Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu makalede, SQL Server'ın Enterprise sürümünde bir veya daha fazla kullanılabilirlik grubunu yapılandırmak ve yönetmek için merkezi olan Always On kullanılabilirlik grupları kavramları tanıtılır. Standart sürüm için , tek bir veritabanı için Temel Always On kullanılabilirlik gruplarını gözden geçirin.
Always On kullanılabilirlik grupları özelliği, veritabanı yansıtmaya kurumsal düzeyde bir alternatif sağlayan yüksek kullanılabilirlik ve olağanüstü durum kurtarma çözümüdür. Always On kullanılabilirlik grupları, bir kuruluş için bir kullanıcı veritabanı kümesinin kullanılabilirliğini en üst düzeye çıkarır. Kullanılabilirlik grubu, birlikte yük devreden kullanılabilirlik veritabanları olarak bilinen ayrık bir kullanıcı veritabanı kümesi için yük devretme ortamını destekler. Kullanılabilirlik grubu, bir dizi okuma-yazma birincil veritabanını ve bir ile sekiz arasında karşılık gelen ikincil veritabanı kümesini destekler. İsteğe bağlı olarak, ikincil veritabanları salt okunur erişim ve/veya bazı yedekleme işlemleri için kullanılabilir hale getirilebilir.
Azure Arc tarafından etkinleştirilen SQL Server ile kullanılabilirlik gruplarını Azure portalında görüntüleyebilirsiniz.
Genel Bakış
Kullanılabilirlik grubu, kullanılabilirlik veritabanları olarak bilinen ayrık bir kullanıcı veritabanı kümesi için çoğaltılmış bir ortamı destekler. Yüksek kullanılabilirlik (HA) veya okuma kapasitesi için bir kullanılabilirlik grubu oluşturabilirsiniz. HA yüksek kullanılabilirlik grubu, birlikte devreden bir veritabanı grubudur. Okuma ölçeği kullanılabilirlik grubu, salt okunur iş yükü için SQL Server'ın diğer örneklerine kopyalanan bir veritabanı grubudur. Kullanılabilirlik grubu, bir birincil veritabanı kümesini ve bir ile sekiz arasında karşılık gelen ikincil veritabanı kümesini destekler. İkincil veritabanları yedek değildir. Veritabanlarınızı ve bunların işlem günlüklerini düzenli olarak yedeklemeye devam edin.
Tavsiye
Birincil veritabanının herhangi bir yedekleme türünü oluşturabilirsiniz. Alternatif olarak, günlük yedeklemeleri ve ikincil veritabanlarının yalnızca kopya tam yedeklemelerini oluşturabilirsiniz. Daha fazla bilgi için bkz. Desteklenen yedeklemeleri bir kullanılabilirlik grubunun ikincil çoğaltmalarına boşaltma.
Her kullanılabilirlik veritabanı kümesi bir erişilebilirlik replikası tarafından barındırılır. İki tür kullanılabilirlik çoğaltması vardır: birincil veritabanlarını barındıran tek bir birincil çoğaltma ve her biri bir dizi ikincil veritabanını barındıran ve kullanılabilirlik grubu için olası yük devretme hedefleri olarak görev yapan bir-sekiz ikincil çoğaltma. Kullanılabilirlik grubu, kullanılabilirlik çoğaltması düzeyinde yük devreder. Kullanılabilirlik çoğaltması, tek bir kullanılabilirlik grubundaki veritabanı kümesi için yalnızca veritabanı düzeyinde yedeklilik sağlar. Yük devretme işlemleri, veri dosyasının kaybolması veya işlem günlüğünün bozulması nedeniyle veritabanının şüpheli duruma gelmesi gibi veritabanı sorunlarından kaynaklanmamıştır.
Birincil çoğaltma, birincil veritabanlarını istemcilerden gelen okuma-yazma bağlantıları için kullanılabilir hale getirir. Birincil replikasyon, birincil veritabanlarının işlem günlüğü kayıtlarını her bir ikincil veritabanına gönderir. Veri eşitleme olarak bilinen bu işlem veritabanı düzeyinde gerçekleşir. Her ikincil çoğaltma işlem günlüğü kayıtlarını önbelleğe alır (günlüğü sağlamlaştırır ) ve ardından bunları ilgili ikincil veritabanına uygular. Veri eşitleme, birincil veritabanı ile bağlı her ikincil veritabanı arasında diğer veritabanlarından bağımsız olarak gerçekleşir. Bu nedenle, ikincil veritabanı diğer ikincil veritabanlarını etkilemeden başarısız olabilir veya askıya alınabilir ve birincil veritabanı diğer birincil veritabanlarını etkilemeden başarısız olabilir veya askıya alınabilir.
İsteğe bağlı olarak, ikincil veritabanlarına salt okunur erişimi desteklemek için bir veya daha fazla ikincil çoğaltma yapılandırabilir ve ikincil veritabanlarında yedeklemelere izin vermek için herhangi bir ikincil çoğaltmayı yapılandırabilirsiniz.
SQL Server 2017 (14.x), kullanılabilirlik grupları için iki farklı mimari kullanıma sunulmuştur. Always On kullanılabilirlik grupları yüksek kullanılabilirlik, olağanüstü durum kurtarma ve okuma ölçeği dengelemesi sağlar. Bu kullanılabilirlik grupları için bir küme yöneticisi gerekir. Windows'da hata toleranslı kümelenme özelliği, küme yöneticisini sağlar. Linux'ta Pacemaker'ı kullanabilirsiniz. Diğer mimari ise okuma ölçekli kullanılabilirlik grubudur. Okuma ölçeği kullanılabilirlik grubu, salt okunur iş yükleri için çoğaltmalar sağlar ancak yüksek kullanılabilirlik sağlamaz. Okuma ölçeği kullanılabilirlik grubunda küme yönetimi yoktur çünkü yük devretme otomatik olarak yapılamaz.
Windows'da HA için Always On kullanılabilirlik gruplarının dağıtılması için bir Windows Server Yük Devretme Kümesi (WSFC) gerekir. Belirli bir kullanılabilirlik grubunun her kullanılabilirlik çoğaltması aynı WSFC'nin farklı bir düğümünde bulunmalıdır. Tek istisna, başka bir WSFC kümesine geçirilirken bir kullanılabilirlik grubunun geçici olarak iki kümeyi birleştirebileceğidir.
Uyarı
Linux'ta kullanılabilirlik grupları hakkında bilgi için bkz. Linux üzerinde SQL Server için kullanılabilirlik grupları.
BIR HA yapılandırmasında, oluşturduğunuz her kullanılabilirlik grubu için bir küme rolü oluşturulur. WSFC kümesi, birincil çoğaltmanın durumunu değerlendirmek için bu rolü izler. Always On kullanılabilirlik grupları için yeter sayı, belirli bir küme düğümünün herhangi bir kullanılabilirlik kopyalarını barındırıp barındırmadığına bakılmaksızın WSFC kümesindeki tüm düğümlere dayanır. Veritabanı yansıtma ile karşılaştırıldığında, Always On kullanılabilirlik gruplarında tanık rolü bulunmamaktadır.
Uyarı
SQL Server AlwaysOn bileşenlerinin WSFC kümesiyle ilişkisi hakkında bilgi için bkz. SQL Server ile Windows Server Yük Devretme Kümelemesi.
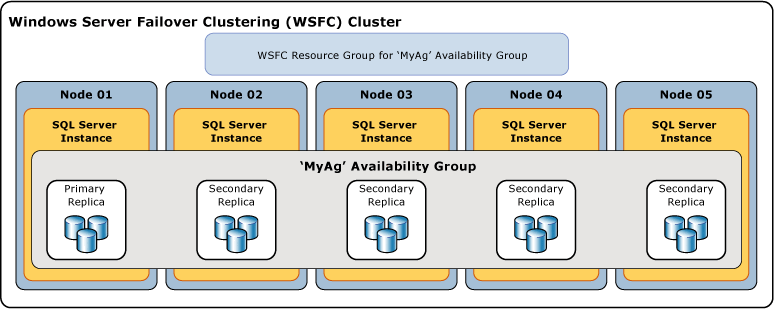
Aşağıdaki çizimde, bir birincil çoğaltma ve dört ikincil çoğaltma içeren bir kullanılabilirlik grubu gösterilmektedir. Bir birincil kopya ve dört eşzamanlı taahhüt yedek kopya da dahil olmak üzere en fazla sekiz yedek kopya desteklenmektedir.
TLS 1.3 şifrelemeyi yapılandırma
SQL Server 2025 (17.x), Windows Server Yük Devretme Kümesi ile Always On kullanılabilirlik grubu çoğaltmalarınız arasındaki iletişim için TLS 1.3 şifrelemesini zorunlu kılmanıza olanak tanıyan Tablosal Veri Akışı 8.0 desteği sağlar.
Daha fazla bilgi için bu makalenin devamında yer alan SQL Server 2025'te TDS 8 desteği konusuna bakın.
Başlamak için Katı şifreleme ile bağlanma'yı gözden geçirin.
Terimler ve tanımlar
| Süre | Açıklama |
|---|---|
| kullanılabilirlik grubu | Birlikte yük devreden kullanılabilirlik veritabanları için bir kapsayıcı. |
| kullanılabilirlik veritabanı | Kullanılabilirlik grubuna ait bir veritabanı. Kullanılabilirlik grubu her kullanılabilirlik veritabanı için tek bir okuma-yazma kopyası ( birincil veritabanı) ve bir ile sekiz arasında salt okunur kopya (ikincil veritabanları) tutar. |
| birincil veritabanı | Kullanılabilirlik veritabanının okuma-yazma kopyası. |
| ikincil veritabanı | Kullanılabilirlik veritabanının salt okunur kopyası. |
| kullanılabilirlik yedeği | Belirli bir SQL Server örneği tarafından barındırılan ve her bir kullanılabilirlik veritabanının yerel bir kopyasını tutan bir kullanılabilirlik grubu örneklemesi. İki tür kullanılabilirlik çoğaltması vardır: tek bir birincil çoğaltma ve bir ile sekiz ikincil çoğaltma. |
| ana kopya | Birincil veritabanlarını istemcilerden okuma-yazma bağlantıları için erişilebilir hale getiren, ayrıca her bir birincil veritabanı için işlem günlüğü kayıtlarını her bir ikincil çoğaltmaya gönderen erişilebilirlik çoğaltması. |
| ikincil kopya | Her kullanılabilirlik veritabanının ikincil bir kopyasını tutan ve kullanılabilirlik grubu için olası yük devretme hedefleri olarak hizmet veren bir kullanılabilirlik çoğaltması. İsteğe bağlı olarak, ikincil çoğaltma ikincil veritabanlarına salt okunur erişimi destekleyebilir, ikincil veritabanlarında yedekleme oluşturmayı destekleyebilir. |
| kullanılabilirlik grubu dinleyicisi | Kullanılabilirlik grubunun birincil veya ikincil çoğaltmasında bulunan bir veritabanına erişmek için istemcilerin bağlanabileceği sunucu adı. Kullanılabilirlik grubu dinleyicileri, gelen bağlantıları birincil çoğaltıcıya veya salt okunur ikincil çoğaltıcıya yönlendirir. |
Kullanılabilirlik veritabanları
Kullanılabilirlik grubuna veritabanı eklemek için veritabanının, birincil çoğaltmayı barındıran sunucu örneğinde bulunan çevrimiçi, okuma-yazma veritabanı olması gerekir. Veritabanı eklediğinizde, kullanılabilirlik grubu birincil veritabanı olarak birleştirilir ve istemciler tarafından kullanılabilir durumda kalır. Yeni birincil veritabanının yedeklerini ikincil çoğaltmayı barındıran sunucu örneğine geri yükleyene kadar, ilişkili bir ikincil veritabanı mevcut değildir (örneğin RESTORE WITH NORECOVERY kullanarak). Yeni ikincil veritabanı kullanılabilirlik grubuna katılana kadar RESTORING durumundadır. Daha fazla bilgi için bkz. Her Zaman Açık İkincil Veritabanında (SQL Server) Veri Taşımayı Başlatma.
Birleştirme, ikincil veritabanını ONLINE durumuna yerleştirir ve ilgili birincil veritabanıyla veri eşitlemesini başlatır.
Veri eşitleme , birincil veritabanında yapılan değişikliklerin ikincil veritabanında yeniden üretildiği işlemdir. Veri eşitleme, birincil veritabanının ikincil veritabanına işlem günlüğü kayıtları göndermesini içerir.
Önemli
Kullanılabilirlik veritabanı bazen Transact-SQL, PowerShell ve SQL Server Yönetim Nesneleri (SMO) adlarında veritabanı çoğaltması olarak adlandırılır. Örneğin, kullanılabilirlik veritabanları hakkında bilgi döndüren Always On dinamik yönetim görünümlerinin adlarında "veritabanı çoğaltması" terimi kullanılır: sys.dm_hadr_database_replica_states ve sys.dm_hadr_database_replica_cluster_states. Ancak SQL Server Books Online'da "replika" terimi genellikle kullanılabilirlik replikalarını ifade eder. Örneğin, "birincil replika" ve "ikincil replika" her zaman erişilebilirlik replikalarına atıfta bulunur.
Kullanılabilirlik replikaları
Her kullanılabilirlik grubu, erişilebilirlik replikaları olarak bilinen iki veya daha fazla yük devretme iş ortağı kümesini tanımlar. Kullanılabilirlik çoğaltmaları, kullanılabilirlik grubunun bileşenleridir. Her kullanılabilirlik çoğaltması, kullanılabilirlik grubundaki kullanılabilirlik veritabanlarının bir kopyasını barındırıyor. Belirli bir kullanılabilirlik grubu için, WSFC kümesinin farklı düğümlerinde bulunan ayrı SQL Server örnekleri kullanılabilirlik çoğaltmalarını barındırmalıdır. Bu sunucu örneklerinin her biri Always On için etkinleştirilmelidir.
SQL Server 2019 (15.x), SQL Server 2017'de (14.x) eş zamanlı çoğaltma sayısının üst sınırını 3'ten 5'e yükseltir. Beş çoğaltmadan oluşan bu grubu, grupta otomatik yük devretme olacak şekilde yapılandırabilirsiniz. Bir birincil replika ve dört eşzamanlı ikincil replika vardır.
Belirli bir örnek, kullanılabilirlik grubu başına yalnızca bir kullanılabilirlik çoğaltması barındırabilir. Ancak, her örneği birçok kullanılabilirlik grubu için kullanabilirsiniz. Belirli bir örnek tek başına örnek veya SQL Server yük devretme kümesi örneği (FCI) olabilir. Sunucu düzeyinde yedeklilik gerekiyorsa Yük Devretme Kümesi Örnekleri'ni kullanın.
Her kullanılabilirlik çoğaltmasına bir başlangıç rolü atanır - ya birincil rol ya da bu çoğaltmanın kullanılabilirlik veritabanlarının devraldığı ikincil rol. Belirli bir çoğaltmanın rolü, okuma-yazma veritabanlarını mı yoksa yalnızca okunabilir veritabanlarını mı barındırdığını belirler. Bir birincil kopya olarak bilinen bir kopyaya birincil rol atanır ve okuma-yazma işlemleri yapılabilen birincil veritabanlarını barındırır. En az bir başka replika, ikincil replika olarak bilinir ve ikincil rol üstlenir. İkincil kopya, ikincil veritabanları olarak bilinen salt okunur veritabanlarını barındırır.
Uyarı
Bir kullanılabilirlik çoğaltmasının rolü belirsiz olduğunda, örneğin bir yük devretme esnasında, veritabanları geçici olarak NOT SYNCHRONIZING durumuna geçer. Rolü, kullanılabilirlik çoğaltmasının rolü çözümleninceye kadar RESOLVING olarak ayarlanır. Kullanılabilirlik çoğaltması birincil role çözümlanırsa, veritabanları birincil veritabanları haline gelir. Erişilebilirlik replikası ikincil role çözülürse, veritabanları ikincil veritabanları haline gelir.
Kullanılabilirlik modları
Her kullanılabilirlik replikası bir kullanılabilirlik modu özelliğine sahiptir. Birincil replikaların, belirli bir ikincil replika işlem günlüğü kayıtlarını diske yazana (günlüğü sağlamlaştırana) kadar veritabanındaki işlemleri işlemeyi bekleyip beklemediğini kullanılabilirlik modu belirler. AlwaysOn kullanılabilirlik grupları iki kullanılabilirlik modunu destekler: zaman uyumsuz işleme modu ve zaman uyumlu işleme modu.
Zaman uyumsuz işleme modu
Bu kullanılabilirlik modunu kullanan bir kullanılabilirlik çoğaltması zaman uyumsuz-işlem çoğaltması olarak adlandırılır. Asenkron taahhüt modunda, birincil çoğaltma, işlem günlüklerini sağlamlaştırmak için asenkron taahhüt ikincil çoğaltmalarından onay beklemeden işlemleri taahhüt eder. Zaman uyumsuz işleme modu, ikincil veritabanlarında işlem gecikmesini en aza indirir, ancak birincil veritabanlarının gerisinde kalmalarını sağlayarak bazı veri kaybını mümkün kılar.
Eşzamanlı taahhüt modu
Bu kullanılabilirlik modunu kullanan bir kullanılabilirlik çoğaltması, eş zamanlı taahhüt çoğaltması olarak bilinir. Eşzamanlı onay modunda, işlemleri tamamlamadan önce, eşzamanlı onay birincil replikası, günlüğün sağlamlaştırılmasını tamamladığını onaylamak için eşzamanlı onay ikincil replikasını bekler. Eşzamanlı bağlantı kurma modu, belirli bir ikincil veritabanı birincil veritabanıyla eşitlendikten sonra onaylanan işlemlerin tamamen korunmasını sağlar. Bu koruma, işlem gecikme süresinin artmasına neden olur. Opsiyonel olarak, SQL Server 2017 (14.x), istendiğinde gecikme süresi maliyetinde güvenliği daha da artırmak için zorunlu eşitlenmiş ikincil sunucular özelliğini kullanıma sunar. Özellik, belirli sayıda eşzamanlı çoğaltmanın bir işlemi onaylaması ve bu işlem onaylandıktan sonra birincil çoğaltmanın işlem yapmasına izin verilmesi için etkinleştirilebilir.
Daha fazla bilgi için bkz . AlwaysOn kullanılabilirlik grubu için kullanılabilirlik modları arasındaki farklar.
Yük devretme türleri
Birincil çoğaltma ile ikincil çoğaltma arasındaki oturum bağlamında, birincil ve ikincil roller yük devretme olarak bilinen bir işlemde geçiş yapabilir. Yük devretme sırasında hedef ikincil replikası birincil role dönüşür ve yeni birincil replikası olur. Yeni birincil çoğaltma, veritabanlarını birincil veritabanları olarak çevrimiçine getirir ve istemci uygulamaları bunlara bağlanabilir. Eski birincil çoğaltma kullanılabilir olduğunda, ikincil role geçer ve ikincil çoğaltmaya dönüşür. Eski birincil veritabanları ikincil veritabanlarına dönüşür ve veri senkronizasyonu devam eder.
Kullanılabilirlik grubu, kullanılabilirlik çoğaltması düzeyinde yük devreder. Veri dosyasının kaybolması, veritabanının silinmesi veya işlem günlüğünün bozulması nedeniyle veritabanı şüpheli duruma gelmesi gibi veritabanı sorunları nedeniyle yük devretme gerçekleşmez.
Üç yük devretme biçimi vardır: otomatik, manuel ve zorunlu (olası veri kaybıyla). Belirli bir ikincil çoğaltmanın desteklediği yük devretme biçimi veya biçimleri, belirli bir durumda kullanılabilirlik moduna bağlıdır. Zaman uyumlu işleme modu için, aşağıdaki gibi birincil çoğaltmada ve hedef ikincil çoğaltmada yük devretme moduna da bağlıdır.
Zaman uyumlu yazma modu, hedef ikincil çoğaltma şu anda birincil çoğaltma ile eşitlenmiş durumdaysa planlı el ile yük devretme ve otomatik yük devretme olmak üzere iki yük devretme türünü destekler. Yük devretme iş ortaklarında yük devretme modu özelliğinin ayarı, bu yük devretme biçimleri için desteği belirler. Yük devretme modunu birincil veya ikincil çoğaltmada el ile olarak ayarlarsanız, ikincil çoğaltma yalnızca el ile yük devretmeyi destekler. Hem birincil hem de ikincil çoğaltmalarda yük devretme modunu otomatik olarak ayarlarsanız, ikincil çoğaltma hem otomatik hem de el ile yük devretmeyi destekler.
Planlanmış manuel yük devretme (veri kaybı olmadan)
Veritabanı yöneticisi bir yük devretme komutu verdikten sonra el ile yük devretme gerçekleşir. Senkronize edilmiş ikincil çoğaltmanın (garantili veri koruması ile) birincil role ve birincil çoğaltmanın ikincil role değişmesine neden olur. El ile yük devretme, hem birincil çoğaltmanın hem de hedef ikincil çoğaltmanın zaman uyumlu işleme modunda çalıştırılmasını gerektirir ve ikincil çoğaltmanın zaten eşitlenmiş olması gerekir.
Otomatik yük devretme (veri kaybı olmadan)
Bir hataya yanıt olarak otomatik yük devretme gerçekleşir. Eşitlenmiş ikincil kopyanın, garantili veri koruması ile, birincil role geçmesine neden olur. Eski birincil replika kullanılabilir olduğunda, ikincil role geçer. Otomatik yük devretme, hem birincil çoğaltmanın hem de hedef ikincil çoğaltmanın, yük devretme modu Otomatik olarak ayarlanmış zaman uyumlu işleme modu altında çalıştırılmasını gerektirir. Ayrıca ikincil çoğaltmanın önceden eşitlenmiş olması, WSFC çoğunluk sağlanması ve kullanılabilirlik grubunun esnek yük devretme politikası tarafından belirtilen koşulları karşılaması gerekir.
Asenkron-commit modunda, yük devretmenin tek biçimi (olası veri kaybıyla) genellikle zorunlu yük devretme olarak adlandırılan manuel yük devretmedir. Zorlamalı yük devretme, manuel başlatmanız gerektiği için manuel bir yük devretme biçimidir. Zorunlu yük devretme, olağanüstü durumlarda bir kurtarma seçeneğidir. Hedef ikincil çoğaltma birincil çoğaltmayla eşitlenmediğinde mümkün olan tek yük devretme biçimidir.
Daha fazla bilgi için bkz. Yük Devretme ve Yük Devretme Modları (Always On Kullanılabilirlik Grupları)
Önemli
- SQL Server Yük Devretme Kümesi Örnekleri (FCI) kullanılabilirlik grupları tarafından otomatik yük devretmeyi desteklemez, bu nedenle yalnızca FCI'nin barındırdığı kullanılabilirlik çoğaltmaları için el ile yük devretme yapılandırabilirsiniz.
- Eşitlenmiş bir ikincil çoğaltmada zorlamalı yük devretme komutu verirseniz, ikincil çoğaltma planlı el ile yük devretme işlemiyle aynı şekilde davranır.
Fayda -ları
Always On kullanılabilirlik grupları, veritabanı kullanılabilirliğini ve kaynak kullanımını geliştiren zengin bir seçenek kümesi sağlar. Temel bileşenler şunlardır:
Dokuz adede kadar yüksek erişilebilirlik yedeğini destekler. Kullanılabilirlik çoğaltması, SQL Server'ın belirli bir örneğinde barındırılan bir kullanılabilirlik grubunun gerçekleştirimi veya örneklenmesidir. Kullanılabilirlik grubuna ait her kullanılabilirlik veritabanının yerel bir kopyasını tutar. Her kullanılabilirlik grubu bir birincil çoğaltmayı ve sekize kadar ikincil çoğaltmayı destekler. Daha fazla bilgi için bkz . Always On kullanılabilirlik grubu nedir?
Önemli
Her kullanılabilirlik çoğaltması tek bir Windows Server Yük Devretme Kümelemesi (WSFC) kümesinin farklı bir düğümünde bulunmalıdır. Kullanılabilirlik grupları için önkoşullar, kısıtlamalar ve öneriler hakkında daha fazla bilgi için bkz. Always On kullanılabilirlik grupları için önkoşullar, kısıtlamalar ve öneriler.
Aşağıdaki gibi alternatif kullanılabilirlik modlarını destekler:
Zaman uyumsuz onaylama modu. Bu kullanılabilirlik modu, kullanılabilirlik çoğaltmaları önemli mesafelere dağıtıldığında iyi çalışan bir olağanüstü durum kurtarma çözümüdür.
Senkron işleme modu. Bu kullanılabilirlik modu, artan işlem gecikme süresi karşılığında performansa göre yüksek kullanılabilirliği ve veri korumayı vurgular. Belirli bir kullanılabilirlik grubu, geçerli birincil çoğaltma dahil olmak üzere en fazla beş eşzamanlı işleme moduna sahip çoğaltmayı destekleyebilir.
Daha fazla bilgi için bkz . AlwaysOn kullanılabilirlik grubu için kullanılabilirlik modları arasındaki farklar.
Kullanılabilirlik grubu yük devretmesinin çeşitli biçimlerini destekler: otomatik yük devretme, planlı el ile yük devretme (genellikle el ile yük devretme olarak adlandırılır) ve zorlamalı el ile yük devretme (genellikle zorlamalı yük devretme olarak adlandırılır). Daha fazla bilgi için bkz. Yük Devretme ve Yük Devretme Modları (Always On Kullanılabilirlik Grupları)
Size, belirtilen bir kullanılabilirlik replikasını aşağıdaki etkin-ikincil özelliklerden birini veya her ikisini destekleyecek şekilde ayarlamanızı sağlar:
İkincil çoğaltma olarak çalışırken, yapılana salt okunur bağlantı erişimi, replikanın veritabanlarına erişim ve bu veritabanlarını okuma olanağı sağlar. Daha fazla bilgi için bkz. Always On kullanılabilirlik grubunun ikincil çoğaltmasına salt okunur iş yükünü boşaltma.
İkincil çoğaltma olarak çalışırken veritabanlarında yedekleme işlemleri gerçekleştirme. Daha fazla bilgi için bkz. Desteklenen yedeklemeleri bir kullanılabilirlik grubunun ikincil çoğaltmalarına boşaltma.
Etkin ikincil özelliklerin kullanılması, BT verimliliğinizi artırır ve ikincil donanımın daha iyi kaynak kullanımıyla maliyeti azaltır. Ayrıca, okuma amacı uygulamalarının ve yedekleme işlerinin ikincil çoğaltmalara boşaltılması, birincil çoğaltmada performansın geliştirilmesine yardımcı olur.
Her kullanılabilirlik grubu için bir kullanılabilirlik grubu dinleyicisini destekler. Kullanılabilirlik grubu dinleyicisi, bir Always On Kullanılabilirlik Grubu'nun birincil veya ikincil replikasındaki bir veritabanına erişmek için istemcilerin bağlanabileceği bir sunucu adıdır. Kullanılabilirlik grubu dinleyicileri, gelen bağlantıları birincil çoğaltıcıya veya salt okunur ikincil çoğaltıcıya yönlendirir. Bir kullanılabilirlik grubu yük devredildiğinde, dinleyici hizmeti hızlı bir şekilde uygulamanın yük devretmesini sağlar. Daha fazla bilgi için bkz. Always On kullanılabilirlik grubu dinleyicisine bağlanma.
Daha fazla denetim sağlamak için esnek bir yük devretme politikasıyla kullanılabilirlik grubunun yük devretmesini destekler. Daha fazla bilgi için bkz. Yük Devretme ve Yük Devretme Modları (Always On Kullanılabilirlik Grupları)
Sayfa bozulmasına karşı koruma için otomatik sayfa onarımı destekler. Daha fazla bilgi için bkz. Otomatik Sayfa Onarımı (Kullanılabilirlik Grupları: Veritabanı Yansıtma).
Güvenli ve yüksek performanslı bir aktarım sağlayan şifreleme ve sıkıştırmayı destekler.
Aşağıdakiler dahil olmak üzere kullanılabilirlik gruplarının dağıtımını ve yönetimini basitleştirmek için tümleşik bir araç kümesi sağlar:
Transact-SQL kullanılabilirlik gruplarını oluşturmak ve yönetmek için DDL deyimleri. Daha fazla bilgi için Her Zaman Açık kullanılabilirlik grupları içinTransact-SQL deyimleri bölümüne bakın.
SQL Server Management Studio araçları, aşağıdaki gibi:
Yeni Kullanılabilirlik Grubu Sihirbazı bir kullanılabilirlik grubu oluşturur ve yapılandırr. Bazı ortamlarda, bu sihirbaz ikincil veritabanlarını otomatik olarak hazırlayabilir ve her biri için veri eşitlemesi başlatabilir. Daha fazla bilgi için bkz. Yeni Kullanılabilirlik Grubu İletişim Kutusunu Kullanma (SQL Server Management Studio).
Kullanılabilirlik Grubuna Veritabanı Ekleme Sihirbazı, var olan bir kullanılabilirlik grubuna bir veya daha fazla birincil veritabanı ekler. Bazı ortamlarda, bu sihirbaz ikincil veritabanlarını otomatik olarak hazırlayabilir ve her biri için veri eşitlemesi başlatabilir. Daha fazla bilgi için bkz. Kullanılabilirlik Grubu Sihirbazı ile Always On kullanılabilirlik grubuna veritabanı ekleme.
Kullanılabilirlik Grubuna Çoğaltma Ekleme Sihirbazı, var olan bir kullanılabilirlik grubuna bir veya daha fazla ikincil çoğaltma ekler. Bazı ortamlarda, bu sihirbaz ikincil veritabanlarını otomatik olarak hazırlayabilir ve her biri için veri eşitlemesi başlatabilir. Daha fazla bilgi için bkz. SQL Server Management Studio'da Kullanılabilirlik Grubu Sihirbazı'nı kullanarak Always On kullanılabilirlik grubunuza çoğaltma ekleme.
Hata Durumunda Yük Devretme Kullanılabilirlik Grubu Sihirbazı, bir kullanılabilirlik grubunda elle bir yük devretme başlatır. Belirttiğiniz yük devretme hedefi olarak ikincil replikasının yapılandırmasına ve durumuna bağlı olarak, sihirbazı planlanmış veya zorunlu manuel yük devretme işlemi yapabilir. Daha fazla bilgi için bkz. SQL Server Management Studio'da Yük Devretme Kullanılabilirlik Grubu Sihirbazı'nı kullanma.
Always On Panosu Always On kullanılabilirlik gruplarını, kullanılabilirlik çoğaltmalarını ve kullanılabilirlik veritabanlarını izler ve Always On ilkeleri için sonuçları değerlendirir. Daha fazla bilgi için Always On Kullanılabilirlik Grubu panosunu kullanma (SQL Server Management Studio) bkz.
Nesne Gezgini Ayrıntıları bölmesi, mevcut kullanılabilirlik gruplarıyla ilgili temel bilgileri görüntüler. Daha fazla bilgi için bkz. Kullanılabilirlik Gruplarını İzlemek için Nesne Gezgini Ayrıntılarını Kullanma.
PowerShell cmdlet'leri. Daha fazla bilgi için bkz. Always On Kullanılabilirlik Grupları için PowerShell Cmdlet'lerine genel bakış.
İstemci bağlantıları
Belirli bir kullanılabilirlik grubunun birincil replikasına istemci bağlantısı sağlamak için bir kullanılabilirlik grubu dinleyicisi oluşturabilirsiniz. Kullanılabilirlik grubu dinleyicisi, istemci bağlantılarını uygun kullanılabilirlik çoğaltmasına yönlendirmek için belirli bir kullanılabilirlik grubuna eklenmiş bir kaynak kümesi sağlar.
Kullanılabilirlik grubu dinleyicisi, sanal ağ adı (VNN), bir veya daha fazla sanal IP adresi (VIP) ve bir TCP bağlantı noktası numarası olarak hizmet eden benzersiz bir DNS adıyla ilişkilendirilir. Daha fazla bilgi için bkz. Always On kullanılabilirlik grubu dinleyicisine bağlanma.
Bir kullanılabilirlik grubunda yalnızca iki kullanılabilirlik çoğaltması varsa ve ikincil çoğaltmaya okuma erişimine izin verecek şekilde yapılandırılmadıysa, istemciler veritabanı yansıtma bağlantı dizesini kullanarak birincil çoğaltmaya bağlanabilir. Bu yaklaşım, veritabanını veritabanı yansıtmasından Always On kullanılabilirlik gruplarına geçirdikten sonra geçici olarak yararlı olabilir. İkincil çoğaltmaları eklemeden önce, kullanılabilirlik grubu için bir kullanılabilirlik grubu dinleyicisi oluşturmanız ve uygulamalarınızı dinleyicinin ağ adını kullanacak şekilde güncelleştirmeniz gerekir.
SQL Server 2025'te TDS 8 desteği
SQL Server 2025 (17.x), Always On kullanılabilirlik grubu çoğaltmalarınıza ve dinleyicinize yönelik bağlantılar için katı TLS 1.3 şifrelemesi zorunlu kılmaya olanak tanıyan TDS 8.0 desteği sağlar.
Yapılandırma gereksinimleri:
-
Yeni kullanılabilirlik grupları:
Encrypt=Strictyan tümcesindeCLUSTER_CONNECTION_OPTIONSile AG'yi oluşturun ve ayarları uygulamak için yük devretme yapın. -
Mevcut kullanılabilirlik grupları: Ayar yapmak için
CLUSTER_CONNECTION_OPTIONSkoşulu ile AG'yiEncrypt=Strictdeğiştirin ve ayarları uygulamak için yük devretme işlemi yapın. - Katı Şifrelemeye Zorla: Her çoğaltma için SQL Server Configuration Manager'da bu seçeneği Evet olarak ayarlayın ve SQL Server çoğaltmalarını yeniden başlatın.
-
Sertifika gereksinimleri:
Encrypt=StrictetkinleştirildiğindeTrustServerCertificateyoksayılır.
Başlamak için Katı şifreleme ile bağlanma'yı gözden geçirin.
Etkin ikincil çoğaltmalar
Always On kullanılabilirlik grupları etkin ikincil çoğaltmaları destekler. Etkin ikincil özellikler şunlar için destek içerir:
İkincil çoğaltmalarda yedekleme işlemleri gerçekleştirme
İkincil çoğaltmalar tam veritabanı, dosya veya dosya grubunun günlük yedeklemelerini ve yalnızca kopya yedeklemelerini gerçekleştirmeyi destekler. Kullanılabilirlik grubunu, yedeklemelerin gerçekleştirileceği yer için bir tercih belirtecek şekilde yapılandırabilirsiniz. SQL Server'ın tercihi zorlamadığını, bu nedenle geçici yedeklemeleri etkilemediğini anlamak önemlidir. Bu tercihin yorumlanması, varsa belirli bir kullanılabilirlik grubundaki veritabanlarının her biri için yedekleme işleri için oluşturduğunuz mantığa bağlıdır. Tek bir kullanılabilirlik çoğaltması için, aynı kullanılabilirlik grubundaki diğer çoğaltmalara göre bu çoğaltmada yedekleme gerçekleştirme önceliğinizi belirtebilirsiniz. Daha fazla bilgi için bkz. Desteklenen yedeklemeleri bir kullanılabilirlik grubunun ikincil çoğaltmalarına boşaltma.
Bir veya daha fazla ikincil çoğaltmaya salt okunur erişim (okunabilir ikincil çoğaltmalar)
Herhangi bir ikincil erişilebilirlik eşleniğini, yerel veritabanlarına yalnızca salt okunur erişime izin verecek şekilde yapılandırabilirsiniz, fakat bazı işlemler tam olarak desteklenmez. Bu yapılandırma, ikincil çoğaltmaya okuma-yazma bağlantı girişimlerini engeller. Yalnızca okuma-yazma erişimine izin vererek birincil çoğaltmada salt okunur iş yüklerini engellemek de mümkündür. Bu yapılandırma, birincil kopyaya salt okunur bağlantıların yapılmasını engeller. Daha fazla bilgi için bkz. Always On kullanılabilirlik grubunun ikincil çoğaltmasına salt okunur iş yükünü boşaltma.
Kullanılabilirlik grubunun şu anda bir kullanılabilirlik grubu dinleyicisi ve bir veya daha fazla okunabilir ikincil çoğaltması varsa, SQL Server okuma amaçlı bağlantı isteklerini bunlardan birine yönlendirebilir (salt okunur yönlendirme). Daha fazla bilgi için bkz. Always On kullanılabilirlik grubu dinleyicisine bağlanma.
Oturum zaman aşımı süresi
Oturum zaman aşımı süresi, bağlantı kapanmadan önce başka bir kullanılabilirlik çoğaltması ile bağlantının ne kadar süreyle etkin kalmayabileceğini belirleyen bir kullanılabilirlik çoğaltması özelliğidir. Birincil ve ikincil çoğaltmalar, hala etkin olduklarının sinyalini vermek için birbirlerine ping gönderir. Zaman aşımı süresi boyunca diğer çoğaltmadan ping almak, bağlantının hala açık olduğunu ve sunucu örneklerinin iletişim kurduğunu gösterir. Ping aldığında, kullanılabilirlik çoğaltması ilgili bağlantıdaki oturum zaman aşımı sayacını sıfırlar.
Oturum zaman aşımı süresi, iki çoğaltmadan birinin diğer çoğaltmadan ping almayı süresiz olarak beklemesini engeller. Oturum zaman aşımı süresi içinde diğer çoğaltma ping göndermezse, çoğaltma zaman aşımına uğrar. Bağlantısı kapanır ve zaman aşımına uğrayan çoğaltma DISCONNECTED durumuna girer. Bağlantısı kesilmiş bir çoğaltma zaman uyumlu işleme modu için yapılandırılmış olsa bile, işlemler bu çoğaltmanın yeniden bağlanmasını ve yeniden eşitlenmesini beklemez.
Her kullanılabilirlik replikası için varsayılan oturum zaman aşımı süresi 10 saniyedir. Bu değeri en az 5 saniyeyle yapılandırabilirsiniz. Genel olarak, zaman aşımı süresini 10 saniye veya daha büyük bir değerde tutun. Değerin 10 saniyeden kısa bir süreye ayarlanması, yoğun yüklü bir sistemin hatalı hata bildirme olasılığına neden olur.
Uyarı
Çözümleme rolünde, ping işlemi gerçekleşmediğinden oturum zaman aşımı süresi uygulanmaz.
Otomatik sayfa onarımı
Her kullanılabilirlik çoğaltması, veri sayfasının okunmasını engelleyen belirli hata türlerini çözerek yerel veritabanındaki bozuk sayfalardan otomatik olarak kurtarmaya çalışır. İkincil çoğaltma bir sayfayı okuyamıyorsa, çoğaltma birincil çoğaltmadan sayfanın yeni bir kopyasını istemektedir. Birincil kopya bir sayfayı okuyamıyorsa, kopya tüm ikincil kopyalara yeni bir kopya isteği yayınlar ve sayfayı yanıt veren ilk ikincil kopyadan alır. Bu istek başarılı olursa, okunamayan sayfa genellikle hatayı gideren kopya ile değiştirilir.
Daha fazla bilgi için bkz. Otomatik Sayfa Onarımı (Kullanılabilirlik Grupları: Veritabanı Yansıtma).
Diğer Veritabanı Altyapısı özellikleriyle birlikte çalışabilirlik ve birlikte var olma
Always On kullanılabilirlik grupları, SQL Server'ın aşağıdaki özellikleri veya bileşenleriyle çalışır:
- Değişiklik veri yakalama (CDC) nedir?
- SQL Server'da Değişiklik İzleme Hakkında
- Kapsayıcı Veritabanları
- Şeffaf veri şifreleme (TDE)
- Always On kullanılabilirlik grupları (SQL Server) ile veritabanı anlık görüntüleri
- FILESTREAM (SQL Server)
- FileTables (SQL Server)
- SQL Server'da günlüğün gönderilmesi hakkında
- Uzak Blob Deposu (RBS) (SQL Server)
- SQL Server Eşleme
- Hizmet Aracısı
- SQL Server Aracısı
- AlwaysOn Kullanılabilirlik Grupları ile Raporlama Hizmetleri (SQL Server)
- Kaynak yöneticisi
- SQL Server 2025 (17.x) ile başlayan TDS 8.0
İlgili görevler
- AlwaysOn kullanılabilirlik grupları için önkoşullar, kısıtlamalar ve öneriler
- Always On kullanılabilirlik gruplarının oluşturulması ve yapılandırılması için başvuru
- Kullanılabilirlik grubunun yönetimi
- Always On kullanılabilirlik gruplarını izleme araçları
- Salt okunur iş yükünü Always On yüksek erişim grubunun ikincil replikasına devretme
- Desteklenen yedeklemelerin yükünü kullanılabilirlik grubunun ikincil çoğaltmalarına boşaltma
- Always On kullanılabilirlik grubu dinleyicisine bağlanma
- Always On kullanılabilirlik grupları içinTransact-SQL ifadeleri
- Always On Kullanılabilirlik Grupları için PowerShell Cmdlet'lerine genel bakış
- SQL Server Blogu - Yüksek Kullanılabilirlik
- SQL Server Blogu
- Arşiv: SQL Server Always On Team Blogları: Resmi SQL Server Always On Team Blogu
- Arşiv: CSS SQL Server Mühendisleri Blogları
- Yüksek Kullanılabilirlik ve Olağanüstü Durum Kurtarma için Microsoft SQL Server Always On Çözümleri Kılavuzu