Apache Spark için Azure Synapse Ayrılmış SQL Havuzu Bağlayıcısı
Giriş
Azure Synapse Analytics'teki Apache Spark için Azure Synapse Ayrılmış SQL Havuzu Bağlayıcısı, Apache Spark çalışma zamanı ile Ayrılmış SQL havuzu arasında büyük veri kümelerinin verimli bir şekilde aktarılmasını sağlar. Bağlayıcı, Azure Synapse Çalışma Alanı ile varsayılan kitaplık olarak gönderilir. Bağlayıcı, dil kullanılarak Scala uygulanır. Bağlayıcı Scala ve Python'ı destekler. Bağlayıcı'yı diğer not defteri dil seçenekleriyle kullanmak için Spark magic komutunu kullanın: %%spark.
Bağlayıcı üst düzeyde aşağıdaki özellikleri sağlar:
- Azure Synapse Ayrılmış SQL Havuzu'ndan okuyun:
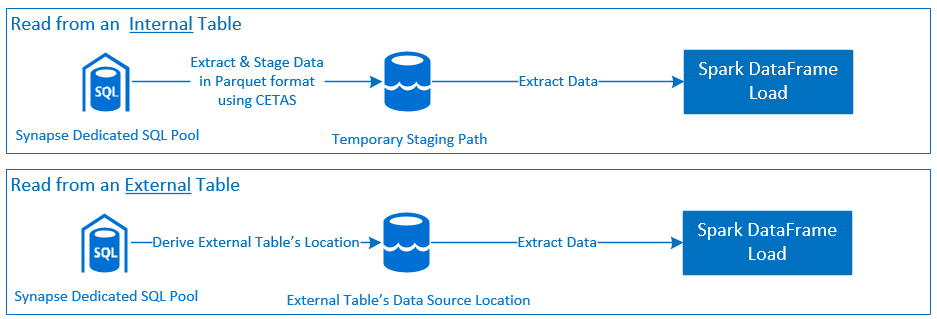
- Synapse Ayrılmış SQL Havuzu Tablolarından (İç ve Dış) ve görünümlerden büyük veri kümelerini okuyun.
- DataFrame'de filtrelerin ilgili SQL koşulu gönderimine eşlendiği kapsamlı koşul aşağı gönderme desteği.
- Sütun ayıklama desteği.
- Sorgu aşağı gönderme desteği.
- Azure Synapse Ayrılmış SQL Havuzu'na yazma:
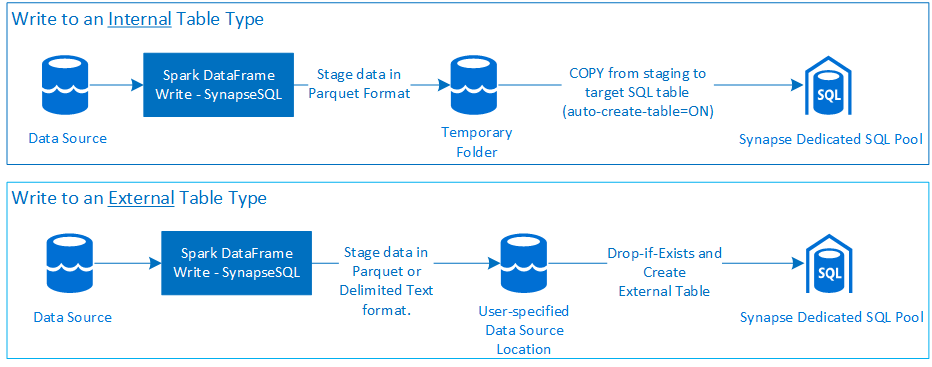
- büyük hacimli verileri İç ve Dış tablo türlerine alın.
- Aşağıdaki DataFrame kaydetme modu tercihlerini destekler:
AppendErrorIfExistsIgnoreOverwrite
- Dış Tabloya Yazma, Parquet ve Sınırlandırılmış Metin dosya biçimini (örnek - CSV) destekler.
- İç tablolara veri yazmak için bağlayıcı artık CETAS/CTAS yaklaşımı yerine COPY deyimini kullanıyor.
- Uçtan uca yazma aktarım hızı performansını iyileştirmeye yönelik geliştirmeler.
- İstemcilerin yazma sonrası ölçümleri almak için kullanabileceği isteğe bağlı bir geri arama tutamacını (Scala işlev bağımsız değişkeni) tanıtır.
- Birkaç örnek şunlardır: kayıt sayısı, belirli bir eylemi tamamlama süresi ve hata nedeni.
