Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR: Machine Learning Studio (klasik)
Machine Learning Studio (klasik)  Azure Machine Learning
Azure Machine Learning
Önemli
Machine Learning Stüdyosu (klasik) desteği 31 Ağustos 2024'te sona erecektir. Bu tarihe kadar Azure Machine Learning'e geçmenizi öneririz.
1 Aralık 2021'den başlayarak artık yeni Machine Learning Stüdyosu (klasik) kaynakları oluşturamayacaksınız. 31 Ağustos 2024'e kadar mevcut Machine Learning Stüdyosu (klasik) kaynaklarını kullanmaya devam edebilirsiniz.
- Makine öğrenmesi projelerini ML Studio'dan (klasik) Azure Machine Learning'e taşıma hakkındaki bilgilere bakın.
- Azure Machine Learning hakkında daha fazla bilgi edinin
ML Stüdyosu (klasik) belgeleri kullanımdan kaldırılacak ve gelecekte güncelleştirilmeyecektir.
Bu makalede, Machine Learning Studio'da (klasik) make ve technical specifications gibi farklı değişkenlere göre bir arabanın fiyatını tahmin eden bir makine öğrenmesi denemesi oluşturacaksınız.
Makine öğrenmesinde yeniyseniz Yeni Başlayanlar için Veri Bilimi video serisi, günlük dil ve kavramları kullanarak makine öğrenmesine harika bir giriş niteliğindedir.
Bu hızlı başlangıç, bir deneme için varsayılan iş akışını izler:
- Bir model oluşturma
- Modeli eğitme
- Modeli puanlama ve test etme
Verileri alma
Makine öğrenmesinde ihtiyacınız olan ilk şey verilerdir. Studio'ya (klasik) dahil olan ve kullanabileceğiniz birkaç örnek veri kümesi vardır veya birçok kaynaktan veri içeri aktarabilirsiniz. Bu örnekte, Otomobil fiyat verileri (Ham) adlı çalışma alanınıza dahil edilmiş örnek veri kümesini kullanacağız. Bu veri kümesi; marka, model, teknik belirtimler ve fiyat gibi bilgiler dahil olmak üzere birçok ayrı otomobil için giriş içerir.
İpucu
Aşağıdaki denemenin çalışan bir kopyasını Azure AI Gallery’de bulabilirsiniz. İlk veri bilimi denemeniz - Otomobil fiyat tahmini bölümüne gidin ve denemenin bir kopyasını Machine Learning Studio (klasik) çalışma alanınıza indirmek için Studio'da Aç'a tıklayın.
Veri kümesini denemenize aşağıdaki gibi aktarabilirsiniz.
Machine Learning Studio (klasik) penceresinin alt kısmındaki +YENİ'ye tıklayarak yeni bir deneme oluşturun. DENEME>
Deneye, tuvalin üst kısmında görebileceğiniz varsayılan bir ad verilir. Bu adı seçerek anlamlı bir adla değiştirin, örneğin, Otomobil fiyat tahmini. Adın benzersiz olması gerekmez.
Deneme tuvalinin sol tarafında bir veri kümesi ve modül paleti bulunur. Otomobil fiyat verileri (Ham) etiketli veri kümesini bulmak için bu paletin en üst kısmındaki Arama kutusuna otomobil yazın. Bu veri kümesini deneme tuvaline sürükleyin.
Bu verilerin nasıl göründüğünü görmek için otomobil veri kümesinin altındaki çıkış bağlantı noktasına tıklayın ve ardından Görselleştir'i seçin.
İpucu
Veri kümeleri ve modülleri küçük dairelerle gösterilen giriş ve çıkış bağlantı noktalarına sahiptir. Giriş bağlantı noktaları yukarıda, çıkış bağlantı noktaları aşağıdadır. Denemeniz üzerinden veri akışı oluşturmak için bir modülün çıkış bağlantı noktasını bir diğerinin giriş bağlantı noktasına bağlayacaksınız. Herhangi bir zamanda bir veri kümesi veya modülün çıkış bağlantı noktasına tıklayarak, veri akışında bu noktadaki verileri görebilirsiniz.
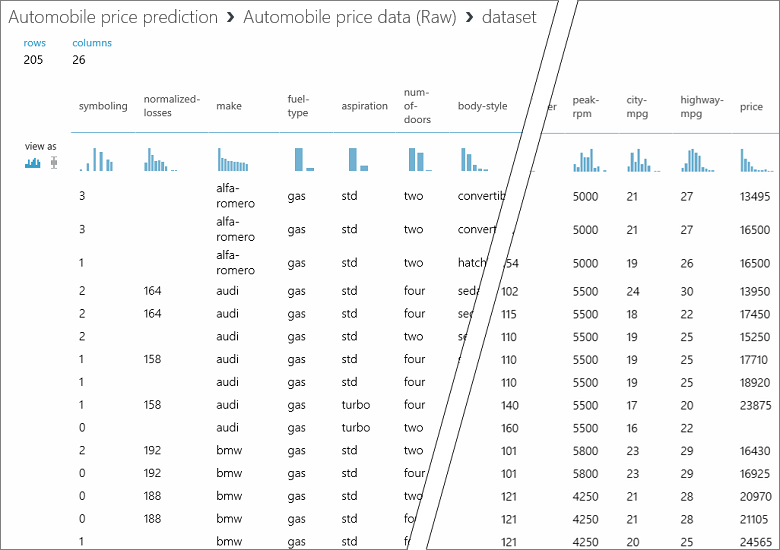
Bu veri kümesinde her satır bir otomobili temsil eder ve her otomobille ilişkili değişkenler sütun olarak görünür. Belirli bir otomobilin değişkenlerini kullanarak en sağdaki sütundaki (sütun 26, "fiyat" başlıklı) fiyatı tahmin edeceğiz.
Sağ üst köşedeki "x" işaretine tıklayarak görselleştirme penceresini kapatın.
Verileri hazırlama
Genellikle bir veri kümesi analiz edilmeden önce biraz ön işleme gerekir. Çeşitli satırların sütunlarında bulunan eksik değerleri fark etmiş olabilirsiniz. Modelin verileri doğru şekilde analiz edebilmesi için bu eksik değerlerin temizlenmesi gerekir. Eksik değerleri olan satırları kaldıracağız. Ayrıca, normalleştirilmiş kayıplar sütununun büyük kısmı eksik değerlere sahiptir; bu nedenle bu sütunu modelin tamamen dışında bırakacağız.
İpucu
Giriş verilerinden eksik değerleri temizleme, çoğu modülü kullanmanın bir önkoşuludur.
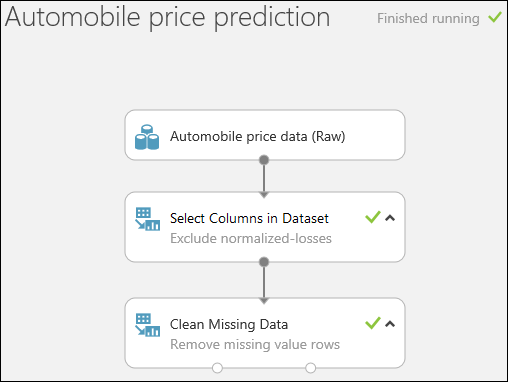
İlk olarak normalleştirilmiş kayıplar sütununu tamamen kaldıran bir modül ekleyeceğiz. Ardından, eksik veri içeren satırları kaldıran başka bir modül ekleriz.
Modül paletinin üst kısmındaki arama kutusuna select columns yazın ve veri kümesinde Sütunları Seç modülünü bulun. Ardından deneme tuvaline sürükleyin. Bu modül, modele hangi veri sütunlarını dahil etmek veya dışarıda bırakmak istediğimizi seçmemizi sağlar.
Automobile price data (Raw) veri kümesinin çıkış bağlantı noktasını Veri Kümesindeki Sütunları Seç işleminin giriş bağlantı noktasına bağlayın.
Select Columns in Dataset (Veri Kümesinde Sütun Seçme) modülüne tıklayın ve Özellikler bölmesinde Sütun seçiciyi başlat seçeneğine tıklayın.
Sol tarafta Kurallar ile’ye tıklayın
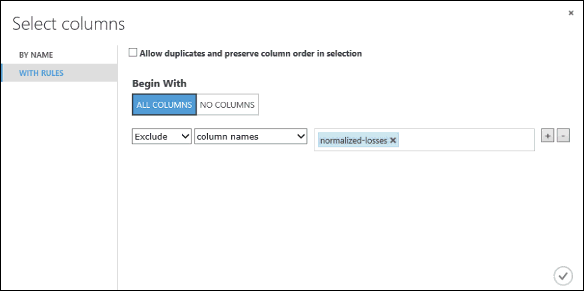
Şununla Başla altında Tüm sütunlar’a tıklayın. Bu kurallar, Veri Kümesindeki Sütunları Seçme özelliğini tüm sütunlardan geçmeye yönlendirir (hariç tutmak üzere olduğumuz sütunlar hariç).
Açılır menülerden Hariç Tut ve sütun adlarını seçin ve ardından metin kutusunun içine tıklayın. Sütun listesi gösterilir. Normalleştirilmiş kayıplar’ı seçin ve metin kutusuna eklenir.
Sütun seçiciyi (sağ altta) kapatmak için onay işareti (Tamam) düğmesine tıklayın.
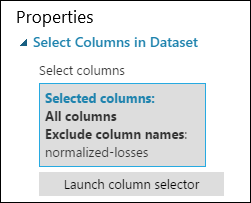
Artık Select Columns in Dataset (Veri Kümesinde Sütun Seçme) için özellikler bölmesi, normalleştirilmiş kayıplar dışındaki tüm veri kümelerindeki tüm sütunlardan geçeceğini belirtir.
İpucu
Modüle çift tıklayıp metin girerek bir modüle yorum ekleyebilirsiniz. Bu, modülün denemenizde ne işe yaradığını bir bakışta görmenize yardımcı olabilir. Bu durumda, Veri Kümesindeki Sütunları Seçme modülüne çift tıklayın ve "Normalleştirilmiş kayıpları dışarıda bırak" yorumunu yazın.
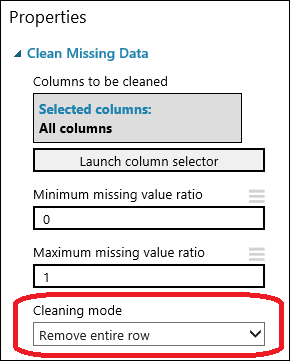
Eksik Verileri Temizleme modülünü deneme tuvaline sürükleyin ve bunu Veri Kümesindeki Sütunları Seçme modülüne bağlayın. Özellikler bölmesinde, Temizleme modu altında Tüm satırı kaldır’ı seçin. Bu seçenekler Eksik Verileri Temizle'yi, eksik değerler içeren satırları kaldırarak verileri temizlemeye yönlendirir. Modüle çift tıklayın ve "Eksik değerli satırları kaldır" yorumunu yazın.
Sayfanın en altında yer alan ÇALIŞTIR'a tıklayarak denemeyi çalıştırın.
Deneme çalıştırma bittiğinde, tüm modüllerin başarıyla tamamlandığını göstermek için yeşil bir onay işareti bulunur. Sağ üst köşede Çalıştırma tamamlandı durumunun olduğuna da dikkat edin.
İpucu
Denemeyi neden şimdi çalıştırdık? Deneme çalıştırılarak, verilerimizin sütun tanımları Veri Kümesindeki Sütunları Seçme modülü ve Eksik Verileri Temizleme modülü aracılığıyla veri kümesinden geçer. Bu, Eksik Verileri Temizleme öğesine bağladığımız modüllerin de aynı bilgilere sahip olacağı anlamına gelir.
Artık temiz verilerimiz var. Temizlenen veri kümesini görüntülemek istiyorsanız Eksik Verileri Temizleme modülünün sol çıkış bağlantı noktasına tıklayın ve Görselleştir'i seçin. Normalleştirilmiş kayıplar sütununun artık dahil olmadığına ve eksik değerlerin yok olduğuna dikkat edin.
Artık veriler temizlendiğine göre, tahmine dayalı modelde hangi özellikleri kullanacağımızı belirtmeye hazırız.
Özellikleri tanımlama
Makine öğrenmesinde özellikler, ilgilendiğiniz bir şeyin tek tek ölçülebilir özellikleridir. Veri kümemizde her bir satır bir otomobili temsil eder ve her bir sütun da bu otomobilin bir özelliğidir.
Tahmine dayalı bir model oluşturmaya yönelik iyi bir özellikler kümesi bulmak için, deneme ve çözmek istediğiniz sorun hakkında bilgi gerekir. Bazı özellikler, hedefi tahmin etmede diğerlerinden daha uygundur. Bazı özelliklerin diğer özelliklerle güçlü bir bağıntısı vardır ve kaldırılabilir. Örneğin, city-mpg ve highway-mpg yakından ilişkilidir, bu nedenle tahmini önemli ölçüde etkilemeden birini tutabilir ve diğerini kaldırabiliriz.
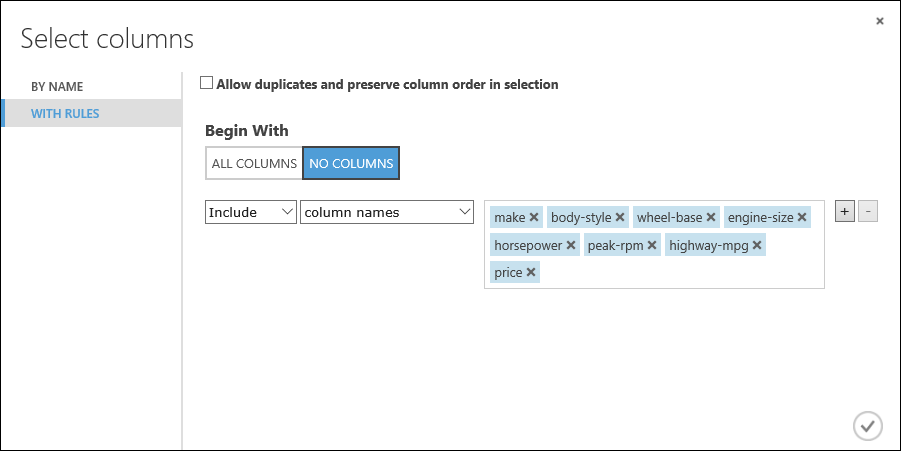
Veri kümemizdeki bir alt özellikler kümesini kullanan bir model oluşturalım. Daha sonra geri dönüp farklı özellikler seçebilir, denemeyi tekrar çalıştırabilir ve daha iyi sonuçlar elde edip etmeyeceğinizi görebilirsiniz. Ancak başlarken aşağıdaki özellikleri deneyelim:
marka, gövde tipi, dingil mesafesi, motor hacmi, beygir gücü, maksimum devir, otoyol yakıt tüketimi, fiyat
Deneme tuvaline başka bir Veri Kümesindeki Sütunları Seçme modülü sürükleyin. Eksik Verileri Temizleme modülünün sol çıkış bağlantı noktasını Veri Kümesindeki Sütunları Seçme modülünün girişine bağlayın.
Modüle çift tıklayın ve "Tahmin için özellik seç" yazın.
Özellikler bölmesindeki Sütun seçiciyi başlat seçeneğine tıklayın.
Kurallarla tıklayın.
Başlangıç altında Kolon yok’a tıklayın. Filtre satırında, Dahil et ve sütun adları öğelerini seçin ve metin kutusunda sütun adları listemizi seçin. Bu filtre, modülü belirttiğimiz sütunlar (özellikler) dışında herhangi bir sütundan (özellik) geçmemeye yönlendirir.
Onay işareti (Tamam) düğmesine tıklayın.
Bu modül, yalnızca bir sonraki adımda kullanacağımız öğrenme algoritmasına geçirmek istediğimiz özellikleri içeren filtrelenmiş bir veri kümesi oluşturur. Daha sonra geri dönüp farklı özellikler seçerek yeniden deneyebilirsiniz.
Algoritma seçme ve uygulama
Artık veriler hazır olduğuna göre, tahmine dayalı bir model oluşturmak için eğitim ve test etme gerekir. Modeli eğitmek ve sonra fiyatları tahmin etmeye ne kadar yaklaştığını görmek üzere modeli test etmek için verilerimizi kullanacağız.
Sınıflandırma ve regresyon, denetimli makine öğrenimi algoritmasının iki türüdür. Sınıflandırma; renk gibi (kırmızı, mavi veya yeşil) tanımlanmış bir kategori kümesinden yanıt tahmin eder. Bir sayıyı tahmin etmek için regresyon kullanılır.
Bir sayı olan fiyatı tahmin etmek istediğimizden bir regresyon algoritması kullanırız. Bu örnekte doğrusal regresyon modeli kullanacağız.
Modele fiyatı da içeren bir veri kümesi vererek modeli eğitiriz. Model verileri tarar ve otomobilin özellikleri ile fiyatı arasındaki bağlantıları arar. Daha sonra modeli test edeceğiz. Bildiğimiz otomobiller için bir özellik kümesi vererek modelin bilinen fiyatı tahmin etmeye ne kadar yaklaştığını göreceğiz.
Verilerimizi modeli eğitmek ve verileri ayrı eğitim ve test kümelerine ayırarak modeli test etmek için kullanırız.
Verileri Bölme modülünü seçip deneme tuvaline sürükleyin ve bunu son Veri Kümesindeki Sütunları Seçme modülüne bağlayın.
Seçmek için Verileri Bölme modülüne tıklayın. İlk çıkış veri kümesinde satır kesiri’ni bulun (tuvalin sağ tarafında Özellikler bölmesinde) ve 0,75 olarak ayarlayın. Bu şekilde, modeli eğitmek için verilerin yüzde 75'ini kullanıp test etmek için yüzde 25'ini ayıracağız.
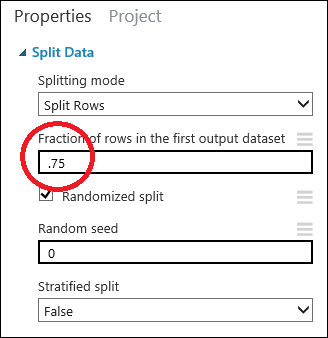
İpucu
Rastgele doldurma parametresini değiştirerek eğitim ve test etme için farklı rastgele örnekler oluşturabilirsiniz. Bu parametre, sözde rastgele sayı üreticisinin tohumlamasını denetler.
Denemeyi çalıştırın. Deneme çalıştırıldığında Veri Kümesindeki Sütunları Seçme ve Verileri Bölme modüllerinin sütun tanımlarını sonra ekleyeceğimiz modüllere geçirmesine olanak sağlanır.
Öğrenme algoritmasını seçmek için, tuvalin solundaki modül paletindeki Machine Learning kategorisini genişletin ve ardından Modeli Başlat'ı genişletin. Böylece makine öğrenimi algoritmalarını başlatmak için kullanılabilecek çeşitli modül kategorileri görüntülenir. Bu deneme için, Regresyon kategorisinin altında Doğrusal Regresyon modülünü seçin ve bunu deneme tuvaline sürükleyin. (Modülü bulmak için palet Arama kutusuna “doğrusal regresyon” da yazabilirsiniz.)
Model Eğitme modülünü bulup deney alanına sürükleyin. Doğrusal Regresyon modülünün çıkışını Modeli Eğitme modülünün sol girişine bağlayın ve Verileri Bölme modülünün eğitim verileri çıkışını (sol bağlantı noktası) Modeli Eğitme modülünün sağ girişine bağlayın.

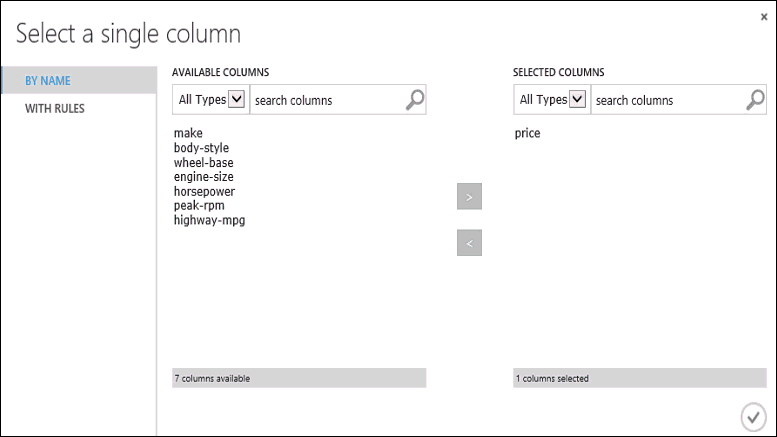
Modeli Eğitme modülüne tıklayın, Özellikler bölmesinde Sütun seçiciyi başlat seçeneğine tıklayın ve ardından fiyat sütununu seçin. Fiyat , modelimizin tahmin edecekleri değerdir.
Sütun seçicide fiyat sütununu Kullanılabilir sütunlar listesinden Seçili sütunlar listesine taşıyarak seçersiniz.
Denemeyi çalıştırın.
Şimdi, fiyat tahmininde bulunmak amacıyla yeni otomobil verilerini puanlamak için kullanılabilecek eğitilmiş bir regresyon modeli oluşturduk.
Deney çalıştırıldıktan sonra, şimdi benzer şekilde görünmelidir.
Yeni otomobil fiyatlarını tahmin et
Verilerimizin yüzde 75'ini kullanarak modeli eğittiğimize göre, modelimizin ne kadar iyi işlediğini görmek için verilerimizin diğer yüzde 25'ini puanlama amacıyla kullanabiliriz.
Model Puanlama modülünü bulup deneme tuvaline sürükleyin. Modeli Eğitme modülünün çıkışını Model Puanlama modülünün sol bağlantı noktasına bağlayın. Verileri Bölme modülünün test verileri çıkışını (sağ bağlantı noktası) Model Puanlama modülünün sağ giriş bağlantı noktasına bağlayın.
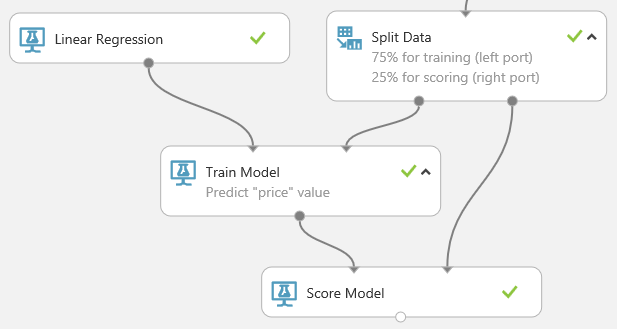
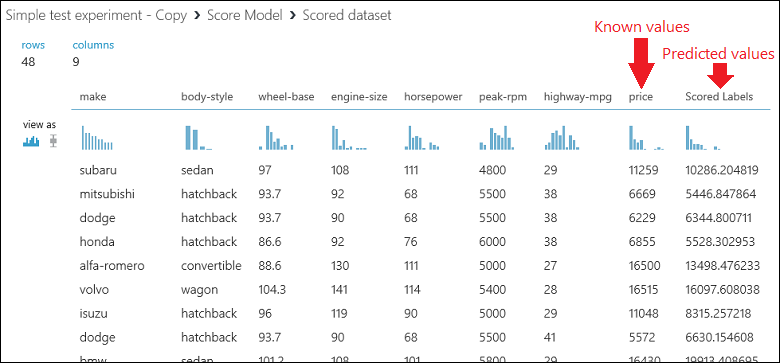
Denemeyi çalıştırın ve Modeli Puanlama modülünün çıkış bağlantı noktasına tıklayıp Görselleştir'i seçerek çıktıyı görüntüleyin. Çıkış, fiyat için tahmin edilen değerleri ve test verileri için bilinen değerleri gösterir.
Son olarak, sonuç kalitesini test edeceğiz. Model Değerlendirme modülünü seçip deneme tuvaline sürükleyin ve Model Puanlama modülünün çıkışını Model Değerlendirme modülünün sol giriş bağlantı noktasına bağlayın. Son deneme şuna benzer şekilde görünecektir:
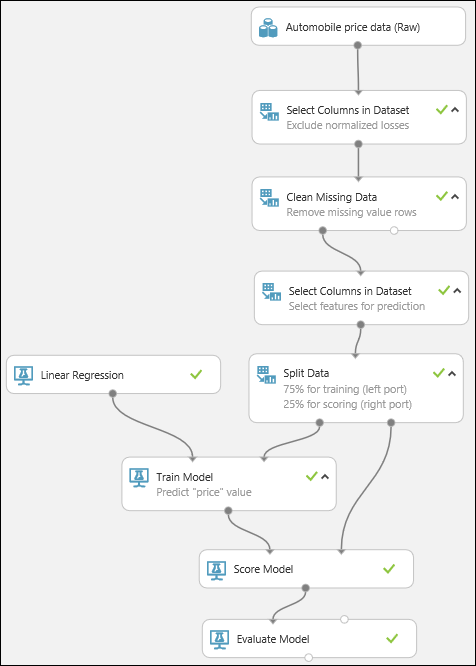
Denemeyi çalıştırın.
Model Değerlendirme modülünden çıkışı görüntülemek için, çıkış bağlantı noktasına tıklayın ve ardından Görselleştir'i seçin.
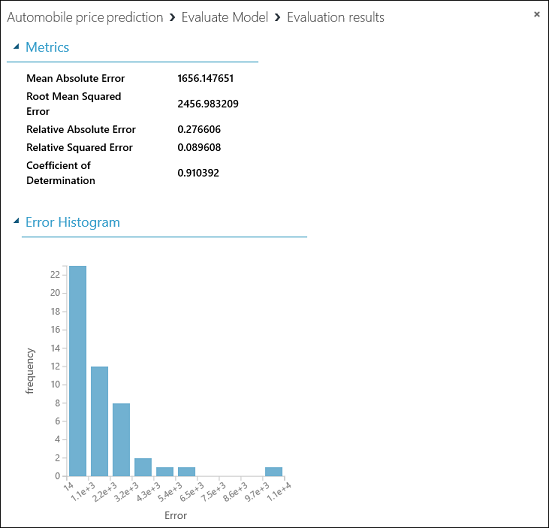
Modelimiz için aşağıdaki istatistikler gösterilir:
- Mean Absolute Error (Ortalama Mutlak Hata) (MAE): Mutlak hataların ortalaması (hata, tahmin edilen değer ile gerçek değer arasındaki farktır).
- Root Mean Squared Error (Kök Ortalama Karesi Alınmış Hata) (RMSE): Test veri kümesinde yapılan tahminlerin karesi alınmış hata ortalamasının kare kökü.
- Relative Absolute Error (Göreli Mutlak Hata): Gerçek değerler ve tüm gerçek değerlerin ortalaması arasındaki mutlak hataların mutlak farka göreli ortalaması.
- Relative Squared Error (Göreli Karesi Alınmış Hata): Gerçek değerlerin ve tüm gerçek değerlerin ortalamasının karesi arasındaki farkın karesine göre hataların ortalaması.
- Coefficient of Determination (Determinasyon Katsayısı): R karesi alınmış değer olarak da bilinen ve modelin verilere ne kadar iyi uyumlu olduğunu gösteren istatistik ölçümleridir.
Her bir hata istatistiği ne kadar küçük olursa o kadar iyidir. Daha küçük olan bir değer, tahminlerin gerçek değerlerle daha yakından eşleştiğini gösterir. Coefficient of Determination (Determinasyon Katsayısı) değeri bire (1.0) ne kadar yakınsa tahminler o kadar iyi olur.
Kaynakları temizleme
Bu makaleyi kullanarak oluşturduğunuz kaynaklara artık ihtiyacınız yoksa ücret ödememek için bunları silin. Ürün içi kullanıcı verilerini dışarı aktarma ve silme makalesinde nasıl yapılacağını öğrenin.
Sonraki adımlar
Bu hızlı başlangıçta örnek veri kümesini kullanarak basit bir deneme oluşturdunuz. Model oluşturma ve dağıtma sürecini daha ayrıntılı bir şekilde incelemek için tahmine dayalı çözüm öğreticisine geçin.