Öğretici: Bulut iş istasyonunda model geliştirme
Azure Machine Learning bulut iş istasyonunda not defteriyle eğitim betiği geliştirmeyi öğrenin. Bu öğreticide, kullanmaya başlamak için ihtiyacınız olan temel bilgiler yer alır:
- Bulut iş istasyonunu ayarlama ve yapılandırma. Bulut iş istasyonunuz, çeşitli model geliştirme gereksinimlerinizi desteklemek için ortamlarla önceden yapılandırılmış bir Azure Machine Learning işlem örneği tarafından desteklenir.
- Bulut tabanlı geliştirme ortamlarını kullanın.
- Model ölçümlerinizi bir not defteri içinden izlemek için MLflow kullanın.
Önkoşullar
Azure Machine Learning'i kullanmak için bir çalışma alanı gerekir. Bir çalışma alanınız yoksa, çalışma alanı oluşturmaya başlamak ve bu çalışma alanını kullanma hakkında daha fazla bilgi edinmek için ihtiyacınız olan kaynakları oluşturma'yı tamamlayın.
İşlemle başlayın
Çalışma alanınızdaki İşlem bölümü, işlem kaynakları oluşturmanıza olanak tanır. İşlem örneği, tamamen Azure Machine Learning tarafından yönetilen bulut tabanlı bir iş istasyonudur. Bu öğretici serisi bir işlem örneği kullanır. Ayrıca kendi kodunuzu çalıştırmak ve model geliştirip test etmek için de kullanabilirsiniz.
- Azure Machine Learning stüdyosu oturum açın.
- Henüz açık değilse çalışma alanınızı seçin.
- Sol gezinti bölmesinde İşlem'i seçin.
- İşlem örneğiniz yoksa ekranın ortasında Yeni ifadesini görürsünüz. Yeni'yi seçin ve formu doldurun. Tüm varsayılan değerleri kullanabilirsiniz.
- İşlem örneğiniz varsa listeden seçin. Durdurulduysa Başlat'ı seçin.
Visual Studio Code'ı (VS Code) açma
Çalışan bir işlem örneğine sahip olduktan sonra bu örneğe çeşitli yollarla erişebilirsiniz. Bu öğreticide VS Code'dan işlem örneğini kullanma gösterilmektedir. VS Code, Azure Machine Learning kaynaklarının gücüyle tam tümleşik bir geliştirme ortamı (IDE) sağlar.
İşlem örneği listesinde, kullanmak istediğiniz işlem örneği için VS Code (Web) veya VS Code (Masaüstü) bağlantısını seçin. VS Code (Masaüstü) seçeneğini belirlerseniz uygulamayı açmak isteyip istemediğinizi soran bir açılır pencere görebilirsiniz.

Bu VS Code örneği, işlem örneğinize ve çalışma alanı dosya sisteminize eklenir. Masaüstünüzde açsanız bile, gördüğünüz dosyalar çalışma alanınızdaki dosyalardır.
Prototip oluşturmak için yeni bir ortam ayarlama (isteğe bağlı)
Betiğinizin çalışması için, kodun beklediği bağımlılıklar ve kitaplıklarla yapılandırılmış bir ortamda çalışıyor olmanız gerekir. Bu bölüm, kodunuz için uyarlanmış bir ortam oluşturmanıza yardımcı olur. Not defterinizin bağlandığı yeni Jupyter çekirdeğini oluşturmak için bağımlılıkları tanımlayan bir YAML dosyası kullanacaksınız.
Dosyayı karşıya yükleyin.
Karşıya yüklediğiniz dosyalar bir Azure dosya paylaşımında depolanır ve bu dosyalar her işlem örneğine bağlanır ve çalışma alanı içinde paylaşılır.
Sağ üstteki Ham dosyayı indir düğmesini kullanarak bilgisayarınıza workstation_env.yml bu conda ortam dosyasını indirin.
Dosyayı bilgisayarınızdan VS Code penceresine sürükleyin. Dosya çalışma alanınıza yüklenir.
Dosyayı kullanıcı adı klasörünüzün altına taşıyın.
Önizlemesini görüntülemek için bu dosyayı seçin ve hangi bağımlılıkları belirttiğini görün. Şunun gibi içerikleri görürsünüz:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibÇekirdek oluşturma.
Şimdi terminali kullanarak workstation_env.yml dosyasını temel alan yeni bir Jupyter çekirdeği oluşturun.
Üst menü çubuğunda Terminal Yeni Terminal'i >seçin.
Geçerli conda ortamlarınızı görüntüleyin. Etkin ortam * ile işaretlenir.
conda env listcdworkstation_env.yml dosyasını karşıya yüklediğiniz klasöre. Örneğin, bunu kullanıcı klasörünüze yüklediyseniz:cd Users/myusernameworkstation_env.yml bu klasörde olduğundan emin olun.
lsSağlanan conda dosyasını temel alarak ortamı oluşturun. Bu ortamın oluşturulması birkaç dakika sürer.
conda env create -f workstation_env.ymlYeni ortamı etkinleştirin.
conda activate workstation_envNot
CommandNotFoundError görürseniz, komutunu çalıştırmak
conda init bashiçin yönergeleri izleyin, terminali kapatın ve yeni bir tane açın. Ardından komutunu yeniden deneyinconda activate workstation_env.Doğru ortamın etkin olduğunu doğrulayın ve *ile işaretlenmiş ortamı yeniden arayın.
conda env listEtkin ortamınızı temel alan yeni bir Jupyter çekirdeği oluşturun.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Terminal penceresini kapatın.
Artık yeni bir çekirdeğiniz var. Ardından bir not defteri açıp bu çekirdeği kullanacaksınız.
Not defteri oluşturma
- Üst menü çubuğunda Dosya Yeni Dosya'yı >seçin.
- Yeni dosyanıza develop-tutorial.ipynb adını verin (veya tercih ettiğiniz adı girin). .ipynb uzantısını kullandığınızdan emin olun.
Çekirdeği ayarlama
- Sağ üst kısımda Çekirdek seç'i seçin.
- Azure ML işlem örneği (computeinstance-name) öğesini seçin.
- Oluşturduğunuz çekirdek olan Öğretici İş İstasyonu Env'yi seçin. Bu seçeneği görmüyorsanız sağ üstteki Yenile aracını seçin.
Eğitim betiği geliştirme
Bu bölümde, UCI veri kümesinden hazırlanan test ve eğitim veri kümelerini kullanarak kredi kartı varsayılan ödemelerini tahmin eden bir Python eğitim betiği geliştirin.
Bu kod, ölçümleri günlüğe kaydetmek için eğitim ve MLflow için kullanır sklearn .
Eğitim betiğinde kullanacağınız paketleri ve kitaplıkları içeri aktaran kodla başlayın.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitArdından bu denemenin verilerini yükleyip işleyin. Bu öğreticide, İnternet'teki bir dosyadan verileri okuyacaksınız.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Verileri eğitim için hazırlayın:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesile otomatik kaydetmeye
MLflowbaşlamak için kod ekleyin, böylece ölçümleri ve sonuçları izleyebilirsiniz. Model geliştirmenin yinelemeli yapısıyla,MLflowmodel parametrelerini ve sonuçlarını günlüğe kaydetmenize yardımcı olur. Modelinizin performansını karşılaştırmak ve anlamak için bu çalıştırmalara geri dönün. Günlükler ayrıca Azure Machine Learning'de geliştirme aşamasından iş akışlarınızın eğitim aşamasına geçmeye hazır olduğunuzda bağlam sağlar.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Modeli eğitin.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Not
Mlflow uyarılarını yoksayabilirsiniz. İzlemeniz gereken tüm sonuçları almaya devam edersiniz.
Yineleme
Artık model sonuçlarınız olduğuna göre, bir şeyi değiştirmek ve yeniden denemek isteyebilirsiniz. Örneğin, farklı bir sınıflandırıcı tekniği deneyin:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Not
Mlflow uyarılarını yoksayabilirsiniz. İzlemeniz gereken tüm sonuçları almaya devam edersiniz.
Sonuçları inceleme
İki farklı modeli denediğinize göre, hangi modelin daha iyi olduğuna karar vermek için tarafından MLFfow izlenen sonuçları kullanın. Doğruluk gibi ölçümlere veya senaryolarınız için en önemli olan diğer göstergelere başvurabilirsiniz. tarafından MLflowoluşturulan işlere bakarak bu sonuçları daha ayrıntılı olarak inceleyebilirsiniz.
Azure Machine Learning stüdyosu çalışma alanınıza dönün.
Sol gezinti bölmesinde İşler'i seçin.
Bulutta geliştirme öğreticisi bağlantısını seçin.
Denediğiniz modellerin her biri için bir tane olan iki farklı iş gösterilir. Bu adlar otomatik olarak oluşturulur. Bir adın üzerine geldiğinizde, adı yeniden adlandırmak istiyorsanız adın yanındaki kalem aracını kullanın.
İlk işin bağlantısını seçin. Ad en üstte görünür. Burada kalem aracıyla da yeniden adlandırabilirsiniz.
Sayfada işin özellikler, çıkışlar, etiketler ve parametreler gibi ayrıntıları gösterilir. Etiketler'in altında modelin türünü açıklayan estimator_name görürsünüz.
tarafından
MLflowgünlüğe kaydedilen ölçümleri görüntülemek için Ölçümler sekmesini seçin. (Farklı bir eğitim kümeniz olduğundan sonuçlarınızın farklı olmasını bekleyin.)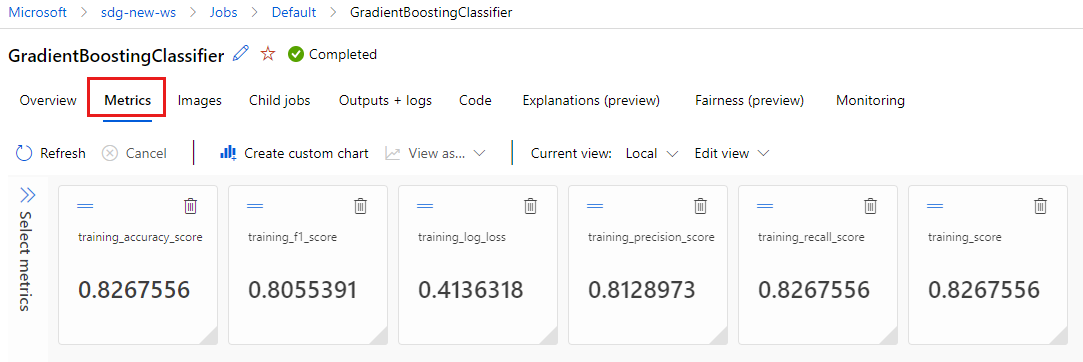
tarafından
MLflowoluşturulan görüntüleri görüntülemek için Resimler sekmesini seçin.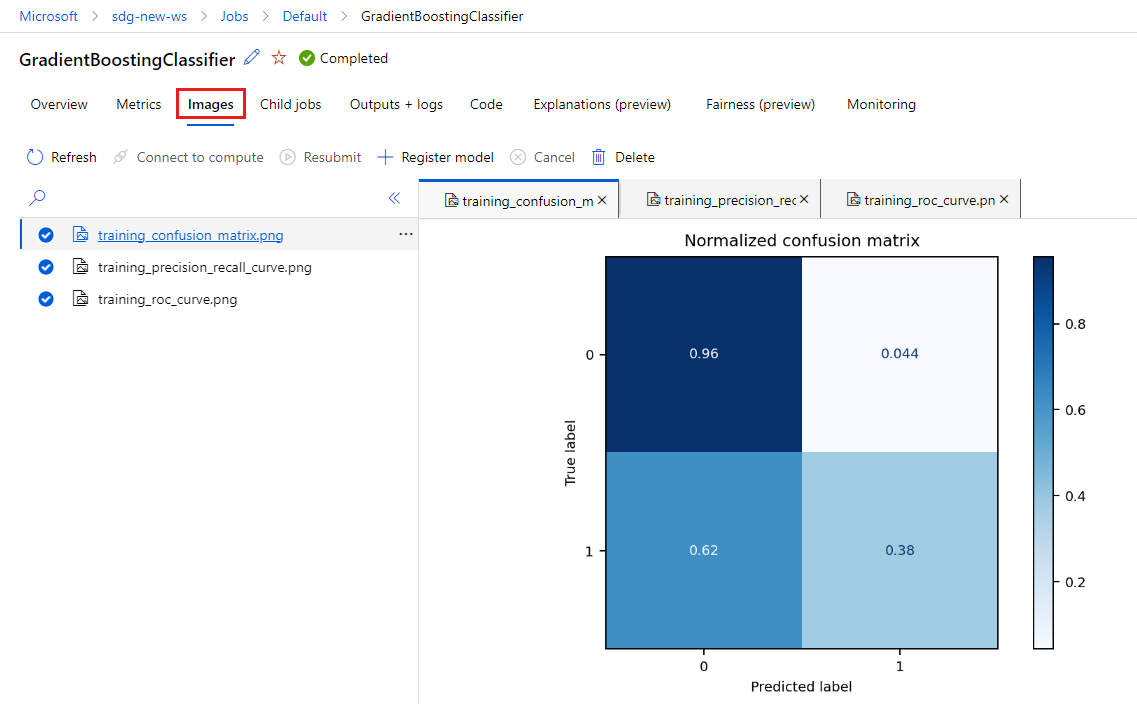
Geri dönün ve diğer modelin ölçümlerini ve görüntülerini gözden geçirin.
Python betiği oluşturma
Şimdi model eğitimi için not defterinizden bir Python betiği oluşturun.
VS Code pencerenizde not defteri dosya adına sağ tıklayın ve Not Defterini Betike Aktar'ı seçin.
Bu yeni betik dosyasını kaydetmek için Dosya > Kaydet menüsünü kullanın. buna train.py de.
Bu dosyaya bakın ve eğitim betiğinde istemediğiniz kodu silin. Örneğin, kullanmak istediğiniz modelin kodunu tutun ve istemediğiniz modelin kodunu silin.
- Otomatik olarak kaydetmeye
mlflow.sklearn.autolog()() başlayan kodu tuttuğunuzdan emin olun. - Python betiğini etkileşimli olarak çalıştırdığınızda (burada yaptığınız gibi), deneme adını (
mlflow.set_experiment("Develop on cloud tutorial")) tanımlayan satırı tutabilirsiniz. Hatta İşler bölümünde farklı bir giriş olarak görmek için farklı bir ad verin. Ancak bir eğitim işi için betiği hazırladığınızda bu satır geçerli değildir ve atlanmalıdır. İş tanımı deneme adını içerir. - Tek bir modeli eğittiğinizde, çalıştırmayı (
mlflow.start_run()ve ) başlatmak vemlflow.end_run()sonlandırmak için çizgiler de gerekli değildir (hiçbir etkisi olmaz), ancak isterseniz içinde bırakılabilir.
- Otomatik olarak kaydetmeye
Düzenlemelerinizi tamamladığınızda dosyayı kaydedin.
Artık tercih ettiğiniz modeli eğitmek için kullanabileceğiniz bir Python betiğiniz var.
Python betiğini çalıştırma
Şimdilik bu kodu Azure Machine Learning geliştirme ortamınız olan işlem örneğinizde çalıştırıyorsunuz. Öğretici: Modeli eğitme, bir eğitim betiğini daha güçlü işlem kaynakları üzerinde daha ölçeklenebilir bir şekilde çalıştırmayı gösterir.
Bu öğreticide daha önce oluşturduğunuz ortamı Python sürümünüz (workstations_env) olarak seçin. Not defterinin sağ alt köşesinde ortam adını görürsünüz. Seçin ve ardından ekranın ortasındaki ortamı seçin.
Şimdi Python betiğini çalıştırın. Sağ üstteki Python Dosyasını Çalıştır aracını kullanın.
Not
Mlflow uyarılarını yoksayabilirsiniz. Otomatik kaydetme işleminden tüm ölçümleri ve görüntüleri almaya devam edersiniz.
Betik sonuçlarını inceleme
Eğitim betiğinizin sonuçlarını görmek için Azure Machine Learning stüdyosu çalışma alanınızdaki İşler'e dönün. Eğitim verilerinin her bölmede değiştiğini, dolayısıyla sonuçların çalıştırmalar arasında da farklılık gösterdiğini unutmayın.
Kaynakları temizleme
Şimdi diğer öğreticilere devam etmek istiyorsanız Sonraki adımlar'a atlayın.
İşlem örneğini durdurma
Şimdi kullanmayacaksanız işlem örneğini durdurun:
- Stüdyoda, sol gezinti alanında İşlem'i seçin.
- Üst sekmelerde İşlem örnekleri'ni seçin
- Listeden işlem örneğini seçin.
- Üst araç çubuğunda Durdur'u seçin.
Tüm kaynakları silme
Önemli
Oluşturduğunuz kaynaklar, diğer Azure Machine Learning öğreticileri ve nasıl yapılır makaleleri için önkoşul olarak kullanılabilir.
Oluşturduğunuz kaynaklardan hiçbirini kullanmayı planlamıyorsanız, ücret ödememek için bunları silin:
Azure portalındaki arama kutusuna Kaynak grupları yazın ve sonuçlardan seçin.
Listeden, oluşturduğunuz kaynak grubunu seçin.
Genel Bakış sayfasında Kaynak grubunu sil'i seçin.
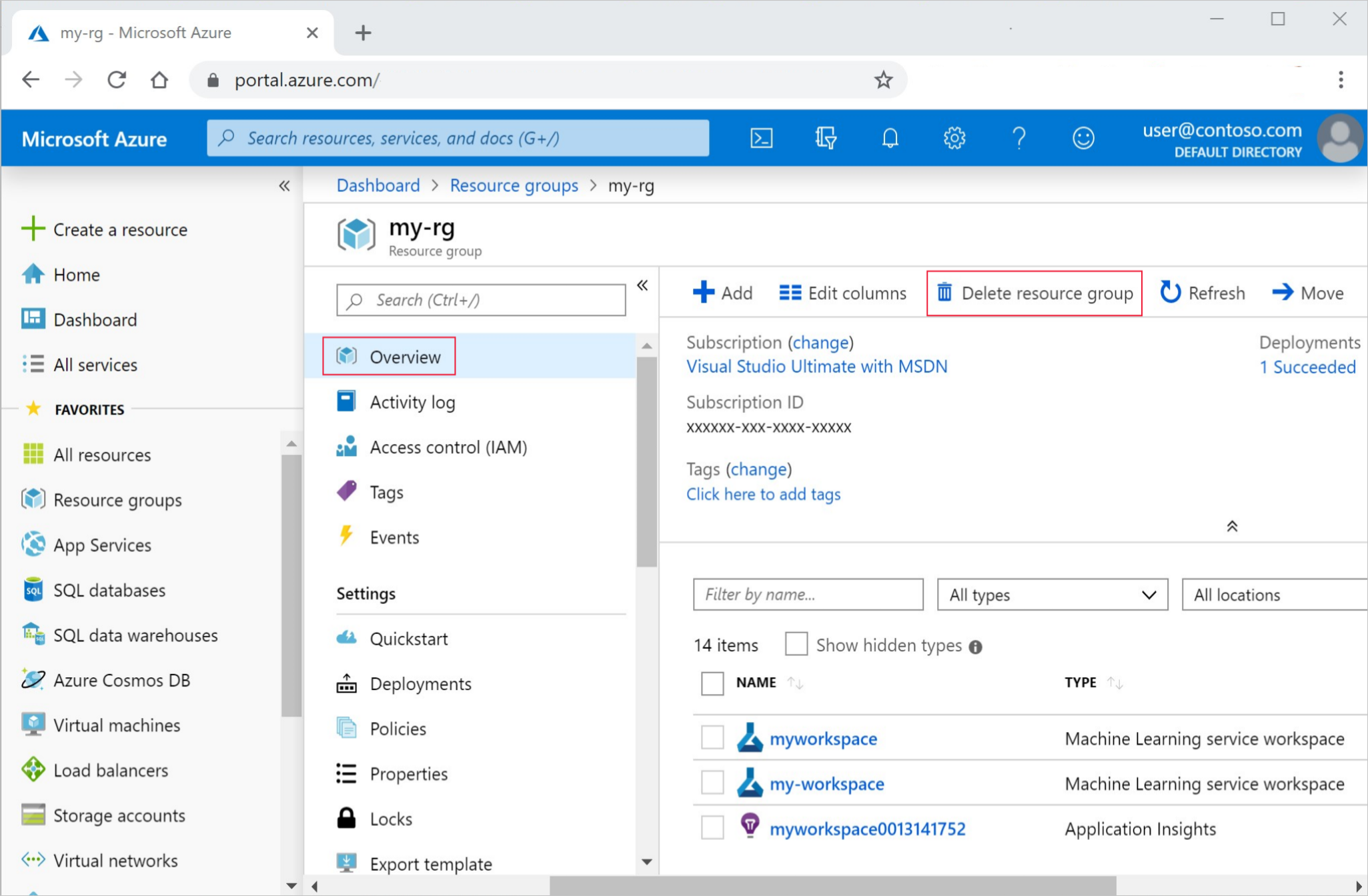
Kaynak grubu adını girin. Ardından Sil'i seçin.
Sonraki adımlar
Aşağıdakiler hakkında daha fazla bilgi edinin:
- Yapıtlardan MLflow'daki modellere
- Azure Machine Learning ile Git kullanma
- Çalışma alanınızda Jupyter not defterlerini çalıştırma
- Çalışma alanınızda işlem örneği terminaliyle çalışma
- Not defteri ve terminal oturumlarını yönetme
Bu öğreticide, kodun bulunduğu makinede prototip oluşturma, model oluşturmanın ilk adımları gösterildi. Üretim eğitiminiz için bu eğitim betiğini daha güçlü uzak işlem kaynaklarında kullanmayı öğrenin: