Veri birleştirme en iyi uygulamaları
Verilerinizi bir müşteri profilinde birleştirmek için kurallar ayarlarken şu en iyi uygulamaları göz önünde bulundurun:
Birleştirme ve tam eşleştirme için zaman arasında denge kurun. Mümkün olan her eşleşmeyi yakalamaya çalışmak, birçok kurala ve birleşmenin uzun zaman almasına yol açar.
Kuralları aşamalı olarak ekleyin ve sonuçları izleyin. Maç sonucunu iyileştirmeyen kuralları kaldırın.
Her müşterinin tek bir satırda temsil edilmesi için her tabloyu tekilleştirin.
Verilerin nasıl girildiğine ilişkin varyasyonları standartlaştırmak için normalleştirmeyi kullanın (örneğin, Cadde - St - St. .
Yazım hatalarını ve ve gibi hataları düzeltmek için bulanık eşleştirmeyi bob@contoso.com stratejik olarak kullanın bob@contoso.cm. Bulanık eşleşmelerin çalıştırılması, tam eşleşmelerden daha uzun sürer. Bulanık eşleştirme için harcanan ekstra sürenin ek eşleşme oranına değip değmediğini görmek için her zaman test edin.
Tam eşleşme ileeşleşmelerin kapsamını daraltın. Belirsiz koşullara sahip her kuralın en az bir tam eşleşme koşuluna sahip olduğundan emin olun.
Çok tekrarlanan veriler içeren sütunları eşleştirmeyin. Belirsiz eşleşen sütunların, formun varsayılan değeri olan "Firstname" gibi sık sık tekrarlanan değerlere sahip olmadığından emin olun.
Birleştirme performansı
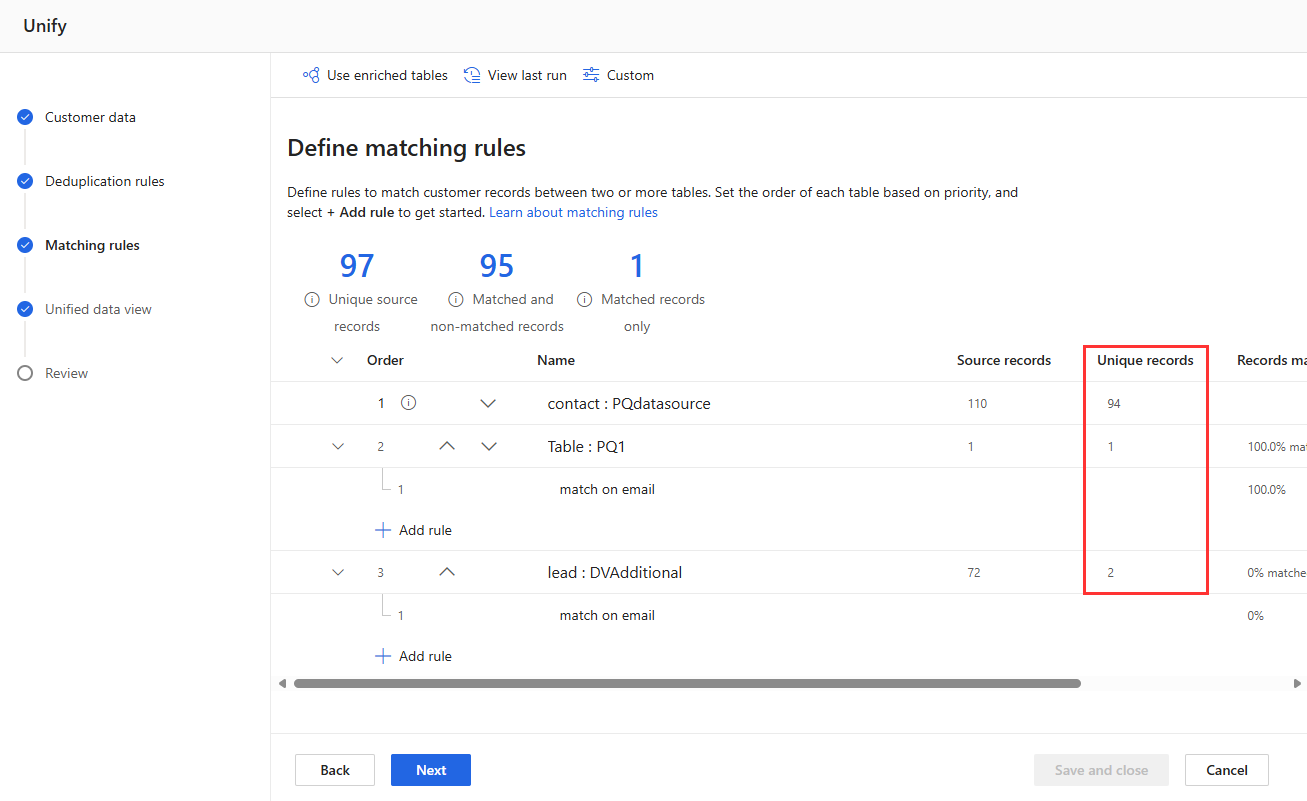
Her kuralın çalışması zaman alır. Her tabloyu diğer tüm tablolarla karşılaştırma veya olası her kayıt eşleşmesini yakalamaya çalışma gibi desenler, birleştirme işleme sürelerinin uzun olmasına neden olabilir. Ayrıca, her tabloyu bir temel tabloyla karşılaştıran bir plan üzerinde daha fazla eşleşme varsa çok az döndürür.
En iyi yaklaşım, her bir tabloyu birincil tablonuzla karşılaştırmak gibi, gerekli olduğunu bildiğiniz temel bir kurallar kümesiyle başlamaktır. Birincil tablonuz, en eksiksiz ve doğru verilere sahip tablo olmalıdır. Bu tablo, Eşleştirme kuralları birleştirme adımında en üstte sıralanmalıdır.
Aşamalı olarak birkaç kural ekleyin ve değişikliklerin ne kadar sürdüğünü ve sonuçlarınızın iyileşip iyileşmediğini görün. Ayarlar Sistem Durumu'na >gidin ve her birleştirme çalıştırması için tekilleştirme ve eşleştirmenin ne kadar sürdüğünü görmek için Eşleştir'i>seçin .
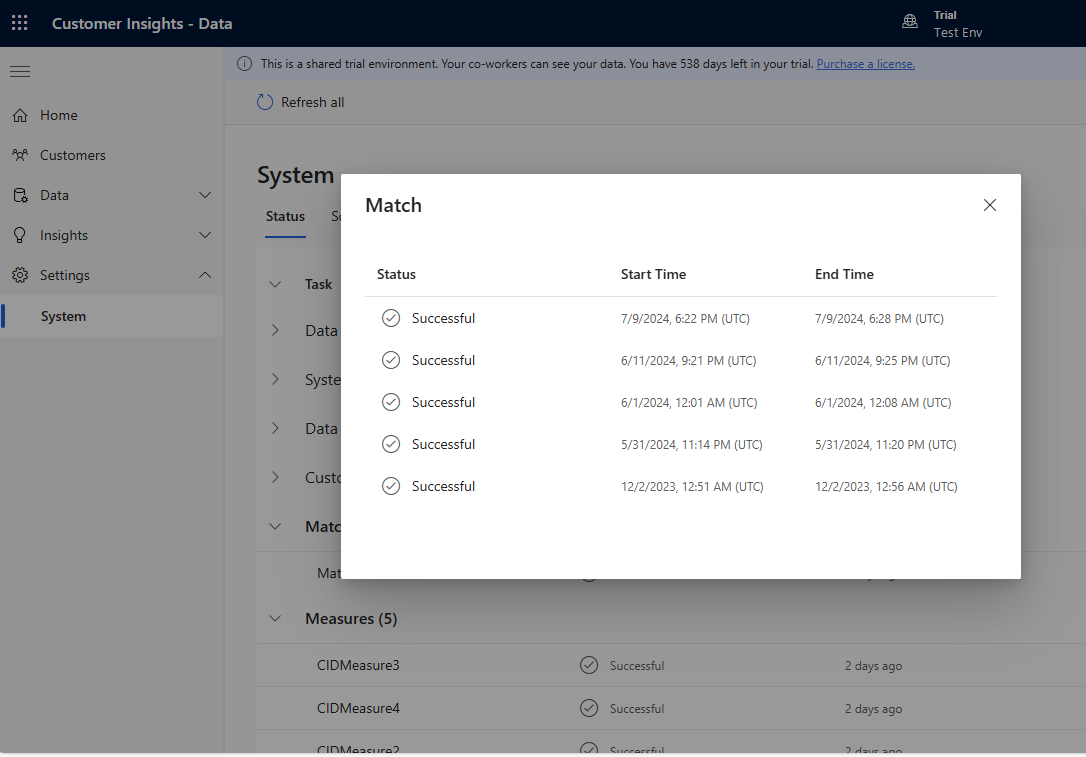
Tekil kayıt sayısının değişip değişmediğini görmek için Tekilleştirme kuralları ve Eşleştirme kuralları sayfalarındaki kural istatistiklerini görüntüleyin. Yeni bir kural bazı kayıtlarla eşleşirse ve benzersiz kayıt sayısı değişmezse, önceki bir kural bu eşleşmeleri tanımlar.
Deduplication
Her tablodaki tek bir satırın her müşteriyi temsil etmesi için bir tablodaki yinelenen müşteri kayıtlarını kaldırmak için yinelenenleri kaldırma kurallarını kullanın. İyi bir kural benzersiz bir müşteri tanımlar.
Bu basit örnekte, 1, 2 ve 3 numaralı kayıtlar bir e-posta veya telefon numarasını paylaşır ve aynı kişiyi temsil eder.
| Kimlik | Adı | Phone | E-posta adresi |
|---|---|---|---|
| Kategori 1 | Kişi 1 | (425) 555-1111 | AAA@A.com |
| 2 | Kişi 1 | (425) 555-1111 | BBB@B.com |
| 3 | Kişi 1 | (425) 555-2222 | BBB@B.com |
| 4 | Kişi 2 | (206) 555-9999 | Person2@contoso.com |
Sadece aynı ismi kullanan farklı kişilerle eşleşen isimlerle eşleştirmek istemiyoruz.
Ad ve Telefon'u kullanarak, 1 ve 2 numaralı kayıtlarla eşleşen Kural 1'i oluşturun.
Ad ve E-posta'yı kullanarak, 2 ve 3 numaralı kayıtlarla eşleşen Kural 2'yi oluşturun.
1. Kural ve 2. Kural birleşimi, 2. kaydı paylaştıklarından tek bir eşleşme grubu oluşturur.
Müşterilerinizi benzersiz bir şekilde tanımlayan kuralların ve koşulların sayısına siz karar verirsiniz. Kesin kurallar, eşleştirmek için sahip olduğunuz verilere, verilerinizin kalitesine ve veri tekilleştirme işleminin ne kadar kapsamlı olmasını istediğinize bağlıdır.
Kazanan ve alternatif kayıtlar
Kurallar çalıştırıldıktan ve yinelenen kayıtlar tanımlandıktan sonra, yinelenenleri kaldırma işlemi bir "Kazanan satırı" seçer. Kazanan olmayan satırlara "Alternatif satırlar" adı verilir. Alternatif satırlar, diğer tablolardaki kayıtları kazanan satırla eşleştirmek için Eşleştirme kuralları birleştirme adımında kullanılır. Satırlar, kazanan satırın yanı sıra alternatif satırlardaki veriyle eşleştirilir.
Tabloya bir kural ekledikten sonra, Birleştir tercihleri aracılığıylakazanan satır olarak hangi satırın seçileceğini yapılandırabilirsiniz. Birleştirme tercihleri tablo başına ayarlanır. Hangi birleştirme ilkesi seçilirse seçilsin, kazanan satır için eşitlik varsa, veri sırasındaki ilk satır eşitliği bozan olarak kullanılır.
Normalleştirme
Daha iyi eşleştirme için verileri standartlaştırmak üzere normalleştirmeyi kullanın. Normalleştirme, büyük veri kümelerinde iyi performans gösterir.
Normalleştirilmiş veriler yalnızca müşteri kayıtlarını daha etkili şekilde eşleştirmek için karşılaştırma amacıyla kullanılır. Son birleştirilmiş müşteri profili çıktınızdaki verileri değiştirmez.
| Normalleştirme | Örnekler |
|---|---|
| Sayılar | Sayıları temsil eden birçok Unicode sembolünü basit sayılara dönüştürür. Örnekler: ❽ ve VIII. her ikisi de 8 rakamına normalleştirilmiştir. Not: Simgelerin, Unicode Point Biçimi'nde kodlanması gerekir. |
| Semboller | Simgeleri ve özel karakterleri kaldırır. Örnekler: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| Metinden küçük harfe | Büyük harf karakterleri küçük harfe dönüştürür. Örnek: "THIS Is aN EXamplE", "bu bir örnektir"e dönüştürülür |
| Tür: Telefon | Çeşitli biçimlerdeki telefonları basamaklara dönüştürür ve ülke kodları ile dahili numaraların sunulma biçimindeki farklılıkları dikkate alır. Örnek: +01 425.555.1212 = 1 (425) 555-1212 |
| Tür: Ad | 500'den fazla yaygın ad çeşitlemesi ve başlığını dönüştürür. Örnekler: "debby" -> "deborah" "prof" ve "professor" -> "Prof". |
| Tür: Adres | Adreslerin ortak kısımlarını dönüştürür Örnekler: "street" -> "st" ve "northwest" -> "nw" |
| Tür: Kuruluş | "Co", "corp", "corporation" ve "ltd" gibi yaklaşık 50 şirket adı "gürültü kelimesini" kaldırır. |
| Unicode - ASCII | Unicode karakterlerini ASCII harf eşdeğerlerine dönüştürür Örnek: "à", "á", "â", "À", "Á", "Â", "Ã", "Ä", "Ⓐ" ve "A", "a" olarak dönüştürülür. |
| Boşluk | Tüm boşlukları kaldırır |
| Diğer ad eşlemesi | Her zaman tam eşleşme olarak kabul edilmesi gereken dizeleri belirtmek için kullanılabilecek özel bir dize çiftleri listesi yüklemenize olanak tanır. Eşleşmesi gerektiğini düşündüğünüz belirli veri örnekleriniz varsa ve diğer normalleştirme modellerinden birini kullanarak eşleştiremiyorsanız diğer ad eşlemesini kullanın. Örnek: Scott ve Scooter veya MSFT ve Microsoft. |
| Özel atlama | Hiçbir zaman eşleşmemesi gereken dizeleri belirtmek için kullanılabilecek özel bir dize listesi yüklemenize olanak tanır. Özel atlama, sahte bir telefon numarası veya sahte bir e-posta gibi yok sayılması gereken ortak değerlere sahip verileriniz olduğunda kullanışlıdır. Örnek: Hiçbir zaman 555-1212 numaralı telefonu eşleştirmeyin veya test@contoso.com |
Tam eşleşme
Bir eşleşme olarak kabul edilmek için iki dizenin ne kadar yakın olması gerektiğini belirlemek için kesinlik kullanın. Varsayılan hassasiyet ayarı tam bir eşleşme gerektirir. Başka herhangi bir değer, bu koşul için belirsiz eşleştirmeyi etkinleştirir.
Duyarlık; düşük (%30 eşleştirme), orta (%60 eşleştirme) ve yüksek (%80 eşleştirme) olarak ayarlanabilir. Veya hassasiyeti %1'lik artışlarla özelleştirebilir ve ayarlayabilirsiniz.
Tam eşleşme koşulları
Belirsiz eşleşmeler için daha küçük bir değer kümesi elde etmek için önce tam eşleşme koşulları çalıştırılır. Etkili olabilmesi için tam eşleştirme koşullarında makul derecede benzersizliğin olması gerekir. Örneğin, tüm müşterileriniz aynı ülkede/bölgede yaşıyorsa, ülkede/bölgede tam bir eşleşme olması kapsamı daraltmaya yardımcı olmaz.
Tam ad, e-posta, telefon veya adres alanları gibi sütunlar iyi bir benzersizliğe sahiptir ve tam eşleşme olarak kullanmak için harika sütunlardır.
Tam eşleşme koşulu için kullandığınız sütunun, bir form tarafından yakalanan varsayılan "Firstname" değeri gibi sık sık tekrarlanan herhangi bir değer içermediğinden emin olun. Müşteri içgörüleri, en çok yinelenen değerler hakkında içgörü sağlamak için veri sütunlarının profilini oluşturabilir. Azure Data Lake (Common Data Model veya Delta biçimi kullanarak), bağlantılarda ve Synapse'de veri profili oluşturmayı etkinleştirebilirsiniz. Veri profili, veri kaynağı bir sonraki yenilemesinde çalıştırılır. Daha fazla bilgi için Veri profili oluşturma'ya gidin.
Bulanık eşleştirme
Yakın olan ancak yazım hataları veya diğer küçük varyasyonlar nedeniyle kesin olmayan dizeleri eşleştirmek için bulanık eşleştirmeyi kullanın. Tam eşleşmelerden daha yavaş olduğu için bulanık eşleştirmeyi stratejik olarak kullanın. Belirsiz koşullara sahip herhangi bir kuralda en az bir tam eşleşme koşulu olduğundan emin olun.
Bulanık eşleştirme, Suzzie ve Suzanne gibi ad varyasyonlarını yakalamak için tasarlanmamıştır. Bu varyasyonlar, Normalleştirme deseni Türü: Ad veya müşterilerin eşleşme olarak değerlendirmek istedikleri ad varyasyonları listesini girebilecekleri özel Diğer Ad eşleştirmesi ile daha iyi yakalanır.
FirstName ve Telefon eşleşmesi gibi bir kurala koşullar ekleyebilirsiniz. Belirli bir kuraldaki koşullar "VE" koşullarıdır. Satırların eşleşmesi için her koşulun eşleşmesi gerekir. Ayrı kurallar "VEYA" koşullarıdır. Kural 1 satırlarla eşleşmezse, satırlar Kural 2 ile karşılaştırılır.
Not
Benzer öğe eşleştirme için yalnızca dize veri türü sütunları kullanabilir. Tamsayı, çift veya datetime gibi diğer veri türlerine sahip sütunlar için duyarlık alanı salt okunurdur ve tam eşleşmeye ayarlanır.
Benzer öğe eşleştirme hesaplamaları
Bulanık eşleşmeler, iki dize arasındaki düzenleme mesafesi puanı hesaplanarak belirlenir. Skor duyarlık eşiğini karşılar veya aşarsa, dizeler bir eşleşme olarak kabul edilir.
Düzenleme mesafesi, bir karakter ekleyerek, silerek veya değiştirerek bir dizeyi diğerine dönüştürmek için gereken düzenleme sayısıdır.
Örneğin, "Jacqueline" ve "Jaclyne" dizeleri, q, u, e, i ve e karakterlerini kaldırdığımızda ve y karakterini eklediğimizde beş düzenleme mesafesine sahiptir.
Düzenleme mesafesi puanını hesaplamak için şu formülü kullanın: (Temel dize uzunluğu – Mesafeyi Düzenle) / Temel dize uzunluğu.
| Temel dize | Karşılaştırma dizesi | Puan |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=.6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0,857 |
| franklin | frank | (8-3) / 8 = 0.625 |