Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir:![]() SQL Server
SQL Server![]() Azure SQL Veritabanı
Azure SQL Veritabanı![]() Azure SQL Yönetilen Örneği
Azure SQL Yönetilen Örneği![]() Microsoft Fabric'te SQL veritabanı
Microsoft Fabric'te SQL veritabanı
Verimli dizinler tasarlamak, iyi veritabanı ve uygulama performansı elde etmek için önemlidir. Dizin eksikliği, fazla dizin oluşturma veya düşük tasarlanmış dizinler veritabanı performans sorunlarının en önemli kaynaklarıdır.
Bu kılavuzda dizin mimarisi ve temel bilgiler açıklanır ve uygulamalarınızın gereksinimlerini karşılayacak etkili dizinler tasarlamanıza yardımcı olacak en iyi yöntemler sağlanır.
Kullanılabilir dizin türleri hakkında daha fazla bilgi için bkz. Dizinler.
Bu kılavuz aşağıdaki dizin türlerini kapsar:
| Birincil depolama biçimi | Dizin türü |
|---|---|
| Disk tabanlı satır deposu | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Kümelenmiş sütun deposu | |
| Kümelenmemiş sütun deposu | |
| Memory-optimized | |
| Hash | |
| Bellek için iyileştirilmiş kümelenmemiş |
XML dizinleri hakkında bilgi için bkz. XML dizinleri (SQL Server) ve Seçmeli XML dizinleri (SXI).
Uzamsal dizinler hakkında bilgi için bkz . Uzamsal Dizinlere Genel Bakış.
Tam metin dizinleri hakkında bilgi için bkz . Full-Text Dizinlerini Doldurma.
Dizinle ilgili temel bilgiler
Düzenli bir kitabı düşünün: Kitabın sonunda, kitap içinde bilgileri hızla bulmaya yardımcı olan bir dizin vardır. Dizin, anahtar sözcüklerin sıralanmış bir listesidir ve her anahtar sözcüğün yanında, her anahtar sözcüğün bulunabileceği sayfalara işaret eden sayfa numaraları kümesi bulunur.
Satır deposu dizini benzerdir: sıralı bir değer listesidir ve her değer için bu değerlerin bulunduğu veri sayfalarının işaretçileri vardır. Dizinin kendisi de dizin sayfaları olarak adlandırılan sayfalarda depolanır. Normal bir kitapta, dizin birden çok sayfaya yayılmışsa ve örneğin sözcüğü içeren tüm sayfaların işaretçilerini bulmanız gerekiyorsa, anahtar sözcüğünü SQLSQLiçeren dizin sayfasını bulana kadar dizinin başından itibaren sayfayı kaydırmanız gerekir. Buradan, kitap sayfalarına götüren işaretleri takip edersiniz. Bu, dizinin en başında her harfin bulunabileceği alfabetik bir liste içeren tek bir sayfa oluşturursanız daha da iyileştirilebilir. Örneğin: "A - D - sayfa 121", "E - G - sayfa 122" vb. Bu ek sayfa, başlangıç noktasını bulmak için dizine göz atma adımını ortadan kaldırır. Böyle bir sayfa normal kitaplarda bulunmaz, ancak bir rowstore indeksinde vardır. Bu tek sayfa, dizinin kök sayfası olarak adlandırılır. Kök sayfa, dizin tarafından kullanılan ağaç yapısının başlangıç sayfasıdır. Ağaç benzetmesinin ardından, gerçek verilere yönelik işaretçiler içeren bitiş sayfaları, ağacın "yaprak sayfaları" olarak adlandırılır.
Dizin, tablo veya görünümden satırların alınmasını hızlandıran bir tablo veya görünümle ilişkili bir disk veya bellek içi yapıdır. Satır deposu dizini, tablo veya görünümdeki bir veya daha fazla sütundaki değerlerden oluşturulmuş anahtarlar içerir. Rowstore dizinleri için bu anahtarlar, Veritabanı Altyapısı'nın anahtar değerleriyle ilişkili satırları hızlı ve verimli bir şekilde bulmasını sağlayan bir ağaç yapısında (B+ ağaç) depolanır.
Satır deposu dizini, mantıksal olarak düzenlenmiş verileri satır ve sütun içeren bir tablo olarak depolar ve fiziksel olarak satır deposu1 adlı satır başına veri biçiminde depolanır. Sütun deposu adı verilen, sütun açısından veri depolamanın alternatif bir yolu vardır.
Veritabanı ve iş yükü için doğru dizinlerin tasarımı, sorgu hızı, dizin güncelleştirme maliyeti ve depolama maliyeti arasında karmaşık bir dengeleme eylemidir. Dar disk tabanlı satır deposu dizinleri veya dizin anahtarında birkaç sütun bulunan dizinler, daha az depolama alanı ve daha küçük bir güncelleştirme yükü gerektirir. Öte yandan geniş dizinler daha fazla sorguyu geliştirebilir. En verimli dizin kümesini bulmadan önce birkaç farklı tasarımla denemeniz gerekebilir. Uygulama geliştikçe, en iyi performansı korumak için dizinlerin değişmesi gerekebilir. Dizinler, veritabanı şemasını veya uygulama tasarımını etkilemeden eklenebilir, değiştirilebilir ve kaldırılabilir. Bu nedenle, farklı dizinlerle deneme yapmaktan çekinmeyin.
Veritabanı Altyapısı'ndaki sorgu iyileştiricisi genellikle sorguyu yürütmek için en etkili dizinleri seçer. Sorgu iyileştiricinin belirli bir sorgu için hangi dizinleri kullandığını görmek için, SQL Server Management Studio'da Sorgu menüsünde Tahmini Yürütme Planını Görüntüle veya Gerçek Yürütme Planı Ekle'yi seçin.
Dizin kullanımını her zaman iyi performansla, ve iyi performansı verimli dizin kullanımıyla eşitlemeyin. Dizin kullanmak her zaman en iyi performansın üretilmesine yardımcı olsaydı, sorgu iyileştiricisinin işi basit olurdu. Gerçekte, yanlış bir dizin seçimi en iyi performanstan daha az performansa neden olabilir. Bu nedenle, sorgu optimize edicisinin görevi, performansı artıracağı durumlarda yalnızca bir dizin veya dizin birleşimi seçmek ve performansı engellediği zaman dizine alınmış olanlardan kaçınmaktır.
Yaygın bir tasarım hatası, "iyileştirici seçeneklerini vermek" için kurgusal olarak birçok dizin oluşturmaktır. Sonuçta elde edilen fazla dizinleme, veri değişikliklerini yavaşlatır ve eşzamanlılık sorunlarına neden olabilir.
1 Rowstore, ilişkisel tablo verilerini depolamanın geleneksel yoludur. Rowstore , temel alınan veri depolama biçiminin bir yığın, B+ ağacı (kümelenmiş dizin) veya bellek için iyileştirilmiş bir tablo olduğu bir tabloya başvurur. Disk tabanlı satır deposu bellek için iyileştirilmiş tabloları dışlar.
Dizin tasarım görevleri
Aşağıdaki görevler dizinleri tasarlamak için önerilen stratejimizi oluşturur:
Veritabanının ve uygulamanın özelliklerini anlama.
Örneğin, yüksek aktarım hızını sürdürmesi gereken sık veri değişikliklerine sahip bir çevrimiçi işlem işleme (OLTP) veritabanında, en kritik sorgular için hedeflenen birkaç dar rowstore dizini iyi bir ilk dizin tasarımı olabilir. Son derece yüksek aktarım hızı için, kilit ve mandalsız tasarım sağlayan bellek için iyileştirilmiş tabloları ve dizinleri göz önünde bulundurun. Daha fazla bilgi için bu kılavuzdaki Bellek için iyileştirilmiş, kümelenmemiş dizin tasarım yönergeleri ve Karma dizin tasarım yönergeleri konularına bakın.
Buna karşılık, çok büyük veri kümelerini hızlı bir şekilde işlemesi gereken bir analiz veya veri ambarı (OLAP) veritabanı için kümelenmiş columnstore dizinlerinin kullanılması özellikle uygun olacaktır. Daha fazla bilgi için bkz. Bu kılavuzda Columnstore dizinleri: genel bakış veya Columnstore dizin mimarisi .
En sık kullanılan sorguların özelliklerini anlama.
Örneğin, sık kullanılan bir sorgunun iki veya daha fazla tabloyu birleştirdiğini bilmek, bu tablolar için dizin kümesini belirlemenize yardımcı olur.
Sorgu koşullarında kullanılan sütunlardaki veri dağıtımını anlayın.
Örneğin, bir dizin birçok farklı veri değerine sahip sütunlar için yararlı olabilir, ancak çok sayıda yinelenen değere sahip sütunlar için bu değer daha az olabilir. Çok sayıda NUL içeren sütunlar veya iyi tanımlanmış veri alt kümeleri olan sütunlar için filtrelenmiş dizin kullanabilirsiniz. Daha fazla bilgi için bu kılavuzdaki Filtrelenmiş dizin tasarımı yönergelerine bakın.
Performansı geliştirebilecek dizin seçeneklerini belirleyin.
Örneğin, mevcut büyük bir tabloda kümelenmiş dizin oluşturma işlemi,
ONLINEdizin seçeneğinden yararlanabilir. seçeneğiONLINE, dizin oluşturulurken veya yeniden oluşturulurken temel alınan verilerde eşzamanlı etkinliğin devam etmesini sağlar. Satır veya sayfa veri sıkıştırması kullanmak, dizinin G/Ç ve bellek ayak izini azaltarak performansı artırabilir. Daha fazla bilgi için bkz. CREATE INDEX.Yinelenen veya çok benzer dizinler oluşturulmasını önlemek için tablodaki mevcut dizinleri inceleyin.
Mevcut bir dizini değiştirmek, yeni ama çoğunlukla yinelenen bir dizin oluşturmaktan daha iyidir. Örneğin, bu sütunlarla yeni bir dizin oluşturmak yerine mevcut bir dizine bir veya iki ek sütun eklemeyi göz önünde bulundurun. Bu, özellikle dizin önerileri eksik olan kümelenmemiş dizinleri ayarladığınızda veya aynı tablo ve sütunlarda benzer dizin çeşitlemeleri sunabileceğiniz Veritabanı Altyapısı Ayarlama Danışmanı'nı kullandığınızda geçerlidir.
Genel dizin tasarımı yönergeleri
Veritabanınızın, sorgularınızın ve tablo sütunlarınızın özelliklerini anlamak, başlangıçta en uygun dizinleri tasarlamanıza ve uygulamalarınız geliştikçe tasarımı değiştirmenize yardımcı olabilir.
Veritabanında dikkat edilmesi gerekenler
Bir dizin tasarlarken aşağıdaki veritabanı yönergelerini göz önünde bulundurun:
Bir tablodaki çok sayıda dizin ,
INSERTUPDATE, veDELETEdeyimlerininMERGEperformansını etkiler çünkü dizinlerdeki verilerin tablodaki veriler değiştikçe değişmesi gerekebilir. Örneğin, bir sütun birkaç dizinde kullanılırsa ve bu sütunun verilerini değiştiren birUPDATEdeyim yürütürseniz, bu sütunu içeren her dizin de güncelleştirilmelidir.Aşırı güncelleştirilmiş tabloları dizinlemekten kaçının ve dizinleri olabildiğince az sütunla dar tutun.
Çok az veri değişikliği olan ancak büyük miktarda veri içeren tablolarda daha fazla dizininiz olabilir. Bu tür tablolar için çeşitli dizinler, dizin güncelleştirme ek yükü kabul edilebilir olmaya devam ederken sorgu performansına yardımcı olabilir. Ancak, tahmine dayalı olarak dizin oluşturmayın. Dizin kullanımını izleyin ve zaman içinde kullanılmayan dizinleri kaldırın.
Veritabanı Altyapısı'nın veri aramak için dizini taraması, temel tabloyu taramak yerine daha uzun sürebileceği için küçük tabloları dizine almak en uygun çözüm olmayabilir. Bu nedenle, küçük tablolardaki dizinler hiçbir zaman kullanılmayabilir, ancak tablodaki veriler güncelleştirildikçe yine de güncelleştirilmelidir.
Görünümlerdeki dizinler, görünüm toplamalar ve/veya birleştirmeler içerdiğinde önemli performans kazançları sağlayabilir. Daha fazla bilgi için bkz. Dizinli görünümler oluşturma.
