Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Tip
Microsoft Fabric Data Warehouse geleceğe hazır mimariye, yerleşik yapay zekaya ve yeni özelliklere sahip data lake foundation üzerinde kurumsal ölçekli ilişkisel bir ambardır. Veri ambarı konusunda yeniyseniz Fabric Data Warehouse ile başlayın. Mevcut özel SQL havuzu iş yükleri, veri bilimi, gerçek zamanlı analiz ve raporlama genelinde yeni özelliklere erişmek için Fabric yükseltilebilir.
Bu bölümde, sunucusuz SQL havuzu sorgularını sarmak için görünümleri oluşturmayı ve kullanmayı öğreneceksiniz. Görünümler, bu sorguları yeniden kullanmanıza olanak sağlar. Power BI gibi araçları sunucusuz SQL havuzuyla birlikte kullanmak istiyorsanız görünümler de gereklidir.
Önkoşullar
İlk adımınız, görünümün oluşturulacağı bir veritabanı oluşturmak ve bu veritabanında kurulum betiğini yürüterek Azure depolamada kimlik doğrulaması yapmak için gereken nesneleri başlatmaktır. Bu makaledeki tüm sorgular örnek veritabanınızda yürütülür.
Dış veriler üzerindeki görüşler
Görünümleri, normal SQL Server görünümlerini oluşturduğunuz gibi oluşturabilirsiniz. Aşağıdaki sorgu, population.csv dosyasını okuyan bir görünüm oluşturur.
Note
Oluşturduğunuz veritabanını kullanmak için sorgudaki ilk satırı ([mydbname] gibi) değiştirin.
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
Görünüm, depolama alanınızın kök URL'siyle bir EXTERNAL DATA SOURCE kullanır ve DATA_SOURCE olarak dosyalara göreli bir dosya yolu ekler.
Delta Lake görünümleri
Delta Lake klasörünün üzerinde görünümleri oluşturuyorsanız, dosya yolunu belirtmek yerine seçenek sonrasında kök klasörün BULK konumunu belirtmeniz gerekir.
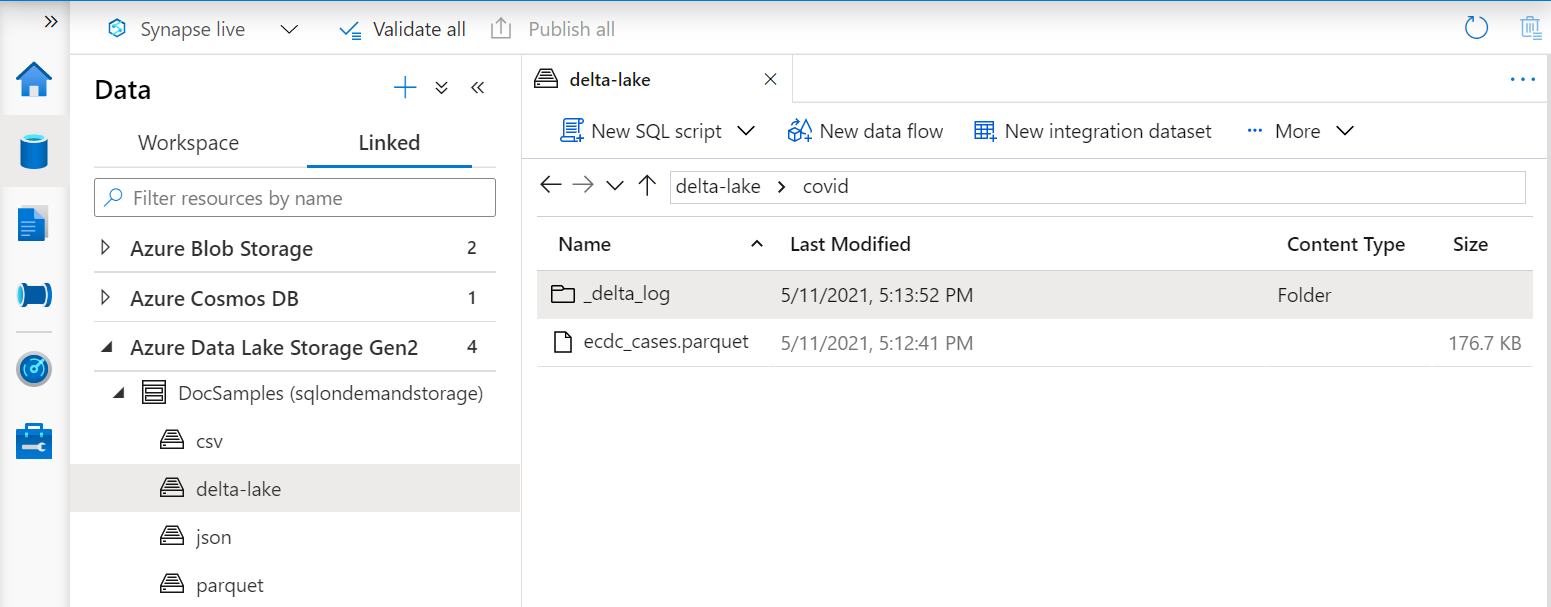
OPENROWSET Delta Lake klasöründeki verileri okuyan işlev, klasör yapısını inceler ve dosya konumlarını otomatik olarak tanımlar.
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
Daha fazla bilgi için Synapse sunucusuz SQL havuzu kendi kendine yardım sayfasını ve Bilinen Azure Synapse Analytics sorunlarını gözden geçirin.
Bölümlenmiş görünümler
Hiyerarşik klasör yapısında bölümlenmiş bir dosya kümeniz varsa, dosya yolundaki joker karakterleri kullanarak bölüm desenini açıklayabilirsiniz. klasör yolunun FILEPATH bölümlerini bölümleme sütunları olarak göstermek için işlevini kullanın.
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
Bölümlenmiş görünümler, bölümleme sütunlarında filtrelerle sorguladığınızda bölüm eleme gerçekleştirerek sorgularınızın performansını artırabilir. Ancak tüm sorgular bölüm ortadan kaldırmayı desteklemediğinden bazı en iyi yöntemleri izlemek önemlidir.
Bölüm elemeyi sağlamak için filtrelerde alt sorgular kullanmaktan kaçının, çünkü bunlar bölümlerin elenmesini engelleyebilir. Bunun yerine, alt sorgunun sonucunu filtreye değişken olarak geçirin.
SQL sorgularında JOIN'leri kullanırken, sorgu planının karmaşıklığını azaltmak ve doğru bölüm eleme olasılığını artırmak için filtre koşulunu NVARCHAR olarak bildirin. Bölüm sütunları genellikle NVARCHAR(1024) olarak belirlenir, bu nedenle koşul ifadesinde aynı türün kullanılması örtük bir dönüştürme gereksinimini önler, bu da sorgu planının karmaşıklığını artırabilir.
Delta Lake bölümlenmiş görünümleri
Delta Lake depolamasının üzerinde bölümlenmiş görünümler oluşturuyorsanız, yalnızca bir kök Delta Lake klasörü belirtebilirsiniz ve bölümleme sütunlarını şu işlevi kullanarak FILEPATH açıkça kullanıma sunmanız gerekmez:
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
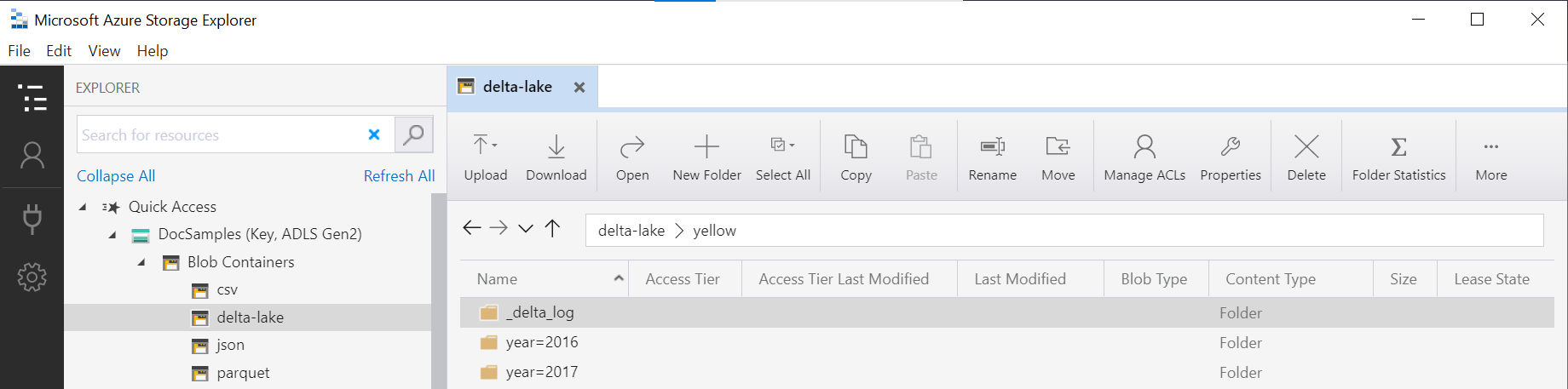
OPENROWSET İşlevi, altındaki Delta Lake klasörünün yapısını inceler ve bölümleme sütunlarını otomatik olarak tanımlar ve kullanıma sunar. Bölümleme sütununu WHERE bir sorgunun yan tümcesine koyarsanız bölümleme eleme işlemi otomatik olarak yapılır.
İşlevdeki OPENROWSET (yellow bu örnekte), veri kaynağı LOCATION içinde tanımlanan URI DeltaLakeStorage ile birleştirilen klasör adının, _delta_log adlı alt klasörü içeren kök Delta Lake klasörüne başvurması gerekir.
Daha fazla bilgi için Synapse sunucusuz SQL havuzu kendi kendine yardım sayfasını ve Bilinen Azure Synapse Analytics sorunlarını gözden geçirin.
JSON görünümleri
Görünümler, dosyalardan getirilen sonuç kümesinin üzerinde fazladan işlem yapmanız gerekiyorsa iyi bir seçimdir. JSON belgelerindeki değerleri ayıklamak için JSON işlevlerini uygulamamız gereken JSON dosyalarını ayrıştırma örneği verilebilir:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
İşlev, OPENJSON JSONL dosyasındaki her satırı ayrıştırarak satır başına metin biçiminde bir JSON belgesi içerir.
Kapsayıcılarda Azure Cosmos DB görünümleri
Kapsayıcıda Azure Cosmos DB analiz depolama alanı etkinleştirildiyse, görünümler Azure Cosmos DB kapsayıcılarının üzerinde oluşturulabilir. Azure Cosmos DB hesap adı, veritabanı adı ve kapsayıcı adı görünümün bir parçası olarak eklenmelidir ve salt okunur erişim anahtarı görünümün başvurduğu veritabanı kapsamlı kimlik bilgilerine yerleştirilmelidir.
Bu örnek betik, bu yönergeleri izleyerek ayarlayabileceğiniz bir veritabanı ve kapsayıcı kullanır.
Önemli
Betikte bu değerleri kendi değerlerinizle değiştirin:
- your-cosmosdb - Cosmos DB hesabınızın adı
- access-key - Cosmos DB hesap anahtarınız
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
Daha fazla bilgi için bkz . Azure Synapse Link'te sunucusuz sql havuzuyla Azure Cosmos DB verilerini sorgulama.
Bir görünüm kullanın
Sorgulardaki görünümleri, SQL Server sorgularında görünümleri kullanırken olduğu gibi kullanabilirsiniz.
Aşağıdaki sorgu, Görünüm oluşturma bölümünde oluşturduğumuz population_csv görünümünü kullanmayı gösterir. 2019'da nüfuslarıyla birlikte ülke/bölge adlarını azalan düzende döndürür.
Note
Oluşturduğunuz veritabanını kullanmak için sorgudaki ilk satırı ([mydbname] gibi) değiştirin.
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
Görünümü sorguladığınızda hatalarla veya beklenmeyen sonuçlarla karşılaşabilirsiniz. Bu, görünümün değiştirilmiş veya artık mevcut olmayan sütunlara veya nesnelere başvurduğunu gösterir. Görünüm tanımını, temel alınan şema değişiklikleriyle uyumlu olacak şekilde el ile ayarlamanız gerekir.
İlgili içerik
Farklı dosya türlerini sorgulama hakkında bilgi için Tek CSV dosyasını sorgulama, Parquet dosyalarını sorgulama ve JSON dosyalarını sorgulama makalelerine bakın.