Azure Synapse Analytics’te Apache Spark
Apache Spark, büyük veri analizi uygulamalarının performansını artırmak üzere bellek içi işlemeyi destekleyen paralel işleme altyapısıdır. Azure Synapse Analytics’te Apache Spark, Microsoft'un buluttaki Apache Spark uygulamalarından biridir. Azure Synapse Azure’da sunucusuz Apache Spark havuzu oluşturmayı ve yapılandırmayı kolaylaştırır. Azure Synapse’de Spark havuzları Azure Depolama ve Azure Data Lake 2. Nesil Depolama ile uyumludur. Bu nedenle Spark havuzlarını Azure’da depolanan verilerinizi işlemek için kullanabilirsiniz.
Apache Spark nedir?
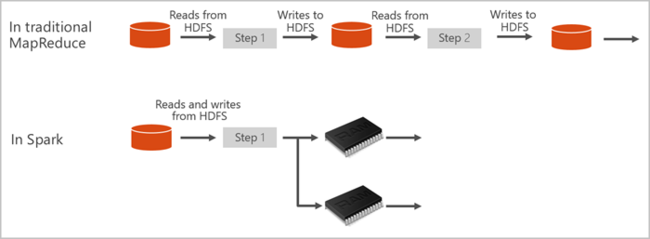
Apache Spark, bellek içi küme hesaplama için temel bileşenleri sunar. Bir Spark işi, verileri belleğe yükleyip önbelleğe alarak tekrar tekrar sorgulayabilir. Bellek içi işlemler, disk tabanlı uygulamalardan çok daha hızlıdır. Spark ayrıca birçok bilgisayar diliyle tümleştirilerek yerel koleksiyonlar gibi dağıtılmış veri kümelerini işlemenizi sağlar. Her şeyi harita olarak yapılandırmaya gerek olmadığı için işlem sayısı azalmış olur. Synapse için Apache Spark videosundan daha fazla bilgi edinebilirsiniz.
Azure Synapse'teki Spark havuzları tam olarak yönetilen bir Spark hizmeti sunar. Azure Synapse Analytics'te Spark havuzu oluşturmanın avantajları burada listelenmiştir.
| Özellik | Açıklama |
|---|---|
| Hız ve verimlilik | Spark örnekleri 60'tan az düğüm için yaklaşık 2 dakika ve 60'tan fazla düğüm için yaklaşık 5 dakika içinde başlar. Örnek, not defteri bağlantısı tarafından canlı tutulmadığı sürece son iş çalıştırıldıktan 5 dakika sonra varsayılan olarak kapanır. |
