Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir:✅ Warehouse in Microsoft Fabric
Bu makalede, Fabric Veri Ambarı mimarisindeki performans, ölçeklenebilirlik ve maliyet verimliliğini sağlayan özellikler ve yenilikler vurgulanır.
Fabric Veri Ambarı, bütünleşik bir veri platformu üzerinde geleceğe hazır bir mimariyle çalışır. Açık delta depolama biçimi ve OneLake tümleştirmesi sayesinde Doku Veri Ambarı'ndaki verileriniz analiz için hazırdır.
Üst düzey mimari

Fabric Veri Ambarı, aşağıdaki yapı taşları ile büyük ölçekte analiz için özel olarak oluşturulmuştur:
| Yapı taşı | Açıklama |
|---|---|
| Birleşik sorgu iyileştiricisi | Kullanıcı tarafından yazılan SQL sorgularının kalitesinden bağımsız olarak dağıtılmış bulut ortamları için en uygun yürütme planını oluşturur. |
| Dağıtılmış sorgu işleme | Hızlı otomatik ölçeklendirme bulut altyapısı ile yüksek düzeyde paralel sorgu yürütmeyi destekler ve sorgular için gerekli işlem kaynaklarını anında sağlar. Ayrı SELECT ve DML iş yükleri, verimli ve yalıtılmış yürütme için ayrı havuzlar kullanır. |
| Sorgu Yürütme Altyapısı | Yüksek performans ve yüksek eşzamanlılık ile büyük miktarda veri üzerinde analiz sorguları yürütmeye yönelik SQL tabanlı bir altyapı. |
| Meta veriler ve işlem yönetimi | Meta veriler ön uçta, arka uçta ve hem yerel SSD önbelleğinde hem de uzak OneLake depolama alanında bulunur. Eşzamanlı işlemleri destekler ve ACID uyumluluğunu sağlar. |
| OneLake'de depolama | Günlük Yapılı Tablolar, güvenli açık depolamaya sahip bir lakehouse modeli olan Açık Delta tablo biçimi kullanılarak uygulanır. |
| Yapı Platformu | Doku Platformu birleşik kimlik doğrulaması ve güvenlik modeli, izleme ve denetim sağlar. Doku Veri Ambarınız Power BI, Data Factory'deki veri işlem hatları, Real-Time Intelligence ve daha fazlası dahil olmak üzere iş gereksinimlerini karşılamak için diğer Doku platformu hizmetlerinde otomatik olarak kullanılabilir. |
Birleşik sorgu iyileştirici altyapısı
Doku Veri Ambarı'ndaki birleşik sorgu iyileştirici, SQL sorgularınızı çalıştırmanın en akıllı yolunu belirleyen altyapıdır.
Bir sorgu gönderdiğinizde, birleşik sorgu iyileştirici bunu yürütmenin olası yollarını arar: tabloları birleştirme, verilerin nereye taşınacağı ve CPU, bellek ve ağ gibi kaynakların nasıl kullanılacağı. Birleştirilmiş sorgu iyileştirici yalnızca ilk seçeneği belirlemez, bu faktörler ve kullanılabilir meta veriler ile istatistikler genelinde maliyeti değerlendirerek izin verilen süre içinde en uygun planı seçer.
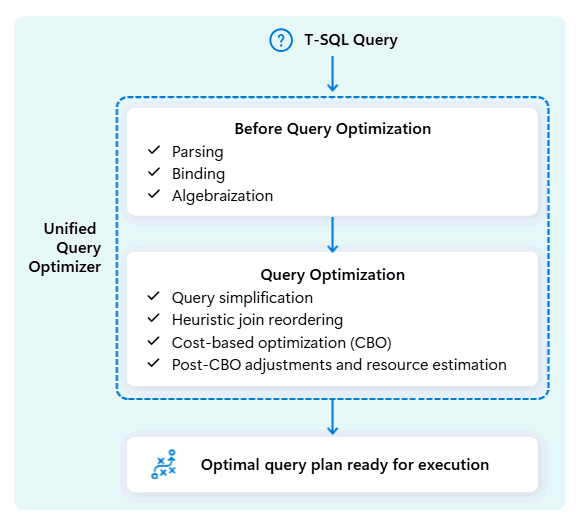
Bir sorgunun yürütme planını iyileştirirken birleştirilmiş sorgu iyileştiricisi tek seferde her şeyi dikkate alır: sorgunuzun şekli, tablolarınızın veri dağılımı ve verileri taşıma maliyeti ile yerel olarak işleme. Birleştirilmiş sorgu iyileştiricisi, küçük bir tabloyu yayınlamanın büyük bir tabloyu düzenlemeden daha ucuz olup olmadığına karar verme gibi akıllıca tercihler yapabilir. Bu, karmaşık veya kötü yazılmış T-SQL sorguları için bile daha az gereksiz veri karışıklığı, daha iyi işlem kullanımı ve daha hızlı performans anlamına gelir.
Tutarlı performans, geliştiricilerin el ile T-SQL sorgu ayarlaması için zaman harcamasını gerektirmez. Örneğin, sorgularda en iyi JOIN sırayı el ile belirlemeniz gerekmez. SQL'iniz önce büyük tabloyu, daha küçük, yüksek oranda seçmeli veri tablosunu ikinci olarak listelerse, iyileştirici daha iyi performans için konumlarını otomatik olarak değiştirebilir. Eşleşen satırlar için başlangıç noktası olarak daha küçük tabloyu ("oluşturma" tarafı) ve arama yapılacak tablo olarak daha büyük tabloyu ("sondaj" tarafı, eşleşmelerin kontrol edildiği) kullanır. Bu yaklaşım bellek kullanımını en aza indirir, veri hareketini azaltır ve paralelliği geliştirir ve doğru sonuçlar sunmaya devam eder.
Birleşik sorgu iyileştiricisi, iş yükleri geliştikçe geçmiş sorgu yürütmelerinden sürekli olarak bilgi edinir ve mümkün olan en iyi performansı sunmak için iyileştirme algoritmasını iyileştirir. Kullanıcılar, karmaşıklıktan bağımsız olarak ve müdahale etmeye gerek kalmadan otomatik olarak hızlı sorgu yürütmeden yararlanıyor.
Dağıtılmış sorgu işleme altyapısı
Doku Veri Ambarı'nda, dağıtılmış sorgu işleme altyapısı sorgu planlarındaki görevlere bilgi işlem kaynakları ayırır. Dağıtılmış sorgu işleme altyapısı, görevleri işlem düğümleri arasında zamanlayabilir, böylece her düğüm bir sorgu planının bir parçasını çalıştırarak daha hızlı performans için paralel yürütmeyi etkinleştirir. Büyük veri kümeleriyle ilgili karmaşık raporlar, dağıtılmış sorgu işlemeden yararlanabilir.
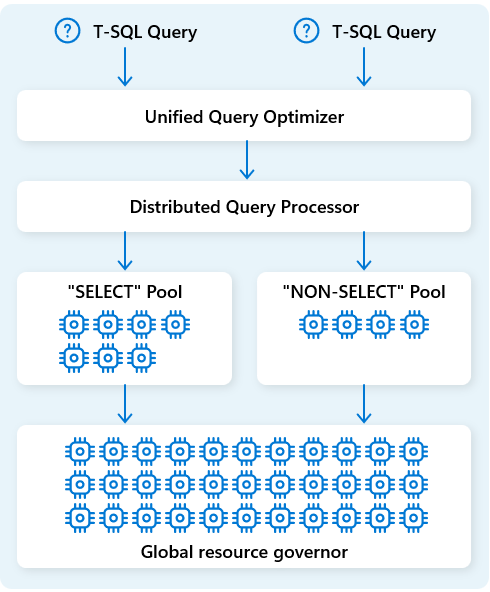
Kaynakları daha da iyileştirmek için, dağıtılmış sorgu işleme altyapısı işlem kaynaklarını iki havuza ayırır: SELECT sorgular ve veri alımı görevleri (NON-SELECT sorgular). Her iş yükü gerektiğinde ayrılmış kaynaklar alır. Bu, örneğin, gecelik ETL işlerinizin sabah panolarını geciktirmeyeceği anlamına gelir.
Bulutta hızlı düğüm sağlama ile, dağıtılmış sorgu işleme altyapısı sorgu hacmi, veri boyutu ve sorgu karmaşıklığındaki değişikliklere yanıt olarak işlem kaynaklarını otomatik olarak yukarı veya aşağı ölçeklendirir. Fabric Veri Ambarı, küçük veri kümeleri ve çok petabayt ölçekteki veriler için paralel işleme özelliklerine sahiptir.
Sorgu yürütme altyapısı
Sorgu yürütme altyapısı, dağıtılmış yürütme planının tek tek işlem düğümlerine atanan bölümlerini çalıştıran bir işlemdir. Sorgu yürütme altyapısı, en uygun maliyetle büyük verilerde verimli analiz için toplu iş modu yürütme ve sütunlu veri biçimlerini kullanmak üzere SQL Server ve Azure SQL Veritabanı tarafından kullanılan altyapıyı temel alır.
Sorgu yürütme altyapısı, verileri doğrudan Fabric OneLake'te depolanan Delta Parquet dosyalarından okur ve sorgu performansını hızlandırmak ve sorguların en uygun hızda yürütülmesini sağlamak için birden çok önbelleğe alma katmanından (bellek ve SSD) yararlanır. Sorgu yürütme altyapısı verileri bellek içinde işler ve gerektiğinde SSD önbelleğinden veya OneLake depolama alanından ek veriler alır.
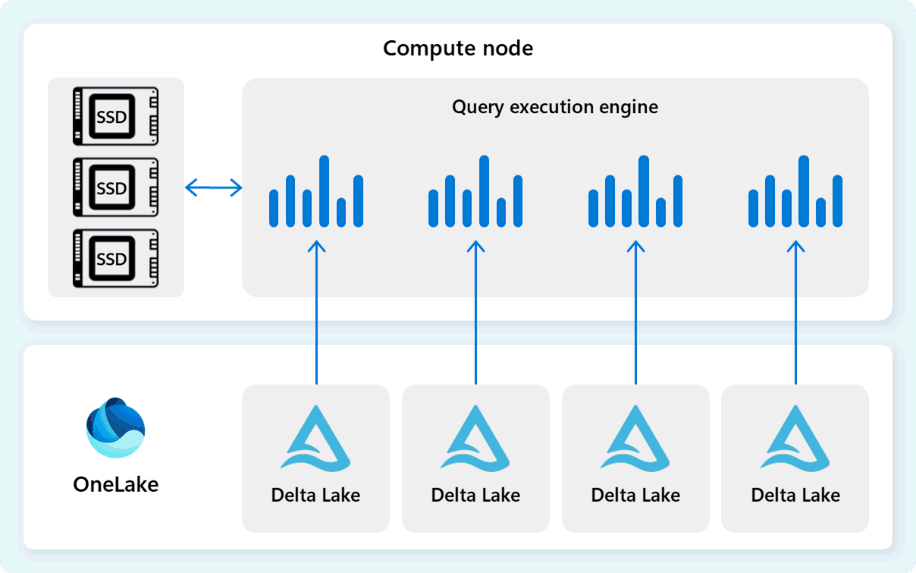
Sorgu yürütme altyapısı, verileri işlerken sorguyla ilgili olmayan kesimleri atlamak için sütun ve satır grubu eleme gerçekleştirir. Bu iyileştirme, dosyalardan ve bellek önbelleğinden taranan veri miktarını azaltarak kaynak kullanımını en aza indirmeye ve genel yürütme süresini geliştirmeye yardımcı olur.
Sorgu yürütme altyapısı, modern veri ambarı çözümlerinde kullanılan genel veri analizi desenlerini destekleyen milyarlarca satırı filtreleme ve toplama konusunda üstündür. Toplu iş modu yürütmesi, modern CPU'nun birden çok satırı paralel olarak işleme özelliğinden yararlanır ve ek yükü önemli ölçüde azaltır ve sorguların geleneksel satır satır yürütmeye kıyasla yüzlerce kat daha hızlı çalışmasını sağlar.
Meta veriler ve işlem yönetimi
Ambar altyapısı tablo şemasını, dosya düzenlemesini, sürüm geçmişini ve işlem durumlarını açıklamak için meta verileri kullanır. Bu meta veriler, ambar altyapısının verileri verimli bir şekilde yönetmesine ve sorgulamasına olanak tanır. Doku Veri Ambarı, yüksek oranda eşzamanlı meta veri işlemlerini yönetmek ve ACID uyumluluğunu sağlamak için OLTP işlem yöneticisini genişleten sağlam ve kapsamlı bir meta veri ve işlem yönetimi mimarisi sunar.
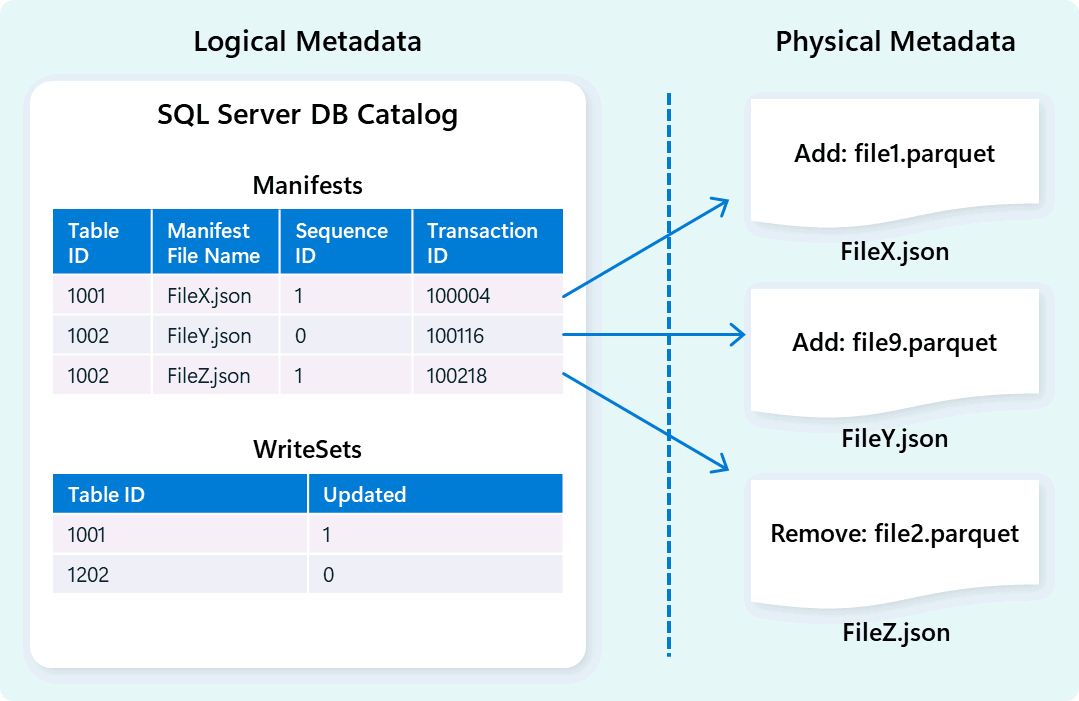
Bu tasarım, tutarlılık sağlarken yüksek eşzamanlılık ile iş yüklerini destekleyen işlem durumlarının hızlı ve güvenilir bir şekilde gezinmesini sağlar.
Depolama ve veri alımı
Fabric Veri Ambarı, ölçeklenebilir, güvenli, yüksek performanslı depolama için açık kaynak Delta formatına sahip bir lakehouse mimarisi kullanır. Delta tablo biçimi, veri sürümü oluşturma özelliğini destekler ve güvenli test ve geri alma işlemleri için zaman yolculuğu ve sıfır kopya kopyalama yoluyla geçmiş anlık görüntülere anında erişim sağlar. Kullanıcı verileri OneLake'de depolanır ve tüm Doku altyapılarının yedeklilik olmadan paylaşılan verilere verimli bir şekilde erişmesini sağlar.
Bu temeli temel alan Fabric Veri Ambarı, basitlik ve esnekliğe odaklanarak en iyi veri alımı performansını sunmak için tasarlanmıştır. Altyapı, gereksiz veri taramasını azaltmak için arka planda parçalanmış dosyaları bir araya getirmek üzere otomatik veri sıkıştırma yoluyla tablo veri depolamasını verimli bir şekilde yönetir. Akıllı veri dağıtım yöntemi, paralel işlemeyi artırmak ve sorgu sonuçlarını geliştirmek için verileri mikro bölümlenmiş hücrelere böler ve düzenler. Bu özellikler, el ile ayarlamalara gerek kalmadan otonom olarak çalışır.