Düzenleme yaklaşımı
Okundu
Write
Önkoşullar
Gerekli Azure kaynaklarını ayarlama gibi önkoşullar ve bunları yapılandırma adımları bu bölümde açıklanmıştır.
Azure kaynakları
Bağımlı Azure Kaynaklarını gözden geçirin ve ayarlayın:
- Azure Data Lake Storage - Azure Synapse Çalışma Alanı için birincil depolama hesabı olarak kullanılır.
- Azure Synapse Çalışma Alanı - Not defterleri oluşturun, DataFrame tabanlı giriş-çıkış iş akışlarını derleyin ve dağıtın.
- Ayrılmış SQL Havuzu (eski adıYLA SQL DW) - kurumsal Veri Depolama özellikleri sağlar.
- Azure Synapse Sunucusuz Spark Havuzu - İşlerin Spark Uygulamaları olarak yürütüldüğü Spark çalışma zamanı.
Veritabanını hazırlama
Synapse Ayrılmış SQL Havuzu veritabanına bağlanın ve aşağıdaki kurulum deyimlerini çalıştırın:
Azure Synapse Çalışma Alanı'nda oturum açmak için kullanılan Microsoft Entra kullanıcı kimliğine eşlenmiş bir veritabanı kullanıcısı oluşturun.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Bağlayıcının ilgili tablolara başarıyla yazabilmesi ve bu tablolardan okunabilmesi için tabloların tanımlanacağı şemayı oluşturun.
CREATE SCHEMA [<schema_name>];
Kimlik Doğrulaması
Microsoft Entra Id tabanlı kimlik doğrulaması
Microsoft Entra Id tabanlı kimlik doğrulaması tümleşik bir kimlik doğrulama yaklaşımıdır. Kullanıcının Azure Synapse Analytics Çalışma Alanı'nda başarıyla oturum açması gerekir.
Temel kimlik doğrulama
Temel bir kimlik doğrulama yaklaşımı, kullanıcının yapılandırmasını username ve password seçeneklerini gerektirir. Azure Synapse Ayrılmış SQL Havuzu'ndaki tablolardan okuma ve tabloya yazmayla ilgili yapılandırma parametreleri hakkında bilgi edinmek için yapılandırma seçenekleri bölümüne bakın.
Yetkilendirme
Azure Data Lake Storage 2. Nesil
Azure Data Lake Storage 2. Nesil erişim izinleri vermenin iki yolu vardır: Depolama Hesabı:
- Rol tabanlı Erişim Denetimi rolü - Depolama Blob Verileri Katkıda Bulunanı rolü
- ataması
Storage Blob Data Contributor Role, Kullanıcıya Azure Depolama Blobu Kapsayıcıları'nı okuma, yazma ve silme izinleri verir. - RBAC, kapsayıcı düzeyinde kaba bir denetim yaklaşımı sunar.
- ataması
-
Erişim Denetim Listeleri (ACL)
- ACL yaklaşımı, belirli bir klasör altındaki belirli yollar ve/veya dosyalar üzerinde ayrıntılı denetimler yapılmasını sağlar.
- Kullanıcıya RBAC yaklaşımı kullanılarak zaten izinler verildiyse ACL denetimleri uygulanmaz.
- İki geniş türde ACL izni vardır:
- Erişim İzinleri (belirli bir düzeyde veya nesnede uygulanır).
- Varsayılan İzinler (oluşturuldukları sırada tüm alt nesneler için otomatik olarak uygulanır).
- İzin türü şunlardır:
-
Execute, klasör hiyerarşileri arasında geçiş yapma veya bu hiyerarşilerde gezinme olanağı sağlar. -
Readokuma özelliğini etkinleştirir. -
Writeyazma özelliğini etkinleştirir.
-
- ACL'leri Bağlayıcının depolama konumlarından başarıyla yazabileceği ve okuyabileceği şekilde yapılandırmak önemlidir.
Not
Synapse Çalışma Alanı işlem hatlarını kullanarak not defterlerini çalıştırmak istiyorsanız, Synapse Çalışma Alanı varsayılan yönetilen kimliğine yukarıda listelenen erişim izinlerini de vermelisiniz. Çalışma alanının varsayılan yönetilen kimlik adı, çalışma alanının adıyla aynıdır.
Synapse çalışma alanını güvenli depolama hesaplarıyla kullanmak için, not defterinden yönetilen bir özel uç nokta yapılandırılmalıdır. Yönetilen özel uç nokta, bölmedeki ADLS 2. Nesil depolama hesabının
Private endpoint connectionsbölümündenNetworkingonaylanmalıdır.
Azure Synapse Ayrılmış SQL Havuzu
Azure Synapse Ayrılmış SQL Havuzu ile başarılı etkileşimi etkinleştirmek için, Ayrılmış SQL Bitiş Noktası'nda da yapılandırılmış bir Active Directory Admin kullanıcı değilseniz aşağıdaki yetkilendirme gereklidir:
Senaryo okuma
db_exporterKullanıcıya sistem saklı yordamını kullanarak verinsp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Yazma senaryosu
- Bağlayıcı, hazırlamadan iç tablonun yönetilen konumuna veri yazmak için COPY komutunu kullanır.
Burada açıklanan gerekli izinleri yapılandırın.
Aşağıda, aynı hızlı erişim parçacığı verilmiştir:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Bağlayıcı, hazırlamadan iç tablonun yönetilen konumuna veri yazmak için COPY komutunu kullanır.
API belgeleri
Apache Spark için Azure Synapse Ayrılmış SQL Havuzu Bağlayıcısı - API Belgeleri.
Yapılandırma seçenekleri
Okuma veya yazma işlemini başarıyla önyüklemek ve yönetmek için Bağlayıcı belirli yapılandırma parametrelerini bekler. nesne tanımı - com.microsoft.spark.sqlanalytics.utils.Constants her parametre anahtarı için standartlaştırılmış sabitlerin listesini sağlar.
Kullanım senaryosuna göre yapılandırma seçeneklerinin listesi aşağıdadır:
-
Microsoft Entra Id tabanlı kimlik doğrulamasını kullanarak okuma
- Kimlik bilgileri otomatik olarak eşlenir ve kullanıcının belirli yapılandırma seçeneklerini sağlaması gerekmez.
- Azure Synapse Ayrılmış SQL Havuzu'ndaki
synapsesqlilgili tablodan okumak için yöntemindeki üç bölümlü tablo adı bağımsız değişkeni gereklidir.
-
Temel kimlik doğrulaması kullanarak okuma
- Azure Synapse Ayrılmış SQL Uç Noktası
-
Constants.SERVER- Synapse Ayrılmış SQL Havuzu Uç Noktası (Server FQDN) -
Constants.USER- SQL Kullanıcı Adı. -
Constants.PASSWORD- SQL Kullanıcı Parolası.
-
- Azure Data Lake Storage (2. Nesil) Uç Noktası - Hazırlama Klasörleri
-
Constants.DATA_SOURCE- Veri hazırlama için veri kaynağı konum parametresinde ayarlanan depolama yolu kullanılır.
-
- Azure Synapse Ayrılmış SQL Uç Noktası
-
Microsoft Entra Id tabanlı kimlik doğrulaması kullanarak yazma
- Azure Synapse Ayrılmış SQL Uç Noktası
- Varsayılan olarak Bağlayıcı, yöntemin üç bölümlü tablo adı parametresinde
synapsesqlayarlanan veritabanı adını kullanarak Synapse Ayrılmış SQL uç noktasını çıkarsar. - Alternatif olarak, kullanıcılar sql uç noktasını belirtmek için seçeneğini kullanabilir
Constants.SERVER. Bitiş noktasının ilgili veritabanını ilgili şemayla barındırdığından emin olun.
- Varsayılan olarak Bağlayıcı, yöntemin üç bölümlü tablo adı parametresinde
- Azure Data Lake Storage (2. Nesil) Uç Noktası - Hazırlama Klasörleri
- İç Tablo Türü için:
-
Constants.TEMP_FOLDERveyaConstants.DATA_SOURCEseçeneğini yapılandırın. - Kullanıcı seçenek sağlamayı
Constants.DATA_SOURCEseçerse, hazırlama klasörü DataSource'tan alınan değer kullanılaraklocationtüretilir. - Her ikisi de sağlanmışsa seçenek
Constants.TEMP_FOLDERdeğeri kullanılır. - Hazırlama klasörü seçeneği olmadığında, Bağlayıcı çalışma zamanı yapılandırmasına göre bir klasör türetir -
spark.sqlanalyticsconnector.stagingdir.prefix.
-
- Dış Tablo Türü için:
-
Constants.DATA_SOURCEgerekli bir yapılandırma seçeneğidir. - Bağlayıcı, veri kaynağının konum parametresinde ayarlanan depolama yolunu yönteminin
locationbağımsız değişkeniylesynapsesqlbirlikte kullanır ve dış tablo verilerini kalıcı hale getirmek için mutlak yolu türetir. - yöntemine
locationsynapsesqlbağımsız değişken belirtilmezse, bağlayıcı konum değerini olarak<base_path>/dbName/schemaName/tableNametüretecektir.
-
- İç Tablo Türü için:
- Azure Synapse Ayrılmış SQL Uç Noktası
-
Temel kimlik doğrulaması kullanarak yazma
- Azure Synapse Ayrılmış SQL Uç Noktası
-
Constants.SERVER- - Synapse Ayrılmış SQL Havuzu Uç Noktası (Server FQDN). -
Constants.USER- SQL Kullanıcı Adı. -
Constants.PASSWORD- SQL Kullanıcı Parolası. -
Constants.STAGING_STORAGE_ACCOUNT_KEYbarındıranConstants.TEMP_FOLDERSDepolama Hesabı ile ilişkili (yalnızca iç tablo türleri) veyaConstants.DATA_SOURCE.
-
- Azure Data Lake Storage (2. Nesil) Uç Noktası - Hazırlama Klasörleri
- SQL temel kimlik doğrulaması kimlik bilgileri depolama uç noktalarına erişmek için geçerli değildir.
- Bu nedenle, Azure Data Lake Storage 2. Nesil bölümünde açıklandığı gibi ilgili depolama erişim izinlerini atadığınızdan emin olun.
- Azure Synapse Ayrılmış SQL Uç Noktası
Kod şablonları
Bu bölümde, Apache Spark için Azure Synapse Ayrılmış SQL Havuzu Bağlayıcısı'nı kullanmayı ve çağırmayı açıklayan başvuru kodu şablonları sunulur.
Not
Python'da Bağlayıcıyı Kullanma-
- Bağlayıcı yalnızca Spark 3 için Python'da desteklenir. Spark 2.4 (desteklenmeyen) için Scala bağlayıcı API'sini kullanarak DataFrame.createOrReplaceTempView veya DataFrame.createOrReplaceGlobalTempView kullanarak PySpark'taki bir DataFrame'den içerikle etkileşim kurabiliriz. Bkz. Bölüm - Hücreler arasında gerçekleştirilmiş verileri kullanma.
- Geri arama tutamacı Python'da kullanılamaz.
Azure Synapse Ayrılmış SQL Havuzundan okuma
Okuma İsteği - synapsesql yöntem imzası
Microsoft Entra Id tabanlı kimlik doğrulamasını kullanarak bir tablodan okuma
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Microsoft Entra Id tabanlı kimlik doğrulamasını kullanarak sorgudan okuma
Not
Sorgudan okurken kısıtlamalar:
- Tablo adı ve sorgu aynı anda belirtilemez.
- Yalnızca belirli sorgulara izin verilir. DDL ve DML SQL'lerine izin verilmez.
- Bir sorgu belirtildiğinde veri çerçevesi üzerindeki seçme ve filtreleme seçenekleri SQL ayrılmış havuzuna gönderilmez.
- Sorgudan okuma yalnızca Spark 3'te kullanılabilir.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Temel kimlik doğrulamasını kullanarak tablodan okuma
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Temel kimlik doğrulamasını kullanarak sorgudan okuma
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Azure Synapse Ayrılmış SQL Havuzuna yazma
Yazma İsteği - synapsesql yöntem imzası
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Microsoft Entra Id tabanlı kimlik doğrulaması kullanarak yazma
Aşağıda, yazma senaryoları için Bağlayıcı'nın nasıl kullanılacağını açıklayan kapsamlı bir kod şablonu bulunur:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Temel kimlik doğrulaması kullanarak yazma
Aşağıdaki kod parçacığı, SQL temel kimlik doğrulaması yaklaşımını kullanarak yazma isteği göndermek için Microsoft Entra Id tabanlı kimlik doğrulaması kullanarak yazma bölümünde açıklanan yazma tanımının yerini alır:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
Temel bir kimlik doğrulama yaklaşımında, bir kaynak depolama yolundaki verileri okumak için diğer yapılandırma seçenekleri gereklidir. Aşağıdaki kod parçacığı, Hizmet Sorumlusu kimlik bilgilerini kullanarak bir Azure Data Lake Storage 2. Nesil veri kaynağından okuma örneği sağlar:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Desteklenen DataFrame kaydetme modları
Azure Synapse Ayrılmış SQL Havuzu'nda hedef tabloya kaynak veriler yazılırken aşağıdaki kaydetme modları desteklenir:
- ErrorIfExists (varsayılan kaydetme modu)
- Hedef tablo varsa, çağrıya döndürülen bir özel durumla yazma durduruldu. Aksi halde, hazırlama klasörlerinden alınan verilerle yeni bir tablo oluşturulur.