| Oluşturma kolaylığı | Azure portalı, Azure PowerShell veya Synapse Analytics .NET SDK'sını kullanarak Azure Synapse'te dakikalar içinde yeni bir Spark havuzu oluşturabilirsiniz. Bkz . Azure Synapse Analytics'te Spark havuzlarını kullanmaya başlama. |
| Kullanım kolaylığı | Synapse Analytics, nteract'ten türetilen özel bir not defteri içerir. Etkileşimli veri işleme ve görselleştirme için bu not defterlerini kullanabilirsiniz. |
| REST API'leri | Azure Synapse Analytics'teki Spark, işleri uzaktan göndermek ve izlemek için REST API tabanlı bir Spark iş sunucusu olan Apache Livy'yi içerir. |
| Azure Data Lake Depolama 2. Nesil desteği | Azure Synapse'teki Spark havuzları Azure Data Lake Depolama 2. Nesil ve BLOB depolamayı kullanabilir. Data Lake Depolama hakkında daha fazla bilgi için bkz. Azure Data Lake Depolama genel bakış. |
| Üçüncü taraf IDE’lerle tümleştirme | Azure Synapse, JetBrains'in IntelliJ IDEA'sı için spark havuzu oluşturmak ve bu havuza uygulama göndermek için yararlı olan bir IDE eklentisi sağlar. |
| Önceden yüklenmiş Anaconda kitaplıkları | Azure Synapse'teki Spark havuzları, Anaconda kitaplıkları önceden yüklenmiş olarak gelir. Anaconda makine öğrenmesi, veri analizi, görselleştirme ve diğer teknolojiler için 200'e yakın kitaplık sağlar. |
| Ölçeklenebilirlik | Azure Synapse havuzlarındaki Apache Spark'ta Otomatik Ölçeklendirme etkinleştirilebilir, böylece havuzlar gerektiğinde düğüm ekleyerek veya kaldırarak ölçeklendirilir. Ayrıca tüm veriler Azure Depolama veya Data Lake Storage üzerinde depolandığından Spark havuzları veri kaybı yaşanmadan kapatılabilir. |
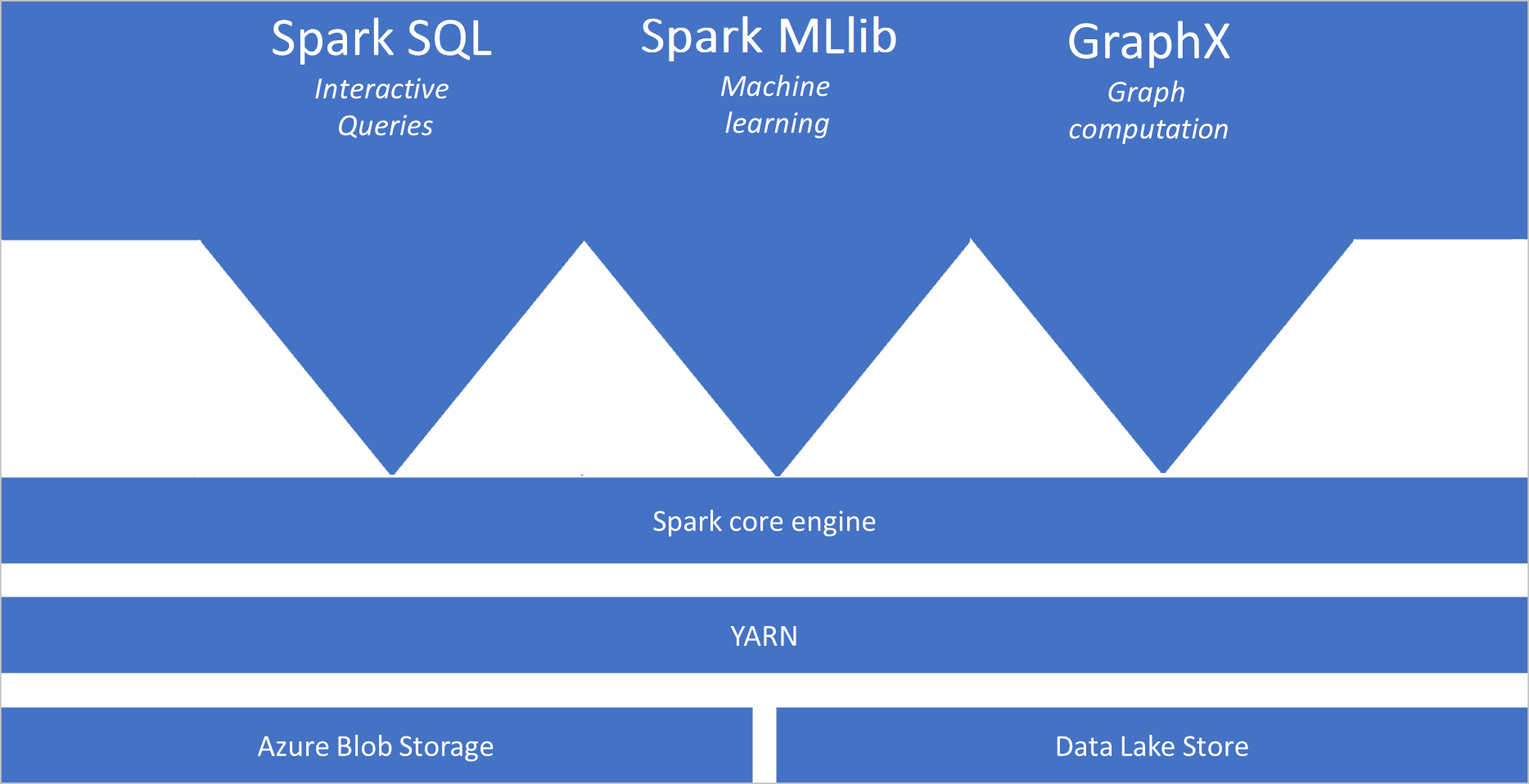
Azure Synapse'teki Spark havuzları, havuzlarda varsayılan olarak kullanılabilen aşağıdaki bileşenleri içerir:
- Spark Core. Spark Core, Spark SQL, GraphX ve MLlib’i içerir.
- Anaconda
- Apache Livy
- nteract not defteri
Spark havuzu mimarisi
Spark uygulamaları, sürücü programı olarak adlandırılan ana programınızdaki nesne tarafından SparkContext koordine edilen bir havuzda bağımsız işlem kümeleri olarak çalışır.
SparkContext, uygulamalar arasında kaynakları ayıran küme yöneticisine bağlanabilir. Küme yöneticisi Apache Hadoop YARN'dır. Bağlandıktan sonra Spark, uygulamanıza yönelik hesaplamalar çalıştıran ve verileri depolayan işlemler olan havuzdaki düğümlerde yürütücüler alır. Ardından, uygulamasına geçirilen SparkContextJAR veya Python dosyaları tarafından tanımlanan uygulama kodunuzu yürütücülere gönderir. Son olarak, SparkContext çalıştırılacak yürütücülere görevler gönderir.
kullanıcının SparkContext ana işlevini çalıştırır ve düğümlerde çeşitli paralel işlemleri yürütür. Ardından, SparkContext işlemlerin sonuçlarını toplar. Düğümler, dosya sisteminden ve dosya sistemine veri okur ve yazar. Düğümler ayrıca dönüştürülmüş verileri dayanıklı Dağıtılmış Veri Kümeleri (RDD) olarak önbelleğe alır.
Spark SparkContext havuzuna bağlanır ve bir uygulamayı yönlendirilmiş bir döngüsel grafiğe (DAG) dönüştürmekle sorumludur. Grafik, düğümlerdeki bir yürütücü işlemi içinde çalışan tek tek görevlerden oluşur. Her uygulama, uygulamanın tamamı boyunca ayakta kalan ve görevleri birden çok iş parçacığında çalıştıran kendi yürütücü işlemlerini alır.
Azure Synapse Analytics'te Apache Spark kullanım örnekleri
Azure Synapse Analytics'teki Spark havuzları aşağıdaki önemli senaryoları etkinleştirir:
- Veri Madenciliği/Veri Hazırlama
Apache Spark, Azure Synapse Analytics içindeki diğer hizmetler tarafından daha değerli hale getirilip kullanılabilmesi için büyük hacimli verilerin hazırlanmasını ve işlenmesini destekleyen birçok dil özelliği içerir. Bu işlem ve bağlantı için birden çok dil (C#, Scala, PySpark, Spark SQL) ve sağlanan kitaplıklar aracılığıyla etkinleştirilir.
- Machine Learning
Apache Spark, Azure Synapse Analytics'teki bir Spark havuzundan kullanabileceğiniz, Spark üzerinde oluşturulmuş bir makine öğrenmesi kitaplığı olan MLlib ile birlikte gelir. Azure Synapse Analytics'teki Spark havuzları, makine öğrenmesi de dahil olmak üzere veri bilimi için çeşitli paketler içeren bir Python dağıtımı olan Anaconda'yı da içerir. Yerleşik not defteri desteğiyle birlikte makine öğrenmesi uygulaması oluşturmak için gerekli ortamı sunar.
- Akış Verileri
Synapse Spark, Azure Synapse Spark çalışma zamanı sürümünün desteklenen sürümünü çalıştırdığınız sürece Spark yapılandırılmış akışını destekler. Tüm işlerin yedi gün boyunca yaşamaları desteklenir. Bu hem toplu iş hem de akış işleri için geçerlidir ve genellikle müşteriler Azure İşlevleri kullanarak yeniden başlatma işlemini otomatikleştirir.
Nereden başlarım?
Azure Synapse Analytics'te Apache Spark hakkında daha fazla bilgi edinmek için aşağıdaki makaleleri kullanın:
- Hızlı Başlangıç: Azure Synapse'te Spark havuzu oluşturma
- Hızlı Başlangıç: Apache Spark not defteri oluşturma
- Öğretici: Apache Spark kullanarak makine öğrenmesi
Not
Resmi Apache Spark belgelerinden bazıları, Azure Synapse Spark'ta bulunmayan Spark konsolunu kullanmaya dayanır. Bunun yerine not defterini veya IntelliJ deneyimlerini kullanın.
Sonraki adımlar
Bu genel bakış, Azure Synapse Analytics'te Apache Spark hakkında temel bilgiler sağlar. Azure Synapse Analytics'te Spark havuzu oluşturmayı öğrenmek için sonraki makaleye geçin: