Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Görüntüler genellikle arama senaryolarıyla ilgili yararlı bilgiler içerir. Arama dizininizdeki görsel içeriği temsil etmek için görüntüleri vektörleştirebilirsiniz . İsterseniz, yapay zeka destekli geliştirmeler ve beceriler kullanarak görüntülerden aranabilir metinler oluşturabilir ve ayıklayabilirsiniz; örneğin:
- Metin ve basamakların optik karakter tanıması için OCR
- Görsel özellikler aracılığıyla görüntüleri açıklayan Görüntü Analizi
- Sağlamak istediğiniz dış görüntü işlemeyi çağırmak için özel beceriler
OCR kullanarak, fotoğraf veya resimlerden stop işaretinde DUR sözcüğü gibi metinleri ve resimleri ayıklayabilirsiniz. Görüntü analizi aracılığıyla, bir karahindiba fotoğrafı için karahindiba veya sarı renk gibi bir resmin metin gösterimini oluşturabilirsiniz. Görüntüyle ilgili boyutu gibi meta verileri de ayıklayabilirsiniz.
Bu makalede beceri kümelerindeki görüntülerle çalışmanın temelleri ele alınır ve ekli görüntülerle çalışma, özel beceriler ve özgün görüntülerde görselleştirmeleri katmanlama gibi çeşitli yaygın senaryolar açıklanmaktadır.
Beceri kümesindeki görüntü içeriğiyle çalışmak için şunları yapmanız gerekir:
- Görüntü içeren kaynak dosyalar
- Görüntü eylemleri için yapılandırılmış bir arama dizin oluşturucu
- OCR veya görüntü analizini çağıran yerleşik veya özel becerilere sahip bir beceri kümesi
- Analiz edilen metin çıkışını almak için alanlar içeren bir arama dizini ve ilişkilendirme oluşturan dizin oluşturucuda çıkış alanı eşlemeleri
İsteğe bağlı olarak, veri madenciliği senaryoları için görüntü analizi çıktısını bir bilgi deposuna kabul etmek için projeksiyonlar tanımlayabilirsiniz.
Kaynak dosyaları ayarlama
Görüntü işleme dizin oluşturucu temellidir; bu da ham girişlerin desteklenen bir veri kaynağında olması gerektiği anlamına gelir.
- Görüntü analizi JPEG, PNG, GIF ve BMP'yi destekler
- OCR JPEG, PNG, BMP ve TIF'yi destekler
Görüntüler tek başına ikili dosyalardır veya PDF, RTF veya Microsoft uygulama dosyaları gibi belgelere eklenir. Belirli bir belgeden en fazla 1.000 resim ayıklanabilir. Belgede 1.000'den fazla resim varsa, ilk 1.000 ayıklanır ve ardından bir uyarı oluşturulur.
Azure Blob Depolama, Azure AI Search'te görüntü işleme için en sık kullanılan depolama alanıdır. Blob kapsayıcısından görüntü almayla ilgili üç ana görev vardır:
Kapsayıcıdaki içeriğe erişimi etkinleştirin. Anahtar içeren bir tam erişim bağlantı dizesi kullanıyorsanız, anahtar size içerik için izin verir. Alternatif olarak, Microsoft Entra Kimliğini kullanarak kimlik doğrulaması yapabilir veya güvenilir bir hizmet olarak bağlanabilirsiniz.
Dosyalarınızı depolayan blob kapsayıcısına bağlanan azureblob türünde bir veri kaynağı oluşturun.
Kaynak verilerinizin dizin oluşturucular ve zenginleştirme için maksimum boyut ve miktar sınırları altında olduğundan emin olmak için hizmet katmanı sınırlarını gözden geçirin.
Görüntü işleme için dizin oluşturucuları yapılandırma
Kaynak dosyalar ayarlandıktan sonra dizin oluşturucu yapılandırmasında parametresini ayarlayarak görüntü normalleştirmesini imageAction etkinleştirin. Görüntü normalleştirme, aşağı akış işleme için görüntülerin daha düzgün hale getirilmesine yardımcı olur. Görüntü normalleştirme aşağıdaki işlemleri içerir:
- Büyük görüntüler, tekdüzen hale getirmek için maksimum yükseklik ve genişlikte yeniden boyutlandırılır.
- Yönlendirmeyi belirten meta verileri olan görüntülerde, görüntü döndürme dikey yükleme için ayarlanır.
imageAction parametresinin none dışında bir değere ayarlanmasının, Azure AI Search fiyatlandırmasına göre görüntü ayıklama için ek ücrete yol açacağını unutmayın.
Meta veri ayarlamaları, her görüntü için oluşturulan karmaşık bir türde yakalanır. Görüntü normalleştirme gereksinimini geri çeviremezsiniz. OCR ve görüntü analizi gibi görüntüler üzerinde yineleyen beceriler normalleştirilmiş görüntüler bekler.
Yapılandırma özelliklerini ayarlamak için dizin oluşturucu oluşturun veya güncelleştirin:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }olarak
dataToExtractayarlayıncontentAndMetadata(gerekli).öğesinin
parsingModevarsayılan (gerekli) olarak ayarlandığını doğrulayın.Bu parametre, dizinde oluşturulan arama belgelerinin ayrıntı düzeyini belirler. Varsayılan mod, bir blob tek bir arama belgesiyle sonuçlanabilecek şekilde bire bir yazışma ayarlar. Belgeler büyükse veya beceriler daha küçük metin öbekleri gerektiriyorsa, işleme amacıyla belgeyi sayfalandırmaya alt bölümlere ayıran Metin Bölme becerisini ekleyebilirsiniz. Ancak arama senaryoları için zenginleştirme görüntü işleme içeriyorsa belge başına bir blob gerekir.
Zenginleştirme ağacında düğümü
imageActionetkinleştirmek için ayarlayınnormalized_images(gerekli):generateNormalizedImagesbelgenin kırılmasının bir parçası olarak normalleştirilmiş görüntüler dizisi oluşturmak için.generateNormalizedImagePerPage(yalnızca PDF için geçerlidir), PDF'deki her sayfanın bir çıkış görüntüsüne işlendiği normalleştirilmiş görüntüler dizisi oluşturmak için. PDF olmayan dosyalar için bu parametrenin davranışı, ayarlamışgenerateNormalizedImagesolduğunuz gibi benzerdir. Ancak, birkaç görüntünün oluşturulması gerekeceğinden, ayargenerateNormalizedImagePerPagedizin oluşturma işlemini tasarım gereği daha az performansa (özellikle büyük belgeler için) ayarlayabilir.
İsteğe bağlı olarak, oluşturulan normalleştirilmiş görüntülerin genişliğini veya yüksekliğini ayarlayın:
normalizedImageMaxWidthpiksel cinsinden. Varsayılan değer 2.000'dir. En yüksek değer 10.000'dir.normalizedImageMaxHeightpiksel cinsinden. Varsayılan değer 2.000'dir. En yüksek değer 10.000'dir.
Normalleştirilmiş görüntüler için maksimum genişlik ve yükseklik için varsayılan olarak 2.000 piksel, OCR becerisi ve görüntü analizi becerisi tarafından desteklenen maksimum boyutlara bağlıdır. OCR becerisi, İngilizce olmayan diller için maksimum genişlik ve yükseklik 4.200,İngilizce için 10.000'i destekler. Maksimum sınırları artırırsanız, beceri kümesi tanımınıza ve belgelerin diline bağlı olarak daha büyük görüntülerde işleme başarısız olabilir.
İsteğe bağlı olarak, iş yükü belirli bir dosya türünü hedeflediyse dosya türü ölçütlerini ayarlayın. Blob dizin oluşturucu yapılandırması, dosya ekleme ve dışlama ayarlarını içerir. istemediğiniz dosyaları filtreleyebilirsiniz.
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Normalleştirilmiş görüntüler hakkında
Hiçbiri imageActiondışında bir değere ayarlandığında, yeni normalized_images alan bir görüntü dizisi içerir. Her görüntü, aşağıdaki üyelere sahip karmaşık bir türdür:
| Görüntü üyesi | Açıklama |
|---|---|
| veriler | JPEG biçiminde normalleştirilmiş görüntünün BASE64 kodlanmış dizesi. |
| Genişlik | Normalleştirilmiş görüntünün piksel cinsinden genişliği. |
| yükseklik | Normalleştirilmiş görüntünün piksel cinsinden yüksekliği. |
| orijinalGenişlik | Normalleştirmeden önce görüntünün özgün genişliği. |
| orijinal yükseklik | Normalleştirmeden önce görüntünün özgün yüksekliği. |
| OrijinaldenDönmeRotasyonu | Normalleştirilmiş görüntüyü oluşturmak için oluşan derecelerde saat yönünün tersine döndürme. 0 derece ile 360 derece arasında bir değer. Bu adım, kamera veya tarayıcı tarafından oluşturulan görüntüdeki meta verileri okur. Genellikle 90 derecenin katı. |
| içerik ofseti | Görüntünün ayıklandığı içerik alanı içindeki karakter uzaklığı. Bu alan yalnızca eklenmiş görüntüleri olan dosyalar için geçerlidir.
contentOffset PDF belgelerinden ayıklanan görüntüler için her zaman belgede ayıklandığı sayfadaki metnin sonundadır. Bu, resmin sayfadaki özgün konumundan bağımsız olarak, resimlerin o sayfadaki tüm metinlerden sonra görüneceği anlamına gelir. |
| sayfa numarası | Resim PDF'den ayıklandıysa veya işlendiyse, bu alan ayıklandığı veya işlendiği PDF'deki sayfa numarasını 1'den başlayarak içerir. Resim PDF'den değilse, bu alan 0'dır. |
| boundingPolygon | Resim PDF'den ayıklandıysa veya işlendiyse, bu alan görüntüyü sayfaya çevreleyen sınırlayıcı çokgenin koordinatlarını içerir. Çokgen, her noktanın sayfa boyutlarına normalleştirilmiş x ve y koordinatlarına sahip olduğu iç içe nokta dizisi olarak temsil edilir. Bu yalnızca kullanılarak imageAction: generateNormalizedImagesayıklanan görüntüler için geçerlidir. |
örnek değeri normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2,
"boundingPolygon": "[[{\"x\":0.0,\"y\":0.0},{\"x\":500.0,\"y\":0.0},{\"x\":0.0,\"y\":300.0},{\"x\":500.0,\"y\":300.0}]]"
}
]
Not
Sınırlayıcı çokgen verileri, iç içe çift JSON kodlu çokgen dizisi içeren bir dize olarak temsil edilir. Her çokgen, her noktanın x ve y koordinatlarına sahip olduğu bir nokta dizisidir. Koordinatlar PDF sayfasına göredir ve başlangıç noktası (0, 0) sol üst köşededir.
Şu anda imageAction: generateNormalizedImages kullanılarak ayıklanan görüntüler her zaman tek bir çokgen oluşturur, ancak birden çok çokgeni destekleyen Belge Düzeni özelliğiyle tutarlılığı sağlamak için çift katmanlı yapı korunur.
Görüntü işleme için beceri kümelerini tanımlama
Bu bölüm, görüntü işlemeyle ilgili olarak beceri girişleriyle , çıkışlarla ve desenlerle çalışmaya yönelik bağlam sağlayarak beceri başvuru makalelerini tamamlar.
Beceri eklemek için beceri kümesi oluşturun veya güncelleştirin.
Azure portalından OCR ve Görüntü Analizi için şablonlar ekleyin veya beceri başvurusu belgelerindeki tanımları kopyalayın. Bunları beceri kümesi tanımınızın beceri dizisine ekleyin.
Gerekirse beceri kümesinin Azure AI hizmetleri özelliğine çok hizmetli bir anahtar ekleyin. Azure AI Search, ücretsiz sınırı (dizin oluşturucu başına günde 20) aşan işlemler için OCR için faturalanabilir bir Azure AI hizmetleri kaynağına ve görüntü analizine yönelik çağrılar yapar. Azure yapay zeka hizmetlerinin arama hizmetinizle aynı bölgede olması gerekir.
Özgün görüntüler PDF'ye veya PPTX veya DOCX gibi uygulama dosyalarına eklenmişse, resim çıkışıyla metin çıkışını birlikte kullanmak istiyorsanız Metin Birleştirme becerisi eklemeniz gerekir. Ekli görüntülerle çalışma konusu bu makalede daha ayrıntılı olarak ele alınılmaktadır.
Beceri kümenizin temel çerçevesi oluşturulduktan ve Azure AI hizmetleri yapılandırıldıktan sonra her bir görüntü becerisine odaklanabilir, girişleri ve kaynak bağlamı tanımlayabilir ve çıkışları bir dizin veya bilgi deposundaki alanlarla eşleyebilirsiniz.
Not
Görüntü işlemeyi aşağı akış doğal dil işleme ile birleştiren örnek bir beceri kümesi için bkz . REST Öğreticisi: Azure bloblarından aranabilir içerik oluşturmak için REST ve AI kullanma. Beceri görüntüleme çıkışının varlık tanıma ve anahtar ifade ayıklamaya nasıl besleneceği gösterilir.
Görüntü işleme için girişler
Belirtildiği gibi, görüntüler belgenin kırılması sırasında ayıklanır ve bir ön adım olarak normalleştirilir. Normalleştirilmiş görüntüler, herhangi bir görüntü işleme becerisinin girişleridir ve her zaman iki yoldan biriyle zenginleştirilmiş bir belge ağacında temsil edilir:
/document/normalized_images/*, bütün olarak işlenen belgeler içindir./document/normalized_images/*/pagesöbekler (sayfalar) halinde işlenen belgeler içindir.
İster OCR'yi hem de görüntü analizini aynı şekilde kullanıyor olun, girişler neredeyse aynı yapıya sahiptir:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Çıkışları arama alanlarına eşleme
Beceri kümesinde Görüntü Analizi ve OCR beceri çıkışı her zaman metindir. Çıktı metni, iç zenginleştirilmiş belge ağacında düğümler olarak gösterilir ve her düğümün, içeriği uygulamanızda kullanılabilir hale getirmek için arama dizinindeki alanlara veya bilgi deposundaki projeksiyonlara eşlenmesi gerekir.
Beceri kümesinde, zenginleştirilmiş belgede hangi düğümlerin mevcut olduğunu belirlemek için her becerinin bölümünü gözden geçirin
outputs:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Beceri çıkışlarını kabul eden alanlar eklemek için bir arama dizini oluşturun veya güncelleştirin.
Aşağıdaki alan koleksiyonu örneğinde içerik blob içeriğidir. Metadata_storage_name dosyanın adını içerir (true
retrievableayarlanır). Metadata_storage_path, blobun benzersiz yoludur ve varsayılan belge anahtarıdır. Merged_content, Metin Birleştirme'den çıkarılır (resimler eklendiğinde kullanışlıdır).Text ve layoutText , OCR beceri çıkışlarıdır ve belgenin tamamı için OCR tarafından oluşturulan tüm çıkışı yakalamak için bir dize koleksiyonu olmalıdır.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Beceri kümesi çıkışını (zenginleştirme ağacındaki düğümler) dizin alanlarıyla eşlemek için dizin oluşturucuyu güncelleştirin.
Zenginleştirilmiş belgeler dahilidir. Zenginleştirilmiş belge ağacındaki düğümleri dışlaştırmak için, düğüm içeriğini hangi dizin alanının alacağını belirten bir çıkış alanı eşlemesi ayarlayın. Zenginleştirilmiş verilere uygulamanız tarafından bir dizin alanı üzerinden erişilir. Aşağıdaki örnekte, arama dizinindeki bir metin alanına eşlenmiş zenginleştirilmiş bir belgedeki metin düğümü (OCR çıktısı) gösterilmektedir.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Kaynak belge alma, görüntü işleme ve dizin oluşturmayı çağırmak için dizin oluşturucuyu çalıştırın.
Sonuçları doğrulama
Görüntü işlemenin sonuçlarını denetlemek için dizinde bir sorgu çalıştırın. Arama Gezgini'ni bir arama istemcisi veya HTTP istekleri gönderen herhangi bir araç olarak kullanın. Aşağıdaki sorgu, görüntü işlemenin çıkışını içeren alanları seçer.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR, görüntü dosyalarındaki metni tanır. Bu, kaynak belgeler saf metin veya saf görüntüyse OCR alanlarının (metin ve layoutText) boş olduğu anlamına gelir. Benzer şekilde, kaynak belge girişleri kesinlikle metinse görüntü çözümleme alanları (imageCaption ve imageTags) boş olur. Dizin oluşturucu yürütmesi, görüntüleme girişleri boşsa uyarılar gösterir. Zenginleştirilmiş belgede düğümler doldurulmadığında bu tür uyarılar beklenir. Blob dizin oluşturmanın, içerik türleriyle yalıtarak çalışmak istiyorsanız dosya türlerini dahil etmenizi veya hariç tutmanızı sağlar. Dizin oluşturucu çalıştırmaları sırasında gürültüyü azaltmak için bu ayarları kullanabilirsiniz.
Sonuçları denetlemek için alternatif bir sorgu içeriği ve merged_content alanlarını içerebilir. Bu alanların herhangi bir blob dosyası için içerik içerdiğine, hatta görüntü işlemenin yapılmadığı alanlara dikkat edin.
Beceri çıkışları hakkında
Beceri çıkışları şunlardır text : (OCR), layoutText (OCR), merged_content, captions (görüntü analizi), tags (görüntü analizi):
textOCR tarafından oluşturulan çıkışı depolar. Bu düğüm türündeCollection(Edm.String)bir alana eşlenmelidir. Arama belgesi başına birden çok resim içeren belgeler için virgülle ayrılmış dizelerden oluşan birtextalan vardır. Aşağıdaki çizimde üç belge için OCR çıkışı gösterilmektedir. İlk olarak, resim içermeyen bir dosya içeren belgedir. İkincisi, bir sözcük (Microsoft) içeren bir belgedir (görüntü dosyası). Üçüncüsü, birden çok resim içeren, bazıları metin içermeyen ("",) bir belgedir."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutText, sayfadaki metin konumu hakkında OCR tarafından oluşturulan ve normalleştirilmiş görüntünün sınırlayıcı kutuları ve koordinatları bakımından açıklanan bilgileri depolar. Bu düğüm türündeCollection(Edm.String)bir alana eşlenmelidir. Arama belgesi başına virgülle ayrılmış dizelerden oluşan birlayoutTextalan vardır.merged_contentMetin Birleştirme becerisinin çıkışını depolar ve kaynak belgeden ham metin içeren ve resmin yerine eklenmişEdm.Stringolan büyük türdetextbir alan olmalıdır. Dosyalar salt metin ise, OCR ve görüntü analizinin yapacak bir şeyi yoktur vemerged_contentaynı olurcontent(blobun içeriğini içeren bir blob özelliği).imageCaptionbir resmin açıklamasını bireysel etiketler olarak ve daha uzun bir metin açıklaması olarak yakalar.imageTagsbir resimle ilgili etiketleri anahtar sözcük koleksiyonu olarak depolar ve kaynak belgedeki tüm görüntüler için bir koleksiyon oluşturur.
Aşağıdaki ekran görüntüsü, metin ve eklenmiş görüntüler içeren bir PDF'nin çizimidir. Belge çatlama üç gömülü görüntü algıladı: martılar, harita, kartal sürü. Örnekteki diğer metinler (başlıklar, başlıklar ve gövde metni dahil) metin olarak ayıklandı ve görüntü işlemenin dışında tutuldu.
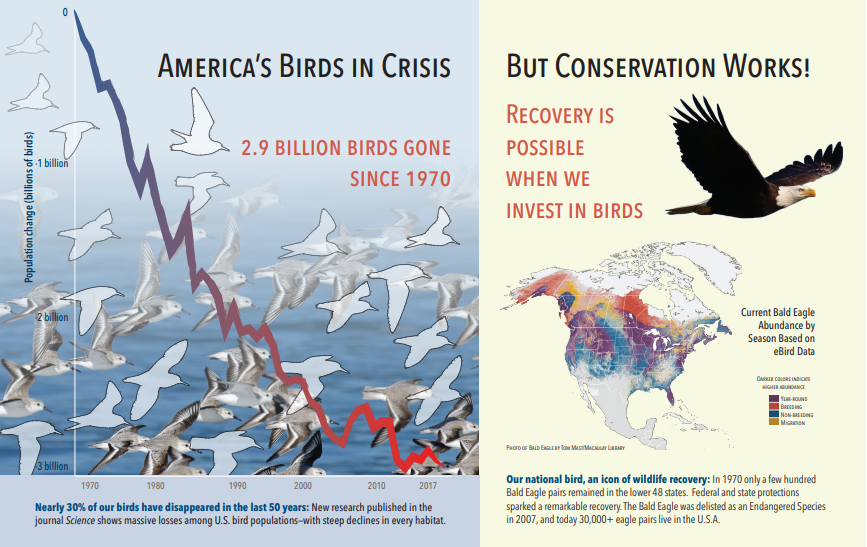
Görüntü analizi çıkışı aşağıdaki JSON'da (arama sonucu) gösterilmiştir. Beceri tanımı, hangi görsel özelliklerin ilgi çekici olduğunu belirtmenize olanak tanır. Bu örnekte etiketler ve açıklamalar üretildi, ancak aralarından seçim yapabileceğiniz daha fazla çıkış var.
imageCaptionoutput, tek sözcüklerden ve görüntüyü açıklayan daha uzun tümceciklerden oluşan, görüntütagsbaşına bir açıklama dizisidir. Martı sürülerinden oluşan etiketlerin suda yüzdüklerine veya bir kuşun yakın çekimlerine dikkat edin.imageTagsoutput, oluşturma sırasına göre listelenen tek etiketli bir dizidir. Etiketlerin yinelendiğini fark edin. Toplama veya gruplandırma yoktur.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Senaryo: PDF'lere eklenmiş görüntüler
İşlemek istediğiniz görüntüler PDF veya DOCX gibi diğer dosyalara eklendiğinde zenginleştirme işlem hattı yalnızca görüntüleri ayıklar ve sonra bunları işlemek üzere OCR'ye veya görüntü analizine geçirir. Görüntü ayıklama, belgenin kırılma aşamasında gerçekleşir ve görüntüler ayrıldıktan sonra, işlenen çıkışı kaynak metinle açıkça birleştirmediğiniz sürece bunlar ayrı kalır.
Metin Birleştirme , görüntü işleme çıktısını belgeye geri yerleştirmek için kullanılır. Metin Birleştirme zor bir gereksinim olmasa da, resim çıkışının (OCR metni, OCR layoutText, resim etiketleri, resim resim yazıları) belgeye yeniden eklenmesi için sık sık çağrılır. Beceriye bağlı olarak, görüntü çıkışı ekli ikili görüntüyü yerinde metin eşdeğeriyle değiştirir. Görüntü Analizi çıkışı, görüntü konumunda birleştirilebilir. OCR çıkışı her zaman her sayfanın sonunda görünür.
Aşağıdaki iş akışı görüntü ayıklama, analiz, birleştirme ve görüntü işlemeli çıkışı Varlık Tanıma veya Metin Çevirisi gibi diğer metin tabanlı becerilere göndermek için işlem hattını genişletme işlemini özetler.
Dizin oluşturucu, veri kaynağına bağlandıktan sonra kaynak belgeleri yükleyip kırıp görüntüleri ve metinleri ayıklar ve her içerik türünü işlenmek üzere kuyruğa alır. Yalnızca kök düğümden (belge) oluşan zenginleştirilmiş bir belge oluşturulur.
Kuyruktaki görüntüler normalleştirilir ve zenginleştirilmiş belgelere belge /normalized_images düğümü olarak geçirilir.
Görüntü zenginleştirmeleri giriş olarak kullanılarak
"/document/normalized_images"yürütülür.Görüntü çıkışları zenginleştirilmiş belge ağacına geçirilir ve her çıkış ayrı bir düğüm olarak gösterilir. Çıkışlar beceriye göre değişiklik gösterir (OCR için metin ve layoutText; Görüntü Analizi için etiketler ve açıklamalı alt yazılar).
İsteğe bağlı olarak, ancak arama belgelerinde hem metin hem de görüntü kaynağı metninin birlikte eklenmesini istiyorsanız, Metin Birleştirme çalışır ve bu görüntülerin metin gösterimini dosyadan ayıklanan ham metinle birleştirir. Metin öbekleri tek bir büyük dizede birleştirilir; burada metin önce dizeye, sonra da OCR metin çıkışına veya resim etiketlerine ve resim yazılarına eklenir.
Metin Birleştirme'nin çıktısı artık metin işleme gerçekleştiren aşağı akış becerileri için analize yönelik kesin metindir. Örneğin, beceri kümesiniz hem OCR hem de Varlık Tanıma içeriyorsa, Varlık Tanıma girişi (Metin Birleştirme beceri çıkışının targetName değeri) olmalıdır
"document/merged_text".Tüm beceriler yürütüldükten sonra zenginleştirilmiş belge tamamlanır. Son adımda dizin oluşturucular, arama dizinindeki tek tek alanlara zenginleştirilmiş içerik göndermek için çıkış alanı eşlemelerine başvurur.
Aşağıdaki örnek beceri kümesi, eklenmiş görüntüler yerine eklenmiş OCRed metin içeren belgenizin özgün metnini içeren bir merged_text alan oluşturur. Giriş olarak kullanan merged_text bir Varlık Tanıma becerisi de içerir.
İstek gövdesi söz dizimi
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Artık bir merged_text alanınız olduğuna göre, bunu dizin oluşturucu tanımınızda aranabilir bir alan olarak eşleyebilirsiniz. Resimlerin metni de dahil olmak üzere dosyalarınızın tüm içeriği aranabilir.
Senaryo: Sınırlayıcı kutuları görselleştirme
Diğer bir yaygın senaryo da arama sonuçları düzen bilgilerini görselleştirmektir. Örneğin, arama sonuçlarınızın bir parçası olarak görüntüde bir metin parçasının bulunduğu yeri vurgulamak isteyebilirsiniz.
OCR adımı normalleştirilmiş görüntülerde gerçekleştirildiğinden, düzen koordinatları normalleştirilmiş görüntü alanındadır, ancak özgün görüntüyü görüntülemeniz gerekiyorsa, düzendeki koordinat noktalarını özgün görüntü koordinat sistemine dönüştürün.
Aşağıdaki algoritmada desen gösterilmektedir:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Senaryo: Özel görüntü becerileri
Görüntüler özel becerilere de geçirilebilir ve bu becerilerden döndürülebilir. Base64 beceri kümesi, özel beceriye geçirilen görüntüyü kodlar. Görüntüyü özel beceri içinde kullanmak için, özel becerinin girişi olarak ayarlayın "/document/normalized_images/*/data" . Özel beceri kodunuzun içinde, base64 dizesini görüntüye dönüştürmeden önce kodunu çözebilirsiniz. Bir görüntüyü beceri kümesine döndürmek için, görüntüyü beceri kümesine döndürmeden önce base64 ile kodlayın.
Görüntü aşağıdaki özelliklere sahip bir nesne olarak döndürülür.
{
"$type": "file",
"data": "base64String"
}
Azure Search Python örnekleri deposu, Python'da görüntüleri zenginleştiren özel bir beceriye sahip eksiksiz bir örneğe sahiptir.
Görüntüleri özel becerilere geçirme
Görüntüler üzerinde çalışmak için özel beceriye ihtiyacınız olan senaryolarda, görüntüleri özel beceriye geçirebilir ve metin veya görüntü döndürmesini sağlayabilirsiniz. Aşağıdaki beceri kümesi bir örnekten alınmalıdır.
Aşağıdaki beceri kümesi normalleştirilmiş görüntüyü alır (belgenin kırılması sırasında elde edilir) ve görüntünün dilimlerini çıkarır.
Örnek beceri kümesi
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Özel beceri örneği
Özel becerinin kendisi beceri kümesinin dışındadır. Bu durumda, ilk olarak özel beceri biçimindeki istek kayıtları toplu işleminde döngüler oluşturan ve ardından base64 ile kodlanmış dizeyi bir görüntüye dönüştüren Python kodu olur.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Benzer şekilde bir görüntü döndürmek için, dosya$typesahip bir JSON nesnesi içinde base64 ile kodlanmış bir dize döndürür.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}