Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğretici, Microsoft Fabric'te Synapse Veri Bilimi iş akışının uçtan uca bir örneğini sunar. Senaryo, çevrimiçi kitap önerileri için bir model oluşturur.
Bu öğretici şu adımları kapsar:
- Verileri bir lakehouse'a yükle
- Veriler üzerinde keşif analizi gerçekleştirme
- Bir model eğitin ve MLflow ile kaydedin.
- Modeli yükleme ve tahminlerde bulunma
Birçok öneri algoritması türü mevcuttur. Bu öğreticide, Alternatif En Küçük Kareler (ALS) matris faktörizasyon algoritması kullanılmaktadır. ALS, model tabanlı işbirliğine dayalı bir filtreleme algoritmasıdır.

ALS, iki düşük rütbeli matris olan U ve V'nin çarpımı olarak R derecelendirme matrisini tahmin etmeye çalışır. Burada, R = U * Vt. Bu yaklaşık değerler genellikle faktör matris olarak adlandırılır.
ALS algoritması yinelemelidir. Her yineleme, faktör matrislerinden birini sabit tutarken, diğerini en az kare yöntemini kullanarak çözer. Ardından yeni çözülen faktör matrisi sabitini tutarken diğer faktör matrisini de çözer.

Önkoşullar
Microsoft Fabric aboneliği alın . Alternatif olarak, ücretsiz Microsoft Fabric deneme sürümünekaydolun.
Microsoft Fabricoturumuna giriş yapın.
Ana sayfanızın sol alt tarafındaki deneyim değiştiriciyi kullanarak Fabric'e geçiş yapın.

- Gerekirse, Microsoft Fabric'te göl evi oluşturmabölümünde açıklandığı gibi bir Microsoft Fabric göl evi oluşturun.
Bir defterde takip edin
Not defterinde izleyebileceğiniz şu seçeneklerden birini belirleyebilirsiniz:
- Yerleşik not defterini açın ve çalıştırın.
- GitHub'dan not defterinizi yükleyin.
Yerleşik not defterini açma
Öğreticiye örnek Kitap önerisi not defteri eşlik eder.
Bu öğreticinin örnek not defterini açmak için Sisteminizi veri bilimi öğreticilerine hazırlamabaşlığındaki yönergeleri izleyin.
Kodu çalıştırmaya başlamadan önce not defterine bir göl evi eklediğinizden emin olun.
Not defterini GitHub'dan içeri aktarma
AIsample - Book Recommendation.ipynb not defteri bu öğreticiye eşlik eder.
Bu öğretici için eşlik eden not defterini açmak üzere, not defterini çalışma alanınıza aktarmak için sisteminizi veri bilimi öğreticilerine hazırlama başlığındaki yönergeleri izleyin.
Bu sayfadaki kodu kopyalayıp yapıştırmayı tercih ederseniz, yeni bir not defteri oluşturabilirsiniz.
Kod çalıştırmaya başlamadan önce not defteri bir göl evi eklemeyi unutmayın.
1. Adım: Verileri yükleme
Bu senaryodaki kitap önerisi veri kümesi üç ayrı veri kümesinden oluşur:
Books.csv: Uluslararası Standart Kitap Numarası (ISBN) her kitabı tanımlar ve geçersiz tarihler zaten kaldırılmıştır. Veri kümesi başlık, yazar ve yayımcıyı da içerir. Birden çok yazarı olan bir kitap için Books.csv dosyası yalnızca ilk yazarı listeler. URL'ler, kapak görüntüleri için Amazon web sitesi kaynaklarını üç boyutta gösterir.
ISBN Book-Title Book-Author Yıl-Of-Publication Yayınevi Resim -URL-S Resim-URL-M Resim-URL-l 0195153448 Klasik Mitoloji Mark P. O. Morford 2002 Oxford Üniversitesi Basını http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Kanada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Her kitabın derecelendirmeleri açık (kullanıcılar tarafından 1 ile 10 arasında bir ölçekte sağlanır) veya örtük (kullanıcı girişi olmadan gözlemlenir ve 0 ile gösterilir).
User-ID ISBN Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: Kullanıcı kimlikleri anonimleştirilir ve tamsayılarla eşlenir. Demografik veriler (örneğin, konum ve yaş) varsa sağlanır. Bu veriler kullanılamıyorsa, bu değerler
null.User-ID Yer Yaş 1 nyc New York Amerika Birleşik Devletleri 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bu not defterini farklı veri kümeleriyle görebilmek için bu parametreleri tanımlayın:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Verileri bir lakehouse'ta indirin ve depolayın
Bu kod veri kümesini indirir ve ardından lakehouse'da depolar.
Önemli
çalıştırmadan önce not defterine bir lakehouse eklediğinizden emin olun. Aksi takdirde bir hata alırsınız.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
MLflow deneme izlemesini ayarlama
MLflow deneme izlemesini ayarlamak için bu kodu kullanın. Bu örnek otomatik kaydetmeyi devre dışı bırakır. Daha fazla bilgi için Microsoft Fabric'teki Otomatik Kayıt makalesine bakın.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Göl evinden veri okuma
Doğru veriler lakehouse'a yerleştirildikten sonra, üç veri kümesini ayrı Spark DataFrame'lere notebook'ta aktarın. Bu koddaki dosya yolları daha önce tanımlanan parametreleri kullanır.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
2. Adım: Keşif veri analizi gerçekleştirme
Ham verileri görüntüleme
display komutuyla DataFrames'i keşfedin. Bu komutla üst düzey DataFrame istatistiklerini görüntüleyebilir ve farklı veri kümesi sütunlarının birbiriyle ilişkisini anlayabilirsiniz. Veri kümelerini incelemeden önce gerekli kitaplıkları içeri aktarmak için şu kodu kullanın:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Kitap verilerini içeren DataFrame'e bakmak için bu kodu kullanın:
display(df_items, summary=True)
Daha sonra kullanmak üzere bir _item_id sütunu ekleyin.
_item_id değeri, öneri modelleri için bir tamsayı olmalıdır. Bu kod, ITEM_ID_COL dizinlere dönüştürmek için StringIndexer kullanır:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
DataFrame'i görüntüleyin ve _item_id değerinin beklendiği gibi monoton ve art arda artıp artmadığını denetleyin:
display(df_items.sort(F.col("_item_id").desc()))
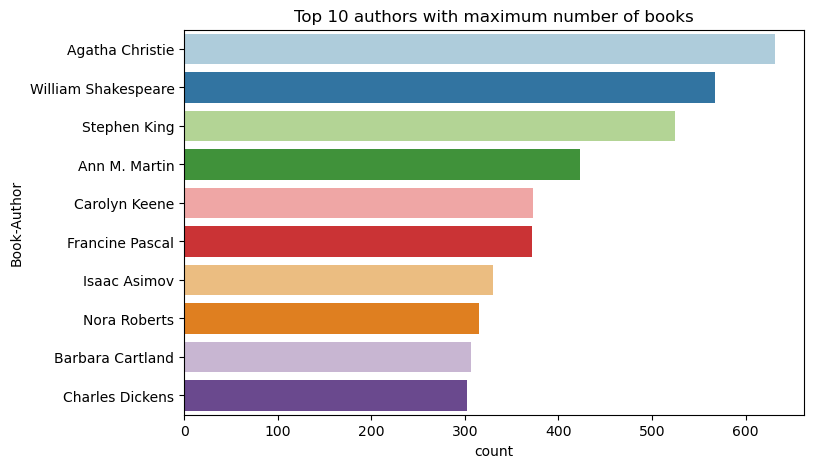
İlk 10 yazarı azalan düzende yazılmış kitap sayısına göre çizmek için bu kodu kullanın. Agatha Christie 600'den fazla kitabıyla önde gelen yazardır ve onu William Shakespeare takip eder.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Ardından, kullanıcı verilerini içeren DataFrame'i görüntüleyin:
display(df_users, summary=True)
Bir satırda eksik User-ID değeri varsa, bu satırı bırakın. Özelleştirilmiş bir veri kümesindeki eksik değerler sorunlara neden olmaz.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Daha sonra kullanmak üzere bir _user_id sütunu ekleyin. Öneri modelleri için _user_id değeri tamsayı olmalıdır. Aşağıdaki kod örneği, USER_ID_COL dizinlere dönüştürmek için StringIndexer kullanır.
Kitap veri kümesinin zaten bir tamsayı User-ID sütunu var. Ancak, farklı veri kümeleriyle uyumluluk için bir _user_id sütunu eklemek bu örneği daha sağlam hale getirir.
_user_id sütununu eklemek için şu kodu kullanın:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Derecelendirme verilerini görüntülemek için şu kodu kullanın:
display(df_ratings, summary=True)
Ayrı derecelendirmeleri alın ve daha sonra ratingsadlı bir listede kullanmak üzere kaydedin:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
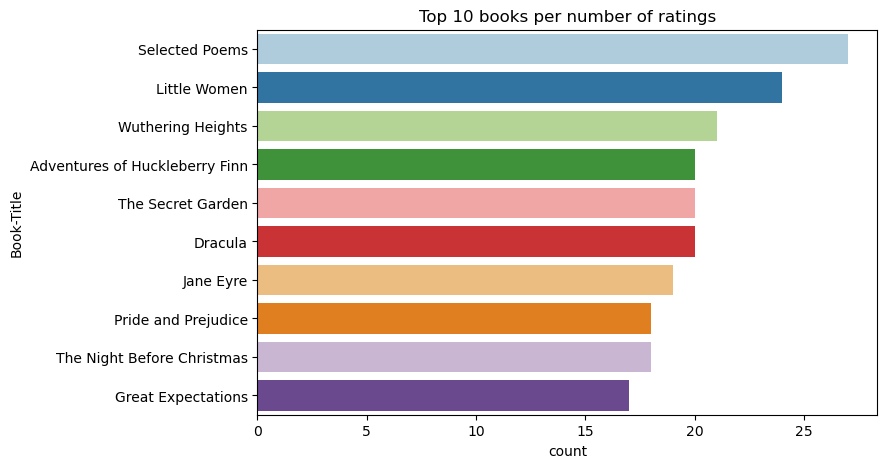
En yüksek derecelendirmeye sahip ilk 10 kitabı göstermek için bu kodu kullanın:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Reytinglere göre, Seçilen Şiirler en popüler kitaptır. Adventures of Huckleberry Finn, The Secret Gardenve Dracula aynı derecelendirmeye sahip.
Verileri birleştirme
Daha kapsamlı bir analiz için üç DataFrame'i tek bir DataFrame'de birleştirin:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Ayrı kullanıcıların, kitapların ve etkileşimlerin sayısını görüntülemek için bu kodu kullanın:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
En popüler öğeleri hesaplama ve çizme
En popüler 10 kitabı hesaplamak ve görüntülemek için bu kodu kullanın:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Bahşiş
Popüler veya En çok satın alınan öneri bölümleri için <topn> değerini kullanın.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Eğitim ve test veri kümelerini hazırlama
ALS matrisi, eğitimden önce veri hazırlığı gerektirir. Verileri hazırlamak için bu kod örneğini kullanın. Kod şu eylemleri gerçekleştirir:
- Derecelendirme sütununu doğru türe dönüştürme
- Kullanıcı derecelendirmeleriyle eğitim verilerini örnekleme
- Verileri eğitim ve test veri kümelerine bölme
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsity, kullanıcıların ilgi alanlarındaki benzerlikleri tanımlayamayan seyrek geri bildirim verilerini ifade eder. Hem verileri hem de geçerli sorunu daha iyi anlamak için veri kümesi sparsity değerini hesaplamak için şu kodu kullanın:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
3. Adım: Modeli geliştirme ve eğitme
Kullanıcılara kişiselleştirilmiş öneriler sunmak için bir ALS modeli eğitin.
Modeli tanımlama
Spark ML, ALS modelini oluşturmak için kullanışlı bir API sağlar. Ancak model, veri seyrekliği ve soğuk başlangıç gibi sorunları güvenilir bir şekilde ele almaz (kullanıcılar veya öğeler yeni olduğunda önerilerde bulunmakta zorlanır). Model performansını geliştirmek için çapraz doğrulamayı ve otomatik hiper parametre ayarlamasını birleştirin.
Model eğitimi ve değerlendirmesi için gereken kitaplıkları içeri aktarmak için bu kodu kullanın:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Model hiperparametrelerini düzenleme
Sonraki kod örneği, hiper parametreler üzerinde arama yapmaya yardımcı olmak için bir parametre kılavuzu oluşturur. Kod ayrıca değerlendirme ölçümü olarak root-mean-square hatasını (RMSE) kullanan bir regresyon değerlendiricisi oluşturur:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
Sonraki kod örneği, önceden yapılandırılmış parametrelere göre farklı model ayarlama yöntemleri başlatır. Model ayarlama hakkında daha fazla bilgi için Apache Spark web sitesindeki ML Ayarlama: model seçimi ve hiper parametre ayarlama bakın.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Modeli değerlendirme
Modülleri test verilerine göre değerlendirmeniz gerekir. İyi eğitilmiş bir modelin veri kümesinde yüksek ölçümler olması gerekir.
Fazla uygun bir modelin eğitim verilerinin boyutunda bir artışa veya yedekli özelliklerden bazılarının azaltılmasına ihtiyacı olabilir. Model mimarisinin değişmesi veya parametrelerinin biraz ince ayara ihtiyacı olabilir.
Not
Negatif R karesi ölçüm değeri, eğitilen modelin yatay düz çizgiden daha kötü performans gösterdiğini gösterir. Bu bulgu, eğitilen modelin verileri açıklamadığını gösterir.
Değerlendirme işlevi tanımlamak için şu kodu kullanın:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
MLflow kullanarak denemeyi izleme
Tüm denemeleri izlemek ve parametreleri, ölçümleri ve modelleri günlüğe kaydetmek için MLflow kullanın. Model eğitimi ve değerlendirmesine başlamak için şu kodu kullanın:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Eğitim çalışmasının günlüğe kaydedilen bilgilerini görüntülemek için çalışma alanınızdan aisample-recommendation adlı denemeyi seçin. Deneme adını değiştirdiyseniz, yeni adı olan denemeyi seçin. Günlüğe kaydedilen bilgiler şu görüntüye benzer:

4. Adım: Puanlama için son modeli yükleme ve tahminlerde bulunma
Model eğitimini tamamladıktan ve en iyi modeli seçtikten sonra, puanlama için modeli yükleyin (bazen çıkarım olarak da adlandırılır). Bu kod modeli yükler ve tahminleri kullanarak her kullanıcı için ilk 10 kitabı önerir:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Çıkış şu tabloya benzer:
| _item_id | _kullanıcı_id | derecelendirme | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Yaşamları... |
| 786 | 7 | 6.2255826 | Piyano AdamıNın D... |
| 45330 | 7 | 4.980466 | Zihin Durumu |
| 38960 | 7 | 4.980466 | İstediği Her Şey |
| 125415 | 7 | 4.505084 | Harry Potter ve ... |
| 44939 | 7 | 4.3579073 | Taltos: Taltosların Yaşamları... |
| 175247 | 7 | 4.3579073 | Bonesetter'ın ... |
| 170183 | 7 | 4.228735 | Basit Yaşam... |
| 88503 | 7 | 4.221206 | Blu Adası... |
| 32894 | 7 | 3.9031885 | Kış Gündönümü |
Tahminleri göle kaydedin
Önerileri lakehouse'a geri yazmak için şu kodu kullanın:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)
İlgili içerik
- Metin sınıflandırma modelini eğitip değerlendirme
- Microsoft Fabric'da bir makine öğrenmesi modeli
- makine öğrenmesi modellerini eğit
- Microsoft Fabric'de makine öğrenmesi deneyleri