Stream Analytics akış birimlerini anlama ve ayarlama
Akış birimini ve akış düğümünü anlama
Akış Birimleri (SU) bir Stream Analytics işini yürütmek için ayrılan bilgi işlem kaynaklarını temsil eder. SU sayısı ne kadar büyük olursa işe ayrılan CPU ve bellek kaynakları o kadar fazla olur. Bu kapasite sorgu mantığına odaklanmanızı sağlar ve Stream Analytics işinizi zamanında çalıştırmak için donanımı yönetme gereksinimini soyutlar.
Azure Stream Analytics iki akış birimi yapısını destekler: SU V1 (kullanım dışı bırakılacak) ve SU V2 (önerilen).
SU V1 modeli, ASA'nın her 6 SU'nun bir iş için tek bir akış düğümüne karşılık geldiği özgün teklifidir. İşler 1 ve 3 SU ile de çalışabilir ve bunlar kesirli akış düğümlerine karşılık gelir. Ölçeklendirme, dağıtılmış bilgi işlem kaynakları sağlayan daha fazla akış düğümü ekleyerek 6'nın üzerinde 6 SU işi ile 12, 18, 24 ve üzeri artışlarla gerçekleşir.
SU V2 modeli (önerilen), aynı işlem kaynakları için uygun fiyatlandırmaya sahip basitleştirilmiş bir yapıdır. SU V2 modelinde 1 SU V2, işiniz için bir akış düğümüne karşılık gelir. 2 SU V2, 2, 3 ile 3 arasında vb.'ye karşılık gelir. 1/3 ve 2/3 SU V2'leri olan işler, bir akış düğümüyle ancak bilgi işlem kaynaklarının bir bölümüyle de kullanılabilir. 3/1 ve 2/3 SU V2 işleri, daha küçük ölçekli iş yükleri için uygun maliyetli bir seçenek sağlar.
V1 ve V2 akış birimleri için temel alınan işlem gücü aşağıdaki gibidir:
SU fiyatlandırması hakkında bilgi için Azure Stream Analytics Fiyatlandırma Sayfası'nı ziyaret edin.
Akış birimi dönüştürmelerini ve bunların nereye uygulanacağını anlama
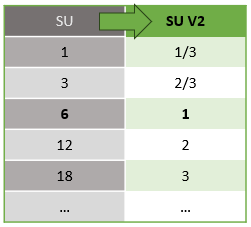
REST API katmanından kullanıcı arabirimine (Azure Portal ve Visual Studio Code) gerçekleşen Akış Birimlerinin otomatik olarak dönüştürülmesi vardır. Bu dönüştürmeyi Etkinlik günlüğünde ve SU değerlerinin kullanıcı arabirimindeki değerlerden farklı göründüğünde göreceksiniz. Bunun nedeni tasarım gereğidir ve BUNUN nedeni REST API alanlarının tamsayı değerleriyle sınırlı olması ve ASA işlerinin kesirli düğümleri (1/3 ve 2/3 Akış Birimleri) desteklemesidir. ASA'nın kullanıcı arabirimi düğüm değerlerini 1/3, 2/3, 1, 2, 3, ... vb. arka uç (etkinlik günlükleri, REST API katmanı) sırasıyla 10 ile çarpılan değerleri 3, 7, 10, 20, 30 olarak görüntüler.
| Standart | Standart V2 (UI) | Standart V2 (Günlükler, Rest API gibi arka uç) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Bu sayede aynı ayrıntı düzeyini iletebilir ve V2 SKU'ları için API katmanındaki ondalık ayırıcıyı ortadan kaldırmış oluruz. Bu dönüştürme otomatiktir ve işinizin performansını etkilemez.
Tüketimi ve bellek kullanımını anlama
Düşük gecikme süreli akış işlemeyi başarabilmek için, Azure Stream Analytics işleri tüm işlemi bellekte gerçekleştirir. Bellek yetersiz olduğunda akış işi başarısız olur. Sonuç olarak, bir üretim işi için akış işinin kaynak kullanımını izlemek ve işlerin 7/24 çalışmasını sağlamak için yeterli kaynağın ayrıldığından emin olmak önemlidir.
%0 ile %100 arasında değişen SU % kullanım ölçümü, iş yükünüzün bellek tüketimini açıklar. Minimum ayak izi olan bir akış işi için bu ölçüm genellikle %10 ile %20 arasındadır. SU kullanımı %80'in üzerindeyse veya giriş olayları geri yerleştiriliyorsa (CPU kullanımını göstermediğinden düşük SU kullanımıyla bile), iş yükünüz büyük olasılıkla daha fazla işlem kaynağı gerektirir ve bu da akış birimi sayısını artırmanızı gerektirir. Ara sıra ani artışları hesaba katmak için SU ölçümünü %80'in altında tutmak en iyisidir. Artan iş yüklerine tepki vermek ve akış birimlerini artırmak için SU Kullanımı ölçümünde %80 uyarısını ayarlamayı göz önünde bulundurun. Ayrıca, bir etki olup olmadığını görmek için filigran gecikmesi ve gerilogged olay ölçümlerini de kullanabilirsiniz.
Stream Analytics akış birimlerini (SU) yapılandırma
Azure portalda oturum açın.
Kaynak listesinde, ölçeklendirmek istediğiniz Stream Analytics işini bulun ve açın.
İş sayfasındaki Yapılandır başlığının altında Ölçek'i seçin. İş oluşturulurken varsayılan SU sayısı 1'dir.
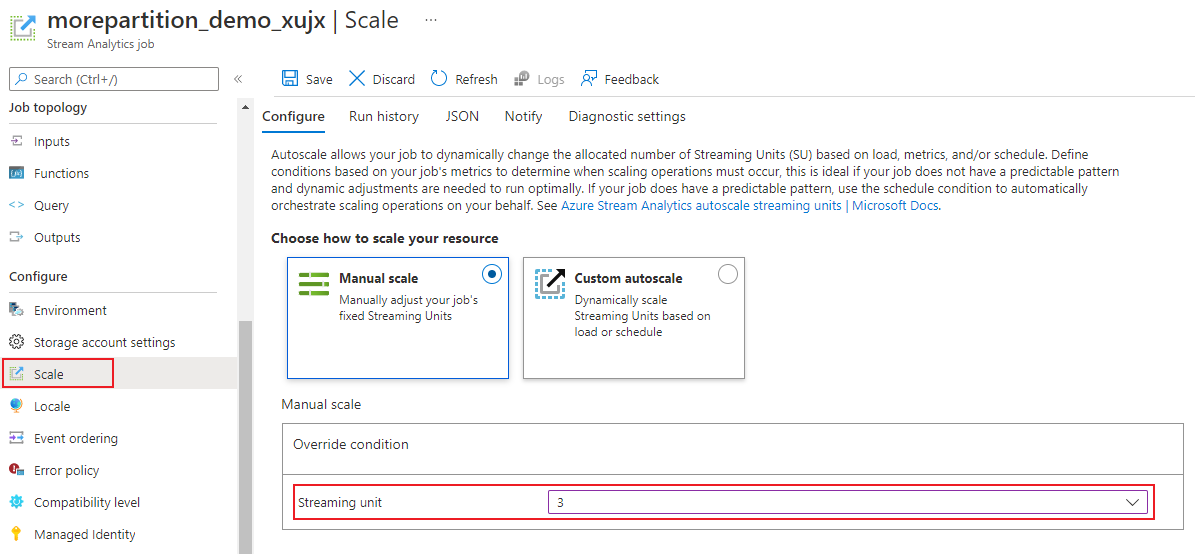
İşin SU'larını ayarlamak için açılan listede SU seçeneğini belirleyin. Belirli bir SU aralığıyla sınırlı olduğunuzu fark edin.
çalışırken işinize atanan SU sayısını değiştirebilirsiniz. İşiniz bölümlenmemiş bir çıkış kullanıyorsa veya farklı PARTITION BY değerlerine sahip çok adımlı bir sorguya sahipse, iş çalışırken bir DIZI SU değeri arasından seçim yapmakla kısıtlanmış olabilirsiniz.
İş performansını izleme
Azure portalını kullanarak bir işin performansla ilgili ölçümlerini izleyebilirsiniz. Ölçüm tanımı hakkında bilgi edinmek için bkz . Azure Stream Analytics iş ölçümleri. Portalda ölçüm izleme hakkında daha fazla bilgi edinmek için bkz . Azure portalı ile Stream Analytics işini izleme.
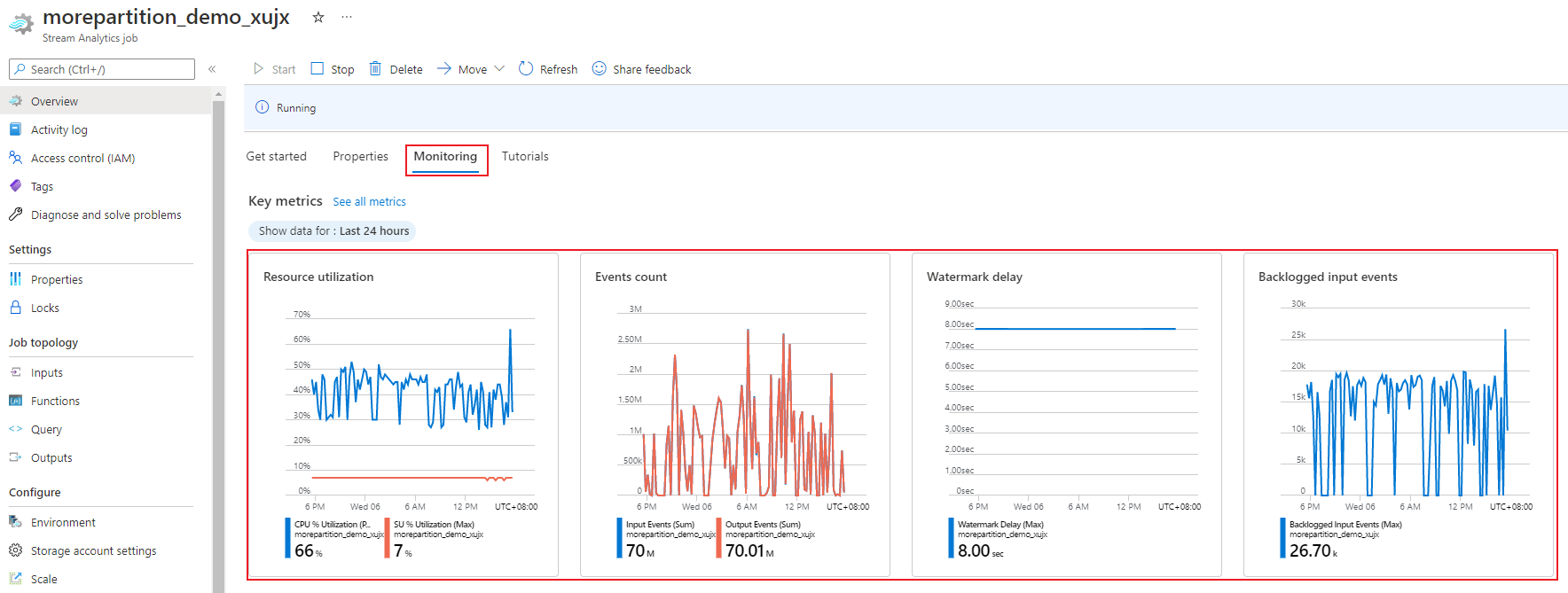
İş yükünün beklenen aktarım hızını hesaplama. Aktarım hızı beklenenden azsa giriş bölümünü ayarlayın, sorguyu ayarlayın ve işinize SU ekleyin.
Bir iş için kaç SU gerekir?
Belirli bir iş için gerekli SU sayısını seçmek, girişlerin bölüm yapılandırmasına ve iş içinde tanımlanan sorguya bağlıdır. Ölçek sayfası doğru sayıda SU ayarlamanıza olanak tanır. Gerekenden daha fazla SU ayırmak en iyi yöntemdir. Stream Analytics işleme altyapısı, ek bellek ayırma maliyetiyle gecikme süresi ve aktarım hızı için iyileştirmeler sağlar.
Genel olarak, en iyi yöntem PARTITION BY kullanmayan sorgular için 1 SU V2 ile başlamaktır. Ardından, temsili miktarda veri geçtikten ve SU Kullanımı ölçümünü inceledikten sonra SU sayısını değiştirdiğiniz bir deneme ve hata yöntemi kullanarak tatlı noktayı belirleyin. Stream Analytics işi tarafından kullanılabilecek en fazla akış birimi sayısı, iş için tanımlanan sorgudaki adım sayısına ve her adımda bölüm sayısına bağlıdır. Sınırlar hakkında buradan daha fazla bilgi edinebilirsiniz.
Doğru sayıda SU seçme hakkında daha fazla bilgi için şu sayfaya bakın: Aktarım hızını artırmak için Azure Stream Analytics işlerini ölçeklendirme.
Not
Belirli bir iş için kaç SU'nun gerekli olduğunu seçmek, girişlerin bölüm yapılandırmasına ve iş için tanımlanan sorguya bağlıdır. bir iş için SU'larda kotanıza kadar seçebilirsiniz. Azure Stream Analytics abonelik kotası hakkında bilgi için Stream Analytics sınırları'na bakın. Aboneliklerinizin SU'larını bu kotanın ötesinde artırmak için Microsoft Desteği başvurun. İş başına geçerli SU değerleri 1/3, 2/3, 1, 2, 3 vb. değerlerdir.
SU kullanım yüzdesini artıran faktörler
Zamana bağlı (zamana dayalı) sorgu öğeleri, Stream Analytics tarafından sağlanan durum bilgisi olan işleçlerin temel kümesidir. Stream Analytics, bellek tüketimini yöneterek, dayanıklılık için denetim noktası belirleyerek ve hizmet yükseltmeleri sırasında durum kurtarma yaparak bu işlemlerin durumunu kullanıcı adına dahili olarak yönetir. Stream Analytics durumları tam olarak yönetse de kullanıcıların dikkate alması gereken birçok en iyi uygulama önerisi vardır.
Karmaşık sorgu mantığına sahip bir işin, sürekli giriş olayları almasa bile yüksek SU kullanımına sahip olabileceğini unutmayın. Bu, giriş ve çıkış olaylarında ani bir ani artış sonrasında oluşabilir. Sorgu karmaşıksa iş bellekte durumu korumaya devam edebilir.
SU kullanımı beklenen düzeylere dönmeden önce kısa bir süre için aniden 0'a düşebilir. Bunun nedeni geçici hatalar veya sistem tarafından başlatılan yükseltmeler olabilir. Bir iş için akış birimi sayısının artırılması, sorgunuz tam olarak paralel değilse SU Kullanımını azaltmayabilir.
Belirli bir süre boyunca kullanımı karşılaştırırken olay hızı ölçümlerini kullanın. InputEvents ve OutputEvents ölçümleri kaç olayın okunup işlendiğini gösterir. Seri durumdan çıkarma hataları gibi hata olaylarının sayısını gösteren ölçümler de vardır. Zaman birimi başına olay sayısı arttığında çoğu durumda SU% artar.
Zamana bağlı öğelerde durum bilgisi olan sorgu mantığı
Azure Stream Analytics işinin benzersiz özelliğinden biri, pencerelenmiş toplamalar, zamana bağlı birleşimler ve zamansal analiz işlevleri gibi durum bilgisi olan işlemler gerçekleştirmektir. Bu işleçlerin her biri durum bilgilerini tutar. Bu sorgu öğeleri için en büyük pencere boyutu yedi gündür.
Geçici pencere kavramı çeşitli Stream Analytics sorgu öğelerinde görünür:
Pencerelenmiş toplamalar: Atlayan, Atlamalı ve Kayan pencerelerin GROUP BY değeri
Zamana bağlı birleşimler: DATEDIFF işleviyle JOIN
Zamana bağlı analiz işlevleri: LIMIT DURATION ile ISFIRST, LAST ve LAG
Aşağıdaki faktörler Stream Analytics işleri tarafından kullanılan belleği (akış birimleri ölçümünün bir parçası) etkiler:
Pencerelenmiş toplamalar
Pencerelenmiş toplama için tüketilen bellek (durum boyutu) her zaman pencere boyutuyla doğru orantılı değildir. Bunun yerine, tüketilen bellek verilerin kardinalitesi veya her zaman penceresindeki grup sayısıyla orantılıdır.
Örneğin, aşağıdaki sorguda ile clusterid ilişkilendirilmiş sayı sorgunun kardinalitesidir.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Önceki sorguda yüksek kardinalitenin neden olduğu sorunları azaltmak için, tarafından bölümlenmiş clusteridEvent Hubs'a olay gönderebilir ve aşağıdaki örnekte gösterildiği gibi sistemin partition BY kullanarak her giriş bölümünü ayrı olarak işlemesine izin vererek sorgunun ölçeğini genişletebilirsiniz:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
Sorgu bölümlendikten sonra birden çok düğüme yayılır. Sonuç olarak, her düğüme gelen değerlerin clusterid sayısı azaltılır ve böylece grup işlecinin kardinalitesi azalır.
Azaltma adımı gereksinimini önlemek için Event Hubs bölümleri gruplandırma anahtarı tarafından bölümlenmelidir. Daha fazla bilgi için bkz . Event Hubs'a genel bakış.
Zamana bağlı birleşimler
Bir zamansal birleşimin tüketilen belleği (durum boyutu), birleştirmenin zamansal wiggle odasındaki olay sayısıyla orantılıdır ve bu da olay giriş hızının wiggle oda boyutuyla çarpılmasıdır. Başka bir deyişle, birleştirmeler tarafından tüketilen bellek, ortalama olay hızıyla çarpılan DateDiff zaman aralığıyla orantılıdır.
Birleştirmedeki eşleşmeyen olayların sayısı sorgunun bellek kullanımını etkiler. Aşağıdaki sorgu, tıklama oluşturan reklam görüntüleme sayısını bulmayı amaçlamaktadır:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
Bu örnekte çok sayıda reklam gösteriliyor ve çok az kişi bu reklama tıklanıyor olabilir ve tüm etkinliklerin zaman penceresinde tutulması gerekir. Tüketilen bellek miktarı pencere boyutu ve olay hızıyla doğru orantılıdır.
Bunu düzeltmek için olayları birleştirme anahtarları tarafından bölümlenmiş Event Hubs'a gönderin (bu örnekte kimlik) ve sistemin her giriş bölümünü aşağıda gösterildiği gibi PARTITION BY kullanarak ayrı ayrı işlemesine izin vererek sorgunun ölçeğini genişletin:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
Sorgu bölümlendikten sonra birden çok düğüme yayılır. Sonuç olarak, her düğüme gelen olay sayısı azalır ve böylece birleştirme penceresinde tutulan durumun boyutu azalır.
Zamana bağlı analiz işlevleri
Zamansal analiz işlevinin tüketilen belleği (durum boyutu), olay hızının süreyle çarpması ile orantılıdır. Analiz işlevleri tarafından kullanılan bellek, pencere boyutuyla orantılı değildir, her zaman penceresinde bölüm sayısıdır.
Düzeltme, zamana bağlı birleşime benzer. PARTITION BY kullanarak sorgunun ölçeğini genişletebilirsiniz.
Sıra dışı arabelleği
Kullanıcı, Olay Sıralama yapılandırma bölmesinde sıra dışı arabellek boyutunu yapılandırabilir. Arabellek, pencere süresi boyunca girişleri tutmak ve yeniden sıralamak için kullanılır. Arabelleğin boyutu, olay giriş hızının sıra dışı pencere boyutuyla çarpmasıyla orantılıdır. Varsayılan pencere boyutu 0'dır.
Sıra dışı arabelleğinin taşma işlemini düzeltmek için PARTITION BY kullanarak sorgunun ölçeğini genişletin. Sorgu bölümlendikten sonra birden çok düğüme yayılır. Sonuç olarak, her düğüme gelen olay sayısı azalır ve böylece her yeniden sıralama arabelleğindeki olay sayısı azalır.
Giriş bölümü sayısı
bir iş girişinin her giriş bölümü bir arabelleğe sahiptir. Giriş bölümü sayısı ne kadar fazlaysa, iş o kadar fazla kaynak tüketir. Her akış birimi için Azure Stream Analytics yaklaşık 7 MB/sn girişi işleyebilir. Bu nedenle, Stream Analytics akış birimlerinin sayısını olay hub'ınızdaki bölüm sayısıyla eşleştirerek iyileştirebilirsiniz.
Genellikle, 1/3 akış birimiyle yapılandırılmış bir iş, iki bölümü olan bir olay hub'ı için yeterlidir (olay hub'ı için en düşük değerdir). Olay hub'ınız daha fazla bölüme sahipse Stream Analytics işiniz daha fazla kaynak tüketir, ancak Event Hubs tarafından sağlanan ek aktarım hızını kullanmayabilir.
1 V2 akış birimine sahip bir iş için olay hub'ından 4 veya 8 bölüm gerekebilir. Ancak, çok fazla kaynak kullanımına neden olduğundan çok fazla gereksiz bölüm kullanmaktan kaçının. Örneğin, 1 akış birimi olan bir Stream Analytics işinde 16 bölümlü veya daha büyük bir olay hub'ı.
Başvuru verileri
Hızlı arama için ASA'daki başvuru verileri belleğe yüklenir. Geçerli uygulamayla, başvuru verilerine sahip her birleştirme işlemi, aynı başvuru verileriyle birden çok kez katılsanız bile başvuru verilerinin bir kopyasını bellekte tutar. PARTITION BY olan sorgular için her bölümde başvuru verilerinin bir kopyası vardır, bu nedenle bölümler tamamen ayrılmıştır. Çarpan etkisiyle, başvuru verileriyle birden çok bölüme birden çok kez katılırsanız bellek kullanımı hızla çok yükselebilir.
UDF işlevlerinin kullanımı
UDF işlevi eklediğinizde, Azure Stream Analytics JavaScript çalışma zamanını belleğe yükler. Bu, SU% değerini etkiler.
Sonraki adımlar
- Azure Stream Analytics'te paralelleştirilebilir sorgular oluşturma
- Aktarım hızını artırmak için Azure Stream Analytics işlerini ölçeklendirme
- Azure Stream Analytics iş ölçümleri
- Azure Stream Analytics iş ölçümleri boyutları
- Azure portalı ile Stream Analytics işini izleme
- Ölçüm boyutlarıyla Stream Analytics iş performansını analiz etme
- Akış Birimlerini anlama ve ayarlama