Azure SQL Veritabanı'ndaki birincil çoğaltmalardaki veritabanları, dizinler için otomatik olarak veritabanı danışmanı performans önerileri oluşturur. İsteğe bağlı olarak otomatik dizin ayarlamayı etkinleştirebilirsiniz.
Sorgu Deposu, altoptimal performansa sahip sorguların tanımlanmasına yardımcı olur ve en iyi duruma getirici tarafından seçilen dizinleri görmenize olanak sağlayan sorgu yürütme planlarının geçmişini sağlar. En sık kullanılan ve kaynak tüketen sorgulara odaklanarak dizin ayarlama değişikliklerinizi en etkili hale getirmek için bu verileri kullanabilirsiniz.
Sorguyla ilgili dikkat edilmesi gerekenler
Bir dizin tasarlarken aşağıdaki sorgu yönergelerini göz önünde bulundurun:
Sorgulardaki koşul ve birleştirme ifadelerinde sık kullanılan sütunlarda kümelenmemiş dizinler oluşturun. Bunlar SARGable sütunlarınızdır . Ancak, dizinlere gereksiz sütun eklemekten kaçınmanız gerekir. Çok fazla dizin sütunu eklemek disk alanını ve dizin güncelleştirme performansını olumsuz etkileyebilir.
İlişkisel veritabanlarında SARGable terimi, sorgunun yürütülmesini hızlandırmak için bir dizin kullanabilen Search ARGumentable bir yüklemi ifade eder. Daha fazla bilgi için bkz. SQL Server ve Azure SQL dizin mimarisi ve tasarım kılavuzu.
Tip
Oluşturduğunuz dizinlerin sorgu iş yükü tarafından gerçekten kullanıldığından her zaman emin olun. Kullanılmayan dizinleri bırakın.
Dizin kullanım istatistikleri sys.dm_db_index_usage_stats ve sys.dm_db_index_operational_stats kullanılabilir.
Sorgunun gereksinimlerini karşılamak için gereken tüm veriler dizinin içinde bulunduğundan, dizinleri kapsamak sorgu performansını geliştirebilir. Başka bir ifadeyle, istenen verileri almak için tablonun veya kümelenmiş dizinin veri sayfalarına değil, yalnızca dizin sayfalarına ihtiyaç vardır; bu da genel disk G/Ç'yi azaltır. Örneğin,
A,BveAsütunlarında oluşturulmuş bileşik bir dizine sahip olan bir tabloda,BveCsütunlarını içeren bir sorgu, belirtilen verileri yalnızca dizinden alabilir.Note
Kapsayan dizin, temel tabloya erişmeden doğrudan bir sorgu tarafından tüm veri erişimini karşılayan, kümelenmemiş bir dizindir.
Bu tür dizinler, dizin anahtarında gerekli tüm SARGable sütunlarına ve dahil edilen sütunlar olarak SARGable olmayan sütunlara sahiptir . Bu, sorgu için gereken tüm sütunların, ya
WHERE,JOINveGROUP BYyan tümcelerinde ya daSELECTveyaUPDATEyan tümcelerinde dizinde bulunduğu anlamına gelir.Sorguyu yürütmek için büyük olasılıkla çok daha az G/Ç vardır. Dizinin tablodaki satır ve sütunlara kıyasla yeterince dar olması, tüm sütunların küçük bir alt kümesi olduğu anlamına gelir.
Büyük bir tablonun küçük bir bölümünü alırken ve bu küçük bölümün sabit bir koşulla tanımlandığı durumlarda dizinleri kapsamayı göz önünde bulundurun.
Çok fazla sütun içeren bir kapsayan dizin oluşturmaktan kaçının çünkü bu, veritabanı depolama, G/Ç ve bellek ayak izini şişirirken avantajını azaltır.
Aynı satırları güncelleştirmek için birden çok sorgu kullanmak yerine, tek bir deyimde mümkün olduğunca çok satır ekleyen veya değiştiren sorgular yazın. Bu, dizin güncelleştirme ek yükünü azaltır.
Sütunla ilgili dikkat edilmesi gerekenler
Bir dizin tasarlarken aşağıdaki sütun yönergelerini göz önünde bulundurun:
Özellikle kümelenmiş dizinler için dizin anahtarının uzunluğunu kısa tutun.
ntext, text, image, varchar(max), nvarchar(max), varbinary(max), json ve vector veri türlerinden oluşan sütunlar dizin anahtarı sütunları olarak belirtilmez. Ancak, bu veri türlerine sahip sütunlar, kümelenmemiş bir dizine anahtar olmayan (dahil) dizin sütunları olarak eklenebilir. Daha fazla bilgi için bu kılavuzdaki Kümelenmemiş dizinlerde dahil edilen sütunları kullanma bölümüne bakın.
Sütun benzersizliğini inceleyin. Aynı anahtar sütunlarında, benzersiz olmayan bir dizin yerine benzersiz bir dizin, sorgu iyileştirici için dizini daha faydalı hale getiren ek bilgiler sunar. Daha fazla bilgi için bu kılavuzdaki Benzersiz dizin tasarımı yönergelerine bakın.
Sütundaki veri dağıtımını inceleyin. Çok sayıda satırı olan ancak birkaç ayrı değeri olan bir sütunda dizin oluşturmak, dizin sorgu iyileştiricisi tarafından kullanılsa bile sorgu performansını iyileştirmeyebilir. Benzetme olarak, aile adına göre alfabetik olarak sıralanmış bir fiziksel telefon dizini, şehirdeki tüm kişilerin adı Smith veya Jones ise bir kişiyi bulma işlemini hızlandırmaz. Veri dağıtımı hakkında daha fazla bilgi için bkz. İstatistikler.
İyi tanımlanmış alt kümelere sahip sütunlarda filtrelenmiş dizinler kullanmayı göz önünde bulundurun; örneğin, çok sayıda NUL içeren sütunlar, değer kategorilerine sahip sütunlar ve farklı değer aralıklarına sahip sütunlar. İyi tasarlanmış bir filtrelenmiş dizin sorgu performansını artırabilir, dizin güncelleştirme maliyetlerini azaltabilir ve bu alt küme birçok sorgu için uygunsa tablodaki tüm satırların küçük bir alt kümesini depolayarak depolama maliyetlerini azaltabilir.
Anahtar birden çok sütun içeriyorsa dizin anahtarı sütunlarının sırasını göz önünde bulundurun. Sorgu koşulunda, bir eşitlik (
=), eşitsizlik (>,>=,<,<=) veyaBETWEENifadesinde ya da birleştirmeye katılan sütunun ilk sırada yer alması gerekir. Ek sütunlar, en farklı olandan en az ayrılığa kadar olan benzersizlik düzeylerine göre sıralanmalıdır.Örneğin, dizin olarak
LastNameFirstNametanımlanırsa, yan tümcesindeki sorgu koşuluWHEREveyaWHERE LastName = 'Smith'olduğunda dizin yararlı olurWHERE LastName = Smith AND FirstName LIKE 'J%'. Ancak, sorgu iyileştiricisi yalnızca üzerindeWHERE FirstName = 'Jane'arama yapılan bir sorgu için dizini kullanmaz veya dizin böyle bir sorgunun performansını iyileştirmez.Sorgu koşullarında yer alıyorsa hesaplanan sütunları dizinlemeyi göz önünde bulundurun. Daha fazla bilgi için bkz. Hesaplanan sütunlardaki dizinler.
Dizin özellikleri
Bir dizinin sorgu için uygun olduğunu belirledikten sonra, durumunuz için en uygun dizin türünü seçebilirsiniz. Dizin özellikleri şunlardır:
- Kümelenmiş veya kümelenmemiş
- Benzersiz veya benzersiz olmayan
- Tek sütun veya çok sütunlu
- Dizindeki anahtar sütunlar için artan veya azalan düzen
- Kümelenmemiş dizinler için, tüm satırlar veya filtrelenmiş satırlar.
- Columnstore veya rowstore
- Bellek için iyileştirilmiş tablolar amacıyla karma veya kümelenmemiş dizin
Dosya gruplarında veya bölüm düzenlerinde dizin yerleşimi
Dizin tasarım stratejinizi geliştirirken, dizinlerin veritabanıyla ilişkili dosya gruplarına yerleştirilmesini göz önünde bulundurmanız gerekir.
Varsayılan olarak, dizinler dizinin oluşturulduğu temel tabloyla (kümelenmiş dizin veya yığın) aynı dosya grubunda depolanır. Aşağıdakiler de dahil olmak üzere diğer yapılandırmalar mümkündür:
Temel tablonun dosya grubu dışında bir dosya grubunda kümelenmemiş dizinler oluşturun.
Kümelenmiş ve kümelenmemiş dizinleri birden çok dosya grubuna yaymak için bölümleyin.
Bölümlenmemiş tablolar için en basit yaklaşım genellikle en iyisidir: tüm tabloları aynı dosya grubunda oluşturun ve kullanılabilir tüm fiziksel depolamayı kullanmak için dosya grubuna gerektiği kadar veri dosyası ekleyin.
Katmanlı depolama kullanılabilir olduğunda daha gelişmiş dizin yerleştirme yaklaşımları göz önünde bulundurulabilir. Örneğin, daha hızlı disklerdeki dosyaları içeren sık erişilen tablolar için bir dosya grubu ve daha yavaş disklerdeki arşiv tabloları için bir dosya grubu oluşturabilirsiniz.
Kümelenmiş dizin içeren bir tabloyu, kümelenmiş dizini bırakarak ve MOVE TO deyiminin yan tümcesinde yeni bir dosya grubu veya bölüm düzeni belirterek başka bir dosya grubuna taşıyabilir ya da DROP INDEX deyimini CREATE INDEX yan tümcesiyle kullanarak bu işlemi gerçekleştirebilirsiniz.
Bölümlenmiş dizinler
Ayrıca disk tabanlı yığınları, kümelenmiş ve kümelenmemiş dizinleri birden çok dosya grubu arasında bölümleyebilirsiniz. Bölümlenmiş dizinler, bölümleme işlevine göre yatay olarak (satıra göre) bölümlenir. partition işlevi, her satırın bölümleme sütunu olarak adlandırılan, belirlediğiniz belirli bir sütunun değerlerine göre bir bölümle nasıl eşlendiği tanımlar. Bölüm düzeni, bir bölüm kümesinin dosya grubuna eşlemini belirtir.
Bir dizinin bölümlenmesi aşağıdaki avantajları sağlayabilir:
Büyük veritabanlarını daha yönetilebilir hale getirin. Örneğin OLAP sistemleri, toplu olarak veri eklemeyi ve kaldırmayı büyük ölçüde kolaylaştıran bölüme duyarlı ETL uygulayabilir.
Uzun süre çalışan analitik sorgular gibi belirli sorgu türlerinin daha hızlı çalışmasını sağlayın. Sorgular bölümlenmiş dizin kullandığında, Veritabanı Altyapısı aynı anda birden çok bölümü işleyebilir ve sorgu tarafından gerekli olmayan bölümleri atlayabilir (ortadan kaldırabilir).
Uyarı
Bölümleme, OLTP sistemlerinde sorgu performansını nadiren iyileştirir, ancak işlem sorgusu birçok bölüme erişmesi gerekiyorsa önemli bir ek yük oluşturabilir.
Daha fazla bilgi için bkz . Bölümlenmiş tablolar ve dizinler.
Dizin sıralama düzeni tasarım yönergeleri
Dizinleri tanımlarken, her dizin anahtarı sütunlarının artan veya azalan sırada depolanması gerekip gerekmediğini göz önünde bulundurun. Artan sıralama varsayılandır.
CREATE INDEX, CREATE TABLE ve ALTER TABLE ifadelerinin söz dizimi, dizinlerdeki ve kısıtlamalardaki tek tek sütunlarda ASC (artan) ve DESC (azalan) anahtar sözcüklerini destekler.
Tabloya ORDER BY başvuran sorgularda, söz konusu dizindeki anahtar sütunu veya sütunları için farklı yönler belirten yan tümceleri olduğunda, anahtar değerlerinin dizinde depolandığı sıranın belirtilmesi yararlı olur. Bu gibi durumlarda, dizin sorgu planında Sıralamaişleci gereksinimini kaldırabilir.
Örneğin Adventure Works Cycles satın alma departmanındaki alıcıların satıcılardan satın aldıkları ürünlerin kalitesini değerlendirmesi gerekir. Alıcılar en çok yüksek ret oranına sahip satıcılar tarafından gönderilen ürünleri bulmakla ilgileniyor.
AdventureWorks örnek veritabanına yönelik aşağıdaki sorguda gösterildiği gibi, bu ölçütleri karşılayacak verilerin alınması için tablodaki sütunun RejectedQtyPurchasing.PurchaseOrderDetail azalan düzende (büyükten küçüke) sıralanması ve sütunun ProductID artan düzende (küçükten büyüğe) sıralanması gerekir.
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
Bu sorgu için aşağıdaki yürütme planı, sorgu iyileştiricisinin sonuç kümesini yan tümcesi tarafından belirtilen sırayla döndürmek için ORDER BY işleci kullandığını gösterir.

Sorgudaki yan tümcesindekilerle ORDER BY eşleşen anahtar sütunlarla disk tabanlı bir satır deposu dizini oluşturulursa, sorgu planındaki Sort işleci ortadan kaldırılarak sorgu planı daha verimli hale getirilir.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
Sorgu yeniden yürütüldükten sonra, aşağıdaki yürütme planı Sort işlecinin artık mevcut olmadığını ve yeni oluşturulan kümelenmemiş dizinin kullanıldığını gösterir.
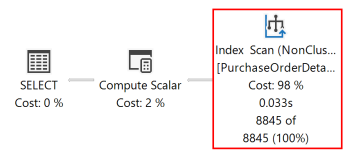
Veritabanı Altyapısı bir dizini her iki yönde de tarayabilir.
RejectedQty DESC, ProductID ASC olarak tanımlanan bir dizin, cümledeki sütunların ORDER BY sıralama yönlerinin tersine çevrildiği bir sorgu için kullanılabilir. Örneğin, yan tümcesine ORDER BYORDER BY RejectedQty ASC, ProductID DESC sahip bir sorgu aynı dizini kullanabilir.
Sıralama düzeni yalnızca dizindeki anahtar sütunlar için belirtilebilir. sys.index_columns katalog görünümü, dizin sütununun artan veya azalan sırada depolanıp depolanmadığını bildirir.
Kümelenmiş dizin tasarım yönergeleri
Kümelenmiş dizin, tablonun tüm satırlarını ve tüm sütunlarını depolar. Satırlar dizin anahtarı değerleri sırasına göre sıralanır. Tablo başına yalnızca bir kümelenmiş dizin olabilir.
Temel tablo terimi, hem kümelenmiş dizin hem de yığın anlamına gelebilir. Yığın, diskte tablonun tüm satırlarını ve tüm sütunlarını içeren sıralanmamış bir veri yapısıdır.
Birkaç özel durumla, her tablonun kümelenmiş dizini olmalıdır. Kümelenmiş dizinin istenen özellikleri şunlardır:
| Mülkiyet | Description |
|---|---|
| Dar | Kümelenmiş dizin anahtarı, aynı temel tablodaki kümelenmemiş dizinlerin bir parçasıdır. Dar bir anahtar veya anahtar sütunlarının toplam uzunluğunun küçük olduğu bir anahtar, tablodaki tüm dizinlerin depolama, G/Ç ve bellek yükünü azaltır. Anahtar uzunluğunu hesaplamak için anahtar sütunları tarafından kullanılan veri türlerinin depolama boyutlarını ekleyin. Daha fazla bilgi için bkz. Veri türü kategorileri. |
| Eşsiz | Kümelenmiş dizin benzersiz değilse, benzersizliği sağlamak için dizin anahtarına otomatik olarak 4 baytlık bir iç benzersizleştirici sütunu eklenir. Kümelenmiş dizin anahtarına mevcut bir benzersiz sütun eklemek, tablodaki tüm dizinlerde benzersizleştirici sütununun depolama, G/Ç ve bellek ek yükünü önler. Ayrıca, bir dizin benzersiz olduğunda sorgu iyileştiricisi daha verimli sorgu planları oluşturabilir. |
| Sürekli artan | Sürekli artan bir dizinde veriler her zaman dizinin son sayfasına eklenir. Bu, indeksin ortasında sayfa bölünmelerini önleyerek sayfa yoğunluğunu korur ve performansı artırır. |
| Değişmez | Kümelenmiş dizin anahtarı, kümelenmemiş dizinlerin bir parçasıdır. Kümelenmiş dizinin anahtar sütunu değiştirildiğinde, tüm kümelenmemiş dizinlerde de bir değişiklik yapılmalı; bu da CPU, Günlükleme, G/Ç ve bellek üzerinde ek yük oluşturur. Kümelenmiş dizinin anahtar sütunları sabitse ek yükten kaçınılır. |
| Yalnızca boş değer atanamayan sütunlara sahip | Bir satırda null atanabilir sütunlar varsa, bir dizinde satır başına 3-4 bayt depolama alanı ekleyen NULL bloğu adlı bir iç yapı içermelidir. Kümelenmiş dizinin tüm sütunlarının null değer alamaz olarak ayarlanması bu ek yükü önler. |
| Yalnızca sabit genişlikli sütunlara sahiptir | Varchar veya nvarchar gibi değişken genişlikli veri türlerini kullanan sütunlar, sabit genişlikli veri türlerine kıyasla değer başına ek 2 bayt kullanır. int gibi sabit genişlikli veri türlerinin kullanılması, tablodaki tüm dizinlerde bu ek yükü önler. |
Kümelenmiş dizin tasarlarken bu özelliklerin mümkün olduğunca çoğunu karşılamak yalnızca kümelenmiş dizini değil, aynı tablodaki tüm kümelenmemiş dizinleri de daha verimli hale getirir. Depolama, G/Ç ve bellek ek yüklerinden kaçınılarak performans iyileştirilir.
Örneğin, tek bir int veya bigint boş olamayan sütundan oluşan kümelenmiş dizin anahtarı, bir IDENTITY yan tümce veya varsayılan kısıtlama kullanılarak bir sıra ile doldurulduğunda ve bir satır eklendikten sonra güncellenmediğinde bu özelliklerin tümüne sahiptir.
Buna karşılık, tek bir benzersiz belirleyici sütunu olan kümelenmiş dizin anahtarı, int için 4 bayt yerine 16 bayt, bigint için 8 bayt depolama alanı kullandığından daha geniştir ve değerler sırayla oluşturulmadığı sürece sürekli artan özelliği karşılamaz.
Tip
Kısıtlama PRIMARY KEY oluşturduğunuzda, kısıtlamayı destekleyen benzersiz bir dizin otomatik olarak oluşturulur. Varsayılan olarak, bu dizin kümelenmiştir; ancak, bu dizin kümelenmiş dizinin istenen özelliklerini karşılamıyorsa kısıtlamayı kümelenmemiş olarak oluşturabilir ve bunun yerine farklı bir kümelenmiş dizin oluşturabilirsiniz.
Kümelenmiş dizin oluşturmazsanız, tablo yığın olarak depolanır ve bu genellikle önerilmez.
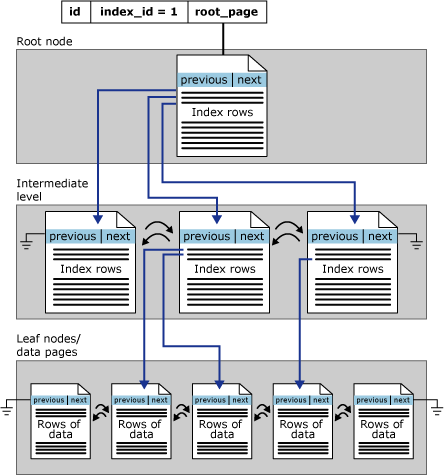
Kümelenmiş dizin mimarisi
Rowstore dizinleri B+ ağaçları olarak düzenlenir. Dizin B+ ağacındaki her sayfaya dizin düğümü adı verilir. B+ ağacının en üst düğümüne kök düğüm adı verilir. Dizindeki alt düğümler yaprak düğümler olarak adlandırılır. Kök ve yaprak düğümler arasındaki dizin düzeyleri topluca ara düzeyler olarak bilinir. Kümelenmiş dizinde yaprak düğümler, temel tablonun veri sayfalarını barındırır. Kök ve ara düzey düğümleri, dizin satırlarını tutan dizin sayfaları içerir. Her dizin satırı, bir anahtar değeri ve B+ ağacındaki bir ara düzey sayfasına veya dizinin yaprak düzeyindeki bir veri satırına yönelik bir işaretçi içerir. Dizinin her düzeyindeki sayfalar, ikiye kat bağlantılı bir listede bağlantılıdır.
Kümelenmiş dizinlerin, dizin tarafından kullanılan her bölüm için sys.partitions tablosunda bir satırı vardır. Varsayılan olarak, kümelenmiş bir dizin tek bir bölüme sahiptir. Kümelenmiş dizinde birden çok bölüm olduğunda, her bölümün ilgili bölüme ilişkin verileri içeren ayrı bir B+ ağaç yapısı vardır. Örneğin, kümelenmiş bir dizinin dört bölümü varsa, her bölümde bir tane olmak üzere dört B+ ağaç yapısı vardır.
Kümelenmiş dizindeki veri türlerine bağlı olarak, her kümelenmiş dizin yapısında belirli bir bölüme ait verilerin depolandığı ve yönetileceği bir veya daha fazla ayırma birimi vardır. En azından her kümelenmiş dizinin bölüm başına bir IN_ROW_DATA ayırma birimi vardır. Kümelenmiş dizin, LOB_DATA gibi büyük nesne (LOB) sütunları içeriyorsa bölüm başına bir ayırma birimine de sahiptir. Ayrıca, 8.060 bayt satır boyutu sınırını aşan değişken uzunlukta sütunlar içeriyorsa bölüm başına bir ROW_OVERFLOW_DATA ayırma birimi vardır.
B+ ağaç yapısındaki sayfalar, kümelenmiş dizin anahtarının değerine göre sıralanır. Tüm eklemeler, eklenen satırdaki anahtar değerinin var olan sayfalar arasında sıralama sırasına sığdığı sayfada yapılır. Bir sayfada satırların fiziksel bir sırada depolanması şart değildir. Ancak, sayfa yuva dizisi olarak adlandırılan iç yapıyı kullanarak satırların mantıksal sıralamasını korur. Yuva dizisindeki girdiler dizin anahtarı sırasına göre tutulur.
Bu çizimde tek bir bölümlemedeki kümelenmiş dizinin yapısı gösterilmektedir.
Kümelenmemiş dizin tasarım yönergeleri
Kümelenmiş ve kümelenmemiş dizin arasındaki temel fark, kümelenmemiş bir dizinin tablodaki sütunların bir alt kümesini içermesi ve genellikle kümelenmiş dizinden farklı sıralanmış olmasıdır. İsteğe bağlı olarak, kümelenmemiş dizin filtrelenebilir; bu da tablodaki tüm satırların bir alt kümesini içerdiği anlamına gelir.
Disk tabanlı satır deposu kümelenmemiş bir dizin, temel tablodaki satırın depolama konumuna işaret eden satır işaretçilerini içerir. Bir tabloda veya dizinli görünümde birden çok kümelenmemiş dizin oluşturabilirsiniz. Genellikle, kümelenmemiş dizinler, aksi takdirde temel tabloyu taraması gereken sık kullanılan sorguların performansını artırmak için tasarlanmalıdır.
Bir kitaptaki dizin kullanımınıza benzer şekilde, sorgu iyileştiricisi de tablodaki veri değerinin konumunu bulmak için kümelenmemiş dizinde arama yaparak veri değerini arar ve ardından verileri doğrudan bu konumdan alır. Bu, dizin sorgularda aranmakta olan veri değerlerinin tablosundaki tam konumu açıklayan girdiler içerdiğinden, kümelenmemiş dizinleri tam eşleşme sorguları için en uygun seçenek haline getirir.
Örneğin, sorgu iyileştiricisi, belirli bir yöneticiye rapor veren tüm çalışanları tabloda sorgulamak için, ilk anahtar sütunu HumanResources.Employee olan kümelenmemiş dizini IX_Employee_ManagerID kullanabilir.
ManagerID Değerler kümelenmemiş dizinde sıralandığından, sorgu iyileştirici dizinde belirtilen ManagerID değerle eşleşen tüm girişleri hızla bulabilir. Her dizin girişi, diğer tüm sütunlardan karşılık gelen verilerin alınabildiği temel tablodaki tam sayfayı ve satırı gösterir. Sorgu iyileştirici dizindeki tüm girişleri bulduklarından sonra, temel tablonun tamamını taramak yerine verileri almak için doğrudan tam sayfaya ve satıra gidebilir.
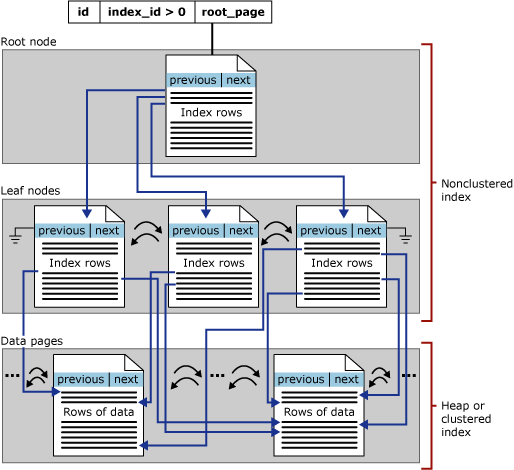
Kümelenmemiş dizin mimarisi
Disk tabanlı satır deposu kümelenmemiş dizinler, aşağıdaki farklılıklar dışında kümelenmiş dizinler ile aynı B+ ağaç yapısına sahiptir:
Kümelenmemiş dizin, tablonun tüm sütunlarını ve satırlarını içermesi gerekmez.
Kümelenmemiş dizinin yaprak düzeyi, veri sayfaları yerine dizin sayfalarından oluşur. Kümelenmemiş dizinin yaprak düzeyindeki dizin sayfaları anahtar sütunlar içerir. İsteğe bağlı olarak, bunları temel tablodan almaktan kaçınmak için tablodaki diğer sütunların bir alt kümesini de dahil edilen sütunlar olarak içerebilirler.
Kümelenmemiş dizin satırlarındaki satır bulucuları bir satırın işaretçisidir veya bir satırın kümelenmiş dizin anahtarıdır ve aşağıdaki gibi açıklanmıştır:
Tabloda kümelenmiş dizin varsa veya dizin dizinli bir görünümdeyse, satır bulucu satırın kümelenmiş dizin anahtarıdır.
Tablo bir yığın ise, yani kümelenmiş dizini yoksa, satır konumlayıcı satıra işaret eden bir işaretçidir. İşaretçi, dosya tanımlayıcısından (KIMLIK), sayfa numarasından ve sayfadaki satırın sayısından oluşturulur. İşaretçinin bütünü Satır Kimliği (RID) olarak bilinir.
Satır bulucuları, kümelenmemiş dizin satırları için benzersizlik de sağlar. Aşağıdaki tabloda Veritabanı Altyapısı'nın kümelenmemiş dizinlere nasıl satır bulucuları eklediği açıklanmaktadır:
| Temel tablo türü | Kümelenmemiş dizin türü | Satır bulucu |
|---|---|---|
| Heap | ||
| Nonunique | Anahtar sütunlara RID eklendi | |
| Unique | Eklenen sütunlara RID eklendi | |
| Benzersiz kümelenmiş dizin | ||
| Nonunique | Anahtar sütunlarına eklenen kümelenmiş dizin anahtarları | |
| Unique | Dahil edilen sütunlara eklenen kümelenmiş dizin anahtarları | |
| Benzersiz olmayan kümelenmiş dizin | ||
| Nonunique | Kümelenmiş dizin anahtarları ve benzersizleştirici (mevcutsa) anahtar sütunlarına eklenir. | |
| Unique | Dahil edilen sütunlara, mevcut olduklarında, kümelenmiş dizin anahtarları ve benzersizleştiriciler eklendi. |
Veritabanı Altyapısı hiçbir zaman belirli bir sütunu bir kereden fazla kümelenmemiş dizinde depolamaz. Kullanıcı, bir kümelenmemiş dizin oluştururken belirttiği dizin anahtarı sırası her zaman kabul edilir: kümelenmemiş dizinin anahtarına eklenmesi gereken tüm satır bulucu sütunları, dizin tanımında belirtilen sütunların ardından anahtarın sonuna eklenir. Kümelenmiş dizin anahtarı satır bulucuları, dizin tanımında açıkça belirtilmesine veya örtük olarak eklenmesine bakılmaksızın sorgu işlemede kullanılabilir.
Aşağıdaki örneklerde, satır bulucularının kümelenmemiş dizinlerde nasıl uygulandığı gösterilmektedir:
| Kümelenmiş indeks | Kümelenmemiş dizin tanımı | Satır bulucuları olan kümelenmemiş dizin tanımı | Explanation |
|---|---|---|---|
Anahtar sütunları (A, B, C) ile benzersiz kümelenmiş dizin |
Anahtar sütunları (B, A) ve dahil edilen sütunlar (E, G) ile tekil olmayan kümelenmemiş dizin |
Anahtar sütunları (B, A, C) ve dahil edilen sütunlar (E, G) |
Kümelenmemiş dizin nonunique olduğundan, satır bulucunun dizin anahtarlarında mevcut olması gerekir. Satır bulucudaki B ve A sütunları zaten mevcut, bu nedenle yalnızca C sütunu eklenir. Sütun C , anahtar sütun listesinin sonuna eklenir. |
Anahtar sütunlu benzersiz kümelenmiş dizin (A) |
Benzer olmayan, kümelenmemiş dizin anahtar sütunları (B, C) ve dahil edilen sütun (A) ile |
Anahtar sütunları (B, C, A) |
Kümelenmemiş dizin nonunique olduğundan satır bulucu anahtara eklenir. Sütun A zaten anahtar sütun olarak belirtilmediğinden, anahtar sütun listesinin sonuna eklenir. Sütun A artık anahtarda olduğundan, sütunu dahil edilen bir sütun olarak depolamanız gerekmez. |
Anahtar sütunlu benzersiz kümelenmiş dizin (A, B) |
Anahtar sütunlu benzersiz kümelenmemiş dizin (C) |
Anahtar sütunu (C) ve dahil edilen sütunlar (A, B) |
Kümelenmemiş dizin benzersizdir, bu nedenle satır bulucu dahil edilen sütunlara eklenir. |
Kümelenmemiş dizinler, sys.partitions içinde dizin tarafından kullanılan her bölüm için bir satıra sahiptir, index_id > 1. Varsayılan olarak, kümelenmemiş bir dizinin tek bir bölümü vardır. Bir kümelenmemiş dizinin birden çok bölümü olduğunda, her bölümün ilgili bölüm için dizin satırlarını içeren bir B+ ağaç yapısı vardır. Örneğin, bir kümelenmemiş dizinin dört bölümü varsa, her bölümde bir tane olmak üzere dört B+ ağaç yapısı vardır.
Kümelenmemiş dizindeki veri türlerine bağlı olarak, her bir kümelenmemiş dizin yapısında belirli bir bölüme ait verilerin depolandığı ve yönetileceği bir veya daha fazla ayırma birimi vardır. En azından, her bir kümelenmemiş dizin, dizin B+ ağaç sayfalarını depolayan bölüm başına bir IN_ROW_DATA ayırma birimine sahiptir. Kümelenmemiş dizin, LOB_DATA gibi büyük nesne (LOB) sütunları içeriyorsa, bölüm başına bir nvarchar(max) ayırma birimine de sahiptir. Ayrıca, 8.060 bayt satır boyutu sınırını aşan değişken uzunlukta sütunlar içeriyorsa bölüm başına bir ROW_OVERFLOW_DATA ayırma birimi vardır.
Aşağıdaki çizimde, tek bir bölümdeki bir kümelenmemiş dizinin yapısı gösterilmektedir.
Kümelenmemiş dizinlerde dahil edilen sütunları kullanma
Kümelenmemiş dizin anahtar sütunlara ek olarak, yaprak düzeyinde depolanan anahtar olmayan sütunlara da sahip olabilir. Bu anahtar olmayan sütunlar dahil edilen sütunlar olarak adlandırılır ve deyiminin INCLUDECREATE INDEX yan tümcesinde belirtilir.
Dahil edilen anahtar olmayan sütunlara sahip bir dizin, sorguyu kapsadığında, yani sorguda kullanılan tüm sütunlar anahtar veya anahtar olmayan sütunlar olarak dizinde olduğunda sorgu performansını önemli ölçüde artırabilir. Veritabanı Altyapısı dizindeki tüm sütun değerlerini bulabildiği için performans artışları elde edilir; temel tabloya erişilmez ve bu da daha az disk G/Ç işlemiyle sonuçlanır.
Bir sütunun bir sorgu tarafından alınması gerekiyorsa ancak sorgu koşullarında, toplamalarında ve sıralamalarında kullanılmadıysa, bunu anahtar sütun olarak değil, eklenen sütun olarak ekleyin. Bunun aşağıdaki avantajları vardır:
Eklenen sütunlar dizin anahtarı sütunları olarak izin verilmeyen veri türlerini kullanabilir.
Dizin anahtarı sütunlarının veya dizin anahtarı boyutunun sayısı hesaplanırken, eklenen sütunlar Veritabanı Altyapısı tarafından dikkate alınmaz. Eklenen sütunlarda en fazla 900 baytlık anahtar boyutuyla sınırlı değilsiniz. Daha fazla sorgu kapsayan daha geniş dizinler oluşturabilirsiniz.
Bir sütunu dizin anahtarından eklenen sütunlara taşıdığınızda, dizin sıralama işlemi daha hızlı hale geldiğinden dizin oluşturma işlemi daha kısa sürer.
Tabloda kümelenmiş dizin varsa, kümelenmiş dizin anahtarında tanımlanan sütun veya sütunlar tablodaki tek tek olmayan dizinlere otomatik olarak eklenir. Bunları kümelenmemiş dizin anahtarında veya dahil edilen sütunlarda belirtmek gerekmez.
Eklenen sütunlara sahip dizinler için yönergeler
Dahil edilen sütunlarla kümelenmemiş dizinler tasarlarken aşağıdaki yönergeleri göz önünde bulundurun:
Eklenen sütunlar yalnızca tablolarda veya dizinlenmiş görünümlerde kümelenmemiş dizinlerde tanımlanabilir.
metin, ntextve resimdışında tüm veri türlerine izin verilir.
Deterministik olan ve kesin veya kesin olmayan hesaplanan sütunlar, dahil edilen sütunlar olabilir. Daha fazla bilgi için bkz. Hesaplanan sütunlardaki dizinler.
Anahtar sütunlarda olduğu gibi, dahil edilen sütunda hesaplanan sütun veri türüne izin verildiğinde görüntü, ntext ve metin veri türlerinden türetilen hesaplanan sütunlar dahil edilebilir.
Sütun adları hem listede hem de
INCLUDEanahtar sütun listesinde belirtilemiyor.Sütun adları listede yinelenemez
INCLUDE.Dizinde en az bir anahtar sütunu tanımlanmalıdır. Eklenen sütun sayısı üst sınırı 1.023'tür. Bu, en fazla tablo sütunu sayısı eksi 1'dir.
Eklenen sütunların varlığından bağımsız olarak, dizin anahtarı sütunları en fazla 16 anahtar sütunu ve toplam dizin anahtarı boyutu 900 bayt olan mevcut dizin boyutu kısıtlamalarını izlemelidir.
Eklenen sütunlara sahip dizinler için tasarım önerileri
Yalnızca sorgu koşullarında, toplamalarda ve sıralamalarda kullanılan sütunların anahtar sütunlar olması için büyük bir dizin anahtarı boyutuna sahip kümelenmemiş dizinleri yeniden tasarlamayı göz önünde bulundurun. Sorguyu kapsayan diğer tüm sütunları anahtar olmayan sütunlara dahil edin. Bu şekilde, sorguyu kapsamak için gereken tüm sütunlara sahip olursunuz, ancak dizin anahtarının kendisi küçük ve verimlidir.
Örneğin, aşağıdaki sorguyu kapsayacak şekilde bir dizin tasarlamak istediğinizi varsayalım.
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
Sorguyu kapsamak için her sütunun dizinde tanımlanması gerekir. Tüm sütunları anahtar sütunları olarak tanımlayabilseniz de, anahtar boyutu 334 bayt olabilir. Arama ölçütü olarak kullanılan tek sütun, uzunluğu 30 bayt olan sütun olduğundan PostalCode , daha iyi bir dizin tasarımı anahtar sütun olarak tanımlar PostalCode ve diğer tüm sütunları anahtar olmayan sütunlar olarak ekler.
Aşağıdaki deyim, sorguyu kapsayacak şekilde eklenen sütunlar içeren bir dizin oluşturur.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Dizinin sorguyu kapsadığını doğrulamak için dizini oluşturun ve tahmini yürütme planını görüntüleyin. Yürütme planında dizin için IX_Address_PostalCode işleci gösteriliyorsa, sorgu dizin kapsamındadır.
Dahil edilen sütunlara sahip dizinler için performansla ilgili dikkat edilmesi gerekenler
Çok fazla sayıda dahil edilen sütun içeren dizinler oluşturmaktan kaçının. Dizin daha fazla sorguyu kapsasa da aşağıdaki nedenden dolayı performans avantajı azalır:
Sayfaya daha az dizin satırı sığar. Bu, disk G/Ç'sini artırır ve önbellek verimliliğini azaltır.
Dizini depolamak için daha fazla disk alanı gerekir. Özellikle, dahil edilen sütunlara varchar(max), nvarchar(max), varbinary(max)veya xml veri türleri eklemek disk alanı gereksinimlerini önemli ölçüde artırabilir. Bunun nedeni sütun değerlerinin dizin yaprak düzeyine kopyalanmış olmasıdır. Bu nedenle, hem dizinde hem de temel tabloda bulunurlar.
Birçok sütunun hem temel tabloda hem de kümelenmemiş dizinde değiştirilmesi gerektiğinden veri değiştirme performansı azalır.
Sorgu performansındaki kazançların veri değişikliği performansındaki düşüşten ve disk alanı gereksinimlerindeki artıştan daha ağır basıp basmadığını belirlemeniz gerekir.
Benzersiz dizin tasarımı yönergeleri
Benzersiz dizin, dizin anahtarının yinelenen değer içermediğini garanti eder. Benzersiz dizin oluşturmak yalnızca benzersizlik verilerin kendisinin bir özelliği olduğunda mümkündür. Örneğin, NationalIDNumber birincil anahtar olduğunda, HumanResources.Employee tablosundaki EmployeeID sütunundaki değerlerin benzersiz olduğundan emin olmak için, UNIQUE sütununda bir NationalIDNumber kısıtlaması oluşturun. Bu kısıtlama, ulusal kimlik numarası aynı olan satırların eklenmesi girişimlerini reddeder.
Çok sütunlu benzersiz dizinlerde dizin, dizin anahtarındaki her değer bileşiminin benzersiz olduğunu garanti eder. Örneğin, , LastNameve FirstName sütunlarının MiddleNamebirleşiminde benzersiz bir dizin oluşturulursa, tablodaki iki satır bu sütunlar için aynı değerlere sahip olamaz.
Hem kümelenmiş hem de kümelenmemiş dizinler benzersiz olabilir. Aynı tabloda benzersiz bir kümelenmiş dizin ve birden çok benzersiz kümelenmemiş dizin oluşturabilirsiniz.
Benzersiz dizinlerin avantajları şunlardır:
- Veri benzersizliği gerektiren iş kuralları uygulanır.
- Sorgu iyileştiricisi için yararlı olan ek bilgiler sağlanır.
PRIMARY KEY Veya UNIQUE kısıtlaması oluşturmak, belirtilen sütunlarda otomatik olarak benzersiz bir dizin oluşturur. Kısıtlama oluşturma UNIQUE ile kısıtlamadan bağımsız benzersiz bir dizin oluşturma arasında önemli bir fark yoktur. Veri doğrulama aynı şekilde gerçekleşir ve sorgu iyileştiricisi bir kısıtlama tarafından oluşturulan veya el ile oluşturulan benzersiz bir dizin arasında ayrım yapmaz. Ancak, iş kurallarının uygulanması hedef olduğunda sütunda bir UNIQUE veya PRIMARY KEY kısıtlaması oluşturmanız gerekir. Bunu yaparak, dizinin amacı açıktır.
Benzersiz dizinle ilgili dikkat edilmesi gerekenler
Verilerde yinelenen anahtar değerleri varsa benzersiz bir dizin
UNIQUE, kısıtlama veyaPRIMARY KEYkısıtlama oluşturulamaz.Veriler benzersizse ve benzersizliğin sağlanmasını istiyorsanız, aynı sütun bileşimi üzerinde benzersiz bir dizin yerine benzersiz olmayan bir dizin oluşturmak, sorgu iyileştiricisine daha verimli yürütme planları üretebilecek ek bilgiler sağlar. Bu durumda bir
UNIQUEkısıtlama veya benzersiz dizin oluşturulması önerilir.Benzersiz bir kümelenmemiş dizin, dahil edilen anahtar olmayan sütunlar içerebilir. Daha fazla bilgi için bkz. Dahil edilen sütunları kümelenmemiş dizinlerde kullanma.
PRIMARY KEYkısıtlamasından farklı olarak,UNIQUEdizin anahtarında null atanabilir bir sütun ile bir kısıtlama veya benzersiz bir dizin oluşturulabilir. Benzersizliği zorlama amacıyla iki NULL değerleri eşit kabul edilir. Örneğin, bu tek sütunlu benzersiz bir dizinde sütunun yalnızca tablodaki bir satır için NULL olabileceği anlamına gelir.
Filtrelenmiş dizin tasarımı yönergeleri
Filtrelenmiş dizin, özellikle tablodaki verilerin küçük bir alt kümesini gerektiren sorgular için uygun olan iyileştirilmiş bir kümelenmemiş dizindir. Tablodaki satırların bir bölümünü dizine almak için dizin tanımında bir filtre koşulu kullanır. İyi tasarlanmış bir filtrelenmiş dizin sorgu performansını artırabilir, dizin güncelleştirme maliyetlerini azaltabilir ve tam tablo diziniyle karşılaştırıldığında dizin depolama maliyetlerini azaltabilir.
Filtrelenmiş dizinler, tam tablo dizinlerine göre aşağıdaki avantajları sağlayabilir:
Geliştirilmiş sorgu performansı ve plan kalitesi
İyi tasarlanmış bir filtrelenmiş dizin, tam tablodaki bir kümelenmemiş dizinden daha küçük olduğundan sorgu performansını ve yürütme planı kalitesini artırır. Filtrelenmiş dizin, yalnızca filtrelenmiş dizindeki satırları kapsadığından tam tablo istatistiklerinden daha doğru olan filtrelenmiş istatistiklere sahiptir.
Daha düşük dizin güncelleştirme maliyetleri
Dizin yalnızca veri işleme dili (DML) deyimleri dizindeki verileri etkilediğinde güncelleştirilir. Filtrelenmiş dizin, daha küçük olduğundan ve yalnızca dizindeki veriler etkilendiğinde güncelleştirildiğinden, dizin güncelleştirme maliyetlerini tam tablo olmayan bir dizinle karşılaştırıldığında azaltır. Özellikle seyrek etkilenen veriler içerdiğinde çok sayıda filtrelenmiş dizine sahip olmak mümkündür. Benzer şekilde, filtrelenmiş bir dizin yalnızca sık etkilenen verileri içeriyorsa, dizinin boyutu daha küçükse istatistikleri güncelleştirme maliyeti azalır.
Daha düşük dizin depolama maliyetleri
Filtrelenmiş dizin oluşturmak, tam tablo dizini gerekli olmadığında, kümelenmemiş dizinler için disk depolama alanını azaltabilir. Depolama gereksinimlerini önemli ölçüde artırmadan, tam tablodaki bir kümelenmemiş dizini birden çok filtrelenmiş dizinle değiştirebilirsiniz.
Filtrelenmiş dizinler, sütunlar iyi tanımlanmış veri alt kümeleri içerdiğinde yararlıdır. Örnekler şunlardır:
Çok sayıda NUL içeren sütunlar.
Veri kategorileri içeren heterojen sütunlar.
Tutarlar, saat ve tarihler gibi değer aralıklarını içeren sütunlar.
Filtrelenmiş dizinler için daha düşük güncelleştirme maliyetleri, tam tablo diziniyle karşılaştırıldığında dizindeki satır sayısı küçük olduğunda en çok fark edilir. Filtrelenen dizin tablodaki satırların çoğunu içeriyorsa, tam tablo dizinine kıyasla bakımın maliyeti daha yüksek olabilir. Bu durumda, filtrelenmiş dizin yerine tam tablo dizini kullanmanız gerekir.
Filtrelenmiş dizinler bir tabloda tanımlanır ve yalnızca basit karşılaştırma işleçlerini destekler. Karmaşık mantığı olan veya birden çok tabloya başvuran bir filtre ifadesi gerekiyorsa, dizinlenmiş hesaplanan sütun veya dizinli görünüm oluşturmanız gerekir.
Filtrelenmiş dizin tasarımında dikkat edilmesi gerekenler
Etkili filtrelenmiş dizinler tasarlamak için uygulamanızın hangi sorguları kullandığını ve bunların verilerinizin alt kümeleriyle ilişkisini anlamak önemlidir. İyi tanımlanmış alt kümelere sahip verilere örnek olarak çok sayıda NUL içeren sütunlar, heterojen değer kategorilerine sahip sütunlar ve farklı değer aralıklarına sahip sütunlar verilebilir.
Aşağıdaki tasarım konuları, filtrelenmiş bir dizinin tam tablo dizinlerine göre ne zaman avantaj sağlayabildiğine ilişkin çeşitli senaryolar sunar.
Veri alt kümeleri için filtrelenmiş dizinler
Bir sütunda sorgular için yalnızca birkaç ilgili değer olduğunda, değerlerin alt kümesinde filtrelenmiş bir dizin oluşturabilirsiniz. Örneğin, sütun çoğunlukla NULL olduğunda ve sorgu yalnızca NULL olmayan değerler gerektiriyorsa, NULL olmayan satırları içeren filtrelenmiş bir dizin oluşturabilirsiniz.
Örneğin AdventureWorks örnek veritabanında 2.679 satır içeren bir Production.BillOfMaterials tablo vardır. Sütunda EndDate NULL olmayan bir değer içeren yalnızca 199 satır vardır ve diğer 2480 satır NULL değerini içerir. Aşağıdaki filtrelenmiş dizin, dizinde tanımlanan sütunları döndüren ve yalnızca EndDate için NULL olmayan bir değere sahip satırları gerektiren sorguları kapsar.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
Filtrelenen dizin FIBillOfMaterialsWithEndDate aşağıdaki sorgu için geçerlidir. Sorgu iyileştiricisinin filtrelenmiş dizini kullanıp kullanmadığını belirlemek için Tahmini Yürütme Planı'nı görüntüleyin.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Filtrelenmiş dizinler oluşturma ve filtrelenmiş dizin koşulu ifadesini tanımlama hakkında daha fazla bilgi için bkz. Filtrelenmiş dizinler oluşturma.
Heterojen veriler için filtrelenmiş dizinler
Tabloda heterojen veri satırları olduğunda, bir veya daha fazla veri kategorisi için filtrelenmiş dizin oluşturabilirsiniz.
Örneğin, tabloda listelenen Production.Product ürünlerin her biri bisikletler, bileşenler, kıyafetler veya aksesuarlar ürün kategorileriyle ilişkili olan bir ProductSubcategoryIDöğesine atanır. Tablodaki sütun değerleri yakın bağıntılı Production.Product olmadığından bu kategoriler heterojendir. Örneğin , , Color, ReorderPoint, ListPrice, Weightve Class sütunları Styleher ürün kategorisi için benzersiz özelliklere sahiptir. Aksesuarlar için 27 ile 36 arasında (dahil) alt kategorilere sahip sık sık sorgular olduğunu varsayalım. Aşağıdaki örnekte gösterildiği gibi aksesuarlar alt kategorilerinde filtrelenmiş dizin oluşturarak donatılar için sorguların performansını geliştirebilirsiniz.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
Sorgu sonuçları dizinde yer aldığı ve sorgu planının temel tabloya erişmesi gerekmediğinden, filtrelenmiş dizin FIProductAccessories aşağıdaki sorguyu kapsar. Örneğin, sorgu koşulu ifadesi ProductSubcategoryID = 33, filtrelenmiş dizin koşulu olan ProductSubcategoryID >= 27 ve ProductSubcategoryID <= 36'nin bir alt kümesidir. Sorgu koşulundaki ProductSubcategoryID ve ListPrice sütunları hem dizindeki anahtar sütunlar olup, name ise dizinin yaprak düzeyinde eklenmiş bir sütun olarak depolanır.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Filtrelenmiş dizinlerde anahtar ve eklenen sütunlar
Filtrelenmiş dizin tanımına az sayıda sütun eklemek en iyi yöntemdir; yalnızca sorgu iyileştiricisinin sorgu yürütme planı için filtrelenmiş dizini seçmesi için gereklidir. Sorgu iyileştiricisi, sorguyu kapsayıp kapsamadığına bakılmaksızın sorgu için filtrelenmiş bir dizin seçebilir. Ancak sorgu iyileştiricisi, sorguyu kapsıyorsa filtrelenmiş bir dizin seçme olasılığı daha yüksektir.
Bazı durumlarda filtrelenmiş dizin, filtrelenmiş dizin ifadesindeki sütunları anahtar olarak eklemeden veya filtrelenmiş dizin tanımına eklenen sütunlar eklemeden sorguyu kapsar. Aşağıdaki yönergelerde, filtrelenmiş dizin ifadesindeki bir sütunun anahtar veya filtrelenmiş dizin tanımına eklenmiş sütun olması gerektiği açıklanmaktadır. Örnekler, daha önce oluşturulan FIBillOfMaterialsWithEndDate filtrelenmiş dizine başvurur.
Filtrelenen dizin ifadesi sorgu koşuluna eşdeğerse ve sorgu filtrelenmiş dizin ifadesindeki sütunu sorgu sonuçlarıyla döndürmediyse, filtrelenmiş dizin ifadesindeki bir sütunun anahtar veya eklenmiş sütun olması gerekmez. Örneğin, FIBillOfMaterialsWithEndDate sorgu koşulu filtre ifadesiyle eşdeğer olduğundan ve EndDate sorgu sonuçlarıyla döndürülmediğinden aşağıdaki sorguyu kapsar. Dizinin FIBillOfMaterialsWithEndDate anahtar veya filtrelenmiş dizin tanımı içinde dahil edilmiş sütun olarak kullanılmasına EndDate ihtiyacı yoktur.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Sorgu koşulu filtrelenmiş dizin ifadesiyle eşdeğer olmayan bir karşılaştırmada sütunu kullanıyorsa, filtrelenmiş dizin ifadesindeki bir sütun, filtrelenmiş dizin tanımında bir anahtar veya eklenen sütun olmalıdır. Örneğin, FIBillOfMaterialsWithEndDate filtrelenmiş dizinden bir satır alt kümesi seçtiğinden aşağıdaki sorgu için geçerlidir. Ancak, aşağıdaki sorguyu kapsamaz çünkü EndDate karşılaştırmada EndDate > '20040101'kullanılır ve filtrelenmiş dizin ifadesiyle eşdeğer değildir. Sorgu işlemcisi, değerlerini EndDateincelemeden bu sorguyu yürütemez. Bu nedenle, EndDate filtrelenmiş dizin tanımında bir anahtar veya dahil edilen sütun olmalıdır.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Filtrelenmiş dizin ifadesindeki bir sütun, eğer sorgu sonuç kümesinde yer alıyorsa, filtrelenmiş dizin tanımında anahtar sütun veya dahil edilmiş sütun olarak bulunmalıdır. Örneğin, FIBillOfMaterialsWithEndDate sorgu sonuçlarında sütunu döndürdüğünden aşağıdaki sorguyu EndDate kapsamaz. Bu nedenle, EndDate filtrelenmiş dizin tanımında bir anahtar veya dahil edilen sütun olmalıdır.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Tablonun kümelenmiş dizin anahtarının filtrelenmiş dizin tanımına bir anahtar veya eklenmiş sütun olması gerekmez. Kümelenmiş dizin anahtarı, filtrelenmiş dizinler de dahil olmak üzere tüm kümelenmemiş dizinlere otomatik olarak eklenir.
Filtre koşulundaki veri dönüştürme işleçleri
Filtrelenen dizinin filtrelenmiş dizin ifadesinde belirtilen karşılaştırma işleci örtük veya açık bir veri dönüştürmeyle sonuçlanırsa, dönüştürme bir karşılaştırma işlecinin sol tarafında gerçekleşirse bir hata oluşur. Çözüm, filtrelenmiş dizin ifadesini karşılaştırma işlecinin sağ tarafına veri dönüştürme işleci (CAST veya CONVERT) ile yazmaktır.
Aşağıdaki örnek, farklı veri türlerinde sütunlar içeren bir tablo oluşturur.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
Aşağıdaki filtrelenmiş dizin tanımında sütun b örtük olarak bir tamsayı veri türüne dönüştürülerek 1 sabitine karşılaştırılır. Filtrelenen önermedeki işlecin sol tarafında dönüştürme gerçekleştiğinden 10611 hata iletisi oluşur.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
Çözüm, sağ taraftaki sabiti, aşağıdaki örnekte görüldüğü gibi sütunuyla baynı türde olacak şekilde dönüştürmektir:
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Veri dönüştürme işleminin sol tarafından bir karşılaştırma işlecinin sağ tarafına taşınması dönüştürmenin anlamını değiştirebilir. Önceki örnekte, işleç sağ tarafa eklendiğinde CONVERT , karşılaştırma bir int karşılaştırmasından varbinary karşılaştırmasına değiştirildi.
Columnstore dizin mimarisi
Columnstore dizini, columnstore adı verilen sütunlu bir veri biçimi kullanarak verileri depolamaya, almaya ve yönetmeye yönelik bir teknolojidir. Daha fazla bilgi için bkz. Columnstore dizinleri: genel bakış.
Sürüm bilgileri ve yenilikler hakkında bilgi edinmek için columnstore dizinlerindeki yenilikler'i ziyaret edin.
Bu temel bilgileri bilmek, bu teknolojinin etkili bir şekilde nasıl kullanılacağını açıklayan diğer columnstore makalelerini anlamanızı kolaylaştırır.
Veri depolama, sütun deposu (columnstore) ve satır deposu (rowstore) kullanır.
Columnstore dizinlerini tartışırken, veri depolama biçimini vurgulama amacıyla rowstore ve columnstore terimlerini kullanırız. Columnstore dizinleri her iki depolama türünü de kullanır.
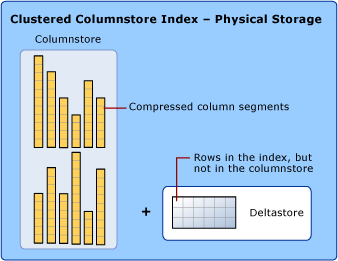
Columnstore, mantıksal olarak satırlar ve sütunlar içeren bir tablo olarak düzenlenmiş ve fiziksel olarak sütuna göre veri biçiminde depolanan verilerdir.
Columnstore dizini, verilerin çoğunu columnstore biçiminde fiziksel olarak depolar. Columnstore biçiminde veriler sütunlar halinde sıkıştırılır ve sıkıştırılmış veriler açılır. Sorgu tarafından istenmeyen satırlardaki diğer değerlerin sıkıştırmalarını kaldırmaya gerek yoktur. Bu, büyük bir tablonun tüm sütununu taramayı hızlandırır.
Satır deposu, satırlar ve sütunlar içeren bir tablo olarak mantıksal olarak düzenlenmiş ve ardından fiziksel olarak satır başına veri biçiminde depolanan verilerdir. Bu, kümelenmiş B+ ağaç dizini veya yığın gibi ilişkisel tablo verilerini depolamanın geleneksel yolu olmuştur.
Columnstore dizini bazı satırları, fiziksel olarak "deltastore" adı verilen bir satır deposu biçiminde de depolar. Delta satır grupları olarak da adlandırılan deltastore, sayıca az oldukları için henüz columnstore'a sıkıştırılmaya uygun olmayan satırların saklandığı bir yerdir. Her delta satır grubu, bir satır deposu olan kümelenmiş B+ ağaç dizini olarak uygulanır.
İşlemler satır gruplarında ve sütun segmentlerinde gerçekleştirilir
columnstore dizini satırları yönetilebilir birimler halinde gruplandırıyor. Bu birimlerin her biri satır grubu olarak adlandırılır. En iyi performans için, bir satır grubundaki satır sayısı sıkıştırma oranını artıracak kadar büyük ve bellek işlemlerinde yararlanabilecek kadar küçüktür.
Örneğin, columnstore dizini şu işlemleri satır gruplarında gerçekleştirir:
Satır gruplarını columnstore'da sıkıştırır. Sıkıştırma, bir satır grubu içindeki her sütun kesiminde gerçekleştirilir.
Silinen verilerin kaldırılması da dahil olmak üzere bir işlem sırasında satır gruplarını birleştirir
ALTER INDEX ... REORGANIZE.Tüm satır gruplarını bir
ALTER INDEX ... REBUILDişlemi sırasında yeniden oluşturur.Dinamik yönetim görünümlerinde (DMV'ler) satır grubu sağlığı ve parçalanma hakkında raporlar.
Deltastore, delta rowgroups adlı bir veya daha fazla satır grubundan oluşur. Her delta satır grubu, küçük toplu yükleri ve eklemeleri depolayan kümelenmiş bir B+ ağaç dizinidir ve satır grubu 1.048.576 satıra ulaştığında, tuple-mover olarak adlandırılan bir işlem otomatik olarak kapalı bir satır grubunu columnstore'da sıkıştırır.
Satır grubu durumları hakkında daha fazla bilgi için bkz. sys.dm_db_column_store_row_group_physical_stats.
Tip
Çok fazla küçük satır grubu olması columnstore dizin kalitesini düşürür. Yeniden düzenleme işlemi, silinen satırların nasıl kaldırılacağını ve sıkıştırılmış satır gruplarının nasıl birleştirileceğini belirleyen bir iç eşik ilkesi izleyerek daha küçük satır gruplarını birleştirir. Birleştirme işleminden sonra dizin kalitesi iyileştirilir.
SQL Server 2019 (15.x) ve sonraki sürümlerinde, tuple taşıyıcı, bir iç eşiğe göre bir süredir var olan daha küçük açık delta satır gruplarını otomatik olarak sıkıştıran ya da çok sayıda satırın silindiği sıkıştırılmış satır gruplarını birleştiren arka plan birleştirme göreviyle desteklenir.
Her sütunun her satır grubunda bazı değerleri vardır. Bu değerlere sütun segmentleri adı verilir. Her satır grubu, tablodaki her sütun için bir sütun kesimi içerir. Her sütunun her satır grubunda bir sütun kesimi vardır.
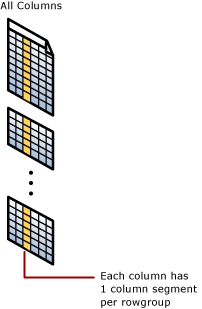
Columnstore dizini bir satır grubunu sıkıştırdığında, her sütun kesimini ayrı ayrı sıkıştırır. Bir sütunun tamamını dekomprese etmek için, columnstore dizini her satır grubundan sadece bir sütun kesimini dekomprese etmelidir.
Küçük yükler ve ek parçalar deltastore'a ulaşıyor.
Columnstore dizini, bir kerede en az 102.400 satırı columnstore dizinine sıkıştırarak columnstore sıkıştırmasını ve performansını geliştirir. Satırları toplu olarak sıkıştırmak için columnstore dizini küçük yükler biriktirir ve deltastore'ya ekler. Deltastore işlemleri arka planda yürütülür. Sorgu sonuçlarını döndürmek için, kümelenmiş columnstore dizini hem columnstore hem de deltastore'dan gelen sorgu sonuçlarını birleştirir.
Satırlar aşağıdaki durumlarda deltastore'a gider:
INSERT INTO ... VALUESdeyimi ile eklendi.Toplu yüklemenin sonunda sayı 102.400'den azdır.
Updated. Her güncelleştirme bir silme ve ekleme olarak uygulanır.
Delta deposu ayrıca silinen, ancak henüz sütun deposundan fiziksel olarak silinmemiş olan satırlar için kimliklerin listesini de depolar.
Delta satır grupları dolduğunda, sütun deposuna sıkıştırılırlar.
Kümelenmiş columnstore dizinleri, satır grubunu columnstore'da sıkıştırmadan önce her delta satır grubunda en fazla 1.048.576 satır toplar. Bu, sütun deposu indeksinin sıkıştırmasını iyileştirir. Delta satır grubu en fazla satır sayısına ulaştığında, bir OPEN durumdan duruma CLOSED geçiş yapılır. Tuple-mover adı verilen bir arka plan işlemi, kapalı satır gruplarını kontrol eder. İşlem kapalı bir satır grubu bulursa, satır grubunu sıkıştırır ve columnstore'da depolar.
Bir delta satır grubu sıkıştırıldığında, mevcut delta satır grubu, ona bir başvuru kalmadığında ve daha sonra ikiye atıcı tarafından kaldırılacak duruma geçer TOMBSTONE, yeni sıkıştırılmış satır grubu ise COMPRESSED olarak işaretlenir.
Satır grubu durumları hakkında daha fazla bilgi için bkz. sys.dm_db_column_store_row_group_physical_stats.
Dizini yeniden oluşturmak veya yeniden düzenlemek için ALTER INDEX kullanarak delta satır gruplarını sütun deposuna zorla taşıyabilirsiniz. Sıkıştırma sırasında bellek baskısı varsa columnstore dizini sıkıştırılmış satır grubundaki satır sayısını azaltabilir.
Her tablo bölümünün kendi satır grupları ve delta satır grupları vardır
Bölümleme kavramı kümelenmiş dizinde, yığında ve columnstore dizininde aynıdır. Bir tablonun bölümlenmesi, tabloyu bir sütun değerleri aralığına göre daha küçük satır gruplarına böler. Genellikle verileri yönetmek için kullanılır. Örneğin, verilerin her yılı için bir bölüm oluşturabilir ve ardından bölüm değiştirme özelliğini kullanarak eski verileri daha ucuz depolama alanına arşivleyebilirsiniz.
Satır grupları her zaman bir tablo bölümü içinde tanımlanır. Bir columnstore dizini bölümlendiğinde, her bölümün kendi sıkıştırılmış satır grupları ve delta satır grupları vardır. Bölümlenmemiş bir tablo bir bölüm içerir.
Tip
Columnstore'dan veri kaldırmanız gerekiyorsa tablo bölümleme kullanmayı göz önünde bulundurun. Artık gerekli olmayan bölümlerin değiştirilmesi ve kesilmesi, columnstore'da parçalanma olmadan verileri silmeye yönelik verimli bir stratejidir.
Her bölümde birden çok delta satır grubu olabilir
Her bölümde birden fazla delta satır grubu olabilir. Columnstore dizininin bir delta satır grubuna veri eklemesi gerektiğinde ve delta satır grubu başka bir işlem tarafından kilitlendiğinde, columnstore dizini farklı bir delta satır grubunda kilit almaya çalışır. Herhangi bir delta satır grubu mevcut değilse, columnstore indeks yeni bir delta satır grubu oluşturur. Örneğin, 10 bölümü olan bir tabloda kolayca 20 veya daha fazla delta satır grubu olabilir.
Columnstore ve rowstore dizinlerini aynı tabloda birleştirme
Kümelenmemiş dizin, temel alınan tablodaki satır ve sütunların bir kısmının veya tümünün kopyasını içerir. Dizin, tablonun bir veya daha fazla sütunu olarak tanımlanır ve satırları filtreleyen isteğe bağlı bir koşula sahiptir.
Bir satır deposu tablosunda güncelleştirilebilir bir kümelenmemiş columnstore dizini oluşturabilirsiniz. Columnstore dizini verilerin bir kopyasını depolar, böylece ek depolamaya ihtiyacınız olur. Ancak columnstore dizinindeki veriler, rowstore tablosunun gerektirdiğinden çok daha küçük bir boyuta sıkıştırılır. Bunu yaparak, columnstore dizininde analiz çalıştırabilir ve rowstore dizinindeki OLTP iş yüklerini aynı anda çalıştırabilirsiniz. Satır deposu tablosundaki veriler değiştiğinde columnstore güncelleştirilir, bu nedenle her iki dizin de aynı verilerle çalışır.
Bir satır deposu tablosunda bir tane kümelenmemiş sütun deposu dizini olabilir. Daha fazla bilgi için bkz. Columnstore dizinleri - tasarım kılavuzu.
Kümelenmiş columnstore tablosunda bir veya daha fazla kümelenmemiş satır deposu dizininiz olabilir. Bunu yaparak, temel alınan columnstore üzerinde verimli tablo aramaları gerçekleştirebilirsiniz. Diğer seçenekler de kullanılabilir duruma gelir. Örneğin, rowstore tablosundaki bir UNIQUE kısıtlamayı kullanarak benzersizliği zorlayabilirsiniz. Satır deposu tablosuna benzersiz olmayan bir değer eklenemediğinde, Veritabanı Altyapısı değeri sütun deposuna da eklemez.
Kümelenmemiş columnstore performansıyla ilgili dikkat edilmesi gerekenler
Kümelenmemiş columnstore dizin tanımı, filtrelenmiş koşul kullanmayı destekler. Columnstore dizini eklemenin performans etkisini en aza indirmek için filtre ifadesini kullanarak analiz için gereken verilerin yalnızca alt kümesinde kümelenmemiş bir columnstore dizini oluşturun.
Bellek ile optimize edilmiş bir tabloda bir sütun deposu dizini olabilir. Tablo oluşturulduğunda oluşturabilir veya daha sonra ile ALTER TABLEekleyebilirsiniz.
Daha fazla bilgi için bkz. Columnstore dizinleri - sorgu performansı.
Bellek optimize edilmiş hash dizin tasarım yönergeleri
In-Memory OLTP kullanılırken, bellek için iyileştirilmiş tüm tabloların en az bir dizini olmalıdır. Bellek optimizasyonlu bir tablo için, her dizin de bellek optimizasyonludur. Karma dizinler, bellek için iyileştirilmiş bir tablodaki olası dizin türlerinden biridir. Daha fazla bilgi için bkz. Memory-Optimized Tablolarındaki Dizinler.
Bellek optimize edilmiş karma dizin mimarisi
Karma dizin bir dizi işaretçiden oluşur ve dizinin her öğesi karma demet olarak adlandırılır.
- Her kova, anahtar girdilerinin bağlantı listesinin bellek adresini depolamak için kullanılan 8 bayttır.
- Her giriş, bir dizin anahtarının değeri ve bellek ile optimize edilmiş temel tablodaki karşılık gelen satırın adresidir.
- Her giriş, tamamı mevcut kova ile zincirlenmiş bir bağlantı listesindeki bir sonraki girişe işaret eder.
Demet sayısı dizin oluşturma zamanında belirtilmelidir:
- Demetlerin tablo satırlarına veya farklı değerlere oranı ne kadar düşükse, ortalama demet bağlantı listesi o kadar uzun olur.
- Kısa bağlantı listeleri, uzun bağlantı listelerinden daha hızlı çalışır.
- Karma dizinlemedeki maksimum demet sayısı 1.073.741.824'tür.
Tip
Verileriniz için doğru BUCKET_COUNT değerini belirlemek üzere bkz. Karma dizini kova sayısını yapılandırma.
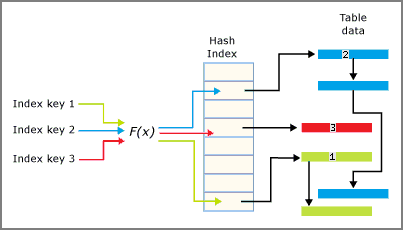
Karma fonksiyonu indeks anahtar sütunlarına uygulanır ve fonksiyonun sonucu bu anahtarın hangi bölmeye düşeceğini belirler. Her kova, karma anahtar değerleri bu kovayla eşlenen satırlara işaret eden bir gösterici içerir.
Karma indeksler için kullanılan karma işlevinin aşağıdaki özellikleri vardır:
- Veritabanı Motoru'nun, tüm karma dizinler için kullanılan tek bir karma işlevi vardır.
- Karma işlevi belirleyicidir. Aynı giriş anahtar değeri her zaman karma dizindeki aynı kova ile eşlenir.
- Birden çok dizin anahtarı aynı karma demetine eşlenebilir.
- Hash fonksiyonu dengelidir, yani dizin anahtar değerlerinin hash kümeleri üzerinden dağılımı, genellikle düz bir doğrusal dağılım yerine Poisson veya çan eğrisi dağılımını izler.
- Poisson dağılımı eşit bir dağıtım değildir. Dizin anahtarı değerleri karma demetlerinde eşit olarak dağılmamaktadır.
- Eğer iki dizin anahtarı aynı karma demetine eşlenmişse, bir karma çakışması meydana gelir. Çok sayıda karma çakışmasının okuma işlemleri üzerinde performans etkisi olabilir. Gerçekçi bir hedef, demetlerin yüzde 30'unun iki farklı anahtar değeri içermesidir.
Karma indeksin ve demetlerin etkileşimi aşağıdaki görüntüde özetlenmiş.
Karma dizin demet sayısını yapılandırma
Karma dizin (hash index) kova sayısı, dizin oluşturulma zamanında belirtilir ve ALTER TABLE...ALTER INDEX REBUILD söz dizimini kullanarak değiştirilebilir.
Çoğu durumda, demet sayısı dizin anahtarındaki ayrı değerlerin sayısının 1 ile 2 katı arasında olmalıdır.
Belirli bir dizin anahtarının sahip olduğu değer sayısını her zaman tahmin edemeyebilirsiniz. Değer BUCKET_COUNT, gerçek anahtar değer sayısının 10 katı içinde yer alıyorsa performans genellikle iyi olur ve fazla tahmin yapmak genellikle az tahmin yapmaktan daha iyidir.
Çok az demet aşağıdaki dezavantajlara sahip olabilir:
- Farklı anahtar değerlerinin daha fazla karma çakışması.
- Her bir farklı değer, aynı kovayı başka bir farklı değerle paylaşmaya zorlanır.
- Kova başına ortalama zincir uzunluğu artar.
- Kovalı zincir ne kadar uzun olursa, dizindeki eşitlik aramalarının hızı o kadar azalır.
Çok fazla demet aşağıdaki dezavantajlara sahip olabilir:
- Çok fazla kova sayısı, daha fazla boş kova ile sonuçlanabilir.
- Boş kovalar, tam dizin taramalarının performanslarını etkiler. Taramalar düzenli olarak gerçekleştiriliyorsa, ayrı dizin anahtarı değerlerinin sayısına yakın bir demet sayısı seçmeyi göz önünde bulundurun.
- Boş demetler bellek kullanır, ancak her demet yalnızca 8 bayt kullanır.
Note
Daha fazla kova eklemek, yinelenen bir değeri paylaşan girişlerin zincirlenmesini azaltmak için hiçbir etkisi yoktur. Değer yineleme hızı, demet sayısını hesaplamak için değil, karma dizinin mi yoksa kümelenmemiş dizinin mi uygun dizin türü olduğuna karar vermek için kullanılır.
Karma dizinler için performansla ilgili dikkat edilmesi gerekenler
Hash dizinin performansı şu şekildedir:
- Yüklem
WHEREtümcesi karma dizin anahtarındaki her sütun için tam bir değer belirttiğinde mükemmeldir. Karma indeks, eşitsizlik koşulu verildiğinde tarama moduna geri döner. - İndeks anahtarındaki
WHEREnı arayan tümcesindeki yüklem zayıf olduğunda. - Yan tümce, iki sütunlu karma dizin anahtarında
WHEREsütun için belirli bir değer belirtip, anahtarın diğer sütunları için değer belirtmediğinde uygun olmaz.
Tip
Koşul, karma dizin anahtarındaki tüm sütunları içermelidir. Hash dizini, dizinde arama yapmak için anahtarın tamamını gerektirir.
Karma dizin kullanılıyorsa ve benzersiz dizin anahtarlarının sayısı satır sayısından 100 kat daha küçükse, büyük satır zincirlerini önlemek için daha büyük bir demet sayısına artırmayı veya bunun yerine kümelenmemiş dizin kullanmayı göz önünde bulundurun.
Hash indeksi oluştur
Karma dizin oluştururken şunları göz önünde bulundurun:
- Hash dizin yalnızca bellek iyileştirilmiş bir tabloda bulunabilir. Disk tabanlı bir tabloda bulunamaz.
- Karma dizin varsayılan olarak benzersiz değildir, ancak benzersiz olarak ilan edilebilir.
Aşağıdaki örnek benzersiz bir karma dizin oluşturur:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Bellek için iyileştirilmiş tablolarda satır sürümleri ve çöp toplama
Bellek için iyileştirilmiş bir tabloda, bir satır bir UPDATE deyimden etkilendiğinde, tablo satırın güncelleştirilmiş bir sürümünü oluşturur. Güncelleştirme işlemi sırasında, diğer oturumlar satırın eski sürümünü okuyabilir ve bu nedenle satır kilidiyle ilişkili performans yavaşlamasını önleyebilirsiniz.
Karma dizin, güncelleştirmeye uyum sağlamak için girdilerinin farklı sürümlerine de sahip olabilir.
Daha sonra eski sürümlere artık ihtiyaç duyulmadığında, eski girdileri temizlemek için bir çöp toplama (GC) iş parçacığı demetleri ve bağlantı listelerini gezer. Bağlantı listesi zincir uzunlukları kısaysa GC iş parçacığı daha iyi performans gösterir. Daha fazla bilgi için bkz. In-Memory OLTP Çöp Toplama.
Bellek için iyileştirilmiş kümelenmemiş dizin tasarım yönergeleri
Karma dizinlerin yanı sıra, kümelenmemiş dizinler bellek için iyileştirilmiş bir tablodaki diğer olası dizin türleridir. Daha fazla bilgi için bkz. Memory-Optimized Tablolarındaki Dizinler.
Bellek için optimize edilmiş kümelenmemiş dizin mimarisi
Bellek için iyileştirilmiş tablolardaki kümelenmemiş dizinler, başlangıçta 2011'de Microsoft Research tarafından öngörülen ve açıklanan Bw ağacı adlı bir veri yapısı kullanılarak uygulanır. Bw ağacı, bir B ağacının kilit ve mandalsız varyasyonudur. Daha fazla bilgi için bkz. Bw ağacı: Yeni Donanım Platformları için B ağacı.
Yüksek düzeyde, Bw ağacı sayfa kimliğine (PidMap), sayfa kimliklerini (PidAlloc) ayırmaya ve yeniden kullanma olanağına ve sayfa haritasında ve birbirine bağlı sayfa kümesine göre düzenlenmiş sayfaların haritası olarak anlaşılabilir. Bu üç üst düzey alt bileşen, bir Bw ağacının temel iç yapısını oluşturur.
Yapı, her sayfanın sıralanmış bir dizi anahtar değerine sahip olması ve dizinde her biri daha düşük bir düzeye, yaprak düzeyleri ise bir veri satırına işaret eden düzeyler olması açısından normal bir B ağacına benzer. Ancak çeşitli farklar vardır.
Karma dizinlerde olduğu gibi, sürüm oluşturmayı desteklemek için birden çok veri satırı birbirine bağlanabilir. Düzeyler arasındaki sayfa işaretçileri, sayfa eşleme tablosuna uzaklıkları olan mantıksal sayfa kimlikleridir ve bu da her sayfa için fiziksel adrese sahiptir.
Dizin sayfalarında yerinde güncelleştirme yoktur. Bu amaçla yeni delta sayfaları kullanıma sunulmuştur.
- Sayfa güncelleştirmeleri için mandallama veya kilitleme gerekmiyor.
- Dizin sayfaları sabit bir boyut değildir.
Her bir yaprak düzeyi olmayan sayfadaki anahtar değer, işaret ettiği alt öğede bulunan en yüksek anahtar değerdir ve her satır da bu sayfanın mantıksal sayfa kimliğini içerir. Yaprak düzeyindeki sayfalarda, anahtar değeriyle birlikte veri satırının fiziksel adresini içerir.
Nokta aramaları B ağaçlarına benzer, ancak sayfalar yalnızca bir yönde bağlantılı olduğundan, Veritabanı Altyapısı sağ sayfa işaretçilerini izler; burada her bir yapraksız sayfa, B ağacında olduğu gibi en düşük değer yerine alt öğesinden en yüksek değere sahiptir.
Yaprak düzeyi bir sayfanın değişmesi gerekiyorsa, Veritabanı Altyapısı sayfanın kendisini değiştirmez. Bunun yerine, Veritabanı Altyapısı değişikliği açıklayan bir delta kaydı oluşturur ve önceki sayfaya ekler. Ardından, önceki sayfanın sayfa eşleme tablosu adresini, bu sayfanın fiziksel adresi haline gelen delta kaydının adresiyle de güncelleştirir.
Bw ağacının yapısını yönetmek için gereken üç farklı işlem vardır: birleştirme, bölme ve birleştirme.
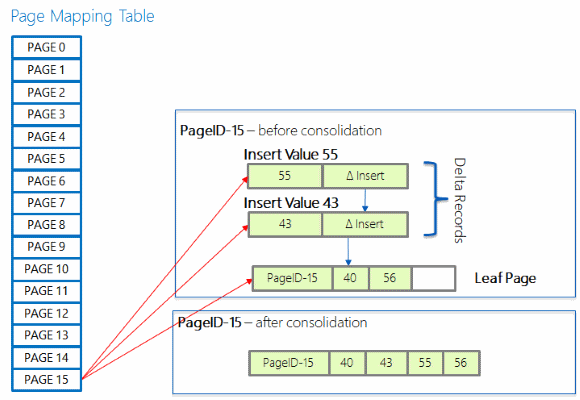
Delta birleştirilmesi
Uzun bir delta kaydı zinciri, bir dizinde arama yaparken uzun zincir geçişi gerektirebileceği için arama performansını düşürebilir. Zaten 16 öğesi olan bir zincire yeni bir delta kaydı eklenirse, delta kayıtlarındaki değişiklikler başvurulan dizin sayfasında birleştirilir ve birleştirmeyi tetikleyen yeni değişiklik kaydı tarafından belirtilen değişiklikler de dahil olmak üzere sayfa yeniden oluşturulur. Yeni yeniden oluşturulmuş sayfa aynı sayfa kimliğine ancak yeni bir bellek adresine sahip.
Sayfayı böl
Bw-tree'deki bir dizin sayfası, tek bir satırı depolamaktan en fazla 8 KB depolamaya kadar her zaman gereken şekilde büyür. Dizin sayfası 8 KB'a büyüdükten sonra, tek bir satırın yeni bir eklemesi dizin sayfasının bölünmesine neden olur. Bir iç sayfa için bu, başka bir anahtar değer ve işaretçi eklemek için yer kalmadığı anlamına gelir. Bir yaprak sayfa için ise, tüm delta kayıtları birleştirildiğinde satırın sayfaya sığamayacak derecede büyük olması anlamını taşır. Yaprak sayfanın sayfa üst bilgisindeki istatistik bilgileri, delta kayıtlarını birleştirmek için gereken alan miktarını izler. Her yeni fark kaydı eklendikçe bu bilgiler ayarlanır.
Bölme işlemi iki atomik adımda gerçekleştirilir. Aşağıdaki diyagramda, 5 değerine sahip bir anahtarın eklenmesi nedeniyle bir yaprak sayfanın bölünmeye neden olduğunu ve geçerli yaprak düzeyi sayfasının sonuna işaret eden bir yaprak olmayan sayfanın bulunduğunu varsayalım.

1. Adım: ve P1olmak üzere iki yeni sayfa P2 ayırın ve yeni eklenen satır da dahil olmak üzere eski P1 sayfadaki satırları bu yeni sayfalara bölün. Sayfanın fiziksel adresini depolamak için P2 yeni bir yuva kullanılır. sayfalar P1 ve P2 henüz hiçbir eş zamanlı işlem tarafından erişilemez. Buna ek olarak, P1'den P2'e mantıksal işaretçi ayarlanır. Ardından, bir atomik adımda, işaretçiyi eski P1 yerine yeni P1olarak değiştirmek için sayfa eşleme tablosunu güncelleştirin.
2. Adım: Yaprak olmayan sayfa P1 işaret eder ama yaprak olmayan bir sayfadan P2 öğesine doğrudan işaretçi yoktur.
P2 yalnızca P1 aracılığıyla ulaşılabilir. Bir yaprak olmayan sayfadan P2'a işaretçi oluşturmak için, yeni bir yaprak olmayan sayfa (iç dizin sayfası) ayırın, eski yaprak olmayan sayfadan tüm satırları kopyalayın ve P2'e işaret eden yeni bir satır ekleyin. Bu işlem tamamlandıktan sonra, tek ve atomik bir adımda, işaretçiyi eski yaprak olmayan sayfadan yeni yaprak olmayan sayfaya değiştirmek için sayfa eşleme tablosunu güncelleyin.
Sayfayı birleştir
Bir DELETE işlem, sayfanın en büyük sayfa boyutunun yüzde 10'undan (8 KB) az olmasına veya tek bir satıra sahip olmasına neden olduğunda, bu sayfa bitişik bir sayfayla birleştirilir.
Sayfadan bir satır silindiğinde, silme için bir delta kaydı eklenir. Ayrıca, dizin sayfasının (af olmayan sayfa) birleştirme için uygun olup olmadığını belirlemek için bir denetim yapılır. Bu denetim, satırı sildikten sonra kalan alanın sayfa boyutu üst sınırının yüzde 10'undan az olup olmadığını doğrular. Uygunsa birleştirme üç atomik adımda gerçekleştirilir.
Aşağıdaki görüntüde, bir DELETE işleminin 10 anahtar değerini sildiğini varsayın.

1. Adım: Anahtar değerini 10 (mavi üçgen) temsil eden bir delta sayfası oluşturulur ve boş olmayan sayfadaki Pp1 işaretçisi yeni delta sayfasına ayarlanır. Ayrıca özel bir birleştirme delta sayfası (yeşil üçgen) oluşturulur ve delta sayfasına işaret etmek için bağlanır. Bu aşamada, her iki sayfa da (delta sayfası ve birleştirme-delta sayfası) hiçbir eşzamanlı işlem tarafından görülemez. Atomik bir adımda, sayfa eşleme tablosundaki yaprak düzeyi sayfanın P1 göstericisi, birleştirme-delta sayfasına işaret edecek şekilde güncellenir. Bu adımdan sonra anahtar değeri 10 içindeki Pp1 girdisi, şimdi birleştirme-delta sayfasına işaret ediyor.
2. Adım: Yaprak olmayan sayfadaki 7 anahtar değerini temsil eden satırın silinmesi ve Pp1 anahtar değeri için girdinin 10 öğesini işaret edecek şekilde güncellenmesi gerekir. Bunu yapmak için, yeni bir boş olmayan sayfa Pp2 ayrılır ve anahtar değeri Pp1 satırının haricindeki tüm satırlar 7 içinden kopyalanır; ardından anahtar değeri 10 için olan satır, sayfa P1'e işaret edecek şekilde güncellenir. Bu yapıldıktan sonra, tek bir atomik adımda, Pp1'ı işaret eden sayfa eşleme tablosu girişi, Pp2'i işaret edecek şekilde güncellenir.
Pp1 artık ulaşılamıyor.
Adım 3: Yaprak düzeyi sayfalar P2 ve P1 birleştirilir ve delta sayfaları kaldırılır. Bunu yapmak için yeni bir sayfa P3 ayrılır, P2 ile P1 içindeki satırlar birleştirilir ve delta sayfası değişiklikleri yeni P3 öğesine eklenir. Ardından, atomik bir adımda, sayfa P1'a işaret eden sayfa eşleme tablosu girişi, sayfa P3'e işaret edecek şekilde güncellenir.
Bellek için iyileştirilmiş kümelenmemiş dizinler için performansla ilgili dikkat edilmesi gerekenler
Kümelenmemiş bir dizinin performansı, eşitsizlik belirleyicileriyle bellek için iyileştirilmiş bir tablo sorgulanırken karma dizinlerden daha iyidir.
Bellek açısından optimize edilmiş bir tablodaki bir sütun, hem karma indeksin hem de kümelenmemiş indeksin parçası olabilir.
Bir kümelenmemiş dizindeki bir anahtar sütunda çok sayıda yinelenen değer olduğunda, güncelleştirmeler, eklemeler ve silmeler için performans düşebilir. Bu durumda performansı artırmanın bir yolu, dizin anahtarında daha iyi seçiciliğe sahip bir sütun eklemektir.
Dizin meta verileri
Dizin tanımları, özellikler ve veri istatistikleri gibi dizin meta verilerini incelemek için aşağıdaki sistem görünümlerini kullanın:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Önceki görünümler tüm dizin türleri için geçerlidir. Columnstore dizinleri için ayrıca aşağıdaki görünümleri kullanın:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
columnstore dizinleri için tüm sütunlar meta verilerde dahil edilen sütunlar olarak depolanır. columnstore dizininde anahtar sütunlar yoktur.
Bellek için iyileştirilmiş tablolardaki dizinler için ayrıca aşağıdaki görünümleri kullanın:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
İlgili içerik
- CREATE INDEX (Transact-SQL)
- Sorgu performansını geliştirmek ve kaynak tüketimini azaltmak için dizin bakımını iyileştirme
- Bölümlü tablolar ve dizinler
- Memory-Optimized Tablolardaki Dizinler
- Columnstore dizinleri: genel bakış
- Hesaplanan sütunlardaki dizinler
- Kümelenmemiş dizinleri eksik indeks önerileri kullanarak iyileştirin