Service Fabric sistem durumu izlemeye giriş
Azure Service Fabric zengin, esnek ve genişletilebilir sistem durumu değerlendirmesi ve raporlaması sağlayan bir sistem durumu modeli sunar. Model, kümenin durumunun ve içinde çalışan hizmetlerin neredeyse gerçek zamanlı izlenmesine olanak tanır. Sağlık bilgilerini kolayca edinebilir ve büyük kesintilere neden olmadan önce olası sorunları düzeltebilirsiniz. Tipik modelde, hizmetler raporları yerel görünümlerine göre gönderir ve bu bilgiler küme düzeyinde genel bir görünüm sağlamak için toplanır.
Service Fabric bileşenleri, geçerli durumlarını raporlamak için bu zengin sistem durumu modelini kullanır. Uygulamalarınızdan sistem durumunu raporlamak için aynı mekanizmayı kullanabilirsiniz. Özel koşullarınızı yakalayan yüksek kaliteli sistem durumu raporlamasına yatırım yaparsanız, çalışan uygulamanız için sorunları çok daha kolay algılayabilir ve düzeltebilirsiniz.
Not
İzlenen yükseltme gereksinimini gidermek için sistem durumu alt sistemini başlattık. Service Fabric, tam kullanılabilirlik, kapalı kalma süresi olmaması ve kullanıcı müdahalesi olmadan en düşük düzeyde olmasını sağlayan izlenen uygulama ve küme yükseltmeleri sağlar. Yükseltme, bu hedeflere ulaşmak için yapılandırılan yükseltme ilkelerine göre sistem durumunu denetler. Yükseltme yalnızca sistem durumu istenen eşiklere uyulduğunda devam edebilir. Aksi takdirde, yöneticilere sorunları çözme şansı vermek için yükseltme otomatik olarak geri alınır veya duraklatılır. Uygulama yükseltmeleri hakkında daha fazla bilgi edinmek için bu makaleye bakın.
Sistem durumu deposu
Sistem durumu deposu, kolay alma ve değerlendirme için kümedeki varlıklarla ilgili sistem durumuyla ilgili bilgileri tutar. Yüksek kullanılabilirlik ve ölçeklenebilirlik sağlamak için Service Fabric kalıcı durum bilgisi olan bir hizmet olarak uygulanır. Sistem durumu deposu fabric:/System uygulamasının bir parçasıdır ve küme çalışır durumdayken kullanılabilir.
Sistem durumu varlıkları ve hiyerarşisi
Sistem durumu varlıkları, farklı varlıklar arasındaki etkileşimleri ve bağımlılıkları yakalayan mantıksal bir hiyerarşide düzenlenir. Sistem durumu deposu, Service Fabric bileşenlerinden alınan raporlara göre sistem durumu varlıklarını ve hiyerarşisini otomatik olarak oluşturur.
Sistem durumu varlıkları Service Fabric varlıklarını yansıtır. (Örneğin, sistem durumu uygulama varlığı kümede dağıtılan bir uygulama örneğiyle eşleşirken , sistem durumu düğümü varlığı bir Service Fabric küme düğümüyle eşleşir.) Sistem durumu hiyerarşisi, sistem varlıklarının etkileşimlerini yakalar ve gelişmiş sistem durumu değerlendirmesinin temelini oluşturur. Service Fabric teknik genel bakış bölümünde önemli Service Fabric kavramları hakkında bilgi edinebilirsiniz. Uygulama hakkında daha fazla bilgi için bkz . Service Fabric uygulama modeli.
Sistem durumu varlıkları ve hiyerarşisi, kümenin ve uygulamaların etkili bir şekilde bildirilmesine, hata ayıklamasına ve izlenmesine olanak tanır. Sistem durumu modeli, kümedeki birçok hareketli parçanın sistem durumunun doğru, ayrıntılı bir gösterimini sağlar.
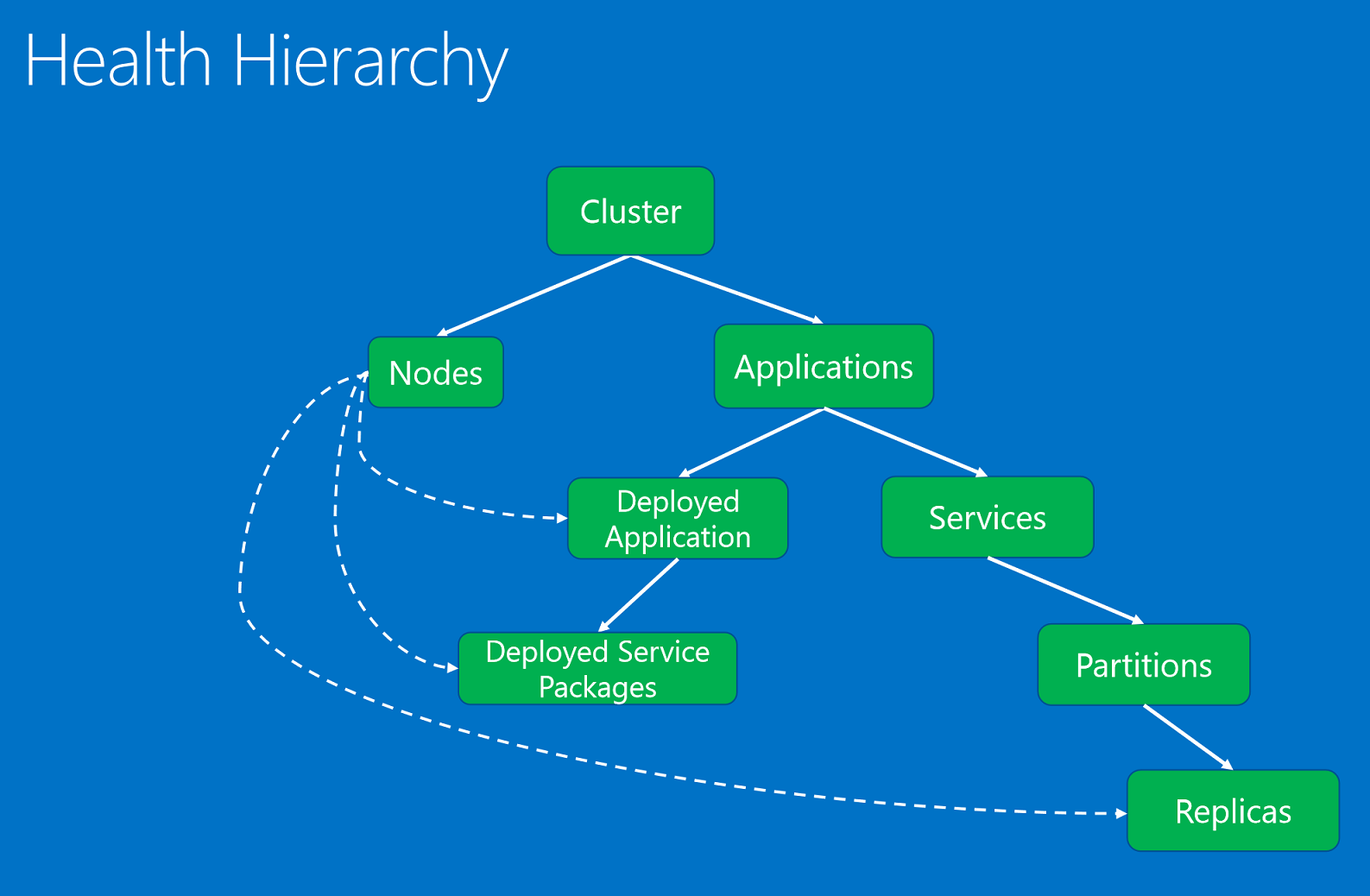 Üst-alt ilişkileri temel alan bir hiyerarşide düzenlenmiş sistem durumu varlıkları.
Üst-alt ilişkileri temel alan bir hiyerarşide düzenlenmiş sistem durumu varlıkları.
Sistem durumu varlıkları şunlardır:
- Küme. Service Fabric kümesinin durumunu temsil eder. Küme durumu raporları, kümenin tamamını etkileyen koşulları açıklar. Bu koşullar kümedeki veya kümenin kendisindeki birden çok varlığı etkiler. Bu koşula bağlı olarak, muhabir sorunu bir veya daha fazla iyi durumda olmayan çocuğa daraltamaz. Örnek olarak, ağ bölümleme veya iletişim sorunları nedeniyle kümenin beyni bölünür.
- Düğüm. Service Fabric düğümünün durumunu temsil eder. Düğüm durumu raporları, düğüm işlevselliğini etkileyen koşulları açıklar. Bunlar genellikle üzerinde çalışan tüm dağıtılan varlıkları etkiler. Örnek olarak disk alanı dışında düğüm (veya bellek, bağlantılar gibi makine genelindeki diğer özellikler) ve bir düğümün devre dışı olduğu durumlar verilebilir. Düğüm varlığı düğüm adı (dize) tarafından tanımlanır.
- Uygulama. Kümede çalışan bir uygulama örneğinin durumunu temsil eder. Uygulama durumu raporları, uygulamanın genel durumunu etkileyen koşulları açıklar. Bunlar tek tek alt öğelere (hizmetler veya dağıtılan uygulamalar) göre daraltılamaz. Örnek olarak uygulamadaki farklı hizmetler arasındaki uçtan uca etkileşim verilebilir. Uygulama varlığı, uygulama adı (URI) ile tanımlanır.
- Hizmet. Kümede çalışan bir hizmetin durumunu temsil eder. Hizmet durumu raporları, hizmetin genel durumunu etkileyen koşulları açıklar. Muhabir sorunu iyi durumda olmayan bir bölüme veya çoğaltmaya daraltamaz. Örnek olarak tüm bölümlerde sorunlara neden olan bir hizmet yapılandırması (bağlantı noktası veya dış dosya paylaşımı gibi) verilebilir. Hizmet varlığı hizmet adı (URI) ile tanımlanır.
- Bölüm. Hizmet bölümünün durumunu temsil eder. Bölüm durumu raporları, çoğaltma kümesinin tamamını etkileyen koşulları açıklar. Örnek olarak çoğaltma sayısının hedef sayının altında olması ve bir bölümün çekirdek kaybına neden olması verilebilir. Bölüm varlığı, bölüm kimliği (GUID) tarafından tanımlanır.
- Çoğaltma. Durum bilgisi olan bir hizmet çoğaltmasının veya durum bilgisi olmayan bir hizmet örneğinin durumunu temsil eder. Çoğaltma, watchdogs ve sistem bileşenlerinin bir uygulama için bildirebileceği en küçük birimdir. Durum bilgisi olan hizmetlere örnek olarak, işlemleri ikincillere çoğaltabilen birincil çoğaltma ve yavaş çoğaltma verilebilir. Ayrıca durum bilgisi olmayan bir örnek, kaynakları tükendiğinde veya bağlantı sorunları olduğunda rapor verebilir. Çoğaltma varlığı, bölüm kimliği (GUID) ve çoğaltma veya örnek kimliği (uzun) ile tanımlanır.
- DeployedApplication. Düğümde çalışan bir uygulamanın durumunu temsil eder. Dağıtılan uygulama durumu raporları, düğümdeki uygulamaya özgü, aynı düğümde dağıtılan hizmet paketlerine daraltılmayan koşulları açıklar. Örnek olarak uygulama paketinin bu düğüme indirilememe hataları ve düğümde uygulama güvenlik sorumlularını ayarlama sorunları verilebilir. Dağıtılan uygulama, uygulama adı (URI) ve düğüm adı (dize) ile tanımlanır.
- DeployedServicePackage. Kümedeki bir düğümde çalışan bir hizmet paketinin durumunu temsil eder. Aynı uygulama için aynı düğümdeki diğer hizmet paketlerini etkilemeyen bir hizmet paketine özgü koşulları açıklar. Örnek olarak hizmet paketinde başlatılamayan bir kod paketi ve okunamayan bir yapılandırma paketi verilebilir. Dağıtılan hizmet paketi uygulama adı (URI), düğüm adı (dize), hizmet bildirim adı (dize) ve hizmet paketi etkinleştirme kimliği (dize) ile tanımlanır.
Sistem durumu modelinin ayrıntı düzeyi, sorunları algılamayı ve düzeltmeyi kolaylaştırır. Örneğin, bir hizmet yanıt vermiyorsa, uygulama örneğinin iyi durumda olmadığını bildirmek mümkündür. Ancak bu düzeyde raporlama ideal değildir, çünkü sorun söz konusu uygulama içindeki tüm hizmetleri etkilemiyor olabilir. Daha fazla bilgi bu bölüme işaret ederse rapor iyi durumda olmayan hizmete veya belirli bir alt bölüme uygulanmalıdır. Veriler hiyerarşi aracılığıyla otomatik olarak ortaya çıkar ve hizmet ve uygulama düzeylerinde iyi durumda olmayan bir bölüm görünür hale getirilir. Bu toplama, sorunun kök nedeninin daha hızlı bir şekilde tespit edilmesine ve çözülmesine yardımcı olur.
Sistem durumu hiyerarşisi üst-alt ilişkilerden oluşur. Küme düğümlerden ve uygulamalardan oluşur. Uygulamaların hizmetleri ve dağıtılan uygulamaları vardır. Dağıtılan uygulamalar hizmet paketlerini dağıttı. Hizmetlerin bölümleri vardır ve her bölümün bir veya daha fazla çoğaltması vardır. Düğümler ve dağıtılan varlıklar arasında özel bir ilişki vardır. Yetkili sistem bileşeni olan Yük Devretme Yöneticisi hizmeti tarafından bildirilen iyi durumda olmayan bir düğüm, dağıtılan uygulamaları, hizmet paketlerini ve üzerinde dağıtılan çoğaltmaları etkiler.
Sistem durumu hiyerarşisi, neredeyse gerçek zamanlı bilgiler olan en son sistem durumu raporlarını temel alarak sistemin en son durumunu temsil eder. İç ve dış watchdogs, uygulamaya özgü mantık veya özel izlenen koşullara göre aynı varlıklar üzerinde rapor verebilir. Kullanıcı raporları sistem raporlarıyla birlikte bulunur.
Büyük bir bulut hizmetinin tasarımı sırasında sistem durumunu raporlamaya ve yanıtlamaya yatırım yapmayı planlayın. Bu ön yatırım, hizmetin hata ayıklamasını, izlemesini ve çalıştırmasını kolaylaştırır.
Sistem durumu durumları
Service Fabric, bir varlığın iyi durumda olup olmadığını açıklamak için üç sistem durumu durumu kullanır: Tamam, uyarı ve hata. Sistem durumu deposuna gönderilen tüm raporlar bu durumlardan birini belirtmelidir. Sistem durumu değerlendirme sonucu bu durumlardan biridir.
Olası sağlık durumları şunlardır:
- Tamam'ı seçin. Varlık iyi durumda. Bu dosyada veya alt öğelerinde bilinen bir sorun bildirilmemiştir (uygun olduğunda).
- Uyarı. Varlığın bazı sorunları vardır, ancak yine de düzgün çalışabiliyor. Örneğin, gecikmeler vardır, ancak henüz herhangi bir işlevsel soruna neden olmaz. Bazı durumlarda, uyarı koşulu dış müdahale olmadan kendini düzeltebilir. Bu gibi durumlarda sağlık raporları farkındalığı artırarak olup bitenler hakkında görünürlük sağlar. Diğer durumlarda, uyarı koşulu kullanıcı müdahalesi olmadan ciddi bir soruna düşebilir.
- Hata. Varlık iyi durumda değil. Varlığın durumunu düzeltmek için eylem yapılmalıdır, çünkü düzgün çalışamaz.
- Bilinmiyor. Varlık sistem durumu deposunda yok. Bu sonuç, birden çok bileşenden sonuçları birleştirilen dağıtılmış sorgulardan alınabilir. Örneğin, düğüm listesi alma sorgusu FailoverManager, ClusterManager ve HealthManager'a gider; uygulama listesi alma sorgusu ClusterManager ve HealthManager'a gider. Bu sorgular birden çok sistem bileşeninden gelen sonuçları birleştirir. Başka bir sistem bileşeni sistem durumu deposunda bulunmayan bir varlık döndürürse, birleştirilen sonucun sistem durumu bilinmiyor olur. Sistem durumu raporları henüz işlenmediğinden veya varlık silindikten sonra temizlendiğinden varlık depoda değil.
Sistem durumu ilkeleri
Sistem durumu deposu, bir varlığın raporlarına ve alt öğelerine göre iyi durumda olup olmadığını belirlemek için sistem durumu ilkeleri uygular.
Not
Sistem durumu ilkeleri küme bildiriminde (küme ve düğüm sistem durumu değerlendirmesi için) veya uygulama bildiriminde (uygulama değerlendirmesi ve alt öğeleri için) belirtilebilir. Sistem durumu değerlendirme istekleri, yalnızca bu değerlendirme için kullanılan özel sistem durumu değerlendirme ilkelerini de geçirebilir.
Varsayılan olarak, Service Fabric üst-alt hiyerarşik ilişki için katı kurallar uygular (her şey iyi durumda olmalıdır). Çocuklardan birinin bile iyi durumda olmayan bir olayı varsa, ebeveyn iyi durumda değil olarak kabul edilir.
Küme sistem durumu ilkesi
Küme sistem durumu ilkesi , küme sistem durumu ve düğüm sistem durumu durumlarını değerlendirmek için kullanılır. İlke, küme bildiriminde tanımlanabilir. Yoksa, varsayılan ilke (sıfır toleranslı hata) kullanılır.
Küme sistem durumu ilkesi aşağıdakileri içerir:
WarningAsError'ı göz önünde bulundurun. Sistem durumu değerlendirmesi sırasında uyarı sistem durumu raporlarının hata olarak ele alınıp alınmayacağını belirtir. Varsayılan: false.
MaxPercentUnhealthyApplications. Küme hata olarak kabul edilmeden önce iyi durumda olmayan uygulamaların en yüksek tolere edilen yüzdesini belirtir.
MaxPercentUnhealthyNodes. Küme hata olarak değerlendirilmeden önce iyi durumda olmayan düğümlerin en yüksek tolere edilen yüzdesini belirtir. Büyük kümelerde, bazı düğümler onarım için her zaman devre dışıdır, bu nedenle bu yüzde bunu tolere etmek üzere yapılandırılmalıdır.
ApplicationTypeHealthPolicyMap. Uygulama türü sistem durumu ilkesi eşlemesi, özel uygulama türlerini açıklamak için küme durumu değerlendirmesi sırasında kullanılabilir. Varsayılan olarak, tüm uygulamalar bir havuza konur ve MaxPercentUnhealthyApplications ile değerlendirilir. Bazı uygulama türleri farklı şekilde ele alınmalıdır, bunlar genel havuzdan alınabilir. Bunun yerine, bunlar eşlemedeki uygulama türü adıyla ilişkili yüzdelere göre değerlendirilir. Örneğin, bir kümede farklı türlerde binlerce uygulama ve özel bir uygulama türünün birkaç denetim uygulaması örneği vardır. Denetim uygulamaları hiçbir zaman hataya neden olmamalıdır. Bazı hataları tolere etmek için genel MaxPercentUnhealthyApplications değerini %20 olarak belirtebilirsiniz, ancak "ControlApplicationType" uygulama türü için MaxPercentUnhealthyApplications değerini 0 olarak ayarlayın. Bu şekilde, birçok uygulamadan bazıları iyi durumda değilse ancak genel iyi durumda olmayan yüzdenin altındaysa küme Uyarı olarak değerlendirilir. Uyarı sistem durumu, küme yükseltmesini veya Hata durumu tarafından tetiklenen diğer izlemeleri etkilemez. Ancak hata durumundaki bir denetim uygulaması bile, yükseltme yapılandırmasına bağlı olarak geri almayı tetikleyen veya küme yükseltmesini duraklatan kümenin iyi durumda olmamasına neden olur. Haritada tanımlanan uygulama türleri için tüm uygulama örnekleri genel uygulama havuzundan çıkarılır. Bunlar, haritadaki belirli MaxPercentUnhealthyApplications kullanılarak uygulama türünün toplam uygulama sayısına göre değerlendirilir. Diğer tüm uygulamalar genel havuzda kalır ve MaxPercentUnhealthyApplications ile değerlendirilir.
Aşağıdaki örnek, küme bildiriminden bir alıntıdır. Uygulama türü eşlemesinde girdileri tanımlamak için, parametre adına "ApplicationTypeMaxPercentUnhealthyApplications-" ön ekini ve ardından uygulama türü adını ekleyin.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. Düğüm türü sistem durumu ilkesi eşlemesi, özel düğüm türlerini açıklamak için küme durumu değerlendirmesi sırasında kullanılabilir. Düğüm türleri, eşlemedeki düğüm türü adıyla ilişkili yüzdelere göre değerlendirilir. Bu değerin ayarlanması, için kullanılan düğümlerin genel havuzu üzerindeMaxPercentUnhealthyNodeshiçbir etkiye sahip değildir. Örneğin, bir kümenin farklı türlerde yüzlerce düğümü ve önemli işleri barındıran birkaç düğüm türü vardır. Bu türdeki hiçbir düğüm devre dışı olmamalıdır. Tüm düğümlerde bazı hataları tolere etmek için genelMaxPercentUnhealthyNodesdeğerini %20 olarak belirtebilirsiniz, ancak düğüm türüSpecialNodeTypeiçin değerini 0 olarak ayarlayınMaxPercentUnhealthyNodes. Bu şekilde, birçok düğümden bazıları iyi durumda değilse ancak genel iyi durumda olmayan yüzdenin altındaysa, küme Uyarı sistem durumu durumunda olarak değerlendirilir. Uyarı sistem durumu, küme yükseltmesini veya Hata durumu tarafından tetiklenen diğer izlemeyi etkilemez. Ancak Hata durumu durumundaki türdekiSpecialNodeTypebir düğüm bile kümeyi iyi durumda yapmaz ve yükseltme yapılandırmasına bağlı olarak geri almayı tetikler veya küme yükseltmesini duraklatır. Buna karşılık, genelMaxPercentUnhealthyNodeskısıtlamanın 0 olarak ayarlanması ve iyi durumda olmayan düğümlerin en yüksek yüzde değerinin hata durumundakiSpecialNodeTypebir düğümle 100 olarak ayarlanmasıSpecialNodeTypekümeyi yine de hata durumuna sokacak çünkü bu durumda genel kısıtlama daha katıdır.Aşağıdaki örnek, küme bildiriminden bir alıntıdır. Düğüm türü eşlemesinde girdileri tanımlamak için parametre adına "NodeTypeMaxPercentUnhealthyNodes-" ön ekini ve ardından düğüm türü adını ekleyin.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Uygulama durumu ilkesi
Uygulama durumu ilkesi, olaylar ve alt durum toplama işlemlerinin uygulamalar ve alt öğeleri için nasıl yapıldığını açıklar. Uygulama paketindeki uygulama bildiriminde ApplicationManifest.xml tanımlanabilir. İlke belirtilmezse Service Fabric, bir sistem durumu raporu veya uyarı veya hata sistem durumu durumunda bir alt öğe varsa varlığın iyi durumda olmadığını varsayar. Yapılandırılabilir ilkeler şunlardır:
- WarningAsError'ı göz önünde bulundurun. Sistem durumu değerlendirmesi sırasında uyarı sistem durumu raporlarının hata olarak ele alınıp alınmayacağını belirtir. Varsayılan: false.
- MaxPercentUnhealthyDeployedApplications. Uygulama hata olarak değerlendirilmeden önce iyi durumda olmayan dağıtılan uygulamaların en yüksek tolere edilen yüzdesini belirtir. Bu yüzde, iyi durumda olmayan dağıtılan uygulamaların sayısı, uygulamaların o anda kümede dağıtılan düğüm sayısına bölünerek hesaplanır. Hesaplama, az sayıda düğümde bir hatayı tolere etmek için yukarı yuvarlar. Varsayılan yüzde: sıfır.
- DefaultServiceTypeHealthPolicy. Uygulamadaki tüm hizmet türleri için varsayılan sistem durumu ilkesinin yerini alan varsayılan hizmet türü sistem durumu ilkesini belirtir.
- ServiceTypeHealthPolicyMap. Hizmet türü başına hizmet durumu ilkelerinin bir haritasını sağlar. Bu ilkeler, belirtilen her hizmet türü için varsayılan hizmet türü sistem durumu ilkelerinin yerini alır. Örneğin, bir uygulama durum bilgisi olmayan bir ağ geçidi hizmet türüne ve durum bilgisi olan bir altyapı hizmet türüne sahipse, durum ilkelerini değerlendirmeleri için farklı şekilde yapılandırabilirsiniz. Hizmet türü başına ilke belirttiğinizde, hizmetin sistem durumu hakkında daha ayrıntılı denetim elde edebilirsiniz.
Hizmet türü sistem durumu ilkesi
Hizmet türü sistem durumu ilkesi, hizmetlerin ve hizmetlerin alt öğelerinin nasıl değerlendirilip toplanıp top yapılacağını belirtir. İlke aşağıdakileri içerir:
- MaxPercentUnhealthyPartitionsPerService. Bir hizmet iyi durumda değil olarak kabul edilmeden önce iyi durumda olmayan bölümlerin en yüksek tolere edilen yüzdesini belirtir. Varsayılan yüzde: sıfır.
- MaxPercentUnhealthyReplicasPerPartition. Bir bölüm iyi durumda değil olarak kabul edilmeden önce iyi durumda olmayan çoğaltmaların en yüksek tolere edilen yüzdesini belirtir. Varsayılan yüzde: sıfır.
- MaxPercentUnhealthyServices. Uygulama iyi durumda değil olarak kabul edilmeden önce iyi durumda olmayan hizmetlerin tolere edilen en yüksek yüzdesini belirtir. Varsayılan yüzde: sıfır.
Aşağıdaki örnek, uygulama bildiriminden bir alıntıdır:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Sistem durumu değerlendirmesi
Kullanıcılar ve otomatik hizmetler istedikleri zaman herhangi bir varlık için sistem durumunu değerlendirebilir. Bir varlığın durumunu değerlendirmek için, sistem durumu deposu varlık üzerindeki tüm sistem durumu raporlarını toplar ve tüm alt öğelerini (uygun olduğunda) değerlendirir. Sistem durumu toplama algoritması, sistem durumu raporlarının nasıl değerlendirileceğini ve alt sistem durumu durumlarının nasıl toplandığını (uygun olduğunda) belirten sistem durumu ilkelerini kullanır.
Sistem durumu raporu toplama
Bir varlık, farklı özelliklerde farklı muhabirler (sistem bileşenleri veya watchdogs) tarafından gönderilen birden çok sistem durumu raporuna sahip olabilir. Toplama, özellikle uygulama veya küme sistem durumu ilkesinin ConsiderWarningAsError üyesi olan ilişkili sistem durumu ilkelerini kullanır. ConsiderWarningAsError, uyarıların nasıl değerlendirileceklerini belirtir.
Toplanan sistem durumu, varlık üzerindeki en kötü sistem durumu raporları tarafından tetiklenir. En az bir hata durumu raporu varsa, toplanan sistem durumu bir hatadır.
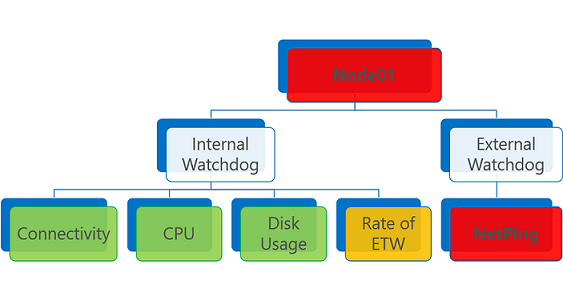
Bir veya daha fazla hata durumu raporu olan bir sistem durumu varlığı Hata olarak değerlendirilir. Sistem durumu ne olursa olsun süresi dolmuş bir sistem durumu raporu için de aynı durum geçerlidir.
Hata raporu ve bir veya daha fazla uyarı yoksa, Toplu sistem durumu, ConsiderWarningAsError ilke bayrağına bağlı olarak uyarı veya hatadır.
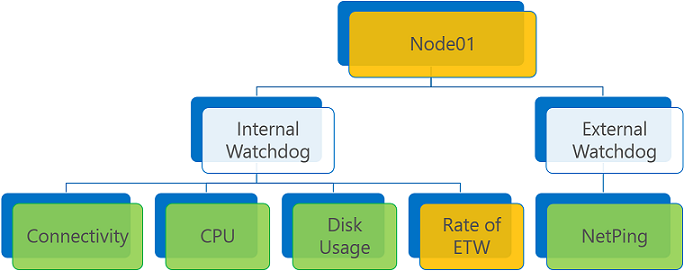
Uyarı raporu ve ConsiderWarningAsError değeri false (varsayılan) olarak ayarlanmış sistem durumu raporu toplaması.
Çocuk sistem durumu toplama
Bir varlığın toplu sistem durumu alt sistem durumu durumlarını yansıtır (uygun olduğunda). Alt sistem durumu durumlarını toplama algoritması, varlık türüne göre geçerli olan sistem durumu ilkelerini kullanır.
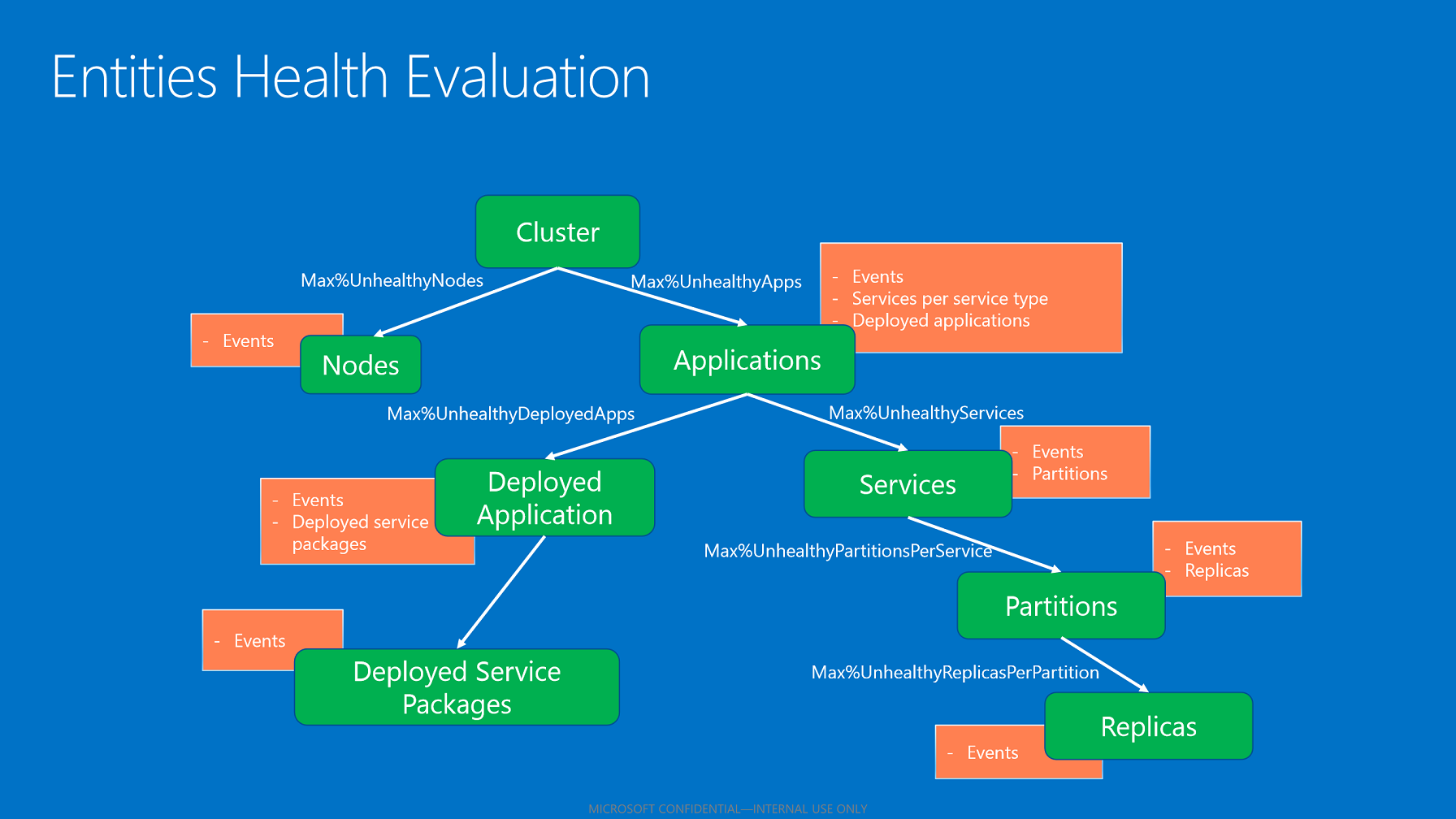
Sistem durumu ilkelerine göre alt toplama.
Sağlık deposu tüm çocukları değerlendirdikten sonra, sağlık durumu iyi durumda olmayan çocukların yapılandırılan en yüksek yüzdesine göre sağlık durumlarını toplar. Bu yüzde, varlık ve alt tür temelinde ilkeden alınır.
- Tüm alt öğelerde Tamam durumları varsa, çocuğun toplanmış sistem durumu Tamam'dır.
- Çocukların hem Tamam hem de uyarı durumları varsa, alt kümelenmiş sistem durumu uyarıdır.
- İyi durumda olmayan çocukların izin verilen en yüksek yüzdesine uymayan hata durumlarına sahip alt öğeler varsa, toplanmış üst sistem durumu bir hatadır.
- Hata durumlarına sahip çocuklar, iyi durumda olmayan çocukların izin verilen en yüksek yüzdesine uyarsa, toplanmış üst sistem durumu uyarıdır.
Sistem durumu raporlama
Sistem bileşenleri, System Fabric uygulamaları ve iç/dış watchdogs, Service Fabric varlıklarına karşı rapor verebilir. Muhabirler , izledikleri koşullara göre izlenen varlıkların durumuyla ilgili yerel belirlemeler yapıyor. Herhangi bir genel duruma veya toplama verilerine bakmaları gerekmez. İstenen davranış, basit muhabirlere sahip olmaktır ve hangi bilgilerin gönderileceğini çıkarsamak için birçok şeye bakması gereken karmaşık organizmalara sahip olmak değildir.
Sistem durumu verilerini sistem durumu deposuna göndermek için, bir muhabirin etkilenen varlığı tanımlaması ve bir sistem durumu raporu oluşturması gerekir. Raporu göndermek için FabricClient.HealthClient.ReportHealth API'sini, veya nesnelerinde, PowerShell cmdlet'lerinde veya CodePackageActivationContext REST'te Partition kullanıma sunulan rapor durumu API'lerini kullanın.
Sistem durumu raporları
Kümedeki varlıkların her biri için sistem durumu raporları aşağıdaki bilgileri içerir:
SourceId. Sistem durumu olayının muhabirini benzersiz olarak tanımlayan bir dize.
Varlık tanımlayıcısı. Raporun uygulandığı varlığı tanımlar. Varlık türüne göre farklılık gösterir:
- Küme. Yok.
- Düğüm. Düğüm adı (dize).
- Uygulama. Uygulama adı (URI). Kümede dağıtılan uygulama örneğinin adını temsil eder.
- Hizmet. Hizmet adı (URI). Kümede dağıtılan hizmet örneğinin adını temsil eder.
- Bölüm. Bölüm Kimliği (GUID). Bölüm benzersiz tanımlayıcısını temsil eder.
- Çoğaltma. Durum bilgisi olan hizmet çoğaltma kimliği veya durum bilgisi olmayan hizmet örneği kimliği (INT64).
- DeployedApplication. Uygulama adı (URI) ve düğüm adı (dize).
- DeployedServicePackage. Uygulama adı (URI), düğüm adı (dize) ve hizmet bildirimi adı (dize).
Özelliği. Muhabirin varlığın belirli bir özelliği için sistem durumu olayını kategorilere ayırmasına olanak tanıyan bir dize (sabit bir numaralandırma değil). Örneğin, A muhabiri Node01 "Depolama" özelliğinin durumunu, B muhabiri ise Node01 "Bağlantı" özelliğinin durumunu bildirebilir. Sistem durumu deposunda, bu raporlar Node01 varlığı için ayrı sistem durumu olayları olarak değerlendirilir.
Açıklama. Bir muhabirin sistem durumu olayı hakkında ayrıntılı bilgi sağlamasına olanak tanıyan dize. SourceId, Property ve HealthState raporu tam olarak açıklamalıdır. Açıklama, rapor hakkında insan tarafından okunabilen bilgiler ekler. Bu metin, yöneticilerin ve kullanıcıların sistem durumu raporunu anlamasını kolaylaştırır.
HealthState. Raporun sistem durumunu açıklayan bir numaralandırma. Kabul edilen değerler Tamam, Uyarı ve Hata'dır.
TimeToLive. Sistem durumu raporunun ne kadar süre geçerli olduğunu gösteren zaman aralığı. RemoveWhenExpired ile birlikte, sistem durumu deposunun süresi dolan olayları nasıl değerlendireceğini bilmesini sağlar. Varsayılan olarak değer sonsuzdur ve rapor sonsuza kadar geçerlidir.
RemoveWhenExpired. Bir boole. True olarak ayarlanırsa, süresi dolan sistem durumu raporu sistem durumu deposundan otomatik olarak kaldırılır ve rapor varlık sistem durumu değerlendirmesini etkilemez. Rapor yalnızca belirli bir süre için geçerli olduğunda ve muhabirin açıkça temizlemesi gerekmeyen durumlarda kullanılır. Ayrıca, sistem durumu deposundan raporları silmek için de kullanılır (örneğin, bir watchdog değiştirilir ve önceki kaynak ve özellik ile rapor göndermeyi durdurur). Sistem durumu deposundan önceki durumları temizlemek için RemoveWhenExpired ile birlikte kısa bir TimeToLive içeren bir rapor gönderebilir. Değer false olarak ayarlanırsa, süresi dolan rapor sistem durumu değerlendirmesinde hata olarak değerlendirilir. False değeri, sistem durumu deposuna kaynağın bu özellik üzerinde düzenli aralıklarla rapor vermesi gerektiğini bildirir. Aksi takdirde, watchdog'da bir sorun olmalı. Olayı hata olarak değerlendirerek watchdog'un durumu yakalanır.
SequenceNumber. Sürekli artması gereken pozitif bir tamsayı, raporların sırasını temsil eder. Sistem durumu deposu tarafından, ağ gecikmeleri veya diğer sorunlar nedeniyle geç alınan eski raporları algılamak için kullanılır. Sıra numarası aynı varlık, kaynak ve özellik için en son uygulanan sayıdan küçük veya buna eşitse rapor reddedilir. Belirtilmezse, sıra numarası otomatik olarak oluşturulur. Sıra numarasını yalnızca durum geçişlerini bildirirken koymak gerekir. Bu durumda, kaynağın hangi raporları gönderdiğini hatırlaması ve yük devretme sırasında kurtarma bilgilerini tutması gerekir.
Bu dört bilgi parçası (SourceId, varlık tanımlayıcısı, Özellik ve HealthState) her sistem durumu raporu için gereklidir. SourceId dizesinin sistem raporları için ayrılmış "System." ön eki ile başlamasına izin verilmez. Aynı varlık için, aynı kaynak ve özellik için yalnızca bir rapor vardır. Aynı kaynak ve özellik için birden çok rapor, sistem durumu istemci tarafında (topluysa) veya sistem durumu deposu tarafında birbirini geçersiz kılar. Değiştirme, sıra numaralarını temel alır; daha yeni raporlar (daha yüksek sıralı sayılarla) eski raporların yerini alır.
Sistem durumu olayları
Sistem durumu deposu, raporlardaki tüm bilgileri ve ek meta verileri içeren sistem durumu olaylarını dahili olarak tutar. Meta veriler, raporun sistem durumu istemcisine verildiği saati ve sunucu tarafında değiştirildiği zamanı içerir. Sistem durumu olayları sistem durumu sorguları tarafından döndürülür.
Eklenen meta veriler aşağıdakileri içerir:
- SourceUtcTimestamp. Raporun sistem durumu istemcisine verildiği zaman (Eşgüdümlü Evrensel Saat).
- LastModifiedUtcTimestamp. Raporun sunucu tarafında en son değiştirildiği saat (Eşgüdümlü Evrensel Saat).
- IsExpired. Sorgu sistem durumu deposu tarafından yürütülürken raporun süresinin dolup dolmadığını belirten bir bayrak. Bir olayın süresi yalnızca RemoveWhenExpired false olduğunda sona erebilir. Aksi takdirde, olay sorgu tarafından döndürülür ve depodan kaldırılır.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. Tamam/uyarı/hata geçişleri için son kez. Bu alanlar, olayın sistem durumu geçişlerinin geçmişini verir.
Durum geçiş alanları daha akıllı uyarılar veya "geçmiş" sistem durumu olay bilgileri için kullanılabilir. Bunlar şunlar gibi senaryoları etkinleştirir:
- Bir özellik X dakikadan uzun süredir uyarı/hata durumunda olduğunda uyarır. Koşulun belirli bir süre denetlenmesi, geçici koşullarla ilgili uyarıları önler. Örneğin, sistem durumu beş dakikadan uzun süredir uyarıysa bir uyarıya çevrilebilir (HealthState == Uyarı ve Şimdi - LastWarningTransitionTime > 5 dakika).
- Yalnızca son X dakika içinde değişen koşullarda uyarır. Bir rapor belirtilen süreden önce zaten hata durumundaysa, önceden işaretlendiği için yoksayılabilir.
- Bir özellik uyarı ve hata arasında geçişiyorsa, ne kadar süredir iyi durumda olmadığını (tamam değil) belirleyin. Örneğin, özelliğin beş dakikadan uzun süredir iyi durumda olmadığı bir uyarıya çevrilebilir (HealthState != Tamam ve Şimdi - LastOkTransitionTime > 5 dakika).
Örnek: Uygulama durumunu raporlama ve değerlendirme
Aşağıdaki örnek, myWatchdog kaynağından application fabric:/WordCount üzerindeki PowerShell aracılığıyla bir sistem durumu raporu gönderir. Sistem durumu raporu, sonsuz TimeToLive ile bir hata durumu durumundaki "kullanılabilirlik" sistem durumu özelliği hakkında bilgi içerir. Ardından, sistem durumu olayları listesinde toplu sistem durumu hataları ve bildirilen sistem durumu olaylarını döndüren uygulama durumunu sorgular.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Sistem durumu modeli kullanımı
İzleme ve sistem durumu belirlemeleri küme içindeki farklı izleyiciler arasında dağıtıldığından sistem durumu modeli bulut hizmetlerinin ve temel alınan Service Fabric platformunun ölçeklendirilmesine olanak tanır. Diğer sistemler, hizmetler tarafından yayılan tüm yararlı olabilecek bilgileri ayrıştıran küme düzeyinde tek ve merkezi bir hizmete sahiptir. Bu yaklaşım ölçeklenebilirliklerini engeller. Ayrıca, sorunları ve olası sorunları mümkün olduğunca kök nedene yakın bir şekilde tanımlamaya yardımcı olmak için belirli bilgileri toplamalarına da izin vermez.
Sistem durumu modeli, izleme ve tanılama, küme ve uygulama durumunu değerlendirmek ve izlenen yükseltmeler için yoğun olarak kullanılır. Diğer hizmetler otomatik onarımlar yapmak, küme sistem durumu geçmişi oluşturmak ve belirli koşullarda uyarılar vermek için sistem durumu verilerini kullanır.
Sonraki adımlar
Service Fabric sistem durumu raporlarını görüntüleme
Sorun giderme için sistem durumu raporlarını kullanma
Hizmet durumunu bildirme ve denetleme
Özel Service Fabric sistem durumu raporları ekleme