Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR:  Python SDK'sı azure-ai-ml v2 (geçerli)
Python SDK'sı azure-ai-ml v2 (geçerli)
Bu makalede, Azure Machine Learning Python SDK v2 kullanarak Keras eğitim betiklerinizi çalıştırmayı öğrenin.
Bu makaledeki örnek kod, TensorFlow arka ucu kullanılarak oluşturulmuş bir Keras modelini eğitmek, kaydetmek ve dağıtmak için Azure Machine Learning'i kullanır. TensorFlow'un üzerinde çalışan Keras Python kitaplığıylaoluşturulmuş bir derin sinir ağı (DNN) olan model, popüler MNIST veri kümesindeki el yazısı basamakları sınıflandırır.
Keras, geliştirmeyi basitleştirmek için diğer popüler DNN çerçevelerini çalıştırabilen üst düzey bir sinir ağı API'sidir. Azure Machine Learning ile esnek bulut işlem kaynaklarını kullanarak eğitim işlerinin ölçeğini hızla genişletebilirsiniz. Ayrıca eğitim çalıştırmalarınızı, sürüm modellerinizi izleyebilir, modelleri dağıtabilir ve çok daha fazlasını yapabilirsiniz.
İster sıfırdan bir Keras modeli geliştirirken ister mevcut bir modeli buluta getirirken Azure Machine Learning üretime hazır modeller oluşturmanıza yardımcı olabilir.
Not
Tek başına Keras paketi yerine TensorFlow'da yerleşik olarak bulunan Keras API tf.keras kullanıyorsanız, bunun yerine TensorFlow modellerini eğitme bölümüne bakın.
Önkoşullar
Bu makaleden yararlanmak için şunları yapmanız gerekir:
- Azure aboneliğine erişme. Henüz bir hesabınız yoksa ücretsiz bir hesap oluşturun.
- Azure Machine Learning işlem örneğini veya kendi Jupyter not defterinizi kullanarak bu makaledeki kodu çalıştırın.
- Azure Machine Learning işlem örneği; indirme veya yükleme gerekmez
- SDK ve örnek depo ile önceden yüklenmiş ayrılmış bir not defteri sunucusu oluşturmaya başlamak için Kaynak oluşturma işlemini tamamlayın.
- Not defteri sunucusundaki örnekler derin öğrenme klasöründe, şu dizine giderek tamamlanmış ve genişletilmiş bir not defteri bulun: v2 > sdk > python > işleri > tek adımlı > tensorflow > train-hyperparameter-tune-deploy-with-keras.
- Jupyter not defteri sunucunuz
- Azure Machine Learning SDK'sını (v2) yükleyin.
- Azure Machine Learning işlem örneği; indirme veya yükleme gerekmez
- keras_mnist.py ve utils.py eğitim betiklerini indirin.
Bu kılavuzun tamamlanmış Jupyter Notebook sürümünü GitHub örnekleri sayfasında da bulabilirsiniz.
Gpu kümesi oluşturmak için bu makaledeki kodu çalıştırabilmeniz için önce çalışma alanınız için kota artışı istemeniz gerekir.
İşi ayarlama
Bu bölüm, gerekli Python paketlerini yükleyerek, bir çalışma alanına bağlanarak, komut işini çalıştırmak için işlem kaynağı oluşturarak ve işi çalıştırmak için bir ortam oluşturarak işi eğitim için ayarlar.
Çalışma alanına bağlanma
İlk olarak Azure Machine Learning çalışma alanınıza bağlanmanız gerekir. Azure Machine Learning çalışma alanı, hizmetin en üst düzey kaynağıdır. Azure Machine Learning'i kullanırken oluşturduğunuz tüm yapıtlarla çalışmak için merkezi bir yer sağlar.
Çalışma alanına erişmek için kullanıyoruz DefaultAzureCredential . Bu kimlik bilgisi Çoğu Azure SDK kimlik doğrulama senaryolarını işleyebilecek durumda olmalıdır.
Sizin için işe yaramazsa DefaultAzureCredential , bkz azure-identity reference documentation . veya Set up authentication daha fazla kullanılabilir kimlik bilgisi için.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Oturum açmak ve kimlik doğrulaması yapmak için bir tarayıcı kullanmayı tercih ediyorsanız, bunun yerine aşağıdaki kodu açıklamayı kaldırmanız ve kullanmanız gerekir.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Ardından Abonelik Kimliğinizi, Kaynak Grubu adınızı ve çalışma alanı adınızı sağlayarak çalışma alanına yönelik bir tanıtıcı alın. Bu parametreleri bulmak için:
- Azure Machine Learning stüdyosu araç çubuğunun sağ üst köşesinde çalışma alanı adınızı arayın.
- Kaynak Grubunuzu ve Abonelik Kimliğinizi göstermek için çalışma alanı adınızı seçin.
- Kaynak Grubu ve Abonelik Kimliği değerlerini koda kopyalayın.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Bu betiği çalıştırmanın sonucu, diğer kaynakları ve işleri yönetmek için kullanacağınız bir çalışma alanı tanıtıcısıdır.
Not
- Oluşturma
MLClient, istemciyi çalışma alanına bağlamaz. İstemci başlatması gecikmelidir ve ilk kez çağrı yapmasını bekler. Bu makalede, işlem oluşturma sırasında bu durum ortaya çıkacaktır.
İşi çalıştırmak için işlem kaynağı oluşturma
Azure Machine Learning'in bir işi çalıştırmak için bir işlem kaynağına ihtiyacı vardır. Bu kaynak, Linux veya Windows işletim sistemine sahip tek veya çok düğümlü makineler ya da Spark gibi belirli bir işlem dokusu olabilir.
Aşağıdaki örnek betikte bir Linux compute clustersağlıyoruz. VM boyutlarının Azure Machine Learning pricing ve fiyatlarının tam listesinin sayfasını görebilirsiniz. Bu örnek için bir GPU kümesine ihtiyacımız olduğundan bir STANDARD_NC6 modeli seçelim ve bir Azure Machine Learning işlem oluşturalım.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)İş ortamı oluşturma
Azure Machine Learning işini çalıştırmak için bir ortama ihtiyacınız vardır. Azure Machine Learning ortamı , işlem kaynağınızda makine öğrenmesi eğitim betiğinizi çalıştırmak için gereken bağımlılıkları (yazılım çalışma zamanı ve kitaplıklar gibi) kapsüller. Bu ortam, yerel makinenizdeki python ortamına benzer.
Azure Machine Learning, seçilmiş (veya hazır) bir ortam kullanmanıza veya Docker görüntüsü veya Conda yapılandırması kullanarak özel bir ortam oluşturmanıza olanak tanır. Bu makalede, Conda YAML dosyası kullanarak işleriniz için özel bir Conda ortamı oluşturacaksınız.
Özel ortam oluşturma
Özel ortamınızı oluşturmak için Conda bağımlılıklarınızı bir YAML dosyasında tanımlayacaksınız. İlk olarak, dosyayı depolamak için bir dizin oluşturun. Bu örnekte dizinine dependenciesadını verdik.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)Ardından dosyayı dependencies dizininde oluşturun. Bu örnekte dosyasını conda.ymladlandırdık.
%%writefile {dependencies_dir}/conda.yaml
name: keras-env
channels:
- conda-forge
dependencies:
- python=3.8
- pip=21.2.4
- pip:
- protobuf~=3.20
- numpy==1.22
- tensorflow-gpu==2.2.0
- keras<=2.3.1
- matplotlib
- azureml-mlflow==1.42.0Belirtim, işinizde kullanacağınız bazı normal paketleri (numpy ve pip gibi) içerir.
Ardından, bu özel ortamı oluşturmak ve çalışma alanınıza kaydetmek için YAML dosyasını kullanın. Ortam, çalışma zamanında bir Docker kapsayıcısına paketlenir.
from azure.ai.ml.entities import Environment
custom_env_name = "keras-env"
job_env = Environment(
name=custom_env_name,
description="Custom environment for keras image classification",
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
job_env = ml_client.environments.create_or_update(job_env)
print(
f"Environment with name {job_env.name} is registered to workspace, the environment version is {job_env.version}"
)Ortam oluşturma ve kullanma hakkında daha fazla bilgi için bkz . Azure Machine Learning'de yazılım ortamları oluşturma ve kullanma.
Eğitim işinizi yapılandırma ve gönderme
Bu bölümde, eğitim için verileri tanıtarak başlayacağız. Ardından, sağladığımız bir eğitim betiğini kullanarak bir eğitim işinin nasıl çalıştırıldığını ele alacağız. Eğitim betiğini çalıştırmak için komutunu yapılandırarak eğitim işini oluşturmayı öğreneceksiniz. Ardından, Azure Machine Learning'de çalıştırılacak eğitim işini göndereceksiniz.
Eğitim verilerini alma
Değiştirilmiş Ulusal Standartlar ve Teknoloji Enstitüsü (MNIST) veritabanındaki el yazısı rakamlardan oluşan verileri kullanacaksınız. Bu veriler Yan LeCun'un web sitesinden alınır ve bir Azure depolama hesabında depolanır.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"MNIST veri kümesi hakkında daha fazla bilgi için Yan LeCun'un web sitesini ziyaret edin.
Eğitim betiğini hazırlama
Bu makalede eğitim betiğini keras_mnist.py sağladık. Uygulamada, herhangi bir özel eğitim betiğini olduğu gibi alabilmeniz ve kodunuzu değiştirmenize gerek kalmadan Azure Machine Learning ile çalıştırabilmeniz gerekir.
Sağlanan eğitim betiği aşağıdakileri yapar:
- verileri test ve eğitme verilerine bölerek verilerin ön işlemesini işler;
- verileri kullanarak modeli eğiter; ve
- çıkış modelini döndürür.
İşlem hattı çalıştırması sırasında, parametreleri ve ölçümleri günlüğe kaydetmek için MLFlow kullanacaksınız. MLFlow izlemeyi etkinleştirmeyi öğrenmek için bkz . MLflow ile ML denemelerini ve modellerini izleme.
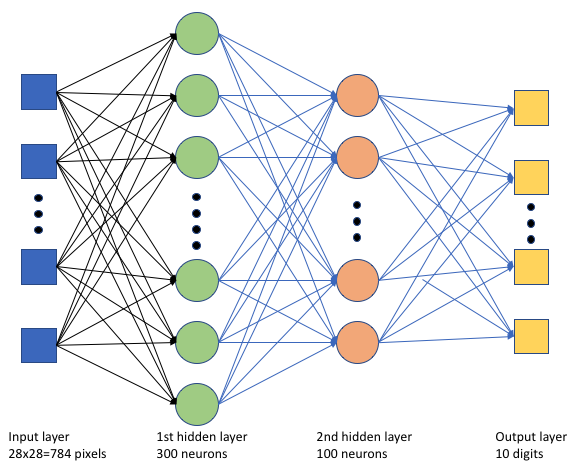
Eğitim betiğinde keras_mnist.pybasit bir derin sinir ağı (DNN) oluşturuyoruz. Bu DNN'de:
- 28 * 28 = 784 nöronlu bir giriş katmanı. Her nöron bir görüntü pikseli temsil eder.
- İki gizli katman. İlk gizli katmanda 300 nöron, ikinci gizli katmanda ise 100 nöron vardır.
- 10 nöronlu bir çıkış katmanı. Her nöron, 0'dan 9'a kadar hedeflenen bir etiketi temsil eder.
Eğitim işini oluşturma
İşinizi çalıştırmak için gereken tüm varlıklara sahip olduğunuz için artık Azure Machine Learning Python SDK v2'yi kullanarak derlemenin zamanı geldi. Bu örnekte bir commandoluşturacağız.
Azure Machine Learning command , eğitim kodunuzu bulutta yürütmek için gereken tüm ayrıntıları belirten bir kaynaktır. Bu ayrıntılar giriş ve çıkışları, kullanılacak donanım türünü, yüklenecek yazılımları ve kodunuzu çalıştırmayı içerir. , command tek bir komut yürütmeye ilişkin bilgileri içerir.
Komutu yapılandırma
Eğitim betiğini çalıştırmak ve istediğiniz görevleri gerçekleştirmek için genel amacı command kullanacaksınız. Eğitim işinizin yapılandırma ayrıntılarını belirtmek için bir Command nesne oluşturun.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=50,
first_layer_neurons=300,
second_layer_neurons=100,
learning_rate=0.001,
),
compute=gpu_compute_target,
environment=f"{job_env.name}:{job_env.version}",
code="./src/",
command="python keras_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="keras-dnn-image-classify",
display_name="keras-classify-mnist-digit-images-with-dnn",
)Bu komutun girişleri veri konumunu, toplu iş boyutunu, birinci ve ikinci katmandaki nöron sayısını ve öğrenme hızını içerir. Web yolunda doğrudan giriş olarak geçiş yaptığımıza dikkat edin.
Parametre değerleri için:
- bu komutu çalıştırmak için oluşturduğunuz işlem kümesini
gpu_compute_target = "gpu-cluster"sağlayın; - Azure Machine Learning işini çalıştırmak için oluşturduğunuz özel ortamı
keras-envsağlayın; - komut satırı eylemini yapılandırın; bu durumda, komut şeklindedir
python keras_mnist.py. Komuttaki girişlere ve çıkışlara gösterimi aracılığıyla${{ ... }}erişebilirsiniz; ve - görünen ad ve deneme adı gibi meta verileri yapılandırma; burada bir deneme, belirli bir projede yapılan tüm yinelemeler için bir kapsayıcıdır. Aynı deneme adı altında gönderilen tüm işler Azure Machine Learning stüdyosu'da yan yana listelenir.
- bu komutu çalıştırmak için oluşturduğunuz işlem kümesini
Bu örnekte komutunu çalıştırmak için kullanacaksınız
UserIdentity. Kullanıcı kimliği kullanmak, komutun işi çalıştırmak ve blobdan verilere erişmek için kimliğinizi kullanacağı anlamına gelir.
İşi gönderme
Şimdi Azure Machine Learning'de çalıştırılacak işi gönderme zamanı geldi. Bu kez üzerinde kullanacaksınız create_or_updateml_client.jobs.
ml_client.jobs.create_or_update(job)İşlem tamamlandıktan sonra iş çalışma alanınıza bir model kaydeder (eğitimin bir sonucu olarak) ve işi Azure Machine Learning stüdyosu görüntülemek için bir bağlantı oluşturur.
Uyarı
Azure Machine Learning, kaynak dizinin tamamını kopyalayarak eğitim betikleri çalıştırır. Karşıya yüklemek istemediğiniz hassas verileriniz varsa bir .ignore dosyası kullanın veya kaynak dizine eklemeyin.
İş yürütme sırasında ne olur?
İş yürütülürken aşağıdaki aşamalardan geçer:
Hazırlanıyor: Tanımlanan ortama göre bir docker görüntüsü oluşturulur. Görüntü çalışma alanının kapsayıcı kayıt defterine yüklenir ve sonraki çalıştırmalar için önbelleğe alınır. Günlükler iş geçmişine de akışla aktarılır ve ilerleme durumunu izlemek için görüntülenebilir. Seçilen bir ortam belirtilirse, seçilen ortamı destekleyen önbelleğe alınmış görüntü kullanılır.
Ölçeklendirme: Küme, çalıştırmayı yürütmek için şu anda kullanılabilir olandan daha fazla düğüm gerektiriyorsa ölçeği artırmayı dener.
Çalışıyor: src betik klasöründeki tüm betikler işlem hedefine yüklenir, veri depoları bağlanır veya kopyalanır ve betik yürütülür. stdout ve ./logs klasöründen alınan çıkışlar iş geçmişine akışla aktarılır ve işi izlemek için kullanılabilir.
Model hiper parametreleri ayarlama
Modeli tek bir parametre kümesiyle eğitdiniz. Şimdi modelinizin doğruluğunu daha da geliştirip geliştirebileceğinizi görelim. Azure Machine Learning'in sweep özelliklerini kullanarak modelinizin hiper parametrelerini ayarlayabilir ve iyileştirebilirsiniz.
Modelin hiper parametrelerini ayarlamak için eğitim sırasında aranacak parametre alanını tanımlayın. Bunu yapmak için, eğitim işine geçirilen bazı parametreleri (batch_size, first_layer_neurons, second_layer_neuronsve learning_rate) paketten azure.ml.sweep özel girişlerle değiştireceksiniz.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[25, 50, 100]),
first_layer_neurons=Choice(values=[10, 50, 200, 300, 500]),
second_layer_neurons=Choice(values=[10, 50, 200, 500]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Ardından, izleyebileceğiniz birincil ölçüm ve kullanılacak örnekleme algoritması gibi süpürmeye özgü bazı parametreleri kullanarak komut işinde süpürme özelliğini yapılandıracaksınız.
Aşağıdaki kodda, birincil ölçümümüzü validation_accen üst düzeye çıkarmak amacıyla farklı hiper parametre yapılandırma kümelerini denemek için rastgele örnekleme kullanırız.
Ayrıca bir erken sonlandırma ilkesi de tanımlarız: BanditPolicy. Bu ilke, her iki yinelemede bir işi denetleyerek çalışır. Birincil ölçüm olan validation_acc, ilk yüzde on aralığının dışında kalırsa Azure Machine Learning işi sonlandıracaktır. Bu, modelin hedef ölçüme ulaşmasına yardımcı olma sözü göstermeyen hiper parametreleri keşfetmeye devam etmesinden kurtarır.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="Accuracy",
goal="Maximize",
max_total_trials=20,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Şimdi, bu işi daha önce olduğu gibi gönderebilirsiniz. Bu sefer, tren işinizin üzerinden süpüren bir süpürme işi çalıştıracaksınız.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)İş çalıştırması sırasında sunulan studio kullanıcı arabirimi bağlantısını kullanarak işi izleyebilirsiniz.
En iyi modeli bulma ve kaydetme
Tüm çalıştırmalar tamamlandıktan sonra modeli en yüksek doğrulukla üreten çalıştırmayı bulabilirsiniz.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "keras_dnn_mnist_model"
path="azureml://jobs/{}/outputs/artifacts/paths/keras_dnn_mnist_model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="mlflow_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Daha sonra bu modeli kaydedebilirsiniz.
registered_model = ml_client.models.create_or_update(model=model)Modeli çevrimiçi uç nokta olarak dağıtma
Modelinizi kaydettikten sonra, azure bulutunda bir web hizmeti olarak çevrimiçi uç nokta olarak dağıtabilirsiniz.
Makine öğrenmesi hizmetini dağıtmak için genellikle şunları yapmanız gerekir:
- Dağıtmak istediğiniz model varlıkları. Bu varlıklar, modelin eğitim işinize önceden kaydettiğiniz dosyasını ve meta verilerini içerir.
- Hizmet olarak çalıştırılacak bazı kodlar. Kod, modeli belirli bir giriş isteğinde (giriş betiği) yürütür. Bu giriş betiği, dağıtılan bir web hizmetine gönderilen verileri alır ve modele geçirir. Model verileri işledikten sonra betik modelin istemciye yanıtını döndürür. Betik modelinize özgüdür ve modelin beklediği ve döndürdüğü verileri anlaması gerekir. MLFlow modeli kullandığınızda Azure Machine Learning bu betiği sizin için otomatik olarak oluşturur.
Dağıtım hakkında daha fazla bilgi için bkz . Python SDK v2 kullanarak yönetilen çevrimiçi uç nokta ile makine öğrenmesi modelini dağıtma ve puanlandırma.
Yeni bir çevrimiçi uç nokta oluşturma
Modelinizi dağıtmanın ilk adımı olarak çevrimiçi uç noktanızı oluşturmanız gerekir. Uç nokta adı Azure bölgesinin tamamında benzersiz olmalıdır. Bu makalede, evrensel olarak benzersiz bir tanımlayıcı (UUID) kullanarak benzersiz bir ad oluşturacaksınız.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "keras-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using Keras",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Uç noktayı oluşturduktan sonra aşağıdaki gibi alabilirsiniz:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Modeli uç noktaya dağıtma
Uç noktayı oluşturduktan sonra modeli giriş betiğiyle dağıtabilirsiniz. Uç noktanın birden çok dağıtımı olabilir. Uç nokta, kuralları kullanarak trafiği bu dağıtımlara yönlendirebilir.
Aşağıdaki kodda, gelen trafiğin %100'lerini işleyen tek bir dağıtım oluşturacaksınız. Dağıtım için rastgele bir renk adı (tff-mavi) belirttik. Dağıtım için tff-green veya tff-red gibi başka bir ad da kullanabilirsiniz. Modeli uç noktaya dağıtma kodu aşağıdakileri yapar:
- daha önce kaydettiğiniz modelin en iyi sürümünü dağıtır;
- dosyasını kullanarak modeli puanlar
score.py; ve - çıkarım yapmak için özel ortamı (daha önce oluşturduğunuz) kullanır.
from azure.ai.ml.entities import ManagedOnlineDeployment, CodeConfiguration
model = registered_model
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="keras-blue-deployment",
endpoint_name=online_endpoint_name,
model=model,
# code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Not
Bu dağıtımın tamamlanmasının biraz zaman almasını bekleyebilirsiniz.
Dağıtılan modeli test etme
Modeli uç noktaya dağıttığınız için, uç nokta üzerindeki yöntemini kullanarak dağıtılan modelin çıkışını invoke tahmin edebilirsiniz.
Uç noktayı test etmek için bazı test verilerine ihtiyacınız vardır. Eğitim betiğimizde kullandığımız test verilerini yerel olarak indirelim.
import urllib.request
data_folder = os.path.join(os.getcwd(), "data")
os.makedirs(data_folder, exist_ok=True)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-images-idx3-ubyte.gz",
filename=os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"),
)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-labels-idx1-ubyte.gz",
filename=os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"),
)Bunları bir test veri kümesine yükleyin.
from src.utils import load_data
X_test = load_data(os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"), False)
y_test = load_data(
os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"), True
).reshape(-1)Test kümesinden 30 rastgele örnek seçin ve bunları bir JSON dosyasına yazın.
import json
import numpy as np
# find 30 random samples from test set
n = 30
sample_indices = np.random.permutation(X_test.shape[0])[0:n]
test_samples = json.dumps({"input_data": X_test[sample_indices].tolist()})
# test_samples = bytes(test_samples, encoding='utf8')
with open("request.json", "w") as outfile:
outfile.write(test_samples)Ardından uç noktayı çağırabilir, döndürülen tahminleri yazdırabilir ve giriş görüntüleriyle birlikte çizebilirsiniz. Yanlış sınıflandırılmış örnekleri vurgulamak için kırmızı yazı tipi rengi ve ters görüntü (siyah üzerinde beyaz) kullanın.
import matplotlib.pyplot as plt
# predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request.json",
deployment_name="keras-blue-deployment",
)
# compare actual value vs. the predicted values:
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Not
Model doğruluğu yüksek olduğundan, yanlış sınıflandırılmış bir örneği görmeden önce hücreyi birkaç kez çalıştırmanız gerekebilir.
Kaynakları temizleme
Uç noktayı kullanmayacaksanız, kaynağı kullanmayı durdurmak için silin. Silmeden önce uç noktayı başka hiçbir dağıtımın kullanmadığından emin olun.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Not
Bu temizleme işleminin tamamlanmasının biraz zaman almasını bekleyebilirsiniz.
Sonraki adımlar
Bu makalede bir Keras modeli eğitip kaydettiniz. Modeli çevrimiçi bir uç noktaya da dağıttınız. Azure Machine Learning hakkında daha fazla bilgi edinmek için bu diğer makalelere bakın.