- Yok saymak
- Hedef tablo varsa, yazma işlemi hata döndürmeden yazma isteğini yoksayar. Aksi halde, hazırlama klasörlerinden alınan verilerle yeni bir tablo oluşturulur.
- Üzerine
- Hedef tablo varsa, hedefteki mevcut veriler hazırlama klasörlerindeki verilerle değiştirilir. Aksi halde, hazırlama klasörlerinden alınan verilerle yeni bir tablo oluşturulur.
- Ekleme
- Hedef tablo varsa, yeni veriler bu tabloya eklenir. Aksi halde, hazırlama klasörlerinden alınan verilerle yeni bir tablo oluşturulur.
Yazma isteği geri çağırma tutamacı
Yeni yazma yolu API'sinde yapılan değişiklikler, istemciye yazma sonrası ölçümlerin anahtar-değer> eşlemesini sağlayan deneysel bir özellik sağladı. Ölçümlerin anahtarları yeni Nesne tanımında tanımlanır: Constants.FeedbackConstants. Ölçümler, geri çağırma tutamacını (a Scala Function) geçirerek JSON dizesi olarak alınabilir. İşlev imzası aşağıdadır:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Aşağıda bazı önemli ölçümler verilmiştir (deve durumunda sunulmuştur):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Aşağıda, yazma sonrası ölçümlere sahip örnek bir JSON dizesi verilmiştir:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Diğer kod örnekleri
Hücreler arasında gerçekleştirilmiş verileri kullanma
Spark DataFrame'ler createOrReplaceTempView , geçici bir görünüm kaydederek başka bir hücrede getirilen verilere erişmek için kullanılabilir.
- Verilerin getirildiği hücre (not defteri dil tercihi gibi
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Şimdi Not Defteri'nde
PySpark (Python)dil tercihini olarak değiştirin ve kayıtlı görünümden veri getirin<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Yanıt işleme
Çağırmanın synapsesql iki olası son durumu vardır: Başarılı veya Başarısız Durum. Bu bölümde, her senaryo için istek yanıtını işleme açıklanmaktadır.
Okuma isteği yanıtı
Tamamlandıktan sonra, hücrenin çıkışında okuma yanıtı parçacığı görüntülenir. Geçerli hücredeki hata, sonraki hücre yürütmelerini de iptal eder. Ayrıntılı hata bilgileri Spark Uygulama Günlükleri'nde bulunur.
Yazma isteği yanıtı
Varsayılan olarak, hücre çıkışına bir yazma yanıtı yazdırılır. Hata durumunda geçerli hücre başarısız olarak işaretlenir ve sonraki hücre yürütmeleri durdurulacaktır. Diğer yaklaşım ise geri çağırma tutamacını yöntemine geçirmektirsynapsesql. Geri çağırma tutamacı, yazma yanıtına programlı erişim sağlar.
Dikkat edilecek diğer noktalar
- Azure Synapse Ayrılmış SQL Havuzu tablolarından okurken:
- Bağlayıcının sütun ayıklama özelliğinden yararlanmak için DataFrame'e gerekli filtreleri uygulamayı göz önünde bulundurun.
- Okuma senaryosu sorgu deyimlerini
TOP(n-rows)çerçevelerken yan tümcesiniSELECTdesteklemez. Verileri sınırlama seçeneği DataFrame'in limit(.) yan tümcesini kullanmaktır.- Örnek: Hücreler arasında gerçekleştirilmiş verileri kullanma bölümü.
- Azure Synapse Ayrılmış SQL Havuzu tablolarına yazarken:
- İç tablo türleri için:
- Tablolar ROUND_ROBIN veri dağıtımıyla oluşturulur.
- Sütun türleri DataFrame'den kaynaktan veri okuyacak şekilde çıkarılır. Dize sütunları ile
NVARCHAR(4000)eşlenir.
- Dış tablo türleri için:
- DataFrame'in ilk paralelliği, dış tablo için veri kuruluşunu yönlendirer.
- Sütun türleri DataFrame'den kaynaktan veri okuyacak şekilde çıkarılır.
- ve DataFrame
repartitionparametresi ayarlanarakspark.sql.files.maxPartitionBytesyürütücüler arasında daha iyi veri dağıtımı elde edilebilir. - Büyük veri kümeleri yazarken, işlem boyutunu sınırlayan DWU Performans Düzeyi ayarının etkisini dikkate almak önemlidir.
- İç tablo türleri için:
- Okuma ve yazma performansını etkileyebilecek azaltma davranışlarını saptamak için Azure Data Lake Storage 2. Nesil kullanım eğilimlerini izleyin.