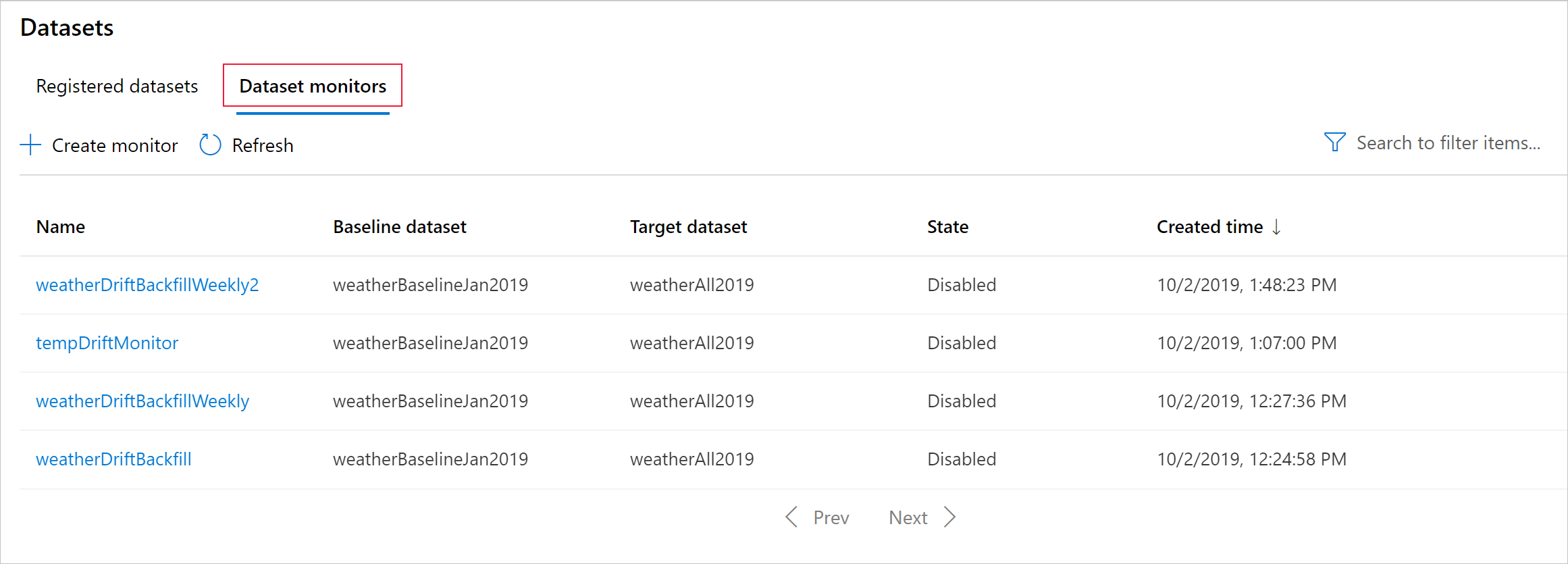
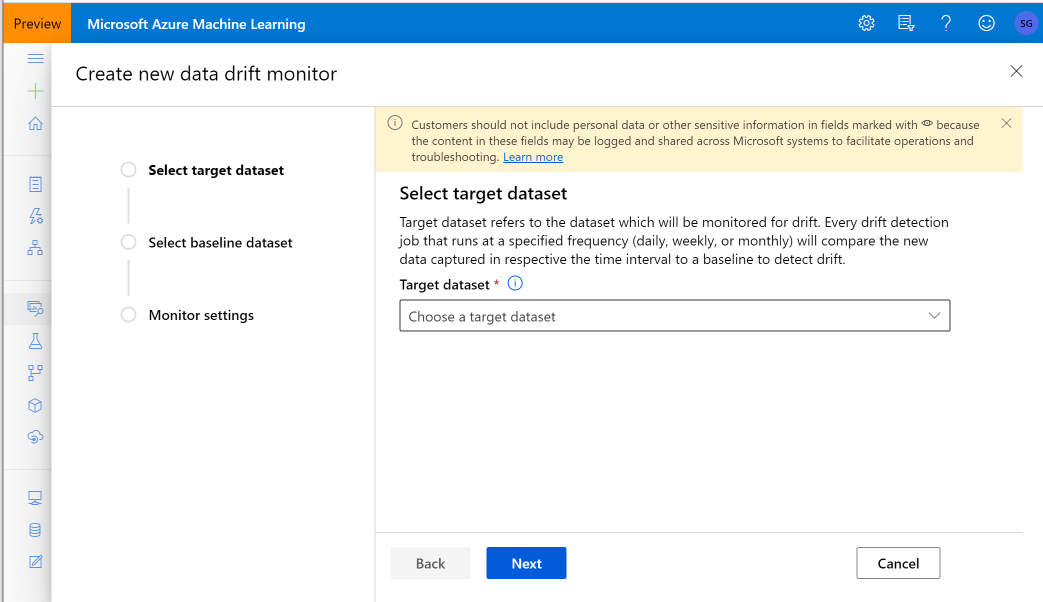
Model İzleyicisi Oluşturma (Model İzleyicisine Geçiş)
Model İzleyici'ye geçiş yaptığınızda, modelinizi bir Azure Machine Learning çevrimiçi uç noktasında üretime dağıttıysanız ve dağıtım zamanında veri toplamayı etkinleştirdiyseniz, Azure Machine Learning üretim çıkarım verilerini toplar ve otomatik olarak Microsoft Azure Blob Depolama'de depolar. Ardından bu üretim çıkarım verilerini sürekli izlemek için Azure Machine Learning model izlemesini kullanabilir ve hedef veri kümesi oluşturmak için modeli doğrudan seçebilirsiniz (Model İzleyicisi'nde üretim çıkarım verileri).
Model İzleyici'ye geçiş yaptığınızda, modelinizi bir Azure Machine Learning çevrimiçi uç noktasında üretime dağıtmadıysanız veya veri toplamayı kullanmak istemiyorsanız, özel sinyaller ve ölçümlerle model izlemeyi de ayarlayabilirsiniz.
Aşağıdaki bölümlerde Model İzleyici'ye geçiş hakkında daha fazla ayrıntı yer almaktadır.
Otomatik olarak toplanan üretim verileri aracılığıyla Model İzleyicisi oluşturma (Model İzleyicisi'ne Geçiş)
Modelinizi bir Azure Machine Learning çevrimiçi uç noktasında üretime dağıttıysanız ve dağıtım zamanında veri toplamayı etkinleştirdiyseniz.
İlk çalıştırma modeli izlemeyi ayarlamak için aşağıdaki kodu kullanabilirsiniz:
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Özel veri ön işleme bileşeni aracılığıyla Model İzleyicisi oluşturma (Model İzleyicisine Geçiş)
Model İzleyici'ye geçiş yaptığınızda, modelinizi bir Azure Machine Learning çevrimiçi uç noktasında üretime dağıtmadıysanız veya veri toplamayı kullanmak istemiyorsanız, özel sinyaller ve ölçümlerle model izlemeyi de ayarlayabilirsiniz.
Dağıtımınız yoksa ancak üretim verileriniz varsa, verileri kullanarak sürekli model izleme gerçekleştirebilirsiniz. Bu modelleri izlemek için şunları yapabilmeniz gerekir:
- Üretimde dağıtılan modellerden üretim çıkarım verilerini toplayın.
- Üretim çıkarım verilerini Azure Machine Learning veri varlığı olarak kaydedin ve verilerin sürekli güncelleştirildiğinden emin olun.
- Özel bir veri ön işleme bileşeni sağlayın ve bunu Azure Machine Learning bileşeni olarak kaydedin.
Verileriniz veri toplayıcı ile toplanmadıysa, özel bir veri ön işleme bileşeni sağlamanız gerekir. Bu özel veri ön işleme bileşeni olmadan, Azure Machine Learning model izleme sistemi zaman penceresi desteğiyle verilerinizi tablo biçiminde işlemeyi bilmez.
Özel ön işleme bileşeniniz şu giriş ve çıkış imzalarına sahip olmalıdır:
| Giriş/Çıkış | İmza adı | Type | Açıklama | Örnek değer |
|---|---|---|---|---|
| input | data_window_start |
değişmez değer, dize | ISO8601 biçimde veri penceresi başlangıç zamanı. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
değişmez değer, dize | ISO8601 biçimde veri penceresi bitiş zamanı. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Toplanan üretim çıkarımı verileri, Azure Machine Learning veri varlığı olarak kaydedilir. | azureml:myproduction_inference_data:1 |
| çıkış | preprocessed_data |
mltable | Başvuru veri şemasının bir alt kümesiyle eşleşen tablosal veri kümesi. |
Özel veri ön işleme bileşeni örneği için bkz . azuremml-examples GitHub deposundaki custom_preprocessing.
Veri kayma sonuçlarını anlama
Bu bölümde, Azure Studio'nun Veri Kümeleri Veri Kümesi izleyicileri / sayfasında bulunan bir veri kümesini izlemenin sonuçları gösterilir. Ayarları güncelleştirebilir ve mevcut verileri bu sayfada belirli bir zaman aralığı için analiz edebilirsiniz.
Veri kaymalarının büyüklüğü ve daha fazla araştırılacak özelliklerin vurgulanmasıyla ilgili üst düzey içgörülerle başlayın.
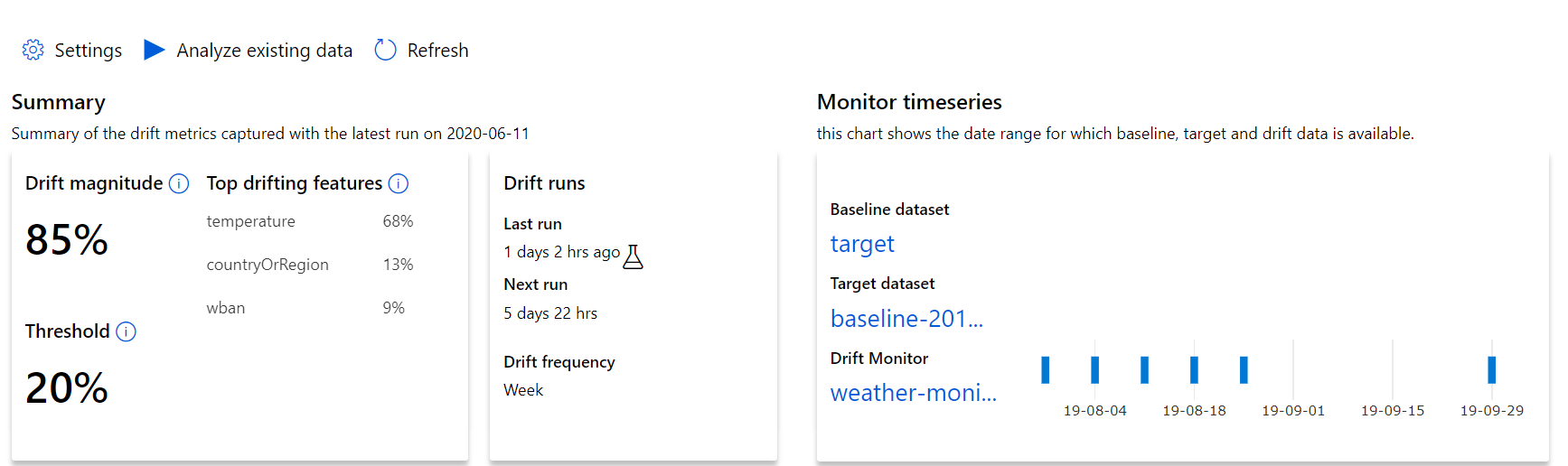
| Metrik Sistem | Açıklama |
|---|---|
| Veri kayma büyüklüğü | Zaman içinde temel ile hedef veri kümesi arasında kayma yüzdesi. Bu yüzde 0 ile 100 arasında değişir, 0 aynı veri kümelerini gösterir ve 100, Azure Machine Learning veri kayma modelinin iki veri kümesini birbirinden tamamen ayırt edebilir. Bu büyüklüğü oluşturmak için kullanılan makine öğrenmesi tekniklerinden dolayı, ölçülen hassas yüzdedeki kirlilik beklenir. |
| En çok sürüklenen özellikler | Veri kümesinden en çok kaymış olan ve bu nedenle Drift Magnitude ölçümüne en çok katkıda bulunan özellikleri gösterir. Birlikte değişken kaydırma nedeniyle, bir özelliğin temel dağılımının görece yüksek özellik önemine sahip olması için değişmesi gerekmez. |
| Threshold | Ayarlanan eşiğin ötesindeki Veri Kayma büyüklüğü uyarıları tetikler. İzleyici ayarlarında eşik değerini yapılandırın. |
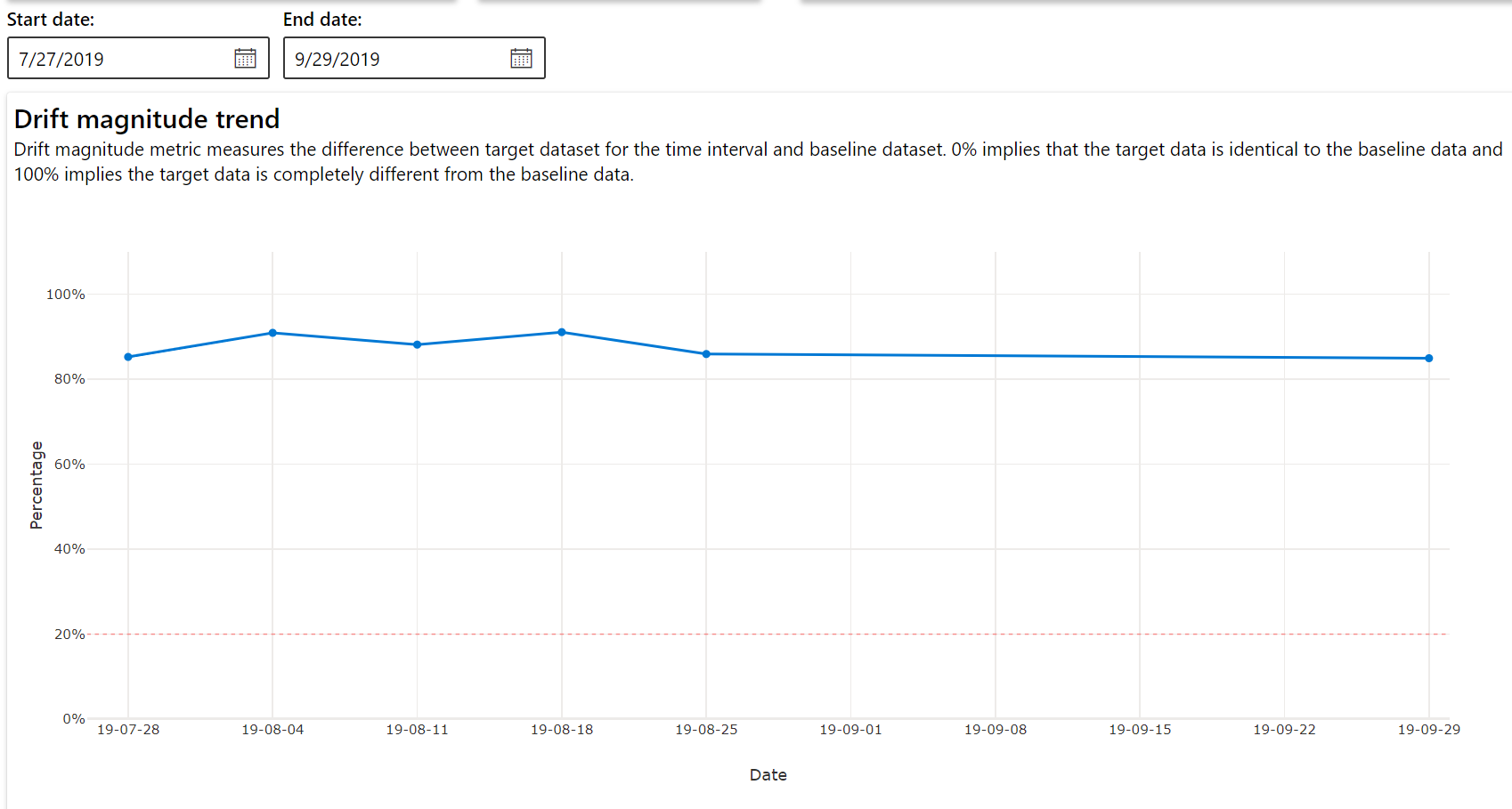
Kayma büyüklüğü eğilimi
Veri kümesinin belirtilen zaman aralığındaki hedef veri kümesinden nasıl farklı olduğunu görün. %100'e yaklaştıkça iki veri kümesi o kadar farklılık gösterir.
Özelliklere göre kayma büyüklüğü
Bu bölüm, seçilen özelliğin dağılımındaki değişiklik ve zaman içindeki diğer istatistikler hakkında özellik düzeyinde içgörüler içerir.
Hedef veri kümesinin profili de zaman içinde oluşturulur. Her özelliğin temel dağılımı arasındaki istatistiksel uzaklık, zaman içindeki hedef veri kümesiyle karşılaştırılır. Kavramsal olarak bu, veri kayma büyüklüğüne benzer. Ancak bu istatistiksel uzaklık tüm özellikler yerine tek bir özellik içindir. Min, max ve mean da kullanılabilir.
Azure Machine Learning stüdyosu, bu tarihe ilişkin özellik düzeyi ayrıntılarını görmek için grafikte bir çubuk seçin. Varsayılan olarak, temel veri kümesinin dağıtımını ve aynı özelliğin en son işinin dağıtımını görürsünüz.
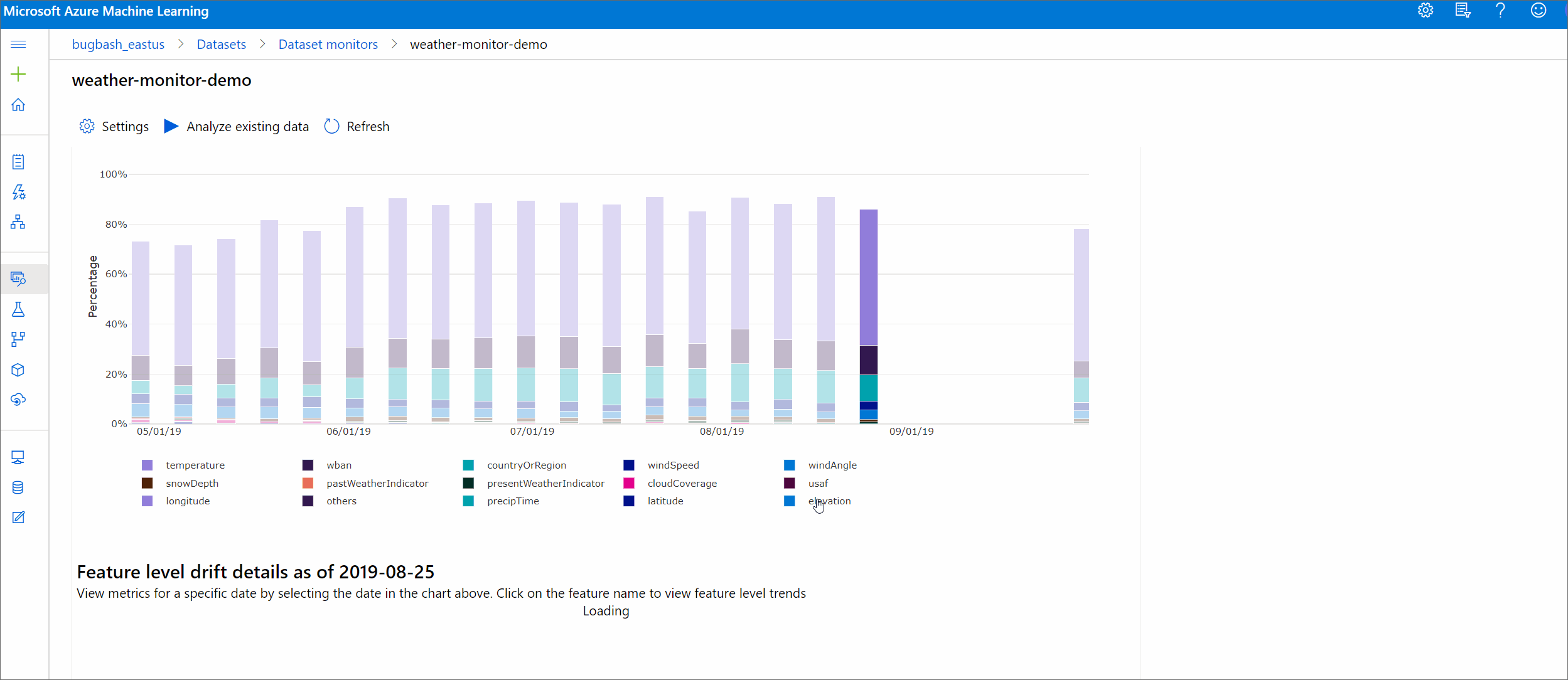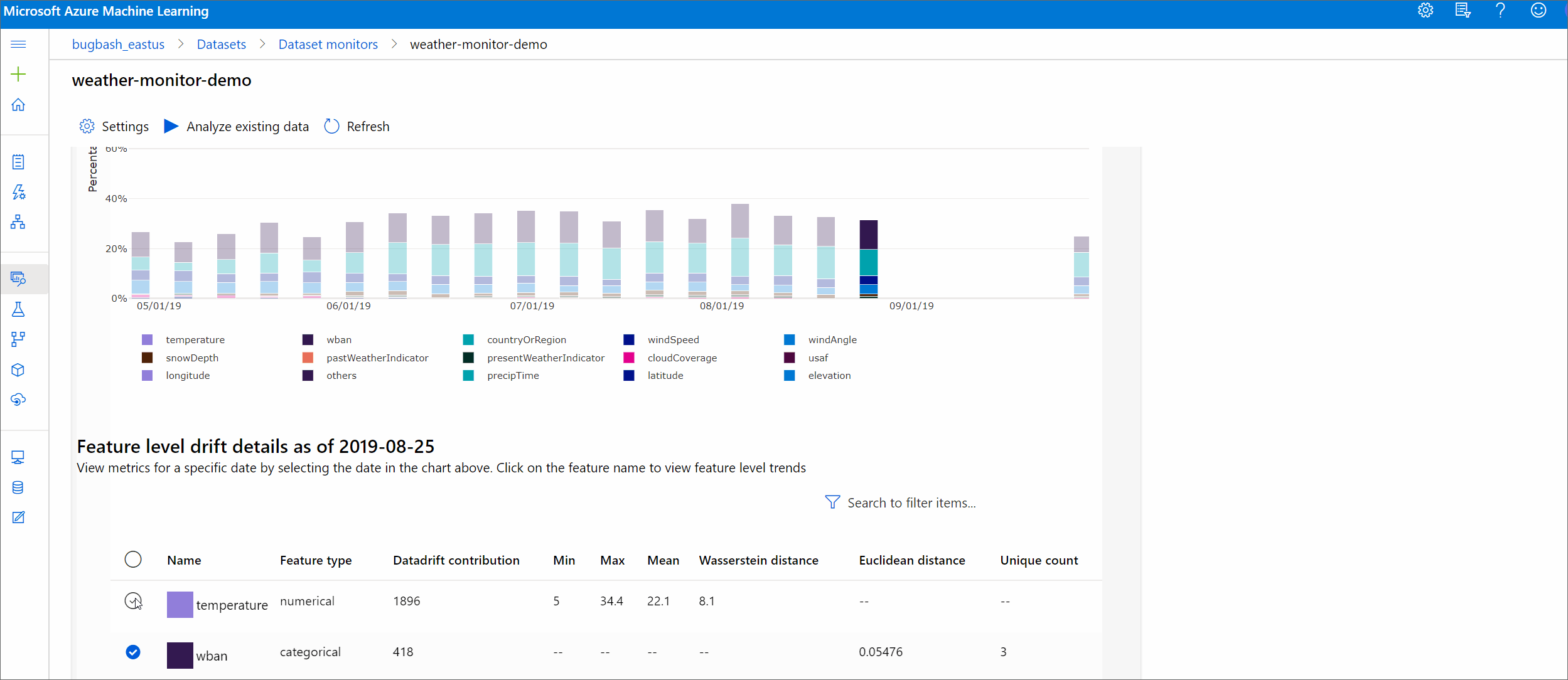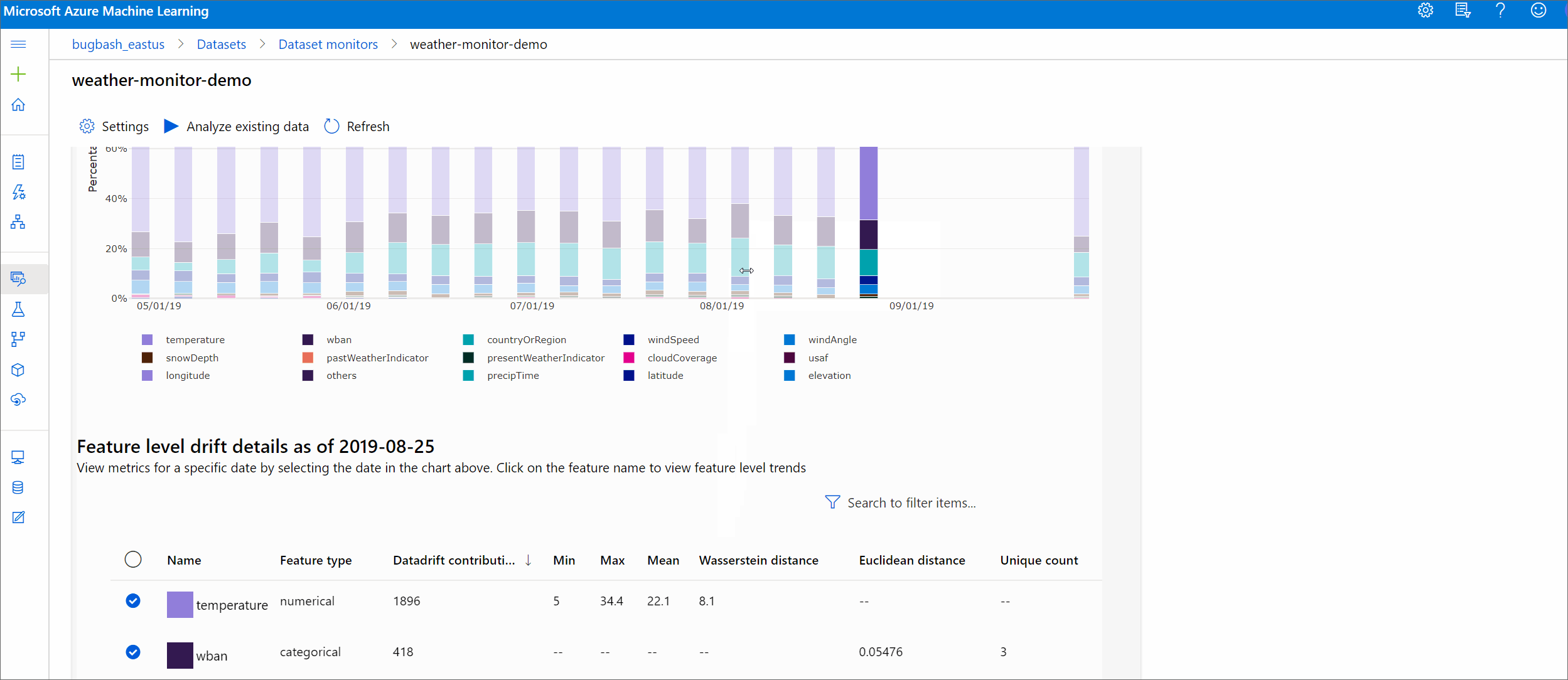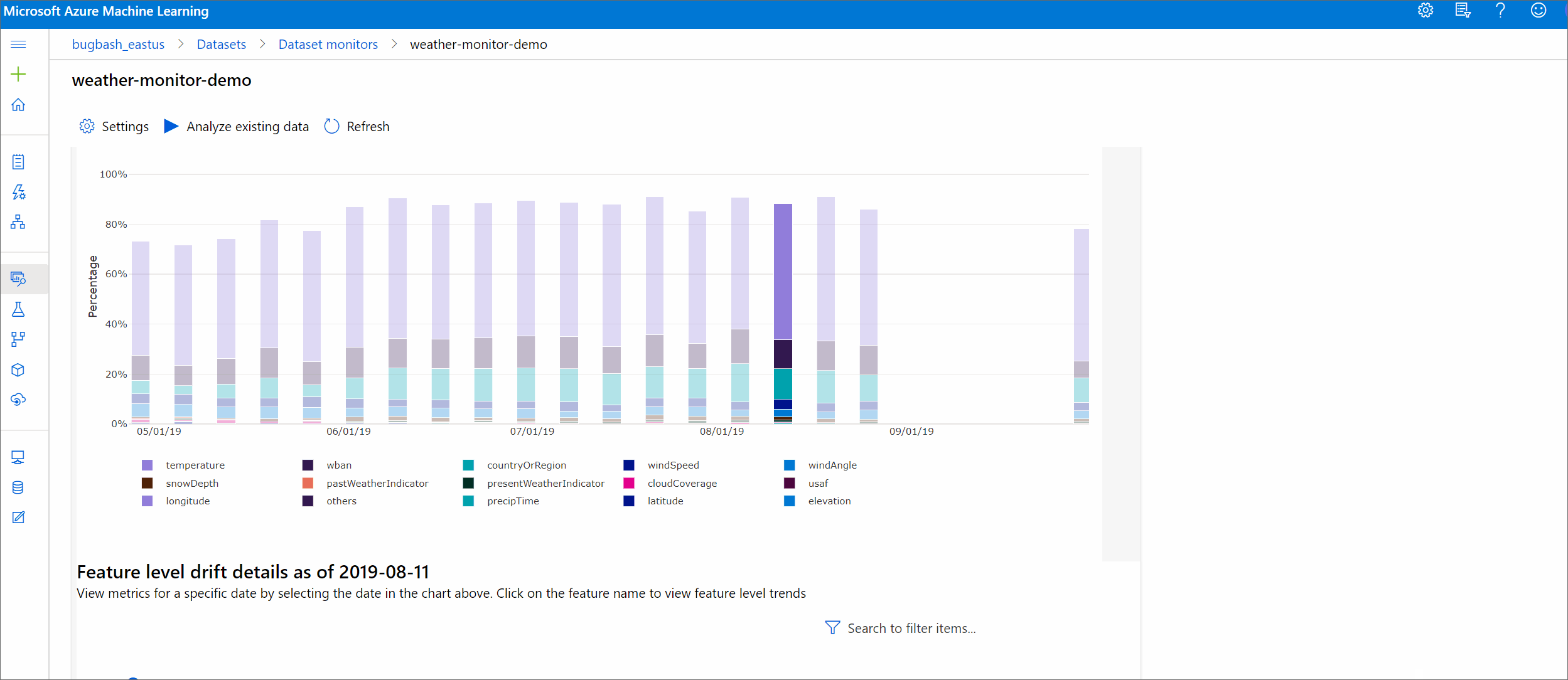
Bu ölçümler python SDK'sında bir DataDriftDetector nesnedeki get_metrics() yöntemi aracılığıyla da alınabilir.
Özellik ayrıntıları
Son olarak, her bir özelliğin ayrıntılarını görüntülemek için aşağı kaydırın. Özelliği seçmek için grafiğin üzerindeki açılan menüleri kullanın ve ayrıca görüntülemek istediğiniz ölçümü seçin.
Grafikteki ölçümler özelliğin türüne bağlıdır.
Sayısal özellikler
Metrik Sistem Açıklama Wasserstein uzaklığı Temel dağılımı hedef dağıtıma dönüştürmek için gereken minimum çalışma miktarı. Ortalama değer Özelliğin ortalama değeri. En düşük değer Özelliğin en düşük değeri. En yüksek değer Özelliğin en yüksek değeri. Kategorik özellikler
Metrik Sistem Açıklama Öklid mesafe Kategorik sütunlar için hesaplanır. Öklid uzaklığı, aynı kategorik sütunun iki veri kümesinden ampirik dağılımından oluşturulan iki vektörde hesaplanır. 0, ampirik dağılımlarda hiçbir fark olmadığını gösterir. 0'dan ne kadar saparsa, bu sütun o kadar kaymıştır. Eğilimler, bu ölçümün zaman serisi çiziminden gözlemlenebilir ve bir kayma özelliğinin ortaya çıkarılmasında yararlı olabilir. Benzersiz değerler Özelliğin benzersiz değerleri (kardinalitesi) sayısı.
Bu grafikte, görüntülenen özelliğin hedef ve bu tarih arasındaki özellik dağılımını karşılaştırmak için tek bir tarih seçin. Sayısal özellikler için iki olasılık dağılımı gösterilir. Özellik sayısalsa çubuk grafik gösterilir.
Ölçümler, uyarılar ve olaylar
Ölçümler, makine öğrenmesi çalışma alanınızla ilişkili Azure Uygulaması lication Insights kaynağında sorgulanabilir. E-posta/SMS/Gönderme/Ses veya Azure İşlevi gibi bir eylemi tetikleyen özel uyarı kuralları ve eylem grupları için ayarlama da dahil olmak üzere Application Insights'ın tüm özelliklerine erişebilirsiniz. Ayrıntılar için application insights belgelerinin tamamına bakın.
Başlamak için Azure portalına gidin ve çalışma alanınızın Genel Bakış sayfasını seçin. İlişkili Application Insights kaynağı en sağdadır:

Sol bölmedeki İzleme'nin altında Günlükler (Analiz) öğesini seçin:
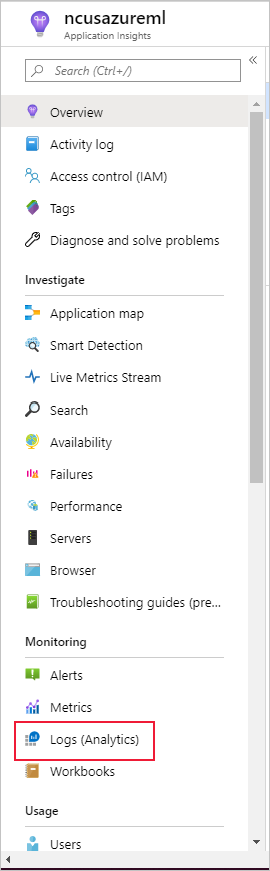
Veri kümesi izleme ölçümleri olarak customMetricsdepolanır. Veri kümesi izleyicisini ayarladıktan sonra bunları görüntülemek için bir sorgu yazabilir ve çalıştırabilirsiniz:

Uyarı kurallarını ayarlamak için ölçümleri tanımladıktan sonra yeni bir uyarı kuralı oluşturun:
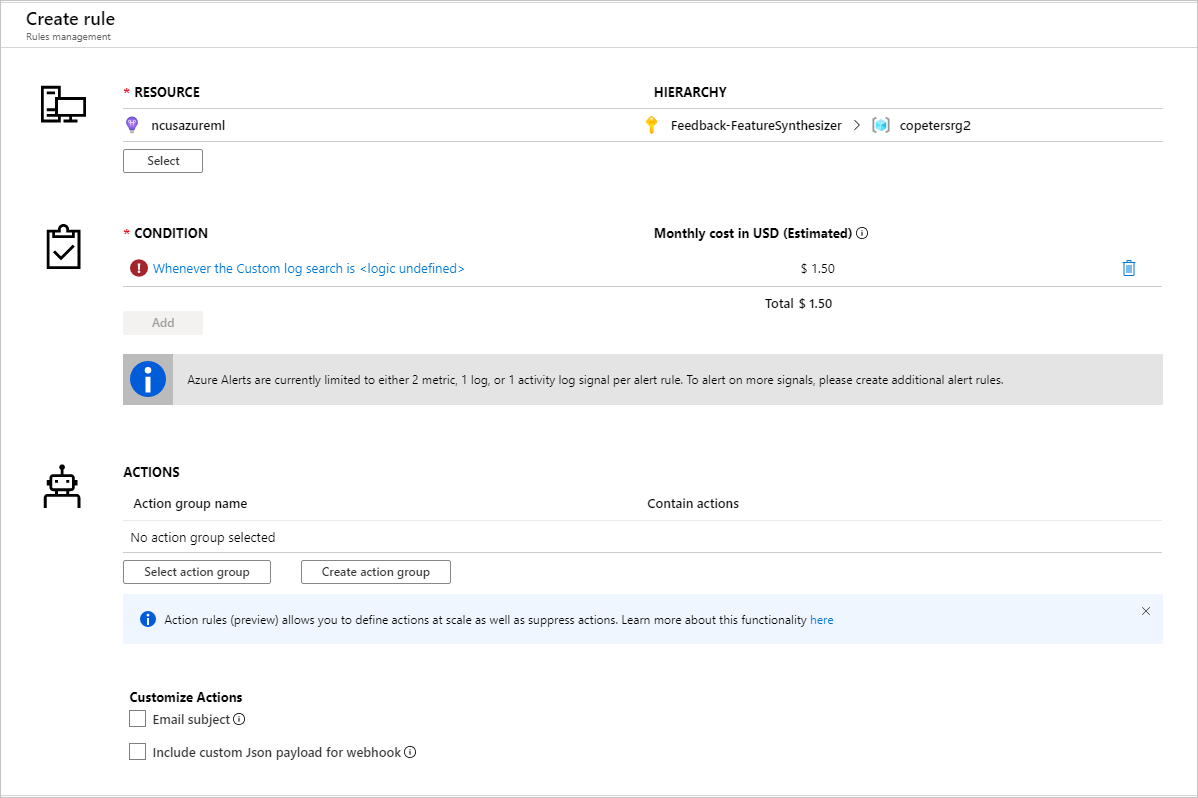
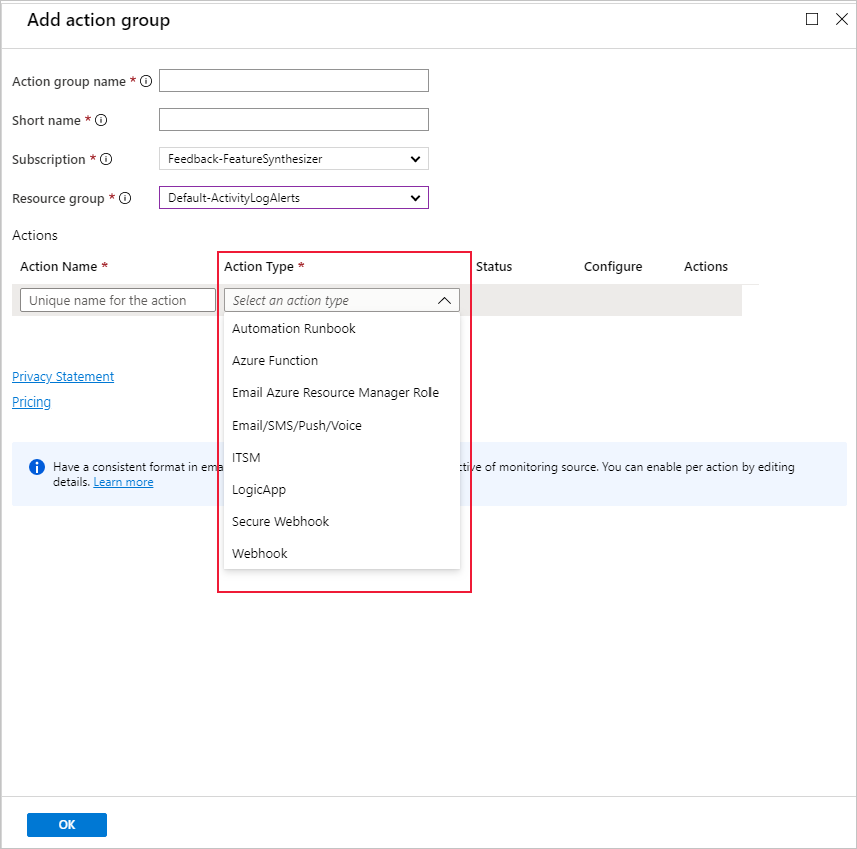
Mevcut bir eylem grubunu kullanabilir veya ayarlanan koşullar karşılandığında gerçekleştirilecek eylemi tanımlamak için yeni bir eylem oluşturabilirsiniz:
Sorun giderme
Veri kayma izleyicileri için sınırlamalar ve bilinen sorunlar:
Geçmiş verileri analiz ederken zaman aralığı, izleyicinin frekans ayarının 31 aralığıyla sınırlıdır.
Özellik listesi belirtilmediği sürece (kullanılan tüm özellikler) 200 özellik sınırlaması.
İşlem boyutu, verileri işleyecek kadar büyük olmalıdır.
Veri kümenizin belirli bir izleyici işi için başlangıç ve bitiş tarihi içinde veri olduğundan emin olun.
Veri kümesi izleyicileri yalnızca 50 veya daha fazla satır içeren veri kümelerinde çalışır.
Veri kümesindeki sütunlar veya özellikler, aşağıdaki tabloda yer alan koşullara göre kategorik veya sayısal olarak sınıflandırılır. Özellik bu koşulları karşılamıyorsa (örneğin, 100 benzersiz değere sahip >bir tür dizesi sütunu) özellik veri kayması algoritmamızdan bırakılır, ancak yine de profili oluşturulur.
Özellik türü Veri türü Koşul Sınırlamalar Kategorik Dize Özellikteki benzersiz değerlerin sayısı 100'den az ve satır sayısının %5'inden azdır. Null, kendi kategorisi olarak kabul edilir. Sayısal int, float Özellikteki değerler sayısal bir veri türündedir ve kategorik bir özelliğin koşulunu karşılamaz. Değerlerin %15'i null ise >özellik bırakıldı. Veri kayma izleyicisi oluşturduğunuzda ancak Azure Machine Learning stüdyosu veri kümesi izleyicileri sayfasında veri göremiyorsanız aşağıdakileri deneyin.
- Sayfanın üst kısmında doğru tarih aralığını seçerek seçmediğinizden emin olun.
- Veri Kümesi İzleyicileri sekmesinde, iş durumunu denetlemek için deneme bağlantısını seçin. Bu bağlantı tablonun en sağ tarafındadır.
- İş başarıyla tamamlandıysa, kaç ölçüm oluşturulduğunu veya herhangi bir uyarı iletisi olup olmadığını görmek için sürücü günlüklerini denetleyin. Denemeyi seçtikten sonra Çıkış + günlükler sekmesinde sürücü günlüklerini bulun.
SDK
backfill()işlevi beklenen çıkışı oluşturmuyorsa, bunun nedeni bir kimlik doğrulama sorunu olabilir. Bu işleve geçirmek için işlem oluşturduğunuzda kullanmayınRun.get_context().experiment.workspace.compute_targets. Bunun yerine, bu işlevebackfill()geçirdiğiniz işlemi oluşturmak için aşağıdaki gibi ServicePrincipalAuthentication kullanın:
Not
Kodunuzda hizmet sorumlusu parolasını sabit kodlamayın. Bunun yerine Python ortamından, anahtar deposundan veya gizli dizilere erişmeye ilişkin diğer güvenli yöntemden alın.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
Model Veri Toplayıcısı'ndan verilerin blob depolama hesabınıza ulaşması 10 dakika kadar sürebilir. Ancak, genellikle daha az zaman alır. Betikte veya Not Defteri'nde, aşağıdaki hücrelerin başarıyla çalıştığından emin olmak için 10 dakika bekleyin.
import time time.sleep(600)
Sonraki adımlar
- Veri kümesi izleyicisi ayarlamak için Azure Machine Learning stüdyosu veya Python not defterine gidin.
- Azure Kubernetes Service'e dağıtılan modellerde veri kayma özelliğini ayarlamayı öğrenin.
- Azure Event Grid ile veri kümesi kayma izleyicilerini ayarlayın.