Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Azure Yapay Zeka Arama, verileri arama dizinine aktarmak için iki temel yöntemi destekler: verilerinizi program aracılığıyla dizine gönderme veya bir dizin oluşturucuyu desteklenen bir veri kaynağına işaret ederek verilerinizi çekme.
Bu öğreticide, istekleri toplu işleyerek ve üstel geri alma yeniden deneme stratejisi kullanarak gönderim modelini kullanarak verilerin nasıl verimli bir şekilde dizine alındığı açıklanmaktadır. Örnek uygulamayı indirip çalıştırabilirsiniz. Bu öğreticide ayrıca uygulamanın önemli yönleri ve verilerin dizinini oluştururken dikkate alınması gereken faktörler açıklanmaktadır.
Bu öğreticide, .NET için Azure SDK'sından C# ve Azure.Search.Documents kitaplığını aşağıdakiler için kullanırsınız:
- Dizin oluşturma
- En verimli boyutu belirlemek için çeşitli toplu iş boyutlarını test etme
- Toplu işleri zaman uyumsuz olarak dizine ekleme
- Dizin oluşturma hızlarını artırmak için birden çok iş parçacığı kullanma
- Başarısız belgeleri yeniden denemek için üstel gerialma stratejisi kullanın.
Önkoşullar
- Etkin aboneliği olan bir Azure hesabı. Ücretsiz hesap oluşturun.
- Visual Studio.
Dosyaları indirme
Bu öğreticinin kaynak kodu Azure-Samples/azure-search-dotnet-scale GitHub deposundaki optimize-data-indexing/v11 klasöründedir.
Dikkat edilmesi gereken temel konular
Aşağıdaki faktörler dizin oluşturma hızlarını etkiler. Daha fazla bilgi için bkz. Büyük veri kümelerini dizine alma.
- Fiyatlandırma katmanı ve bölüm/çoğaltma sayısı: Bölüm ekleme veya katmanınızı yükseltme dizin oluşturma hızlarını artırır.
- Dizin şeması karmaşıklığı: Alan ve alan özellikleri eklemek dizin oluşturma hızlarını düşürür. Daha küçük dizinleri dizine almak daha hızlıdır.
- Toplu iş boyutu: En uygun toplu iş boyutu, dizin şemanıza ve veri kümenize göre değişir.
- İş parçacığı/çalışan sayısı: Tek bir iş parçacığı dizin oluşturma hızlarından tam olarak yararlanmaz.
- Yeniden deneme stratejisi: Üstel geri alma yeniden deneme stratejisi, en iyi dizin oluşturma için en iyi yöntemdir.
- Ağ veri aktarım hızları: Veri aktarım hızları sınırlayıcı bir faktör olabilir. Veri aktarım hızlarını artırmak için Azure ortamınızdan verileri dizine alın.
Arama hizmeti oluşturma
Bu öğretici, Azure portalında oluşturabileceğiniz bir Azure AI Search hizmeti gerektirir. Mevcut bir hizmeti geçerli aboneliğinizde de bulabilirsiniz. Dizin oluşturma hızlarını doğru bir şekilde test etmek ve iyileştirmek için üretimde kullanmayı planladığınız fiyatlandırma katmanını kullanmanızı öneririz.
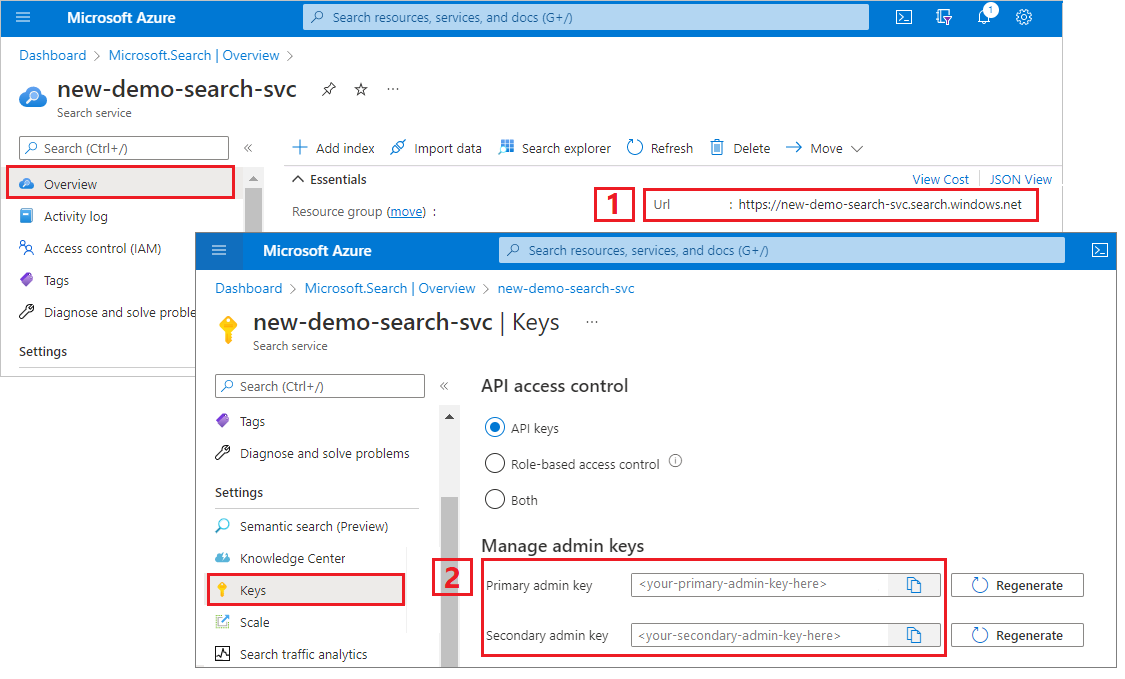
Azure Yapay Zeka Arama için yönetici anahtarı ve URL alma
Bu öğreticide anahtar tabanlı kimlik doğrulaması kullanılır. Dosyaya appsettings.json yapıştırmak için bir yönetici API anahtarı kopyalayın.
Sol bölmeden Genel Bakış'ı seçin ve uç noktayı kopyalayın. Şu biçimde olmalıdır:
https://my-service.search.windows.netSol bölmeden Ayarlar>Anahtarları'nı seçin ve hizmette tam haklar için bir yönetici anahtarı kopyalayın. İş sürekliliğini sağlamak için, birini değiştirmeniz gerektiğinde iki değiştirilebilir yönetici anahtarı sağlanmıştır. İsteklerde nesneleri eklemek, değiştirmek veya silmek için iki anahtardan birini kullanabilirsiniz.
Ortamınızı ayarlama
OptimizeDataIndexing.slnDosyayı Visual Studio'da açın.Çözüm Gezgini'nde
appsettings.json, dosyayı önceki adımda topladığınız bağlantı bilgileriyle düzenleyin.{ "SearchServiceUri": "https://{service-name}.search.windows.net", "SearchServiceAdminApiKey": "", "SearchIndexName": "optimize-indexing" }
Kodu keşfetme
'yi güncelleştirdikten appsettings.jsonsonra içindeki OptimizeDataIndexing.sln örnek program derlenip çalıştırılmaya hazır olmalıdır.
Bu kod, .NET SDK ile çalışmanın temelleri hakkında ayrıntılı bilgi sağlayan Hızlı Başlangıç: Tam metin arama'nın C# bölümünden türetilir.
Bu basit C#/.NET konsol uygulaması aşağıdaki görevleri gerçekleştirir:
- C#
Hotelsınıfının veri yapısını temel alan veAddresssınıfına da başvuran yeni bir indeks oluşturur. - En verimli boyutu belirlemek için çeşitli toplu iş boyutlarını test eder
- Verileri zaman uyumsuz olarak dizinler
- Dizin oluşturma hızlarını artırmak için birden çok iş parçacığı kullanma
- Başarısız olan öğeleri yeniden denemek için üstel geri çekilme stratejisini kullanma
Programı çalıştırmadan önce kodu ve bu örneğin dizin tanımlarını incelemek için bir dakikanızı alın. İlgili kod birkaç dosyadadır:
-
Hotel.csveAddress.csdizini tanımlayan şemayı içerir -
DataGenerator.csbüyük miktarda otel verisi oluşturmayı kolaylaştıran basit bir sınıf içerir -
ExponentialBackoff.csbu makalede açıklandığı gibi dizin oluşturma işlemini iyileştirmeye yönelik kod içerir -
Program.csAzure Yapay Zeka Arama dizinini oluşturma ve silme, veri gruplarını dizinleyen ve farklı grup boyutlarını test eden işlevler içerir
Dizini oluşturma
Bu örnek program, bir Azure Yapay Zeka Arama dizini tanımlamak ve oluşturmak için .NET için Azure SDK'sını kullanır. C# veri modeli sınıfından bir dizin yapısı oluşturmak için FieldBuilder sınıfından yararlanır.
Veri modeli, Hotel sınıfı tarafından tanımlanmış olup, bu sınıf aynı zamanda Address sınıfına referanslar içermektedir.
FieldBuilder dizin için karmaşık bir veri yapısı oluşturmak üzere birden çok sınıf tanımında detaya iner. Meta veri etiketleri, her alanın aranabilir veya sıralanabilir olması gibi öznitelikleri tanımlamak için kullanılır.
Dosyasındaki Hotel.cs aşağıdaki kod parçacıkları tek bir alan ve başka bir veri modeli sınıfına başvuru belirtir.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
Program.cs dosyasında dizin, bir ad ve FieldBuilder.Build(typeof(Hotel)) yöntemi tarafından oluşturulan bir alan koleksiyonuyla tanımlanır ve ardından şu şekilde oluşturulur:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Veri oluştur
Test verisi oluşturmak amacıyla DataGenerator.cs dosyasında basit bir sınıf uygulanmaktadır. Bu sınıfın amacı, dizin oluşturma için benzersiz bir kimlikle çok sayıda belge oluşturmayı kolaylaştırmaktır.
Benzersiz kimliklere sahip 100.000 otelin listesini almak için aşağıdaki kodu çalıştırın:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Bu örnekte test için kullanılabilecek iki otel boyutu vardır: küçük ve büyük.
Dizininizin şeması dizin oluşturma hızlarını etkiler. Bu öğreticiyi tamamladıktan sonra, hedeflenen dizin şemanıza en uygun verileri oluşturmak için bu sınıfı dönüştürmeyi göz önünde bulundurun.
Toplu iş boyutlarını test edin
Bir dizine tek veya birden çok belge yüklemek için Azure Yapay Zeka Arama aşağıdaki API'leri destekler:
Belgeleri toplu olarak dizine alma, dizin oluşturma performansını önemli ölçüde artırır. Bu yığınlar, en fazla 1.000 belge veya yığın başına yaklaşık 16 MB olabilir.
Verileriniz için en uygun toplu iş boyutunu belirlemek, dizin oluşturma hızlarını iyileştirmenin önemli bir bileşenidir. En uygun toplu iş boyutunu etkileyen iki birincil faktör şunlardır:
- Dizininizin şeması
- Verilerinizin boyutu
En uygun toplu iş boyutu dizininize ve verilerinize bağlı olduğundan en iyi yaklaşım, senaryonuz için en yüksek dizin oluşturma hızlarındaki sonuçları belirlemek üzere farklı toplu iş boyutlarını test etmektir.
Aşağıdaki işlev, toplu iş boyutlarını test etmeye yönelik basit bir yaklaşımı gösterir.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Tüm belgeler aynı boyutta olmadığından (bu örnekte olsalar da), arama hizmetine gönderdiğimiz verilerin boyutunu tahmin ediyoruz. Bunu yapmak için önce nesnesini JSON'a dönüştüren ve ardından bayt cinsinden boyutunu belirleyen aşağıdaki işlevi kullanabilirsiniz. Bu teknik, hangi toplu iş boyutlarının MB/sn dizin oluşturma hızları açısından en verimli olduğunu belirlememizi sağlar.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
İşlev, her toplu iş boyutu için test etmek istediğiniz deneme sayısının artısını SearchClient gerektirir. Her toplu iş için dizin oluşturma sürelerinde değişkenlik olabileceğinden, sonuçları istatistiksel olarak daha önemli hale getirmek için her toplu işlemi varsayılan olarak üç kez deneyin.
await TestBatchSizesAsync(searchClient, numTries: 3);
İşlevi çalıştırdığınızda konsolunuzda aşağıdaki örneğe benzer bir çıkış görmeniz gerekir:
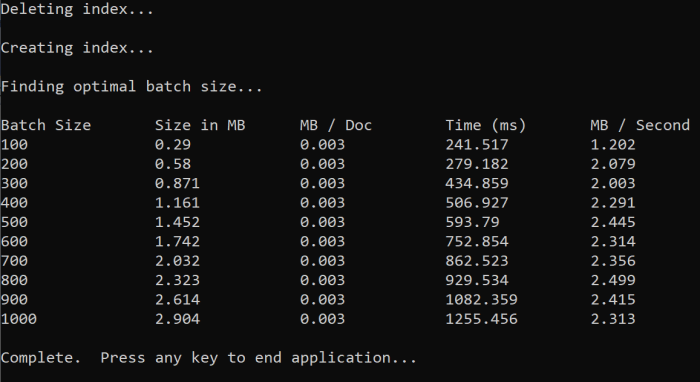
Hangi toplu iş boyutunun en verimli olduğunu belirleyin ve bu öğreticinin sonraki adımında bu toplu iş boyutunu kullanın. Farklı toplu iş boyutlarında MB/sn cinsinden bir düzey görebilirsiniz.
Verilerin dizinini oluşturma
Kullanmak istediğiniz toplu iş boyutunu tanımladığınıza göre, bir sonraki adım verilerin dizinini oluşturmaktır. Verileri verimli bir şekilde dizine almak için şu örnek:
- Birden çok iş parçacığı veya işçi kullanır
- Üstel gerileme yeniden deneme stratejisini uygular
41 ile 49 arasında açıklama satırlarını kaldırın ve programı yeniden çalıştırın. Bu çalıştırmada örnek, parametreleri değiştirmeden kodu çalıştırırsanız 100.000'e kadar toplu belge oluşturur ve gönderir.
Birden çok iş parçacığı/çalışan kullanma
Azure Yapay Zeka Arama'ün dizin oluşturma hızlarından yararlanmak için, toplu dizin oluşturma isteklerini aynı anda hizmete göndermek için birden çok iş parçacığı kullanın.
Önemli noktalardan birkaçı en uygun iş parçacığı sayısını etkileyebilir. Senaryonuz için en uygun iş parçacığı sayısını belirlemek için bu örneği değiştirebilir ve farklı iş parçacığı sayılarıyla test edebilirsiniz. Ancak, eşzamanlı olarak çalışan birkaç iş parçacığınız olduğu sürece, verimlilik kazançlarının çoğundan yararlanabilmeniz gerekir.
Arama hizmetine isabet eden istekleri artırdığınızda, isteğin tam olarak başarılı olmadığını belirten HTTP durum kodlarıyla karşılaşabilirsiniz. Dizin oluşturma sırasında iki yaygın HTTP durum kodu şunlardır:
- 503 Hizmet Kullanılamıyor: Bu hata, sistemin ağır yük altında olduğu ve isteğinizin şu anda işlenemeyeceği anlamına gelir.
- 207 Çoklu Durum: Bu hata, bazı belgelerin başarılı olduğu, ancak en az birinin başarısız olduğu anlamına gelir.
Üstel gerileme yeniden deneme stratejisini uygula
Bir hata olursa, üstel geri alma yeniden deneme stratejisini kullanarak istekleri yeniden denemeniz gerekir.
Azure Yapay Zeka Arama'ün .NET SDK'sı 503'leri ve diğer başarısız istekleri otomatik olarak yeniden dener, ancak 207'leri yeniden denemek için kendi mantığınızı uygulamanız gerekir. Polly gibi açık kaynak araçlar yeniden deneme stratejisinde yararlı olabilir.
Bu örnekte kendi üstel geri çekilme yeniden deneme stratejimizi uygulayacağız. İlk olarak başarısız bir istek için maxRetryAttempts ve delay dahil olmak üzere bazı değişkenler tanımlıyoruz.
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Dizin oluşturma işleminin sonuçları değişkeninde IndexDocumentResult resultdepolanır. Bu değişken, aşağıdaki örnekte gösterildiği gibi toplu işteki belgelerin başarısız olup olmadığını denetlemenizi sağlar. Kısmi bir hata varsa, başarısız belgelerin kimliğine göre yeni bir toplu iş oluşturulur.
RequestFailedException özel durumlar da yakalanmalıdır çünkü bu durum isteklerin tamamen başarısız olabileceğini gösterir ve yeniden denenmelidir.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Buradan, üstel geri alma kodunu kolayca çağrılabilmesi için bir işleve sarmalayın.
Daha sonra etkin iş parçacıklarını yönetmek için başka bir işlev oluşturulur. Kolaylık olması için bu işlev buraya dahil değildir ancak ExponentialBackoff.cs bulunabilir. Aşağıdaki komutu kullanarak işlevi çağırabilirsiniz; burada hotels karşıya yüklemek istediğimiz verilerdir, 1000 toplu işlem boyutudur, ve 8 eşzamanlı iş parçacıklarının sayısıdır.
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
İşlevi çalıştırdığınızda aşağıdaki örneğe benzer bir çıkış görmeniz gerekir:
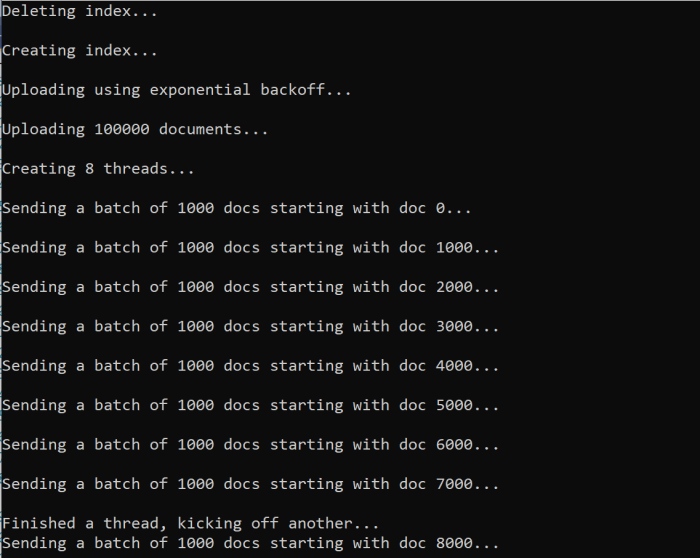
Bir grup belge başarısız olduğunda, hatanın ve toplu işlemin yeniden denendiğini belirten bir hata yazdırılır.
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
İşlevin çalışması tamamlandıktan sonra, tüm belgelerin dizine eklendiğini doğrulayabilirsiniz.
Dizini keşfetme
Program çalışmayı tamamladıktan sonra, program aracılığıyla veya Azure portalında Arama gezginini kullanarak doldurulmuş arama dizinini keşfedebilirsiniz.
Programlı olarak
Dizindeki belge sayısını denetlemek için iki ana seçenek vardır: Belgeleri Say API'si ve Dizin İstatistiklerini Al API'si. Her iki yolun da işlenmesi için zaman gerekir, bu nedenle döndürülen belge sayısı başlangıçta beklediğinizden daha düşükse alarma almayın.
Belgeleri Say
Belgeleri Say işlemi, arama dizinindeki belgelerin sayısını döndürür.
long indexDocCount = await searchClient.GetDocumentCountAsync();
Dizin İstatistiklerini Alma
Dizin İstatistiklerini Al işlemi geçerli dizin için bir belge sayısı ve depolama kullanımı döndürür. Dizin istatistiklerinin güncellenmesi belge sayısının güncellenmesinden daha uzun sürer.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure portal
Azure portalında, sol bölmeden Dizinler listesindeki optimize-indexing dizinini bulun.

Belge Sayısı ve Depolama Boyutu, Dizin İstatistiklerini Al API'sini temel alır ve güncelleştirilmek birkaç dakika sürebilir.
Sıfırla ve yeniden çalıştır
Geliştirmenin ilk deneysel aşamalarında tasarım yinelemesi için en pratik yaklaşım, nesneleri Azure Yapay Zeka Arama'ten silmek ve kodunuzun bunları yeniden oluşturmasına izin vermektir. Kaynak adları benzersizdir. Bir nesneyi sildiğinizde, aynı adı kullanarak nesneyi yeniden oluşturabilirsiniz.
Bu öğreticinin örnek kodu, mevcut dizinleri denetler ve kodunuzu yeniden çalıştırabilmeniz için bunları siler.
Dizinleri silmek için Azure portalını da kullanabilirsiniz.
Kaynakları temizle
Kendi aboneliğinizde çalışırken, bir projenin sonunda artık ihtiyacınız olmayan kaynakları kaldırmak iyi bir fikirdir. Çalışır durumda bırakılan kaynaklar sana pahalıya mal olabilir. Kaynakları tek tek silebilir veya kaynak grubunu silip kaynak kümesinin tamamını silebilirsiniz.
Sol gezinti bölmesindeki Tüm kaynaklar veya Kaynak grupları bağlantısını kullanarak Kaynakları Azure portalında bulabilir ve yönetebilirsiniz.
Sonraki adım
Büyük miktarlardaki verilerin dizinini oluşturma hakkında daha fazla bilgi edinmek için aşağıdaki öğreticiyi deneyin: