Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Tip
Microsoft Fabric Data Warehouse geleceğe hazır mimariye, yerleşik yapay zekaya ve yeni özelliklere sahip data lake foundation üzerinde kurumsal ölçekli ilişkisel bir ambardır. Veri ambarı konusunda yeniyseniz Fabric Data Warehouse ile başlayın. Mevcut özel SQL havuzu iş yükleri, veri bilimi, gerçek zamanlı analiz ve raporlama genelinde yeni özelliklere erişmek için Fabric yükseltilebilir.
Bu makalede, Delta Lake dosyalarını okumak için sunucusuz Synapse SQL havuzunu kullanarak sorgu yazmayı öğreneceksiniz. Delta Lake, APACHE Spark ve büyük veri iş yüklerine ACID (bölünmezlik, tutarlılık, yalıtım ve dayanıklılık) işlemleri getiren açık kaynaklı bir depolama katmanıdır. Delta lake tablolarını sorgulama videosundan daha fazla bilgi edinebilirsiniz.
Önemli
Sunucusuz SQL havuzları Delta Lake 1.0 sürümünü sorgulayabilir. Delta Lake 1.2 sürümünden bu yana sunulan değişiklikler (sütunları yeniden adlandırma gibi) sunucusuz olarak desteklenmez. Delta'nın daha yüksek sürümlerini silme vektörleri, v2 denetim noktaları ve diğerleriyle kullanıyorsanız Lakehouses için Microsoft Fabric SQL uç noktası gibi diğer sorgu altyapısını kullanmayı düşünmelisiniz.
Synapse çalışma alanında sunucusuz SQL havuzu, Delta Lake biçiminde depolanan verileri okumanızı ve raporlama araçlarına sunmanızı sağlar. Sunucusuz SQL havuzu Apache Spark, Azure Databricks veya Delta Lake biçiminin başka bir üreticisi kullanılarak oluşturulan Delta Lake dosyalarını okuyabilir.
Azure Synapse'teki Apache Spark havuzları, veri mühendislerinin Scala, PySpark ve .NET kullanarak Delta Lake dosyalarını değiştirmesine olanak tanır. Sunucusuz SQL havuzları, veri analistlerinin veri mühendisleri tarafından oluşturulan Delta Lake dosyalarıyla ilgili raporlar oluşturmasına yardımcı olur.
Önemli
Sunucusuz SQL havuzunu kullanarak Delta Lake biçimini sorgulama, genel erişime açık işlevselliktir. Ancak Spark Delta tablolarını sorgulama işlemi hala genel önizleme aşamasındadır ve üretime hazır değildir. Spark havuzları kullanılarak oluşturulan Delta tablolarını sorgularsanız karşılaşabileceğiniz bilinen sorunlar vardır. Sunucusuz SQL havuzu kendi kendine yardım bölümünde bilinen sorunlara bakın.
Önkoşullar
Önemli
Veri kaynakları yalnızca özel veritabanlarında oluşturulabilir (ana veritabanında veya Apache Spark havuzlarından çoğaltılan veritabanlarında oluşturulmaz).
Bu makaledeki örnekleri kullanmak için aşağıdaki adımları tamamlamanız gerekir:
- NYC Yellow Taxi depolama hesabına referans veren bir veri kaynağıyla bir veritabanı oluşturun.
- 1. adımda oluşturduğunuz veritabanında kurulum betiğini yürüterek nesneleri başlatın. Bu kurulum betiği, bu örneklerde kullanılan veri kaynaklarını, veritabanı kapsamlı kimlik bilgilerini ve dış dosya biçimlerini oluşturur.
Veritabanınızı oluşturduysanız ve bağlamı veritabanınıza geçirdiyseniz (bir sorgu düzenleyicisinde veritabanını seçmek için USE database_name deyimi veya açılır menü kullanarak), veri kümenizin kök URI'sini içeren dış veri kaynağınızı oluşturabilir ve bunu Delta Lake dosyalarını sorgulamak için kullanabilirsiniz. Örneğin:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Bir veri kaynağı SAS anahtarı veya özel kimlikle korunuyorsa, veri kaynağını veritabanı kapsamlı kimlik bilgileriyle yapılandırabilirsiniz.
Depolamanın kök klasörüne işaret eden konuma sahip bir dış veri kaynağı oluşturabilirsiniz. Dış veri kaynağını oluşturduktan sonra, veri kaynağını ve işlevdeki OPENROWSET dosyanın göreli yolunu kullanın. Bu şekilde dosyalarınızda tam mutlak URI'yi kullanmanız gerekmez. Daha sonra depolama konumuna erişmek için özel kimlik bilgileri de tanımlayabilirsiniz.
Delta Lake klasörünü okuma
Önemli
Örnek veri kaynaklarını ve tabloları ayarlamak için önkoşullardaki kurulum betiğini kullanın.
OPENROWSET işlevi, kök klasörünüzün URL'sini sağlayarak Delta Lake dosyalarının içeriğini okumanızı sağlar.
Dosyanızın DELTA içeriğini görmenin en kolay yolu, OPENROWSET işlevinin dosya URL'sini sağlamak ve biçimi belirtmektirDELTA. Dosya genel kullanıma açıksa veya Microsoft Entra kimliğiniz bu dosyaya erişebiliyorsa, aşağıdaki örnekte gösterilen gibi bir sorgu kullanarak dosyanın içeriğini görebilmeniz gerekir:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Sütun adları ve veri türleri Delta Lake dosyalarından otomatik olarak okunur. işlevi, OPENROWSET dize sütunları için VARCHAR(1000) gibi en iyi tahmin türlerini kullanır.
İşlevdeki OPENROWSET URI, adlı _delta_logbir alt klasör içeren kök Delta Lake klasörüne başvurmalıdır.
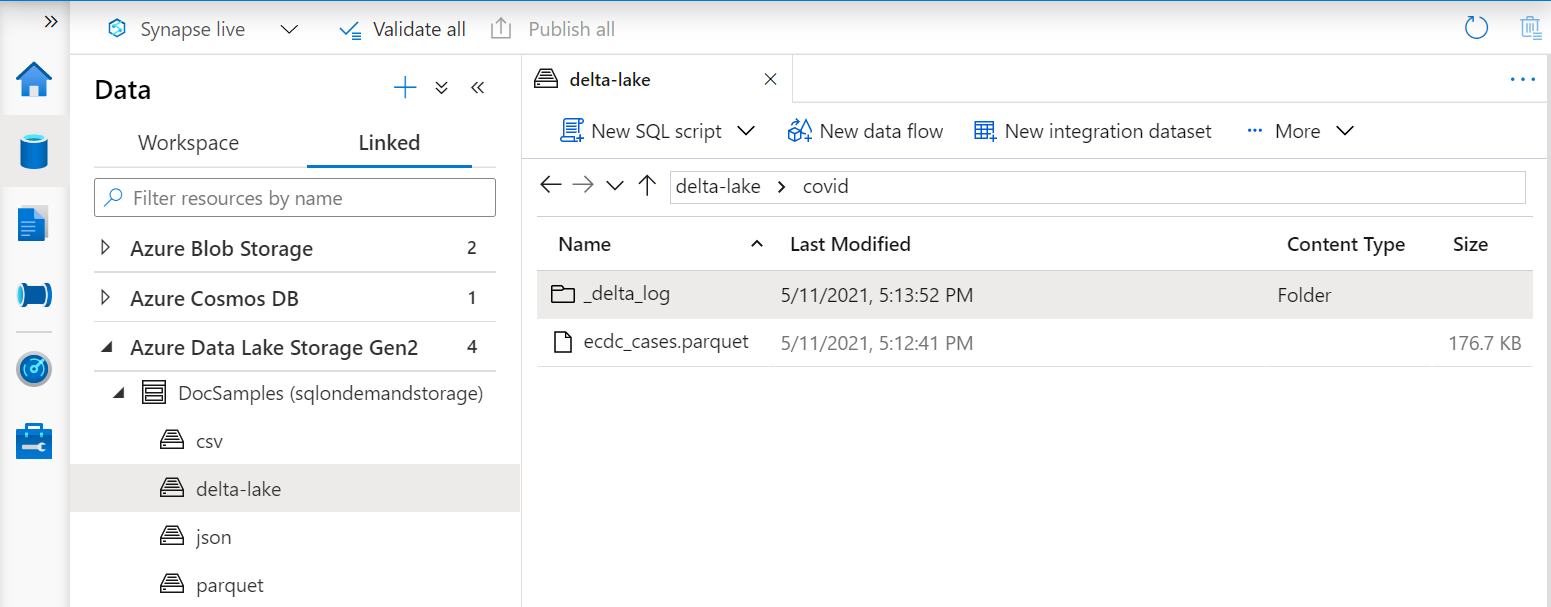
Bu alt klasöre sahip değilseniz Delta Lake biçimini kullanmazsınız. Aşağıdaki örnek Apache Spark Python betiği gibi bir betik kullanarak klasördeki düz Parquet dosyalarınızı Delta Lake biçimine dönüştürebilirsiniz:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Sorgularınızın performansını geliştirmek için the WITH clause içinde açık türler belirtmeyi göz önünde bulundurun.
Not
Sunucusuz Synapse SQL havuzu, sütunları ve bunların türlerini otomatik olarak belirlemek için şema çıkarımı kullanır. Şema çıkarımı kuralları Parquet dosyaları için kullanılanla aynıdır. Delta Lake tür eşlemesini SQL yerel türüyle eşleştirmek için Parquet tür eşlemesini denetleyin.
Dosyanıza erişebildiğinizden emin olun. Dosyanız SAS anahtarı veya özel Azure kimliği ile korunuyorsa, sql oturum açma bilgileri için sunucu düzeyinde bir kimlik bilgisi ayarlamanız gerekir.
Önemli
Delta Lake dosyalarındaki dize değerleri UTF-8 kodlaması kullanılarak kodlandığından UTF-8 veritabanı harmanlaması (örneğin Latin1_General_100_BIN2_UTF8) kullandığınızdan emin olun.
Delta Lake dosyasındaki metin kodlaması ile harmanlama arasındaki uyuşmazlık beklenmeyen dönüştürme hatalarına neden olabilir.
Aşağıdaki T-SQL deyimini kullanarak geçerli veritabanının varsayılan harmanlamasını kolayca değiştirebilirsiniz:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; Harmanlamalar hakkında daha fazla bilgi için bkz . Synapse SQL için desteklenen harmanlama türleri.
Şemayı açıkça belirtin
OPENROWSET , yan tümcesini kullanarak WITH dosyadan hangi sütunları okumak istediğinizi açıkça belirtmenizi sağlar:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Sonuç kümesi şemasının açık belirtimiyle, tür boyutlarını en aza indirip kötümser VARCHAR(1000) yerine dize sütunları için daha kesin VARCHAR(6) türlerini kullanabilirsiniz. Türlerin küçültülmesi, sorgularınızın performansını önemli ölçüde artırabilir.
Önemli
Veritabanı düzeyinde bir UTF-8 harmanlaması ayarlayın veya Latin1_General_100_BIN2_UTF8 tüm dize sütunları için WITH örneğinde olduğu gibi açıkça bir UTF-8 harmanlaması belirttiğinizden emin olun.
Dosyadaki metin kodlaması ile dize sütunu harmanlaması arasındaki uyuşmazlık beklenmeyen dönüştürme hatalarına neden olabilir.
Aşağıdaki T-SQL deyimini kullanarak geçerli veritabanının varsayılan harmanlamasını kolayca değiştirebilirsiniz:
alter database current collate Latin1_General_100_BIN2_UTF8 Aşağıdaki tanımı kullanarak sütun türlerinde harmanlamayı kolayca ayarlayabilirsiniz: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Veri kümesi
Bu örnekte NYC Yellow Taxi veri kümesi kullanılmıştır. Özgün PARQUET veri kümesi biçime DELTA dönüştürülür ve DELTA sürüm örneklerde kullanılır.
Bölümlenmiş verileri sorgulama
Bu örnekte sağlanan veri kümesi ayrı alt klasörlere bölünür (bölümlenir).
Parquet'in aksine, işlevini kullanarak FILEPATH belirli bölümleri hedeflemeniz gerekmez. , OPENROWSET Delta Lake klasör yapınızdaki bölümleme sütunlarını belirler ve bu sütunları kullanarak verileri doğrudan sorgulamanızı sağlar. Bu örnekte, 2017'nin ilk üç ayı için yıla, aya ve payment_type göre ücret tutarları gösterilmektedir.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
OPENROWSET işlevi, where yan tümcesindeki year ve month ile eşleşmeyen bölümleri ortadan kaldıracaktır. Bu dosya/bölüm ayıklama tekniği veri kümenizi önemli ölçüde azaltır, performansı artırır ve sorgunun maliyetini azaltır.
İşlevdeki OPENROWSET klasör adı (yellow bu örnekte), LOCATION veri kaynağında DeltaLakeStorage kullanılarak birleştirilir ve içerisinde _delta_log adlı bir alt klasör bulunan kök Delta Lake klasörüne başvurmalıdır.
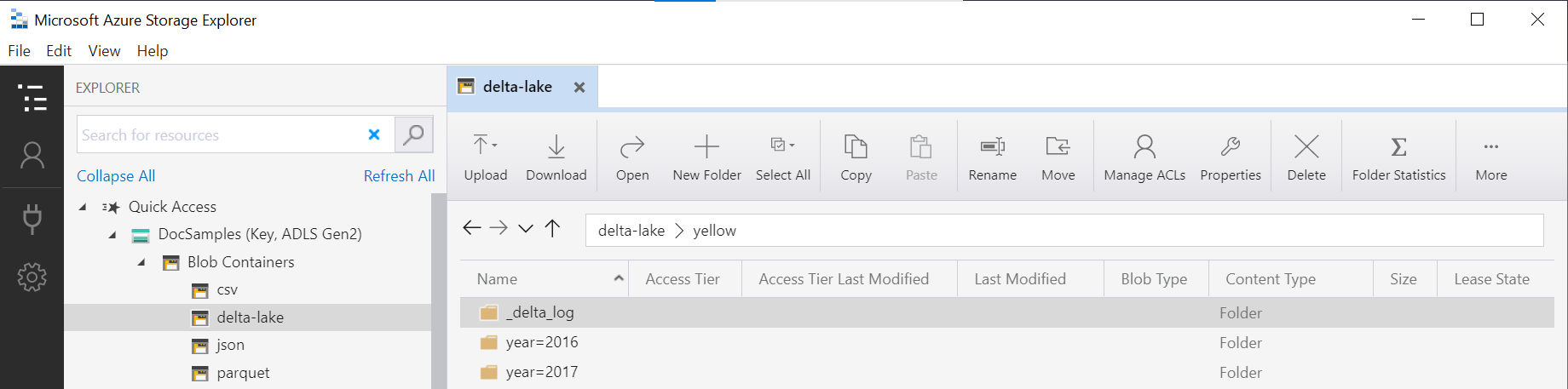
Bu alt klasöre sahip değilseniz Delta Lake biçimini kullanmazsınız. Aşağıdaki Apache Spark Python betiğini kullanarak klasördeki düz Parquet dosyalarınızı Delta Lake biçimine dönüştürebilirsiniz:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
İşlevin ikinci bağımsız değişkeni, klasör deseninin DeltaTable.convertToDeltaLake (bu örnekte) bir parçası olan bölümleme sütunlarını (year=*/month=* yıl ve ay) ve bunların türlerini temsil eder.
Sınırlamalar
- Synapse sunucusuz SQL havuzu kendi kendine yardım sayfasındaki sınırlamaları ve bilinen sorunları gözden geçirin.
İlgili içerik
Sonraki makaleye ilerleyerek Parquet iç içe türlerini sorgulamayı öğrenin. Delta Lake çözümü oluşturmaya devam etmek istiyorsanız Delta Lake klasöründe görünümler veya dış tablolar oluşturmayı öğrenin.