Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu Azure AI Search öğreticisinde, Spark kümesinden yüklenen büyük verileri dizine almayı ve sorgulamayı öğreneceksiniz. Jupyter Notebook'u şu şekilde ayarlarsınız:
- Apache Spark oturumunda veri çerçevesine çeşitli formlar (faturalar) yükleme
- Özelliklerini belirlemek için formları analiz etme
- Sonuçta elde edilen çıkışı tablosal veri yapısında bir araya getirme
- Çıktıyı Azure AI Search'te barındırılan bir arama dizinine yazma
- Oluşturduğunuz içeriği keşfetme ve sorgulama
Bu öğretici, büyük veriler üzerinde yüksek düzeyde paralel makine öğrenmesini destekleyen açık kaynak bir kitaplık olan SynapseML'ye bağımlılığını alır. SynapseML'de arama dizini oluşturma ve makine öğrenmesi, özel görevler gerçekleştiren transformatörler aracılığıyla kullanıma sunulur. Transformatörler çok çeşitli yapay zeka özelliklerine sahiptir. Bu alıştırmada analiz ve yapay zeka zenginleştirmesi için AzureSearchWriter API'lerini kullanacaksınız.
Azure AI Search'ün yerel yapay zeka zenginleştirmesi olsa da bu öğreticide, Azure AI Search dışında yapay zeka özelliklerine nasıl erişabileceğiniz gösterilmektedir. Dizin oluşturucular veya beceriler yerine SynapseML kullanarak veri sınırlarına veya bu nesnelerle ilişkili diğer kısıtlamalara tabi olmazsınız.
İpucu
Bu tanıtımın kısa bir videosunu izleyin. Video, daha fazla adım ve görselle bu öğreticide genişler.
Önkoşullar
Kitaplığa synapseml ve birkaç Azure kaynağına ihtiyacınız vardır. Mümkünse, Azure kaynaklarınız için aynı aboneliği ve bölgeyi kullanın ve daha sonra basit temizleme için her şeyi tek bir kaynak grubuna yerleştirin. Aşağıdaki bağlantılar portal yüklemelerine yöneliktir. Örnek veriler genel bir siteden içeri aktarılır.
- SynapseML paket1
- Azure AI Search (herhangi bir katman) 2
-
API Türü3 olan Azure AI hizmetleri çoklu hizmet hesabı (herhangi bir katman)
AIServices - Apache Spark 3.3.0 çalışma zamanı 4 ile Azure Databricks (herhangi bir katman)
1 Bu bağlantı, paketi yüklemeye yönelik bir öğreticiye yönlendirir.
2 Ücretsiz katmanını kullanarak örnek verilerin dizinini oluşturabilir, ancak veri hacimleriniz büyükse daha yüksek bir katman seçebilirsiniz . Faturalanabilir katmanlar için Bağımlılıkları Ayarla adımında arama API anahtarını sağlayın.
3 Bu öğreticide Azure AI Belge Zekası ve Azure AI Translator kullanılır. Aşağıdaki yönergelerde, bir çok hizmetli hesap anahtarı ve bölge sağlayın. Aynı anahtar her iki hizmet için de çalışır.
Bu öğreticide, API türünde AIServicesbir Azure AI hizmetleri çok hizmetli hesabı kullanmanız önemlidir. API türünü Azure portalında Azure yapay zeka hizmetleri çok hizmetli hesap sayfanızın Genel Bakış bölümünden de kontrol edebilirsiniz. API türü hakkında daha fazla bilgi için bkz. Azure AI Search'te Azure AI hizmetleri çoklu hizmet kaynağı ekleme.
4 Bu öğreticide, Azure Databricks Spark bilgi işlem platformunu sağlar. Kümeyi ve çalışma alanını ayarlamak için portal yönergelerini kullandık.
Not
Yukarıdaki Azure kaynakları, Microsoft Identity platformundaki güvenlik özelliklerini destekler. Kolaylık olması için bu öğreticide, her hizmetin Azure portalı sayfalarından kopyalanan uç noktaları ve anahtarları kullanarak anahtar tabanlı kimlik doğrulaması varsayılır. Bu iş akışını bir üretim ortamında uygularsanız veya çözümü başkalarıyla paylaşırsanız, sabit kodlanmış anahtarları tümleşik güvenlik veya şifrelenmiş anahtarlarla değiştirmeyi unutmayın.
Spark kümesi ve not defteri oluşturma
Bu bölümde bir küme oluşturacak, kitaplığı yükleyecek synapseml ve kodu çalıştırmak için bir not defteri oluşturacaksınız.
Azure portalında Azure Databricks çalışma alanınızı bulun ve Çalışma alanını başlat'ı seçin.
Soldaki menüde İşlem'i seçin.
İşlem oluşturmayı seçin.
Varsayılan yapılandırmayı kabul edin. Kümenin oluşturulması birkaç dakika sürer.
Kümenin çalışır durumda olduğunu ve çalıştığını doğrulayın. Küme adında yeşil bir nokta durumunu onaylar.
Küme oluşturulduktan sonra kitaplığını
synapsemlyükleyin:Küme sayfasının üst kısmındaki sekmelerden Kitaplıklar'ı seçin.
Yeni yükle'yi seçin.
Maven'ı seçin.
Koordinatlar içinde
com.microsoft.azure:synapseml_2.12:1.0.9arayın.Yükle'yi seçin.
Soldaki menüde Not Defteri>seçin.
Not defterine bir ad verin, varsayılan dil olarak Python'ı seçin ve kitaplığı olan kümeyi
synapsemlseçin.Ardışık yedi hücre oluşturun. Aşağıdaki bölümlerde, bu hücrelere kod yapıştırırsınız.
Bağımlılıkları ayarla
Aşağıdaki kodu not defterinizin ilk hücresine yapıştırın.
Yer tutucuları her kaynağın uç noktaları ve erişim anahtarlarıyla değiştirin. Sizin için oluşturulacak yeni arama dizini için bir ad belirtin. Başka değişiklik gerekmez, bu nedenle hazır olduğunuzda kodu çalıştırın.
Bu kod birden çok paketi içeri aktarır ve bu öğreticide kullanılan Azure kaynaklarına erişimi ayarlar.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-azure-ai-services-multi-service-key"
cognitive_services_region = "placeholder-azure-ai-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-admin-api-key"
search_index = "placeholder-for-new-search-index-name"
Spark'a veri yükleme
Aşağıdaki kodu ikinci hücreye yapıştırın. Değişiklik gerekmez, bu nedenle hazır olduğunuzda kodu çalıştırın.
Bu kod bir Azure depolama hesabından birkaç dış dosya yükler. Dosyalar, bir veri çerçevesinde okunan çeşitli faturalardır.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Belge zekası ekle
Aşağıdaki kodu üçüncü hücreye yapıştırın. Değişiklik gerekmez, bu nedenle hazır olduğunuzda kodu çalıştırın.
Bu kod AnalyzeInvoices transformatörünü yükler ve faturaları içeren veri çerçevesine bir referans gönderir. Faturalardan bilgi ayıklamak için Azure AI Belge Zekası'nın önceden oluşturulmuş fatura modelini çağırır.
from synapse.ml.services import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
Çıktı aşağıdaki ekran görüntüsüne benzer görünmelidir. Form analizinin yoğun yapılandırılmış bir sütuna nasıl paketlendiğine ve bu sütunla çalışmanın zor olduğuna dikkat edin. Sonraki dönüştürme, sütunu satırlara ve sütunlara ayrıştırarak bu sorunu çözer.
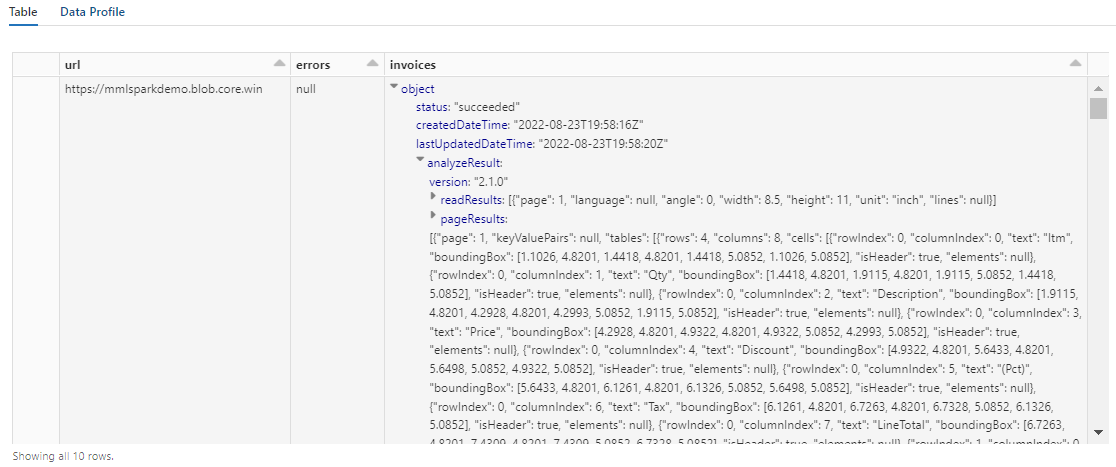
Belge yönetim bilgileri çıkışını yeniden yapılandırma
Aşağıdaki kodu dördüncü hücreye yapıştırın ve çalıştırın. Değişiklik gerekmez.
Bu kod, Belge Zekası transformatörlerinin çıkışını analiz eden ve tablosal bir veri yapısı çıkaran bir transformatör olan FormOntologyLearner'ı yükler. AnalyzeInvoices'un çıkışı dinamiktir ve içeriğinizde algılanan özelliklere göre değişir. Ayrıca transformatör çıkışı tek bir sütunda birleştirir. Çıkış dinamik olduğundan ve birleştirildiğinden, daha fazla yapı gerektiren aşağı akış dönüşümlerinde kullanmak zordur.
FormOntologyLearner, tablosal veri yapısı oluşturmak için kullanılabilecek desenleri arayarak AnalyzeInvoices transformatörünün yardımcı programını genişletir. Çıkışı birden çok sütun ve satır halinde düzenlemek, içeriği AzureSearchWriter gibi diğer dönüştürücülerde kullanılabilir hale getirir.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
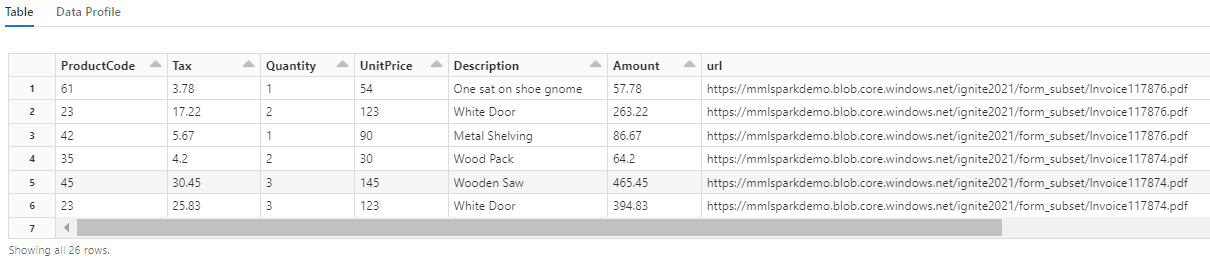
display(itemized_df)
Bu dönüşümün iç içe geçmiş alanları bir tabloya nasıl yeniden düzenlediğine ve bu sayede sonraki iki dönüşümün nasıl etkinleştiğine dikkat edin. Bu ekran görüntüsü kısa olması için kırpılmıştır. Kendi not defterinizde takip ediyorsanız 19 sütun ve 26 satırınız vardır.
Çeviri ekleme
Aşağıdaki kodu beşinci hücreye yapıştırın. Değişiklik gerekmez, bu nedenle hazır olduğunuzda kodu çalıştırın.
Bu kod, Azure AI hizmetlerinde Azure AI Translator hizmetini çağıran çeviri dönüştürücü olan Translate'i yükler. "Açıklama" sütununda İngilizce olan özgün metin, makine tarafından çeşitli dillere çevrilmiştir. Tüm çıkışlar "output.translations" dizisinde birleştirilir.
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
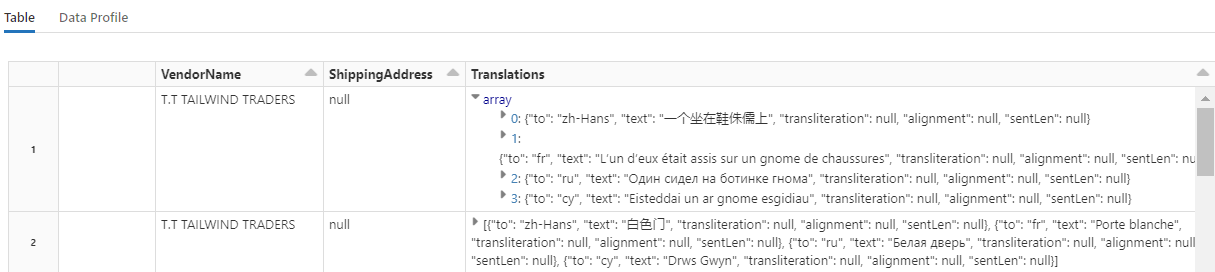
display(translated_df)
İpucu
Çevrilmiş dizeleri denetlemek için satırların sonuna kaydırın.
AzureSearchWriter ile arama dizini ekleme
Aşağıdaki kodu altıncı hücreye yapıştırın ve çalıştırın. Değişiklik gerekmez.
Bu kod AzureSearchWriter yükler. Tablosal bir veri kümesi tüketir ve her sütun için bir alan tanımlayan bir arama dizini şeması çıkartır. Çeviriler yapısı bir dizi olduğundan, her dil çevirisi için alt alanları olan karmaşık bir koleksiyon olarak dizin içinde ifade edilir. Oluşturulan dizinin bir belge anahtarı vardır ve Dizin Oluşturma REST API'sini kullanarak oluşturulan alanlar için varsayılan değerleri kullanır.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
AzureSearchWriter tarafından oluşturulan dizin tanımını keşfetmek için Azure portalındaki arama hizmeti sayfalarını denetleyin.
Not
Varsayılan arama dizinini kullanamıyorsanız, JSON'da bir dış özel tanım sağlayabilir ve URI'sini "indexJson" özelliğinde dize olarak geçirebilirsiniz. Hangi alanların belirtileceğini bilmeniz için önce varsayılan dizini oluşturun ve ardından örneğin belirli çözümleyicilere ihtiyacınız varsa özelleştirilmiş özelliklerle izleyin.
Dizini sorgulama
Aşağıdaki kodu yedinci hücreye yapıştırın ve çalıştırın. söz dizimini değiştirmek veya içeriğinizi daha fazla incelemek için daha fazla örnek denemek istemeniz dışında değişiklik gerekmez:
Sorgular veren transformatör veya modül yoktur. Bu hücre, Belge Ara REST API'sine yapılan basit bir çağrıdır.
Bu özel örnek, "door" ("search": "door") sözcüğünü aramaktır. Ayrıca eşleşen belge sayısının "sayısını" döndürür ve sonuçlar için yalnızca "Açıklama" ve "Çeviriler" alanlarının içeriğini seçer. Alanların tam listesini görmek istiyorsanız "select" parametresini kaldırın.
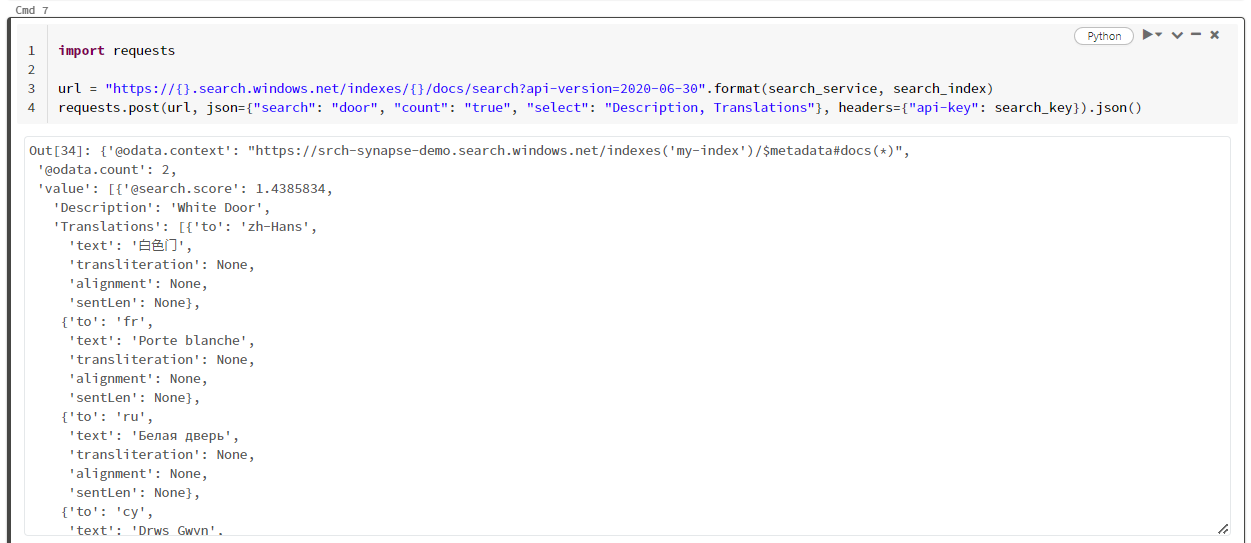
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
Aşağıdaki ekran görüntüsünde örnek betiğin hücre çıkışı gösterilmektedir.
Kaynakları temizleme
Kendi aboneliğinizde çalışırken, bir projenin sonunda artık ihtiyacınız olmayan kaynakları kaldırmak iyi bir fikirdir. Çalışır durumda bırakılan kaynaklar maliyetlerin artmasına neden olabilir. Kaynakları teker teker silebilir veya tüm kaynak grubunu silerek kaynak kümesinin tamamını kaldırabilirsiniz.
Sol gezinti bölmesindeki Tüm kaynaklar veya Kaynak grupları bağlantısını kullanarak Kaynakları Azure portalında bulabilir ve yönetebilirsiniz.
Sonraki adımlar
Bu öğreticide, Azure AI Search'te arama dizinleri oluşturmanın ve yüklemenin yeni bir yolu olan SynapseML'deki AzureSearchWriter transformatörü hakkında bilgi edindiniz. Transformatör, yapılandırılmış JSON'ı giriş olarak alır. FormOntologyLearner, SynapseML'deki Belge Zekası transformatörleri tarafından üretilen çıktı için gerekli yapıyı sağlayabilir.
Sonraki adım olarak, Azure AI Search aracılığıyla keşfetmek isteyebileceğiniz dönüştürülmüş içerik üreten diğer SynapseML öğreticilerini gözden geçirin: