Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR:  Python SDK'sı azure-ai-ml v2 (geçerli)
Python SDK'sı azure-ai-ml v2 (geçerli)
Not
İşlem hattı oluşturmak için SDK v1 kullanan bir öğretici için bkz . Öğretici: Görüntü sınıflandırması için Azure Machine Learning işlem hattı oluşturma.
Makine öğrenmesi işlem hattı, eksiksiz bir makine öğrenmesi görevini çok adımlı bir iş akışına böler. Her adım, tek tek geliştirebileceğiniz, iyileştirebileceğiniz, yapılandırabileceğiniz ve otomatikleştirebileceğiniz yönetilebilir bir bileşendir. İyi tanımlanmış arabirimler adımları bağlar. Azure Machine Learning işlem hattı hizmeti, işlem hattı adımları arasındaki tüm bağımlılıkları düzenler.
İşlem hattı kullanmanın avantajları standartlaştırılmış MLOps uygulaması, ölçeklenebilir ekip işbirliği, eğitim verimliliği ve maliyet azaltmadır. İşlem hatlarının avantajları hakkında daha fazla bilgi edinmek için bkz . Azure Machine Learning işlem hatları nedir?
Bu öğreticide, Azure Machine Learning Python SDK v2 kullanarak üretime hazır bir makine öğrenmesi projesi oluşturmak için Azure Machine Learning'i kullanacaksınız. Bu öğreticiden sonra Azure Machine Learning Python SDK'sını kullanarak şunları yapabileceksiniz:
- Azure Machine Learning çalışma alanınıza tanıtıcı alma
- Azure Machine Learning veri varlıkları oluşturma
- Yeniden kullanılabilir Azure Machine Learning bileşenleri oluşturma
- Azure Machine Learning işlem hatlarını oluşturma, doğrulama ve çalıştırma
Bu öğretici sırasında, bir modeli kredi varsayılan tahmini için eğitmek üzere bir Azure Machine Learning işlem hattı oluşturursunuz. İşlem hattı iki adımı işler:
- Veri hazırlama
- Eğitilen modeli eğitip kaydetme
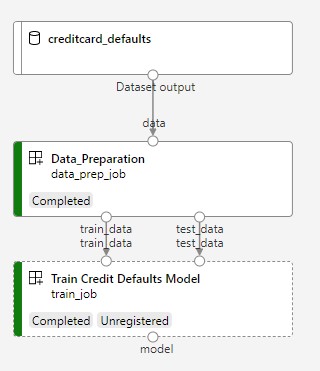
Sonraki görüntüde, gönderdikten sonra Azure studio'da gördüğünüz basit bir işlem hattı gösterilir.
İki adım veri hazırlama ve eğitimdir.
Bu videoda, öğreticideki adımları izleyebilmek için Azure Machine Learning stüdyosu kullanmaya nasıl başlayabileceğiniz gösterilmektedir. Videoda not defteri oluşturma, işlem örneği oluşturma ve not defterini kopyalama gösterilmektedir. Aşağıdaki bölümlerde bu adımlar da açıklanmaktadır.
Önkoşullar
-
Azure Machine Learning'i kullanmak için bir çalışma alanı gerekir. Bir çalışma alanınız yoksa, çalışma alanı oluşturmaya başlamak ve bu çalışma alanını kullanma hakkında daha fazla bilgi edinmek için ihtiyacınız olan kaynakları oluşturma'yı tamamlayın.
Önemli
Azure Machine Learning çalışma alanınız yönetilen bir sanal ağ ile yapılandırılmışsa, genel Python paket depolarına erişime izin vermek için giden kuralları eklemeniz gerekebilir. Daha fazla bilgi için bkz . Senaryo: Genel makine öğrenmesi paketlerine erişme.
-
Stüdyoda oturum açın ve henüz açık değilse çalışma alanınızı seçin.
Bu öğreticide ihtiyacınız olan veri varlığını oluşturmak için verilerinizi karşıya yükleme, bunlara erişme ve verileri keşfetme öğreticisini tamamlayın. İlk veri varlığını oluşturmak için tüm kodu çalıştırdığınızdan emin olun. İsterseniz verileri inceleyebilir ve düzeltebilirsiniz, ancak yalnızca bu öğretici için ilk verilere ihtiyacınız vardır.
-
Çalışma alanınızda bir not defteri açın veya oluşturun:
- Kod kopyalayıp hücrelere yapıştırmak istiyorsanız yeni bir not defteri oluşturun.
- Veya studio'nun Örnekler bölümünde tutorials/get-started-notebooks/pipeline.ipynb dosyasını açın. Ardından Kopyala'yı seçerek not defterini Dosyalarınıza ekleyin. Örnek not defterlerini bulmak için bkz . Örnek not defterlerinden öğrenme.
Çekirdeğinizi ayarlayın ve Visual Studio Code'da (VS Code) açın
Açık not defterinizin üst çubuğunda, henüz yoksa bir işlem örneği oluşturun.

İşlem örneği durdurulduysa İşlemi başlat'ı seçin ve çalışana kadar bekleyin.

İşlem örneği çalışana kadar bekleyin. Ardından sağ üst kısımda bulunan çekirdeğin olduğundan
Python 3.10 - SDK v2emin olun. Aksi takdirde, bu çekirdeği seçmek için açılan listeyi kullanın.
Bu çekirdeği görmüyorsanız işlem örneğinizin çalıştığını doğrulayın. Bu durumda, not defterinin sağ üst kısmındaki Yenile düğmesini seçin.
Kimliğinizin doğrulanması gerektiğini belirten bir başlık görürseniz Kimliği Doğrula'yı seçin.
Not defterini burada çalıştırabilir veya Azure Machine Learning kaynaklarının gücüyle tam tümleşik bir geliştirme ortamı (IDE) için VS Code'da açabilirsiniz. VS Code'da Aç'ı ve ardından web veya masaüstü seçeneğini belirleyin. Bu şekilde başlatıldığında VS Code işlem örneğinize, çekirdeğinize ve çalışma alanı dosya sisteminize eklenir.





Önemli
Bu öğreticinin geri kalanı, öğretici not defterinin hücrelerini içerir. Bunları kopyalayıp yeni not defterinize yapıştırın veya kopyaladıysanız şimdi not defterine geçin.
İşlem hattı kaynaklarını ayarlama
Azure CLI, Python SDK veya stüdyo arabiriminden Azure Machine Learning çerçevesini kullanabilirsiniz. Bu örnekte, işlem hattı oluşturmak için Azure Machine Learning Python SDK v2'yi kullanırsınız.
İşlem hattını oluşturmadan önce şu kaynaklara ihtiyacınız vardır:
- Eğitim için veri varlığı
- İşlem hattını çalıştırmak için yazılım ortamı
- İşin yürütüldüğü işlem kaynağı
Çalışma alanına tanıtıcı oluşturma
Kodu kullanmadan önce çalışma alanınıza referans gösterebilmek için bir yola ihtiyacınız var.
ml_client öğesini çalışma alanında bir tutum olarak oluşturun. Daha sonra kaynakları ve işleri yönetmek için kullanırsınız ml_client .
Sonraki hücreye Abonelik Kimliğinizi, Kaynak Grubu adınızı ve Çalışma Alanı adınızı girin. Bu değerleri bulmak için:
- Sağ üst Azure Machine Learning stüdyosu araç çubuğunda çalışma alanı adınızı seçin.
- Çalışma alanı, kaynak grubu ve abonelik kimliğinin değerini koda kopyalayın. Bir değeri kopyalamanız, alanı kapatmanız ve yapıştırmanız ve ardından sonraki değer için döndürmeniz gerekir.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
SDK Referansı:
Not
MLClient oluşturma çalışma alanına bağlanmaz. İstemci başlatması gecikmeli. İlk defa bir arama yapması gerektiğinde bekler. Başlatma sonraki kod hücresinde gerçekleşir.
çağrısı ml_clientyaparak bağlantıyı doğrulayın. Bu arama çalışma alanına ilk kez çağrı yaptığınızdan kimlik doğrulaması yapmanız istenebilir.
# Verify that the handle works correctly.
# If you get an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
SDK Referansı:
Kayıtlı veri varlığına erişme
Öğretici: Azure Machine Learning'de verilerinizi karşıya yükleme, erişme ve keşfetme kısmında önceden kaydettiğiniz verilerle başlayın.
Not
Azure Machine Learning, verilerin Data yeniden kullanılabilir bir tanımını kaydetmek ve verileri bir işlem hattı içinde kullanmak için bir nesne kullanır.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
SDK Referansı:
İşlem hattı adımları için iş ortamı oluşturma
Şimdiye kadar, geliştirme makineniz olan hesaplama örneğinde bir geliştirme ortamı oluşturdunuz. ayrıca işlem hattının her adımı için kullanılacak bir ortama da ihtiyacınız vardır. Her adımın kendi ortamı olabilir veya birden çok adım için bazı ortak ortamları kullanabilirsiniz.
Bu örnekte, conda yaml dosyası kullanarak işleriniz için bir conda ortamı oluşturursunuz. İlk olarak, dosyayı depolamak için bir dizin oluşturun.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Şimdi dosyayı bağımlılıklar dizininde oluşturun.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.10
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
Belirtim, işlem hattınızda kullandığınız bazı normal paketleri (numpy, pip) ve bazı Azure Machine Learning'e özgü paketleri (azureml-mlflow) içerir.
Azure Machine Learning işlerini çalıştırmak için Azure Machine Learning paketleri gerekmez. Bu paketleri ekleyerek, Azure Machine Learning işi içinde Azure Machine Learning ile etkileşim kurabilir, ölçümleri günlüğe kaydedebilir ve modelleri kaydedebilirsiniz. Bunları bu öğreticinin devamında eğitim betiğinde kullanacaksınız.
Bu özel ortamı oluşturmak ve çalışma alanınıza kaydetmek için yaml dosyasını kullanın:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
SDK Referansı:
Eğitim işlem hattını oluşturma
artık işlem hattınızı çalıştırmak için gereken tüm varlıklara sahip olduğunuz için işlem hattının kendisini oluşturmanın zamanı geldi.
Azure Machine Learning işlem hatları, genellikle çeşitli bileşenlerden oluşan yeniden kullanılabilir ML iş akışlarıdır. Bir bileşenin tipik yaşam döngüsü şöyledir:
- Bileşenin YAML belirtimini yazın veya bunu
ComponentMethodkullanarak programatik şekilde oluşturun. - İsteğe bağlı olarak, yeniden kullanılabilir ve paylaşılabilir hale getirmek için bileşeni çalışma alanınıza bir ad ve sürümle kaydedin.
- Bu bileşeni işlem hattı kodundan yükleyin.
- Bileşenin girişlerini, çıkışlarını ve parametrelerini kullanarak işlem hattını uygulayın.
- İşlem hattını gönderin.
Bir bileşeni iki şekilde oluşturabilirsiniz: programlı tanım ve YAML tanımı. Sonraki iki bölümde bileşen oluşturma adımları her iki şekilde de izlenmiştir. Her iki seçeneği de deneyerek iki bileşeni oluşturabilir veya tercih ettiğiniz yöntemi seçebilirsiniz.
Not
Bu öğreticide kolaylık sağlamak için tüm bileşenler için aynı hesaplama kullanılır. Ancak, her bileşen için farklı hesaplamalar ayarlayabilirsiniz. Örneğin, gibi train_step.compute = "cpu-cluster"bir satır ekleyebilirsiniz. Her bileşen için farklı işlemlerle işlem hattı oluşturma örneğini görüntülemek için cifar-10 işlem hattı öğreticisindeki Temel işlem hattı işi bölümüne bakın.
Bileşen oluşturma 1: veri hazırlığı (programlı tanımı kullanarak)
İlk bileşeni oluşturarak başlayın. Bu bileşen, verilerin ön işlemesini işler. Ön işleme görevi data_prep.py Python dosyasında gerçekleştirilir.
İlk olarak, data_prep bileşeni için bir kaynak klasör oluşturun:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Bu betik, verileri eğitme ve test veri kümelerine bölme basit görevini gerçekleştirir. Azure Machine Learning, veri kümelerini işlemlere klasör olarak bağlar. Bağlı giriş klasörünün içindeki veri dosyasına erişmek için bir yardımcı select_first_file işlev oluşturdunuz.
MLFlow işlem hattı çalışıyorken parametreleri ve ölçümleri günlüğe kaydetmek için kullanılır.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
artık istediğiniz görevi gerçekleştirebilen bir betiğiniz olduğuna göre, bundan bir Azure Machine Learning Bileşeni oluşturun.
Komut satırı eylemlerini çalıştırabilen genel amacı CommandComponent kullanın. Bu komut satırı eylemi doğrudan sistem komutlarını çağırabilir veya bir betik çalıştırabilir. Girişler ve çıkışlar, komut satırında ${{ ... }} gösterimini kullanarak belirtilir.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
SDK Referansı:
İsteğe bağlı olarak, gelecekte yeniden kullanmak üzere bileşeni çalışma alanına kaydedin.
# Now register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create and register the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
SDK Referansı:
Bileşen oluşturma 2: eğitim (yaml tanımını kullanarak)
Oluşturduğunuz ikinci bileşen eğitim ve test verilerini kullanır, ağaç tabanlı bir model eğitir ve çıkış modelini döndürür. Öğrenme ilerleme durumunu kaydetmek ve görselleştirmek için Azure Machine Learning günlük özelliklerini kullanın.
sınıfını CommandComponent ilk bileşeninizi oluşturmak için kullandınız. Bu kez, ikinci bileşeni tanımlamak için yaml tanımını kullanırsınız. Her yöntemin kendi avantajları vardır. YAML tanımı kodla birlikte versiyon kontrolüne eklenebilir ve okunabilir bir geçmiş takibi sağlar. Kullanarak programlama yöntemi CommandComponent , yerleşik sınıf belgeleri ve kod tamamlama ile daha kolay olabilir.
Bu bileşen için dizini oluşturun:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Dizinde eğitim betiğini oluşturun:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Bu eğitim betiğinde görebileceğiniz gibi model eğitildikten sonra model dosyası kaydedilir ve çalışma alanına kaydedilir. Artık uç noktaları çıkarsamada kayıtlı modeli kullanabilirsiniz.
Bu adımın ortamı için yerleşik (seçilmiş) Azure Machine Learning ortamlarından birini kullanırsınız.
azureml etiketi, sisteme adı özenle hazırlanmış ortamlarda aramasını söyler.
İlk olarak, bileşeni açıklayan yaml dosyasını oluşturun:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Şimdi bileşeni oluşturun ve kaydedin. Kaydetmek, diğer işlem hatlarında yeniden kullanmanıza olanak tanır. Çalışma alanınıza erişimi olan diğer herkes de kayıtlı bileşeni kullanabilir.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create and register the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
SDK Referansı:
Bileşenlerden işlem hattı oluşturma
Bileşenlerinizi tanımlayıp kaydettikten sonra işlem hattını uygulamaya başlayın.
load_component() tarafından döndürülen Python işlevleri, herhangi bir normal Python işlevi gibi çalışır. Her adımı çağırmak için bunları bir işlem hattında kullanın.
İşlem hattını kodlamak için Azure Machine Learning işlem hatlarını tanımlayan belirli @dsl.pipeline bir dekoratör kullanın. Dekoratörde işlem hattı açıklamasını ve işlem ve depolama gibi varsayılan kaynakları belirtin. Python işlevinde olduğu gibi işlem hatlarında da girişler olabilir. Farklı girişlere sahip tek bir işlem hattının birden çok örneğini oluşturabilirsiniz.
Aşağıdaki örnekte giriş verileri, bölme oranı ve kayıtlı model adını giriş değişkenleri olarak kullanın. Ardından, bileşenleri çağırın ve giriş ve çıkış tanımlayıcılarını kullanarak bağlayın.
.outputs özelliğini kullanarak her adımın çıkışlarına erişin.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
SDK Referansı:
Şimdi işlem hattı tanımınızı kullanarak veri kümenizle bir işlem hattı oluşturun, seçtiğiniz bölme oranını ve modeliniz için belirlediğiniz adı kullanın.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
SDK Referansı:
İşi gönderme
Şimdi işi Azure Machine Learning'de çalıştırılacak şekilde gönderin. Bu kez üzerinde create_or_updatekullanınml_client.jobs.
Deneme adını verin. Deneme, belirli bir projede yapılan tüm yinelemeler için bir kapsayıcıdır. Aynı deneme adı altında gönderilen tüm işler Azure Machine Learning studio'da yan yana görünür.
İşlem hattı tamamlandıktan sonra, eğitimin bir sonucu olarak çalışma alanınıza bir model kaydeder.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
SDK Referansı:
Önceki hücrede oluşturulan bağlantıyı kullanarak işlem hattınızın ilerleme durumunu izleyebilirsiniz. Bu bağlantıyı ilk kez seçtiğinizde işlem hattının hala çalıştığını görebilirsiniz. Tamamlandığında, her bileşenin sonuçlarını inceleyebilirsiniz.
Kredi Varsayılanları Modelini Eğit bileşenine çift tıklayın.
Eğitim hakkında görmek istediğiniz iki önemli sonuç:
Günlüklerinizi görüntüleyin:
- Çıkışlar+günlükler sekmesini seçin.
- Klasörleri
user_logs>std_log.txtBu bölümde açın, betik çalıştırma stdout'u gösterir.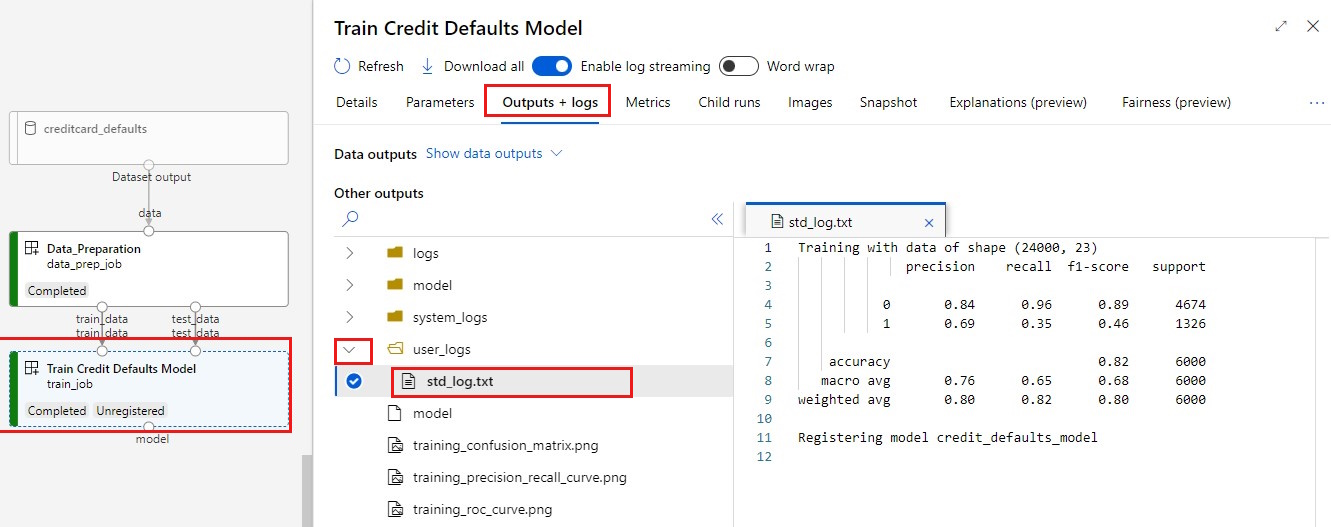
Ölçümlerinizi görüntüleme: Ölçümler sekmesini seçin. Bu bölümde farklı günlüğe kaydedilen ölçümler gösterilir. Bu örnekte mlflow
autologging, eğitim ölçümlerini otomatik olarak günlüğe kaydeder.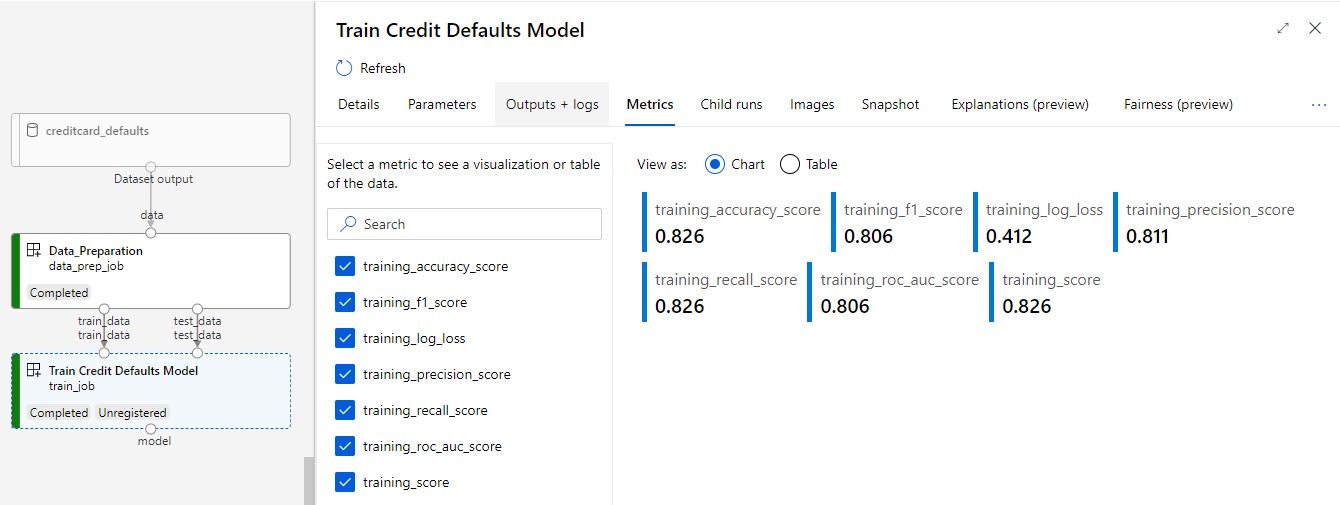


Modeli çevrimiçi uç nokta olarak dağıtma
Modelinizi çevrimiçi uç noktaya dağıtma hakkında daha fazla bilgi için bkz. Modeli çevrimiçi uç nokta olarak dağıtma öğreticisi.
Kaynakları temizleme
Diğer öğreticilere devam etmek istiyorsanız Sonraki adıma geçin.
İşlem örneğini durdurma
İşlem örneğini şimdi kullanmayacaksanız durdurun:
- Stüdyoda, sol bölmede İşlem'i seçin.
- Üst sekmelerde İşlem örnekleri'ni seçin.
- Listeden işlem örneğini seçin.
- Üst araç çubuğunda Durdur'u seçin.
Tüm kaynakları silme
Önemli
Oluşturduğunuz kaynaklar, diğer Azure Machine Learning öğreticileri ve nasıl yapılır makaleleri için önkoşul olarak kullanılabilir.
Oluşturduğunuz kaynaklardan hiçbirini kullanmayı planlamıyorsanız, ücret ödememek için bunları silin:
Azure portalındaki arama kutusuna Kaynak grupları yazın ve sonuçlardan seçin.
Listeden, oluşturduğunuz kaynak grubunu seçin.
Genel Bakış sayfasında Kaynak grubunu sil'i seçin.
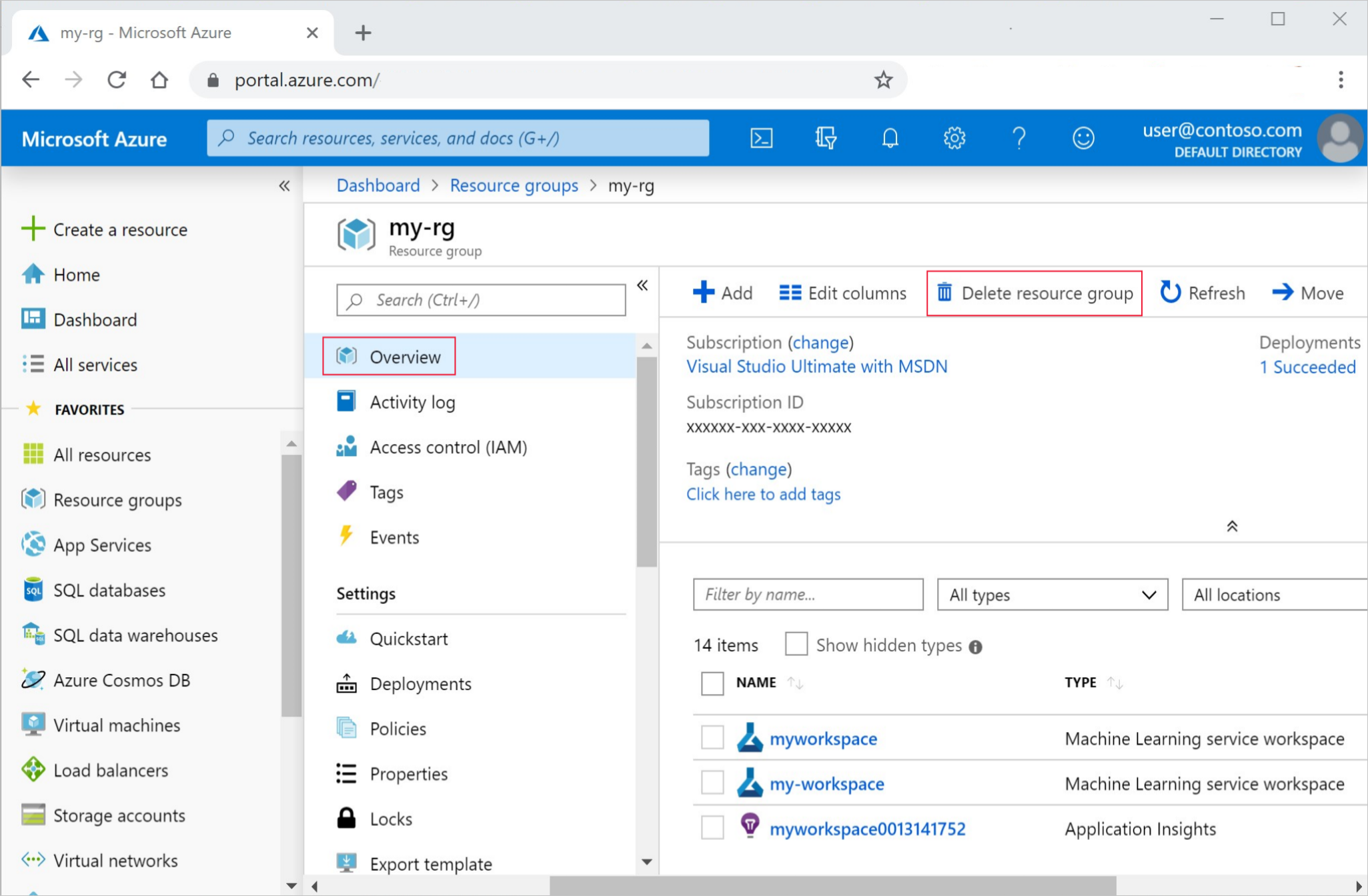
Kaynak grubu adını girin. Ardından Sil'i seçin.