Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğretici, Microsoft Fabric'te Synapse Veri Bilimi iş akışının uçtan uca bir örneğini sunar. Senaryo, banka müşterilerinin ayrılıp ayrılmayacağını tahmin etmek için bir model oluşturur. Değişim oranı veya zarar oranı, banka müşterilerinin bankayla işlerini sonlandırma oranını içerir.
Bu öğretici şu adımları kapsar:
- Özel kitaplıkları yükleme
- Verileri yükleme
- Verileri keşifsel veri analizi yoluyla anlayın ve işleyin, ardından Fabric Data Wrangler özelliğinin kullanımını gösterin.
- Makine öğrenmesi modellerini eğitmek ve MLflow ve Fabric Autologging özellikleriyle denemeleri izlemek için scikit-learn ve LightGBM kullanma
- Son makine öğrenmesi modelini değerlendirme ve kaydetme
- Power BI görselleştirmeleriyle model performansını gösterme
Önkoşullar
bir Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz Microsoft Fabric deneme sürümü için kaydolun.
Microsoft Fabricoturum aç.
Ana sayfanızın sol alt tarafındaki deneyim değiştiriciyi kullanarak Fabric'e geçiş yapın.

- Gerekirse, Microsoft Fabric'te göl evi oluşturmabölümünde açıklandığı gibi bir Microsoft Fabric lakehouse oluşturun.
Bir defterde takip edin
Not defterinde izleyebileceğiniz şu seçeneklerden birini belirleyebilirsiniz:
- Yerleşik not defterini açın ve çalıştırın.
- GitHub'dan not defterinizi karşıya yükleyin.
Yerleşik not defterini açma
Örnek Müşteri kaybı defteri bu öğreticiye eşlik eder.
Bu öğreticinin örnek not defterini açmak için Sisteminizi veri bilimi öğreticilerine hazırlamabaşlığındaki yönergeleri izleyin.
Kodu çalıştırmaya başlamadan önce not defterine bir göl evi eklediğinizden emin olun.
Not defterini GitHub'dan içeri aktarma
AIsample - Banka Müşterisi Churn.ipynb not defteri bu öğreticiye eşlik eder.
Bu öğreticide eşlik eden not defterini açmak için, not defterini çalışma alanınıza aktarmak için sisteminizi veri bilimi öğreticilerine hazırlama başlığındaki yönergeleri izleyin.
Bu sayfadaki kodu kopyalayıp yapıştırmayı tercih ederseniz, yeni bir not defteri oluşturabilirsiniz.
Kod çalıştırmaya başlamadan önce not defteri bir göl evi eklemeyi unutmayın.
1. Adım: Özel kitaplıkları yükleme
Makine öğrenmesi modeli geliştirme veya geçici veri analizi için Apache Spark oturumunuz için hızlı bir şekilde özel bir kitaplık yüklemeniz gerekebilir. Kitaplıkları yüklemek için iki seçeneğiniz vardır.
- Yalnızca geçerli not defterinizde bir kitaplık yüklemek için not defterinizdeki satır içi yükleme özelliklerini (
%pipveya%conda) kullanın. - Alternatif olarak, bir Doku ortamı oluşturabilir, ortak kaynaklardan kitaplıklar yükleyebilir veya özel kitaplıklar yükleyebilirsiniz ve çalışma alanı yöneticiniz ortamı çalışma alanı için varsayılan olarak ekleyebilir. Daha sonra ortamdaki tüm kitaplıklar çalışma alanındaki tüm not defterlerinde ve Spark iş tanımlarında kullanılabilir hale gelir. Ortamlar hakkında daha fazla bilgi için bkz. Microsoft Fabric 'da ortam oluşturma, yapılandırma ve kullanma.
Bu öğreticide, not defterinize imblearn kitaplığını yüklemek için %pip install kullanın.
Not
%pip install çalıştırıldıktan sonra PySpark çekirdeği yeniden başlatılır. Diğer hücreleri çalıştırmadan önce gerekli kitaplıkları yükleyin.
# Use pip to install libraries
%pip install imblearn
2. Adım: Verileri yükleme
churn.csv'daki veri kümesi, 10.000 müşterinin değişim sıklığı durumunu ve aşağıdaki 14 özniteliği içerir:
- Kredi puanı
- Coğrafi konum (Almanya, Fransa, İspanya)
- Cinsiyet (erkek, kadın)
- Yaş
- Süre (kişinin o bankada müşteri olduğu yıl sayısı)
- Hesap bakiyesi
- Tahmini maaş
- Müşterinin bankadan satın aldığı ürün sayısı
- Kredi kartı durumu (müşterinin kredi kartı olup olmadığı)
- Etkin üye durumu (kişinin etkin bir banka müşterisi olup olmadığı)
Veri kümesi satır numarası, müşteri kimliği ve müşteri soyadı sütunlarını da içerir. Bu sütunlardaki değerler müşterinin bankadan ayrılma kararını etkilememelidir.
Müşteri banka hesabı kapatma olayı, bu müşteri için değişim oranını tanımlar.
Exited veri kümesindeki sütun müşterinin terkiyle ilgili olarak atıfta bulunur. Bu öznitelikler hakkında çok az bağlama sahip olduğumuzdan, veri kümesi hakkında arka plan bilgilerine ihtiyacımız yoktur. Bu özniteliklerin Exited durumuna nasıl katkı sağlayacağını anlamak istiyoruz.
Bu 10.000 müşteriden yalnızca 2037 müşteri (kabaca 20%) bankadan ayrıldı. Sınıf dengesizliği oranı nedeniyle yapay verilerin oluşturulmasını öneririz. Karışıklık matrisi doğruluğunun dengesiz sınıflandırmayla ilgisi olmayabilir. Precision-Recall Eğrisi Altındaki Alan 'ı (AUPRC) kullanarak doğruluğu ölçmek isteyebiliriz.
- Bu tabloda
churn.csvverilerinin önizlemesi gösterilir:
| Müşteri ID | Soyadı | Kredi Puanı | Coğrafya | Cinsiyet | Yaş | Görev Süresi | Denge | NumOfProducts | HasCrCard | AktifÜyeMi | Tahmini Maaş | Çıkış yapıldı |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Fransa | Dişi | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Tepe | 608 | İspanya | Dişi | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Veri kümesini indirin ve lakehouse'a yükleyin
Bu not defterini farklı veri kümeleriyle kullanabilmek için bu parametreleri tanımlayın:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Bu kod, veri kümesinin genel kullanıma açık bir sürümünü indirir ve ardından bu veri kümesini bir Fabric lakehouse'ta depolar:
Önemli
Not defterine bir lakehouse ekleyin, çalıştırmadan önce. Bunun yapılmaması hataya neden olur.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Not defterini çalıştırmak için gereken süreyi kaydetmeye başlayın:
# Record the notebook running time
import time
ts = time.time()
Göl evinden ham verileri oku
Bu kod, lakehouse'un Dosyalar bölümünden ham verileri okur ve farklı tarih bölümleri için daha fazla sütun ekler. Bölümlenmiş delta tablosunun oluşturulması bu bilgileri kullanır.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Veri kümesinden pandas DataFrame oluşturma
Bu kod, daha kolay işleme ve görselleştirme için Spark DataFrame'i pandas DataFrame'e dönüştürür:
df = df.toPandas()
3. Adım: Keşif veri analizi gerçekleştirme
Ham verileri görüntüleme
displayile ham verileri keşfedin, bazı temel istatistikleri hesaplayın ve grafik görünümlerini gösterin. Öncelikle veri görselleştirmesi için gerekli kitaplıkları içeri aktarmanız gerekir - örneğin, seaborn. Seaborn bir Python veri görselleştirme kitaplığıdır ve veri çerçeveleri ve diziler üzerinde görseller oluşturmak için üst düzey bir arabirim sağlar.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
İlk veri temizleme işlemini gerçekleştirmek için Data Wrangler kullanma
Pandas veri çerçevelerini keşfetmek ve dönüştürmek için Data Wrangler'ı doğrudan not defterinden başlatın. Düzenleme için etkin pandas DataFrame'lerine göz atmak için yatay araç çubuğundan Veri Wrangler açılır listesini seçin. Data Wrangler'da açmak istediğiniz DataFrame'i seçin.
Not
Not defteri çekirdeği meşgulken veri Wrangler açılamaz. Veri Wrangler'ı başlatmadan önce hücre çalıştırılması bitmelidir. Data Wranglerhakkında daha fazla bilgi edinin.

Data Wrangler başlatıldıktan sonra, aşağıdaki görüntülerde gösterildiği gibi veri paneliyle ilgili açıklayıcı bir genel bakış oluşturulur. Genel bakış, DataFrame'in boyutu, eksik değerler vb. hakkında bilgi içerir. Eksik değerlere sahip satırları, yinelenen satırları ve belirli adlara sahip sütunları bırakmak üzere betiği oluşturmak için Data Wrangler'ı kullanabilirsiniz. Ardından betiği bir hücreye kopyalayabilirsiniz. Sonraki hücre kopyalanan betiği gösteriyor.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Öznitelikleri belirleme
Bu kod kategorik, sayısal ve hedef öznitelikleri belirler:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Beş sayılık özeti göster
Beş sayılık özeti göstermek için kutu çizimlerini kullanma
- en düşük puan
- birinci çeyrek
- Medyan
- üçüncü çeyrek
- maksimum puan
sayısal öznitelikler için.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
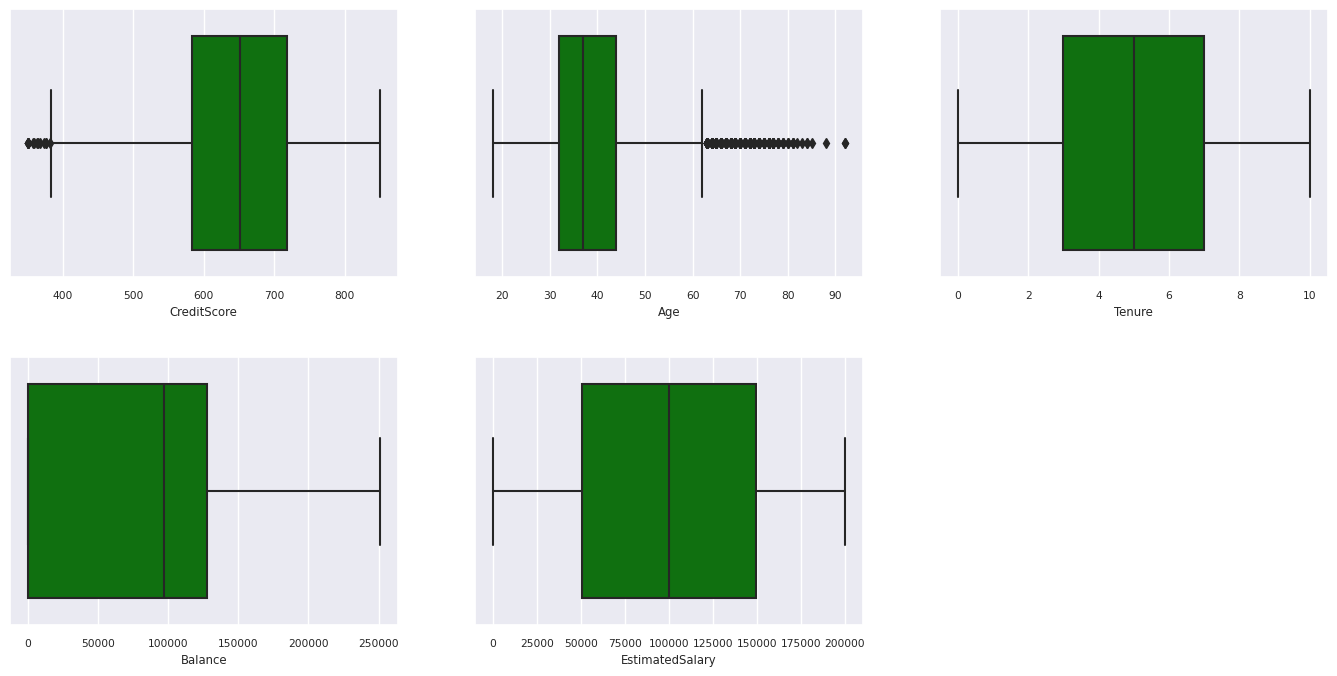
Çıkmış ve çıkmamış müşterilerin dağılımını göster.
Kategorik öznitelikler genelinde çıkışlı ve çıkışsız müşterilerin dağılımını gösterin:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
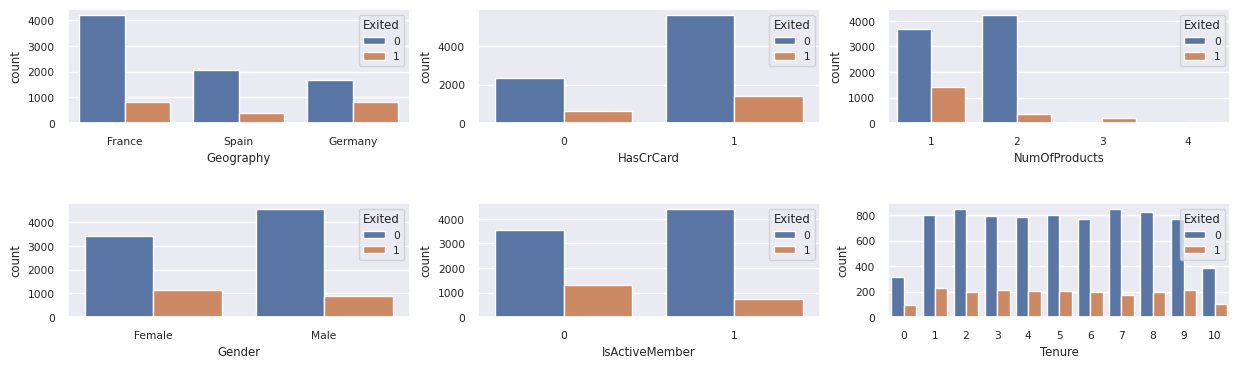
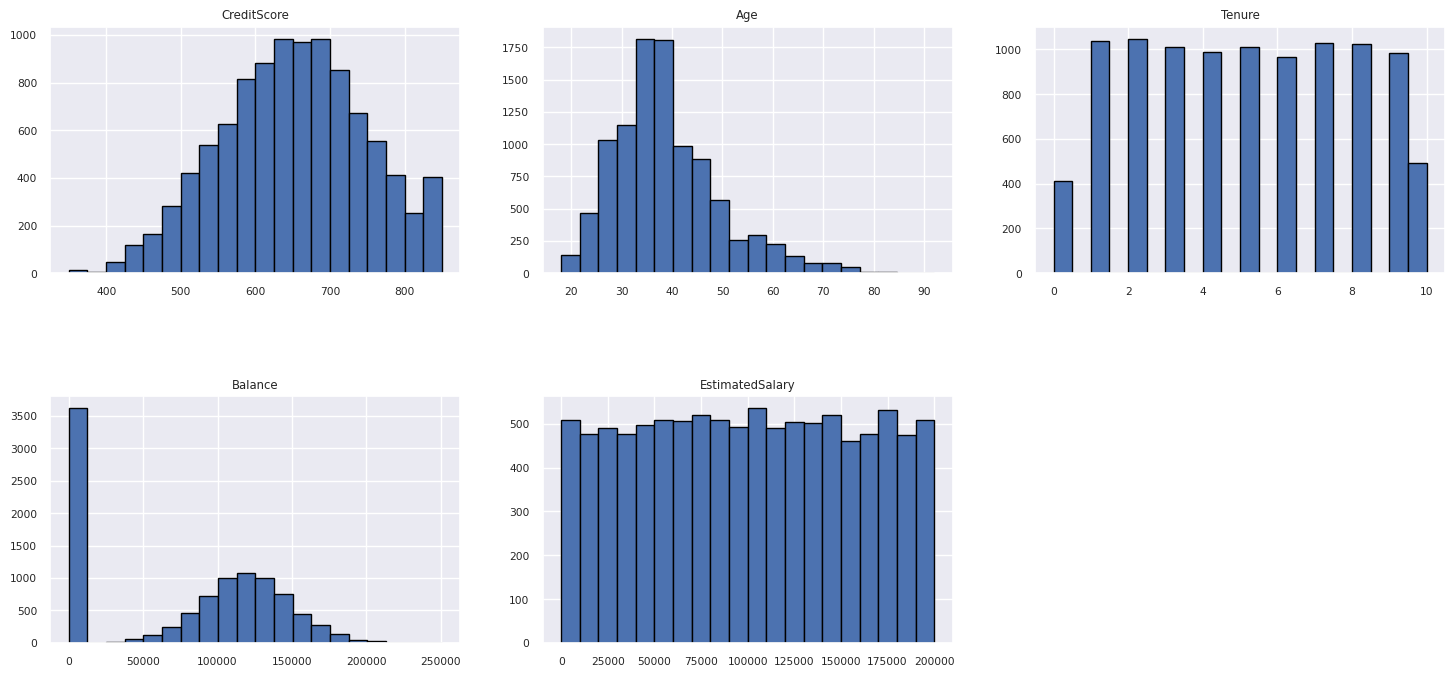
Sayısal özniteliklerin dağılımını gösterme
Sayısal özniteliklerin sıklık dağılımını göstermek için histogram kullanın:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Özellik mühendisliği gerçekleştirme
Bu özellik mühendisliği, geçerli öznitelikleri temel alarak yeni öznitelikler oluşturur:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
One-hot kodlama yapmak için Veri Wrangler'ı kullanın
Data Wrangler'ı başlatmak için daha önce açıklandığı gibi aynı adımlarla, tek etkin kodlama gerçekleştirmek için Data Wrangler'ı kullanın. Bu hücre, one-hot encoding için kopyalanan oluşturulan betiği gösterir.


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Power BI raporunu oluşturmak için delta tablosu oluşturma
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Keşif veri analizinden gözlemlerin özeti
- Müşterilerin çoğu Fransa'dan. İspanya, Fransa ve Almanya'ya kıyasla en düşük dalgalanma oranına sahip.
- Çoğu müşterinin kredi kartı vardır
- Bazı müşteriler 60 yaşın üzerindedir ve kredi puanları 400'ün altındadır. Ancak aykırı değerler olarak düşünülemezler
- Çok az müşterinin ikiden fazla banka ürünü var
- Etkin olmayan müşterilerin değişim sıklığı daha yüksek
- Cinsiyet ve süre yıllarının müşterinin banka hesabını kapatma kararı üzerinde çok az etkisi vardır
4. Adım: Model eğitimi ve izlemesi gerçekleştirme
Veriler hazır olduğunda, şimdi modeli tanımlayabilirsiniz. Bu not defterine rastgele orman ve LightGBM modelleri uygulayın.
Scikit-learn ve LightGBM kitaplıklarını kullanarak birkaç kod satırı içeren modelleri uygulayın. Ayrıca, denemeleri izlemek için MLflow ve Fabric Autologging'i kullanın.
Bu kod örneği, delta tablosunu lakehouse'dan yükler. Lakehouse'u kaynak olarak kullanan diğer delta tablolarını da kullanabilirsiniz.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
MLflow kullanarak modelleri izlemek ve günlüğe kaydetmek için bir deneme oluşturun
Bu bölümde bir denemenin nasıl oluşturulacağı gösterilmektedir ve model ve eğitim parametrelerini ve puanlama ölçümlerini belirtir. Ayrıca modelleri eğitmeyi, kayıt altına almayı ve eğitilen modelleri daha sonra kullanmak üzere depolamayı gösterir.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Otomatik kaydetme, model eğitildiğinden hem giriş parametresi değerlerini hem de bir makine öğrenmesi modelinin çıkış ölçümlerini otomatik olarak yakalar. Bu bilgiler, MLflow API'lerinin veya çalışma alanınızdaki ilgili denemenin erişebileceği ve görselleştirebildiği çalışma alanınıza kaydedilir.
Tamamlandığında, denemeniz şu görüntüye benzer:

İlgili adlarına sahip tüm denemeler günlüğe kaydedilir ve parametrelerini ve performans ölçümlerini izleyebilirsiniz. Otomatik kaydetme hakkında daha fazla bilgi edinmek için bkz. Microsoft Fabric'nde Otomatik Kaydetme.
Deneme ve otomatik kaydetme belirtimlerini ayarlama
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
scikit-learn ve LightGBM'i içeri aktarma
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Eğitim ve test veri kümelerini hazırlama
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Eğitim verilerine SMOTE uygula
Dengesiz sınıflandırmanın bir sorunu vardır çünkü modelin karar sınırını etkili bir şekilde öğrenemeyecek kadar az azınlık sınıfı örneği vardır. Bunu işlemek için Yapay Azınlık Aşırı Örnekleme Tekniği (SMOTE), azınlık sınıfı için yeni örnekler üretebilmek adına en yaygın kullanılan tekniktir. 1. adımda yüklediğiniz imblearn kitaplığıyla SMOTE'ye erişin.
SMOTE'yi yalnızca eğitim veri kümesine uygulayın. Özgün verilerde model performansının geçerli bir tahminini elde etmek için test veri kümesini özgün dengesiz dağılımında bırakmanız gerekir. Bu deneme, üretimdeki durumu temsil eder.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Daha fazla bilgi için bkz. SMOTE ve rastgele aşırı örneklemeden SMOTE ve ADASYN. Dengesiz öğrenme web sitesi bu kaynakları barındırıyor.
Modeli eğitin
Modeli en fazla dört derinlikte ve dört özellikle eğitmek için Rastgele Orman'ı kullanın:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Maksimum sekiz derinlikte ve altı özellikle modeli eğitmek için Rastgele Orman'ı kullanın:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Modeli LightGBM ile eğitme:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Model performansını izlemek için deneme yapıtını görüntüleme
Deneme çalıştırmaları, deneme yapıtına otomatik olarak kaydedilir. Bu yapıtı çalışma alanında bulabilirsiniz. Eser adı, deneyi kurmak için kullanılan adı temel alır. Tüm eğitilen modeller, çalıştırmalarının sonuçları, performans ölçümleri ve model parametreleri deney sayfasında kaydedilmektedir.
Denemelerinizi görüntülemek için:
- Sol panelde çalışma alanınızı seçin.
- Bu durumda, sample-bank-churn-experimentdeneme adını bulun ve seçin.
5. Adım: Son makine öğrenmesi modelini değerlendirme ve kaydetme
En iyi modeli seçmek ve kaydetmek için çalışma alanından kaydedilen denemeyi açın:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Test veri kümesinde kaydedilen modellerin performansını değerlendirme
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
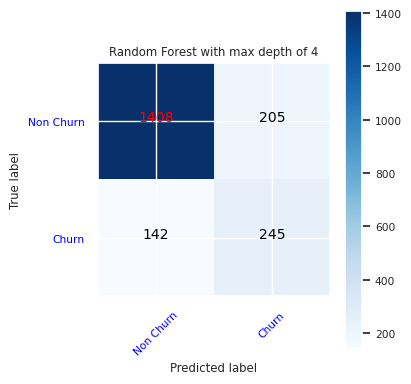
Karışıklık matrisi kullanarak doğru/yanlış pozitif/negatifleri gösterme
Sınıflandırmanın doğruluğunu değerlendirmek için karışıklık matrisini çizen bir betik oluşturun. Ayrıca Sahtekarlık Algılama örneğigösterildiği gibi SynapseML araçlarını kullanarak bir karışıklık matrisi çizebilirsiniz.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
Rastgele orman sınıflandırıcısı için dört özellik içeren maksimum derinlikte bir karışıklık matrisi oluşturun:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
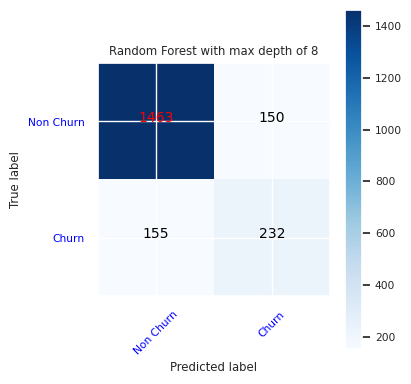
Altı özelliğe sahip maksimum sekiz derinliği olan rastgele orman sınıflandırıcısı için bir karışıklık matrisi oluşturun:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
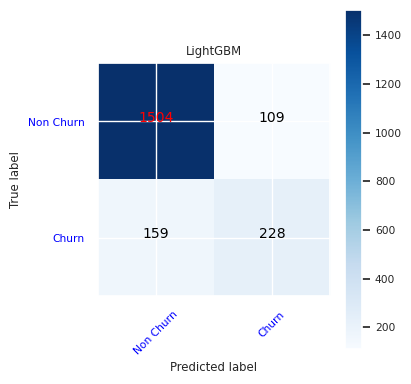
LightGBM için karışıklık matrisi oluşturma:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Power BI için sonuçları kaydetme
Model tahmin sonuçlarını Power BI'da görselleştirmeye taşımak için delta çerçevesini lakehouse'a kaydedin.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
6. Adım: Power BI'da görselleştirmelere erişme
Power BI'da kayıtlı tablonuza erişin:
- Sol tarafta OneLakeöğesini seçin.
- Bu not defterine eklediğiniz lakehouse'u seçin.
- Bu Lakehouse açma bölümünde Aç'ıseçin.
- Şeritte Yeni Anlam Modeliöğesini seçin.
df_pred_results'i seçin ve ardından tahminlere bağlı yeni bir Power BI anlam modeli oluşturmak için onaylayın seçin. - Yeni anlamsal model açın. OneLake'de bulabilirsiniz.
- Power BI rapor yazma sayfasını açmak için anlam modelleri sayfasının üstündeki araçlar menüsünden dosya altında Yeni Rapor Oluştur seçeneğini seçin.
Aşağıdaki ekran görüntüsünde bazı örnek görselleştirmeler gösterilmektedir. Veri paneli, bir tablodan seçilecek delta tabloları ve sütunları gösterir. Uygun kategori (x) ve değer (y) ekseni seçildikten sonra, filtreleri ve işlevleri (örneğin, tablo sütununun toplamını veya ortalamasını) seçebilirsiniz.
Not
Bu ekran görüntüsünde, gösterilen örnekte Power BI'da kaydedilen tahmin sonuçlarının analizi açıklanmaktadır:

Ancak gerçek bir müşteri değişim sıklığı kullanım örneği için, kullanıcının konu uzmanlığına ve firma ve iş analizi ekibinin ve firmanın ölçüm olarak standartlaştırdığı öğelere bağlı olarak görselleştirme oluşturması için daha kapsamlı bir gereksinim kümesine ihtiyacı olabilir.
Power BI raporu, ikiden fazla banka ürünü kullanan müşterilerin daha yüksek değişim oranına sahip olduğunu gösterir. Ancak, birkaç müşterinin ikiden fazla ürünü vardı. (Sol alt paneldeki çizime bakın.) Banka daha fazla veri toplamalı, ancak daha fazla ürünle ilişkili diğer özellikleri de araştırmalıdır.
Almanya'daki banka müşterileri, Fransa ve İspanya'daki müşterilere kıyasla daha yüksek bir değişim oranına sahiptir. (Sağ alt paneldeki çizime bakın). Rapor sonuçlarına bağlı olarak, müşterileri ayrılmaya teşvik eden faktörlerle ilgili bir araştırma yararlı olabilir.
Orta yaşlı müşteriler daha fazladır (25 ile 45 arasında). 45 ile 60 arasındaki müşteriler daha fazla çıkış yapmaya eğilimlidir.
Son olarak, kredi puanı daha düşük olan müşteriler büyük olasılıkla diğer finansal kurumlar için bankadan ayrılır. Banka, kredi puanı ve hesap bakiyesi düşük olan müşterileri bankada kalmaya teşvik etmenin yollarını keşfetmelidir.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")
İlgili içerik
- Microsoft Fabric'de makine öğrenmesi modeli
- makine öğrenmesi modellerini eğit
- Microsoft Fabric'de makine öğrenmesi deneyleri