Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
ŞUNLAR IÇIN GEÇERLIDIR: Machine Learning Studio (klasik)
Machine Learning Studio (klasik)  Azure Machine Learning
Azure Machine Learning
Önemli
Machine Learning Stüdyosu (klasik) desteği 31 Ağustos 2024'te sona erecektir. Bu tarihe kadar Azure Machine Learning'e geçmenizi öneririz.
1 Aralık 2021'den başlayarak artık yeni Machine Learning Stüdyosu (klasik) kaynakları oluşturamayacaksınız. 31 Ağustos 2024'e kadar mevcut Machine Learning Stüdyosu (klasik) kaynaklarını kullanmaya devam edebilirsiniz.
- Makine öğrenmesi projelerini ML Studio'dan (klasik) Azure Machine Learning'e taşıma hakkındaki bilgilere bakın.
- Azure Machine Learning hakkında daha fazla bilgi edinin
ML Stüdyosu (klasik) belgeleri kullanımdan kaldırılacak ve gelecekte güncelleştirilmeyecektir.
Bu öğreticide, tahmine dayalı analiz çözümü geliştirme sürecine genişletilmiş bir bakış sunarsınız. Machine Learning Studio'da (klasik) basit bir model geliştirirsiniz. Ardından modeli Machine Learning web hizmeti olarak dağıtırsınız. Dağıtılan bu model, yeni verileri kullanarak tahminlerde bulunabilir. Bu öğretici, üç bölümden oluşan bir öğretici serisinin birinci bölümüdür.
Bir kişinin kredi başvurusunda verdiği bilgilere dayanarak kredi riskini tahmin etmeniz gerektiğini varsayalım.
Kredi riski değerlendirmesi karmaşık bir sorundur, ancak bu öğretici bunu biraz basitleştirir. Bunu, Machine Learning Studio (klasik) kullanarak tahmine dayalı analiz çözümü oluşturma örneği olarak kullanacaksınız. Bu çözüm için aMachine Learning Studio (klasik) ve Machine Learning web hizmeti kullanacaksınız.
Bu üç bölümlü öğreticide, genel kullanıma açık kredi riski verileriyle başlayacaksınız. Ardından tahmine dayalı bir model geliştirip eğitebilirsiniz. Son olarak modeli bir web hizmeti olarak dağıtırsınız.
Bu bölümde yapacaklarınız:
- Machine Learning Studio (klasik) çalışma alanı oluşturma
- Mevcut verileri yükleme
- Deneme oluşturma
Daha sonra bu denemeyi kullanarak 2 . bölümdeki modelleri eğitebilir ve ardından bunları 3. bölümde dağıtabilirsiniz.
Önkoşullar
Bu öğreticide, Machine Learning Studio'yu (klasik) daha önce en az bir kez kullandığınız ve makine öğrenmesi kavramları hakkında bilgi sahibi olduğunuz varsayılır. Ancak ikisinde birden uzman olduğunuz varsayılmaz.
Machine Learning Studio'yu (klasik) daha önce hiç kullanmadıysanız, hızlı başlangıç olan Machine Learning Studio'da ilk veri bilimi denemenizi oluşturma (klasik) ile başlamak isteyebilirsiniz. Hızlı Başlangıç Rehberi, size Machine Learning Studio (klasik) ile ilk kez çalışma olanağı tanır. Modülleri nasıl sürükleyip bırakacağınız, birbirine nasıl bağlayacağınız, denemeyi nasıl çalıştıracağınız ve sonuçları nasıl inceleyeceğiniz konusunda temel bilgiler verilir.
İpucu
Bu öğreticide geliştirdiğiniz denemenin çalışan bir kopyasını Azure AI Galerisi'nde bulabilirsiniz. Öğretici - Kredi riskini tahmin etme bölümüne gidin ve denemenin bir kopyasını Machine Learning Studio (klasik) çalışma alanınıza indirmek için Studio'da Aç'a tıklayın.
Machine Learning Studio (klasik) çalışma alanı oluşturma
Machine Learning Studio'yu (klasik) kullanmak için bir Machine Learning Studio (klasik) çalışma alanınız olmalıdır. Bu çalışma alanı, denemeleri oluşturmak, yönetmek ve yayımlamak için ihtiyacınız olan araçları içerir.
Çalışma alanı oluşturmak için Machine Learning Studio (klasik) çalışma alanı oluşturma ve paylaşma başlığına bakın.
Çalışma alanınız oluşturulduktan sonra Machine Learning Studio (klasik) (https://studio.azureml.net/Home öğesini açın. Birden fazla çalışma alanınız varsa, pencerenin sağ üst köşesindeki araç çubuğunda çalışma alanını seçebilirsiniz.
İpucu
Çalışma alanının sahibiyseniz, çalışma alanına başkalarını davet ederek üzerinde çalıştığınız denemeleri paylaşabilirsiniz. Bunu, AYARLAR sayfasında Machine Learning Studio'da (klasik) yapabilirsiniz. Yalnızca her kullanıcı için Microsoft hesabına veya kuruluş hesabına ihtiyacınız vardır.
AYARLAR sayfasında KULLANICILAR'a tıklayın, ardından pencerenin alt kısmındaki DAHA FAZLA KULLANICI DAVET ET'e tıklayın.
Mevcut verileri yükleme
Kredi riski için tahmine dayalı bir model geliştirmek için modeli eğitmek ve test etmek için kullanabileceğiniz verilere ihtiyacınız vardır. Bu öğretici için UC Irvine Makine Öğrenimi deposundaki "UCI Statlog (Almanca Kredi Verileri) Veri Kümesi"ni kullanacaksınız. Burada bulabilirsiniz:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
german.data adlı dosyayı kullanacaksınız. Bu dosyayı yerel sabit sürücünüze indirin.
german.data veri kümesi, kredi için geçmiş 1000 başvuru sahibi için 20 değişkenden oluşan satırlar içerir. Bu 20 değişken, veri kümesinin her kredi başvurusu için tanımlayıcı özellikler sağlayan özellik kümesini ( özellik vektöru) temsil eder. Her satırdaki ek bir sütun, başvuranın hesaplanan kredi riskini temsil eder ve 700 başvuru sahibi düşük kredi riski ve 300'ün yüksek risk olarak tanımlanmıştır.
UCI web sitesi, bu veriler için özellik vektörünün özniteliklerinin açıklamasını sağlar. Bu veriler finansal bilgileri, kredi geçmişini, çalışma durumunu ve kişisel bilgileri içerir. Her başvuru sahibi için düşük veya yüksek kredi riski olup olmadığını belirten bir ikili derecelendirme verilmiştir.
Tahmine dayalı analiz modelini eğitmek için bu verileri kullanacaksınız. İşiniz bittiğinde modelinizin yeni bir birey için özellik vektörlerini kabul edebilmesi ve düşük veya yüksek kredi riski olup olmadığını tahmin edebilmesi gerekir.
İşte ilginç bir dönüş.
UCI web sitesindeki veri kümesinin açıklaması, bir kişinin kredi riskini yanlış sınıflandırmanız durumunda maliyetinden bahseder. Model, düşük kredi riski olan biri için yüksek kredi riski tahmininde bulunuyorsa, model yanlış sınıflandırma yapmıştır.
Ancak ters sınıflandırma, finansal kurum için beş kat daha maliyetlidir: Model, aslında yüksek kredi riski olan biri için düşük kredi riski öngörüyorsa.
Bu nedenle, modelinizi, bu ikinci tür yanlış sınıflandırmanın maliyetinin diğer şekilde yanlış sınıflandırmaktan beş kat daha yüksek olması için eğitmek istiyorsunuz.
Denemenizde modeli eğitirken bunu yapmanın basit bir yolu, yüksek kredi riski olan birini temsil eden girişlerin çoğaltılarak (beş kez) yapılmasıdır.
Daha sonra model, gerçekten yüksek riskli olan bir kişiyi düşük kredi riski olarak yanlış sınıflandırırsa, model aynı yanlış sınıflandırmayı her yineleme için bir kez olmak üzere beş kez yapar. Bu, eğitim sonuçlarında bu hatanın maliyetini artırır.
Veri kümesi biçimini dönüştürme
Özgün veri kümesi boş ayrılmış bir biçim kullanır. Machine Learning Studio (klasik), virgülle ayrılmış değer (CSV) dosyasıyla daha iyi çalıştığından boşlukları virgülle değiştirerek veri kümesini dönüştüreceksiniz.
Bu verileri dönüştürmenin birçok yolu vardır. Bunun bir yolu, aşağıdaki Windows PowerShell komutunu kullanmaktır:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Bir diğer yol da Unix sed komutunu kullanmaktır:
sed 's/ /,/g' german.data > german.csv
Her iki durumda da, denemenizde kullanabileceğiniz german.csv adlı bir dosyada verilerin virgülle ayrılmış bir sürümünü oluşturdunuz.
Veri kümesini Machine Learning Studio'ya yükleme (klasik)
Veriler CSV biçimine dönüştürüldükten sonra, bunları Machine Learning Studio'ya (klasik) yüklemeniz gerekir.
Machine Learning Studio (klasik) giriş sayfasını (https://studio.azureml.net) açın.
Pencerenin sol üst köşesindeki menüye
 tıklayın, Azure Machine Learning'e tıklayın, Studio'yu seçin ve oturum açın.
tıklayın, Azure Machine Learning'e tıklayın, Studio'yu seçin ve oturum açın.Pencerenin alt kısmındaki +YENİ'ye tıklayın.
VERİ KÜMESİ'ni seçin.
YEREL DOSYADAN seçin.
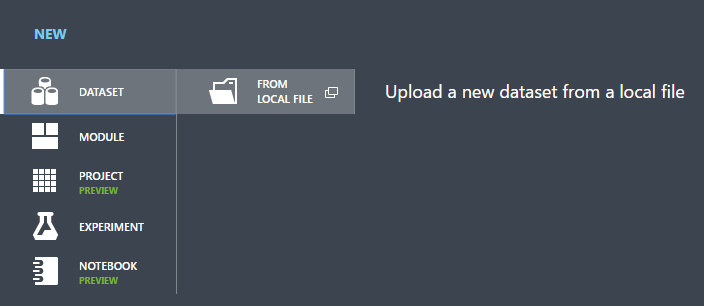
Yeni veri kümesi yükleme iletişim kutusunda, Gözat'a tıklayın ve oluşturduğunuz german.csv dosyasını bulun.
Veri kümesi için bir ad girin. Bu öğretici için "UCI Alman Kredi Kartı Verileri" olarak adlandırabilirsiniz.
Veri türü için Üst bilgi içermeyen Genel CSV Dosyası (.nh.csv) öğesini seçin.
İstersenize bir açıklama ekleyin.
Tamam onay işaretine tıklayın.
Bu, verileri bir denemede kullanabileceğiniz bir veri kümesi modülüne yükler.
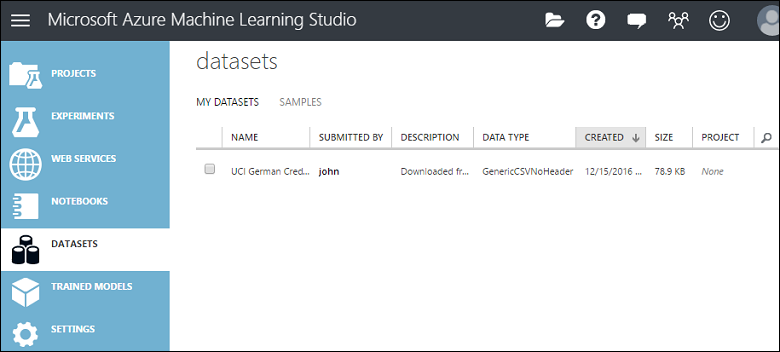
Studio (klasik) penceresinin sol kısmındaki DATASETS sekmesine tıklayarak Studio'ya (klasik) yüklediğiniz veri kümelerini yönetebilirsiniz.
Diğer veri türlerini bir denemeye aktarma hakkında daha fazla bilgi için bkz . Eğitim verilerinizi Machine Learning Studio'ya (klasik) aktarma.
Deneme oluşturma
Bu öğreticinin sonraki adımı, Machine Learning Studio (klasik) içinde yüklediğiniz veri kümesini kullanan bir eksperimen oluşturmaktır.
Studio'da (klasik) pencerenin alt kısmındaki +YENİ'ye tıklayın.
EXPERIMENT sekmesini seçin ve ardından "Boş Deney" seçeneğini seçin.
Tuvalin üst kısmındaki varsayılan deneme adını seçin ve anlamlı bir adla yeniden adlandırın.

İpucu
Özellikler bölmesinde deneme için Özet ve Açıklama'nın doldurulması iyi bir uygulamadır. Bu özellikler, daha sonra buna bakan herkesin hedeflerinizi ve metodolojinizi anlaması için denemeyi belgeleme fırsatı verir.

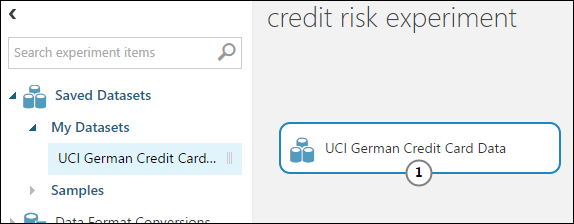
Deneme tuvalinin sol kısmındaki modül paletinde Kayıtlı Veri Kümeleri'ni genişletin.
Veri Kümelerim altında oluşturduğunuz veri kümesini bulun ve tuvale sürükleyin. Paletin üstündeki Arama kutusuna adı girerek de veri kümesini bulabilirsiniz.
Verileri hazırlama
Verilerin ilk 100 satırını ve veri kümesinin tamamı için bazı istatistiksel bilgileri görüntüleyebilirsiniz: Veri kümesinin çıkış bağlantı noktasına (alttaki küçük daire) tıklayın ve Görselleştir'i seçin.
Veri dosyası sütun başlıklarıyla birlikte gelmediğinden, Studio (klasik) genel başlıklar (Col1, Col2 vb .) sağlamıştır. İyi başlıklar model oluşturmak için gerekli değildir, ancak denemedeki verilerle çalışmayı kolaylaştırır. Ayrıca, sonunda bu modeli bir web hizmetinde yayımladığınızda, başlıklar hizmetin kullanıcısına sütunları tanımlamaya yardımcı olur.
Meta Verileri Düzenle modülünü kullanarak sütun başlıkları ekleyebilirsiniz.
Veri kümesiyle ilişkili meta verileri değiştirmek için Meta Verileri Düzenle modülünü kullanırsınız. Bu durumda, sütun başlıkları için daha kolay adlar sağlamak için bunu kullanırsınız.
Meta Verileri Düzenle'yi kullanmak için önce hangi sütunların değiştirileceğini belirtirsiniz (bu örnekte, bunların tümü).) Ardından, bu sütunlarda gerçekleştirilecek eylemi belirtirsiniz (bu örnekte sütun başlıklarını değiştirirsiniz.)
Modül paletinde, Arama kutusuna "meta veriler" yazın. Meta Verileri Düzenle modülü listesinde görünür.
Meta Verileri Düzenle modülüne tıklayıp tuvale sürükleyin ve daha önce eklediğiniz veri kümesinin altına bırakın.
Veri kümesini Meta Verileri Düzenle'ye bağlayın: Veri kümesinin çıkış bağlantı noktasına (veri kümesinin altındaki küçük daire) tıklayın, Meta Verileri Düzenle giriş bağlantı noktasına (modülün üst kısmındaki küçük daire) sürükleyin ve fare düğmesini bırakın. Tuvalde gezinseniz bile veri kümesi ve modül bağlı kalır.
Deneme şu şekilde görünmelidir:
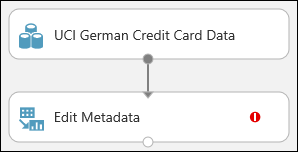
Kırmızı ünlem işareti, bu modülün özelliklerini henüz ayarlamadığınıza işaret eder. Bundan sonra o işlemi yapacaksınız.
İpucu
Modüle çift tıklayıp metin girerek bir modüle yorum ekleyebilirsiniz. Bu, modülün denemenizde ne işe yaradığını bir bakışta görmenize yardımcı olabilir. Bu durumda, Meta Verileri Düzenle modülüne çift tıklayın ve "Sütun başlıkları ekle" açıklamasını yazın. Metin kutusunu kapatmak için tuvalde başka bir yere tıklayın. Açıklamayı görüntülemek için modüldeki aşağı oka tıklayın.
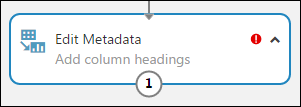
Meta Verilerini Düzenle'yi seçin ve tuvalin sağındaki Özellikler bölmesinde Sütun seçicisini başlat'a tıklayın.
Sütunları seç iletişim kutusunda Kullanılabilir Sütunlar'daki tıklayın>. Diyalog kutusu şöyle görünmelidir:
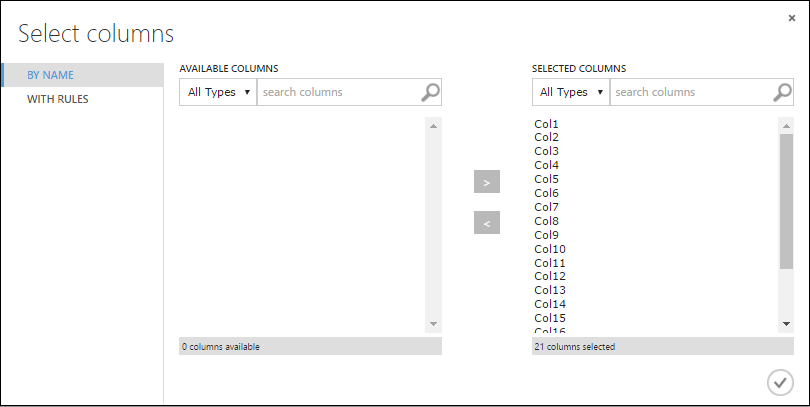
Tamam onay işaretine tıklayın.
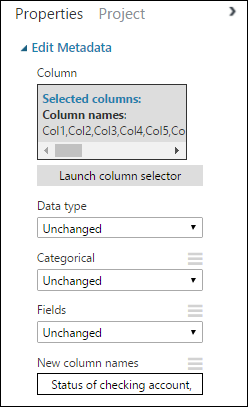
Özellikler bölmesine dönüp Yeni sütun adları parametresini arayın. Bu alana, veri kümesindeki 21 sütun için virgülle ve sütun sırasına göre ayrılmış bir ad listesi girin. UCI web sitesindeki veri kümesi belgelerinden sütun adlarını alabilir veya kolaylık sağlamak için aşağıdaki listeyi kopyalayıp yapıştırabilirsiniz:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskÖzellikler bölmesi şöyle görünür:
İpucu
Sütun başlıklarını doğrulamak istiyorsanız denemeyi çalıştırın (deneme tuvalinin altındaki ÇALıŞTıR'a tıklayın). Çalıştırma tamamlandığında (Meta Verileri Düzenle'de yeşil bir onay işareti görünür), Meta Verileri Düzenle modülünün çıkış bağlantı noktasına tıklayın ve Görselleştir'i seçin. Deneme aracılığıyla verilerin ilerleme durumunu görüntülemek için herhangi bir modülün çıkışını aynı şekilde görüntüleyebilirsiniz.
Eğitim ve test veri kümeleri oluşturma
Modeli eğitmek için bazı verilere ve test etmek için bazı verilere ihtiyacınız vardır. Bu nedenle, denemenin bir sonraki adımında veri kümesini iki ayrı veri kümesine bölersiniz: modelimizi eğitme ve test için bir veri kümesi.
Bunu yapmak için Verileri Bölme modülünü kullanırsınız.
Verileri Bölme modülünü bulun, tuvale sürükleyin ve Meta Verileri Düzenle modülüne bağlayın.
Varsayılan olarak, bölme oranı 0,5'tir ve Rastgele bölme parametresi ayarlanır. Bu, verilerin rastgele yarısının Verileri Bölme modülünün bir portundan ve diğer yarısının diğer portundan çıktığı anlamına gelir. Eğitim ve test verileri arasındaki bölmeyi değiştirmek için bu parametreleri ve Rastgele tohum parametresini ayarlayabilirsiniz. Bu örnekte, bunları olduğu gibi bırakırsınız.
İpucu
İlk çıkış veri kümesindeki satırların kesiri özelliği, verilerin ne kadarının sol çıkış bağlantı noktasından çıkış yapılacağını belirler. Örneğin, oranı 0,7 olarak ayarlarsanız verilerin %70'i sol bağlantı noktasından ve %30'unun sağ bağlantı noktasından çıkışını alır.
Verileri Bölme modülüne çift tıklayın ve "Eğitim/test verileri %50 bölünür" açıklamasını girin.
Verileri Bölme modülünün çıkışlarını istediğiniz gibi kullanabilirsiniz, ancak şimdi eğitim verileri olarak sol çıkışı ve test verileri olarak sağ çıkışı kullanmayı seçelim.
Önceki adımda belirtildiği gibi, yüksek kredi riskini düşük olarak yanlış sınıflandırmanın maliyeti, düşük kredi riskini yüksek olarak yanlış sınıflandırma maliyetinden beş kat daha yüksektir. Bunu hesaba katmanız için bu maliyet işlevini yansıtan yeni bir veri kümesi oluşturursunuz. Yeni veri kümesinde her yüksek riskli örnek beş kez çoğaltılırken, düşük riskli her örnek çoğaltılmaz.
R kodunu kullanarak bu çoğaltmayı yapabilirsiniz:
Yürüt R Betiği modülünü bulup deney tuvasına sürükleyin.
Verileri Bölme modülünün sol çıkış bağlantı noktasını R Betiği Yürütme modülünün ilk giriş bağlantı noktasına ("Veri Kümesi1") bağlayın.
R Betiğini Yürüt modülüne çift tıklayın ve "Maliyet ayarlamasını ayarla" açıklamasını girin.
Özellikler bölmesinde, R Betiği parametresindeki varsayılan metni silin ve şu betiği girin:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")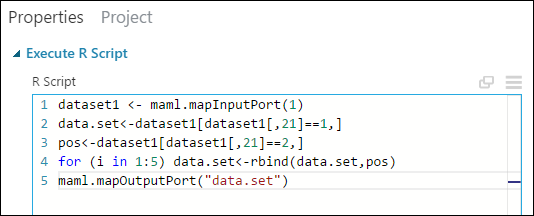
Eğitim ve test verilerinin aynı maliyet ayarlamasına sahip olması için Verileri Bölme modülünün her çıkışı için aynı çoğaltma işlemini yapmanız gerekir. Bunu yapmanın en kolay yolu, az önce oluşturduğunuz R Betiğini Yürütme modülünü çoğaltmak ve bunu Verileri Bölme modülünün diğer çıkış bağlantı noktasına bağlamaktır.
R Betiği Yürütme modülüne sağ tıklayın ve Kopyala'yı seçin.
Deneme tuvalini sağ tıklatın ve Yapıştır'ı seçin.
Yeni modülü konuma sürükleyin ve ardından Verileri Bölme modülünün doğru çıkış bağlantı noktasını bu yeni R Betiğini Yürüt modülünün ilk giriş bağlantı noktasına bağlayın.
Tuvalin en altında Çalıştır'a tıklayın.
İpucu
R Betiği Yürütme modülünün kopyası, özgün modülle aynı betiği içerir. Tuvale bir modül kopyalayıp yapıştırdığınızda, kopya özgün modülün tüm özelliklerini korur.
Denememiz şu şekilde görünür:
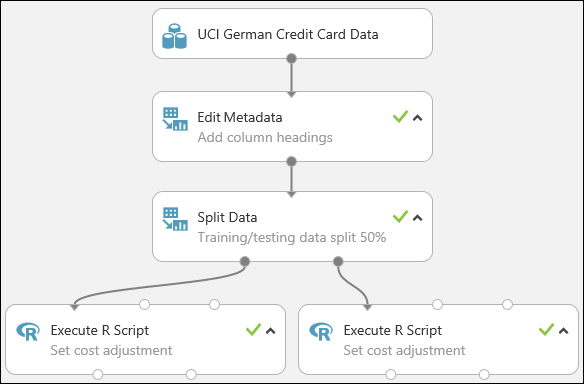
Denemelerinizde R betiklerini kullanma hakkında daha fazla bilgi için bkz . Denemenizi R ile genişletme.
Kaynakları temizleme
Bu makaleyi kullanarak oluşturduğunuz kaynaklara artık ihtiyacınız yoksa ücret ödememek için bunları silin. Ürün içi kullanıcı verilerini dışarı aktarma ve silme makalesinde nasıl yapılacağını öğrenin.
Sonraki adımlar
Bu öğreticide şu adımları tamamladınız:
- Machine Learning Studio (klasik) çalışma alanı oluşturma
- Var olan verileri çalışma alanına yükleme
- Deneme oluşturma
Artık bu veriler için modelleri eğitmeye ve değerlendirmeye hazırsınız.