Lưu ý
Cần có ủy quyền mới truy nhập được vào trang này. Bạn có thể thử đăng nhập hoặc thay đổi thư mục.
Cần có ủy quyền mới truy nhập được vào trang này. Bạn có thể thử thay đổi thư mục.
These features and Azure Databricks platform improvements were released in May 2026.
Note
Releases are staged. Your Azure Databricks account might not be updated until a week or more after the initial release date.
Databricks Apps horizontal scaling (Beta)
May 29, 2026
You can now run a Databricks app across multiple instances behind a single app URL. Horizontal scaling provides higher availability, zero-downtime deployments, and session affinity, which routes every request from a given user to the same instance so the app can keep per-user data on that instance. Convert an existing standard app to horizontally scaled, or enable horizontal scaling when creating a new app. Converted apps can also opt out of pre-installed Python libraries to run on a clean base OS image.
See Horizontal scaling for Databricks apps and Opt out of pre-installed Python libraries for Databricks apps.
Lakeflow Designer updates for May 29, 2026
May 29, 2026
The following updates were made to Lakeflow Designer:
- Bidirectional AI-generated descriptions: Each operator now displays an AI-generated description of what it does. Editing the description reconfigures the operator.
- N-way Combine: The Combine operator now accepts any number of input tables.
- Custom join conditions: You can now add a custom join condition by clicking the arrow between the left and right tables. Edit the AI-generated description or manually write SQL to configure the condition.
- Improved filter readability: Datetime values in filter conditions now render in plain English instead of ISO format.
- Multi-modal output types: Operators can now render plots, HTML, images, and other non-table outputs directly in the preview pane.
- Configurable output panel: Switch the output panel between input and output (default), input only, or output only. In the combined view, you can now resize the input and output panes.
- Improved drag-to-connect hit target: Drag from an operator's + button to add a connected downstream operator.
- Genie Code change summary: Genie Code now shows a one-line summary of its most recent edit above the input box.
- Better Note placement: New Notes no longer overlap neighboring operators by default.
- Inline parameter examples: SQL and Python operators now surface available parameters with inline sample code showing how to reference them.
- Bug fixes and improvements: Fixed Python operator handling of triple-quoted strings, and a
KeyErrorthrown by the Python preview when an upstream operator was disconnected.
Workspace sidebar navigation updates
May 21, 2026
The workspace sidebar navigation has updated section groupings:
- A new Analytics section groups Dashboards, Genie Spaces, and Alerts.
- The SQL section is renamed to Lakehouse and contains SQL Editor, Queries, Query History, and SQL Warehouses.
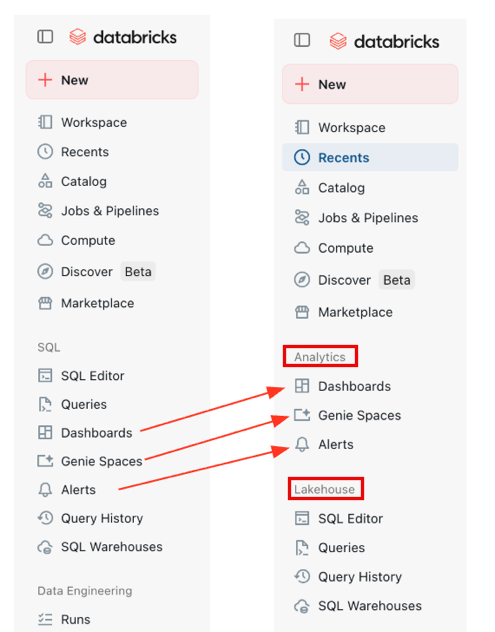
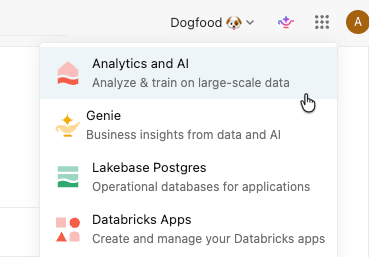
In the app switcher, Lakehouse is also renamed to Analytics and AI.
Anthropic Claude Opus 4.8 now available as a Databricks-hosted model
May 28, 2026
Databricks Model Serving now supports Anthropic Claude Opus 4.8 as a Databricks-hosted model.
To access this model, use:
Cross-engine attribute-based access controls (Beta)
May 28, 2026
External engines can now read Unity Catalog managed tables (Delta and Iceberg) with attribute-based access controls (ABAC), row filters, and column masks enforced server-side. See Cross-engine attribute-based access controls (ABAC).
Real-time mode in Lakeflow Spark Declarative Pipelines, and the update_flow API are now available (Public Preview)
May 27, 2026
Real-time mode in Lakeflow Spark Declarative Pipelines is now in Public Preview. Achieve end-to-end latency as low as five milliseconds for operational streaming workloads such as fraud detection, real-time personalization, and instant decision-making. Real-time mode uses the new update_flow decorator, which writes to sinks using update output mode and supports stateful aggregations without requiring a watermark. See Use real-time mode in Lakeflow Spark Declarative Pipelines and update_flow.
Google Drive managed ingestion connector (Beta)
May 27, 2026
The Google Drive connector in Lakeflow Connect is now available in Beta. The connector allows you to ingest files from Google Drive into Azure Databricks. Both unstructured (binary) and structured (CSV, JSON, XML, Excel, Parquet, Avro, ORC) ingestion are supported, as well as file metadata ingestion. See Google Drive connector.
Workspace admin setting for serverless notebook execution timeout
May 27, 2026
Workspace admins can now set the default execution timeout for serverless notebooks in the workspace admin settings, replacing the previous manual override process. To configure the timeout, go to Settings > Compute and, under Serverless interactive, update the Serverless interactive execution timeout setting.
The default timeout is 2.5 hours, and users can still override the timeout for an individual notebook by using spark.databricks.execution.timeout. See Serverless overspend protection.
Refresh policies and EXPLAIN CREATE MATERIALIZED VIEW for materialized views are now generally available
May 27, 2026
Refresh policies and the EXPLAIN CREATE MATERIALIZED VIEW statement are now generally available for materialized views. Use refresh policies to control when Azure Databricks performs incremental or full refresh, optimizing cost and predictability. Use EXPLAIN CREATE MATERIALIZED VIEW to check whether a query can be incrementalized before defining the materialized view. Available in Databricks SQL and Databricks Runtime 17.3 and above. See Incremental refresh for materialized views.
Removed legacy Assistant slash commands
May 26, 2026
The /settings and /rename slash commands are no longer available in the notebook Genie Code Assistant chat pane. Adjust notebook settings and rename notebooks from the notebook UI instead.
Other slash commands, such as /doc, /explain, /fix, /optimize, and /prettify, are unchanged. See Use slash commands for prompts.
Lakeflow Spark Declarative Pipelines parameters are now in Beta
May 26, 2026
Pipeline parameters let you define key-value pairs at the pipeline level and reference them from SQL source code using named parameter syntax. See Use parameters with pipelines.
Databricks Runtime maintenance updates (05/26)
May 26, 2026
New maintenance updates are available for supported Databricks Runtime versions. These updates include bug fixes, security patches, and performance improvements. For details, see:
- Databricks Runtime 18.2
- Databricks Runtime 18.1
- Databricks Runtime 18.0
- Databricks Runtime 17.3 LTS
- Databricks Runtime 16.4 LTS
- Databricks Runtime 15.4 LTS
- Databricks Runtime 14.3 LTS
- Databricks Runtime 13.3 LTS
Genie Code Agent mode is now available by default for workspaces with the compliance security profile enabled
May 25, 2026
Genie Code Agent mode is now available by default for workspaces with the compliance security profile enabled and HIPAA controls selected.
With Agent mode, Genie Code can automate multiple steps from a single prompt, including retrieving relevant assets, generating and running code, fixing errors automatically, and visualizing results.
See Genie Code.
Databricks Runtime 18 and Databricks Runtime 18 for Machine Learning are in Beta
May 22, 2026
Databricks Runtime 18 and Databricks Runtime 18 for Machine Learning are now in Beta, powered by Apache Spark 4.1.0.
Databricks Runtime 18 is the first release to use a unified release notes format. Previously, each feature version (18.0, 18.1, 18.2) had its own release notes page. Features that would previously have shipped as 18.3 or later now ship as dated updates to Databricks Runtime 18. For more information, see About unified release notes.
Unity Catalog managed Apache Iceberg tables, foreign Apache Iceberg tables, and Apache Iceberg v3 features are generally available
May 21, 2026
The following Apache Iceberg capabilities in Unity Catalog are now generally available:
- Unity Catalog managed Iceberg tables: Create and manage Iceberg tables in Unity Catalog using Databricks Runtime, Databricks SQL, or external Iceberg-compatible engines. Managed Iceberg tables support liquid clustering, predictive optimization, materialized views, and streaming tables. See What is Apache Iceberg in Azure Databricks?.
- Foreign Iceberg tables: Read Iceberg tables managed by external catalogs such as AWS Glue, Hive metastore, or Snowflake Horizon Catalog through Lakehouse Federation. See Work with foreign tables.
- Iceberg v3 features: Use deletion vectors, the VARIANT data type, and row lineage on managed Delta Lake tables with UniForm, managed Iceberg tables, and foreign Iceberg tables. See Use Apache Iceberg v3 features.
Postgres password authentication is now disabled by default for new Lakebase Autoscaling projects
May 21, 2026
New Lakebase Autoscaling projects now have native Postgres password authentication disabled by default. Existing Autoscaling projects are unaffected. To allow native Postgres roles to connect with static passwords, enable password connections in project settings. See Manage password connections.
Databricks CLI is now GA
May 21, 2026
The Databricks CLI is now generally available (GA). As part of this release, the CLI has been updated to store user-to-machine (U2M) tokens in OS-native secure storage. See Token storage.
For information about the Databricks CLI, see Databricks CLI.
Instance events and instance pools system tables are now available (Public Preview)
May 21, 2026
The system.compute.instance_events and system.compute.instance_pools system tables are now in Public Preview. Use these tables to track state transitions of classic compute instances and the full history of instance pool configurations across your account. See Instance events table schema and Instance pools table schema.
Vector Search storage-optimized endpoints are GA
May 20, 2026
Vector Search storage-optimized endpoints are now generally available. Storage-optimized endpoints have a larger capacity (over one billion vectors at dimension 768) and provide 10-20x faster indexing than standard endpoints. Pricing is optimized for the larger number of vectors. For details, see Vector Search endpoint options.
Fixed LOD expression syntax update for metric views
May 20, 2026
Fixed level of detail (LOD) expressions in metric views are now defined directly in the expr field of a dimension using SQL window functions, replacing the previous two-step approach of pre-computing values in the source query. See Use level of detail (LOD) expressions in metric views.
Serve custom LLMs with Custom Model Serving (Beta)
May 20, 2026
You can now serve custom and fine-tuned LLMs on Azure Databricks with a vLLM engine, including multimodal models and PEFT recipes that Foundation Model APIs does not support. Custom LLM Serving is in Beta. See Serve custom LLMs with Custom Model Serving.
Lakebase Autoscaling now supports compute sizes up to 64 CU (128 GB)
May 20, 2026
Lakebase Autoscaling now supports compute sizes up to 64 CU (128 GB RAM), up from the previous maximum of 32 CU (64 GB RAM). Larger workloads can now use dynamic scaling. See Autoscaling.
Authenticate as a service principal using OAuth U2M (Beta)
May 20, 2026
You can now use the OAuth U2M flow to obtain tokens as a service principal's identity instead of your own user account. You must have the Service Principal Manager role on the service principal.
See Authenticate as a service principal using OAuth U2M.
Customer-managed keys now support MLflow managed evaluation features
May 19, 2026
You can now use the following MLflow managed evaluation features in workspaces encrypted with customer-managed keys (CMK):
- Production monitoring of GenAI apps with MLflow 3 scorers.
- The Review App for collecting expert feedback on traces.
- Evaluation datasets. The catalog that stores the dataset must not itself be CMK-encrypted.
Agent Bricks Supervisor Agent now supports nesting supervisor agents as subagent tools
May 19, 2026
You can now add another Supervisor Agent as a subagent tool, enabling nested multi-agent orchestration. See Use Supervisor Agent to create a coordinated multi-agent system.
Databricks Container Services for standard compute is now available (Beta)
May 19, 2026
Databricks Container Services for standard compute is now in Beta. You can now specify a Docker image when creating standard compute on Databricks Runtime 18.3 or later, allowing you to use custom containers in shared compute environments. See Databricks Container Services for standard compute.
Lakeflow Designer updates
May 19, 2026
The following updates were made to Lakeflow Designer:
- Enabled by default: Lakeflow Designer is now enabled by default for all free edition, premium, and enterprise tier workspaces. To get started, click +New in the sidebar and select Visual data prep. If you don't see this option, contact your workspace admin.
- AI operator search: The operator panel now suggests operators based on intent. For example, typing "average by month" surfaces the Aggregate operator.
- Configurable sample size: You can now set the number of sample rows to run with each operator. Each operator remembers its own custom limit.
- Git, import, clone, and export: You can now export, clone, and import visual data prep files using File > Export or File > Clone. Files can also be stored and managed in Git folders.
- User-defined operators (Public Preview): You can now create user-defined operators that appear alongside built-in operators. Use them to extend Lakeflow Designer with your own business logic, calculations, or integrations. Three operator types are supported:
uc-udf,uc-udtf, andpython-run-function. See User-defined operators in Lakeflow Designer. - Bug fixes and improvements: Fixed multiple issues including right-click canvas behavior, undo/redo button state, Markdown node underline formatting, and unconfigured filter condition handling.
Edits to resources in the UI now automatically update YAML
May 19, 2026
Edits to jobs and pipeline settings in the UI now automatically update YAML. See Edit bundle resources.
Azure Databricks Add-in for Excel support for all compliance security profile standards
May 19, 2026
The Azure Databricks Add-in for Excel (Public Preview) now supports all compliance security profile standards supported by Azure Databricks. For more, see Compliance security profile and Connect to Azure Databricks from Microsoft Excel.
Unified runs list is generally available
May 18, 2026
You can now view all of your job and pipeline runs in the updated Runs list. Track all of your pipeline runs in one place and filter by status, time, run-as user, run ID, and error codes in real time. Spot trends using the visualization and summary of the current top five error codes. See View recent runs across all jobs and pipelines.
Recover a deleted Lakebase project within 7 days
May 15, 2026
When you delete a Lakebase project, it now enters a soft-deleted state for 7 days before permanent deletion. You can recover the project during that window, restoring all branches, databases, endpoints, and project settings. See Recover a deleted project.
Share Genie Code chat threads
May 15, 2026
You can now share Genie Code chat threads with other users, groups, or service principals. Recipients receive read-only access to view the shared chat thread. See Share a chat thread.
Agent Bricks Supervisor Agent now supports vector search indexes as subagent tools
May 15, 2026
You can now add vector search indexes as subagent tools in your Supervisor Agent. See Use Supervisor Agent to create a coordinated multi-agent system.
Lakeflow Spark Declarative Pipelines sinks are now generally available
May 15, 2026
The Lakeflow Spark Declarative Pipelines sink API is now generally available. Use sinks with append flows to write transformed pipeline data to external targets, including Delta tables, Apache Kafka topics, Azure Event Hubs, and custom Python data sources. See Using sinks in pipelines.
View run history for scheduled refreshes in Google Sheets
May 14, 2026
You can now view the run history of scheduled refreshes in the Azure Databricks Connector for Google Sheets. Each run shows its Run ID, start time, and success status. See Schedule data refreshes in Google Sheets.
Lakeflow Spark Declarative Pipelines environment versions (Beta)
May 14, 2026
Environment versions for Lakeflow Spark Declarative Pipelines are now in Beta. Configure an environment version on a pipeline to pin the Python language version and set of preinstalled libraries, decoupling your pipeline's Python runtime from Databricks Runtime upgrades. See Configure environment versions for pipelines.
Databricks SQL alerts are now generally available
May 14, 2026
The latest version of Databricks SQL alerts is now generally available. SQL alerts let you monitor data and KPIs by running a query on a schedule, evaluating a condition, and notifying recipients when the condition is met. Use SQL alerts to monitor KPI drifts, detect anomalies, and surface data quality issues. See Databricks SQL alerts.
SQL alert task in Lakeflow Jobs is now in Public Preview
May 14, 2026
The SQL alert task in Lakeflow Jobs, previously in Beta, is now in Public Preview. Use the task to evaluate a Databricks SQL alert as part of a Lakeflow Job. The task returns its evaluation state as a task output value, so downstream tasks can branch on the result. See SQL alert task for jobs.
Publish a Unity Catalog catalog to Microsoft Fabric (Beta)
May 14, 2026
You can now publish a Unity Catalog catalog to Microsoft Fabric from Azure Databricks as a read-only mirrored catalog. Fabric users can query Unity Catalog tables with no data movement. See Publish a Unity Catalog catalog to Microsoft Fabric.
New Lakebase Autoscaling instances now scale to zero by default
May 13, 2026
New Lakebase Autoscaling instances now scale to zero by default after 24 hours of inactivity, reducing compute costs for idle projects. To learn more about scale to zero, see Scale to zero. To configure scale to zero, see Configure scale to zero. To change the scale to zero default for new Lakebase Autoscaling projects, see Compute defaults. This change does not affect existing projects.
ai_parse_document is now available by default for workspaces with the compliance security profile enabled
May 13, 2026
ai_parse_document is now available by default for workspaces with the compliance security profile enabled and HIPAA, HITRUST, C5, and TISAX controls selected.
Use ai_parse_document to parse structured content from unstructured documents including PDFs, images, Word documents, and PowerPoint files.
See ai_parse_document function.
Databricks Runtime maintenance updates (05/13)
May 13, 2026
New maintenance updates are available for supported Databricks Runtime versions. These updates include bug fixes, security patches, and performance improvements. For details, see:
- Databricks Runtime 18.2
- Databricks Runtime 18.1
- Databricks Runtime 18.0
- Databricks Runtime 17.3 LTS
- Databricks Runtime 16.4 LTS
- Databricks Runtime 15.4 LTS
- Databricks Runtime 14.3 LTS
- Databricks Runtime 13.3 LTS
Lakebase Autoscaling: Lakehouse Sync is now in Public Preview
May 12, 2026
Lakehouse Sync is now in Public Preview for Lakebase Autoscaling. Lakehouse Sync enables continuous, low-latency replication of your Lakebase Postgres tables into Unity Catalog managed Delta tables using Change Data Capture (CDC). See Lakebase Change Data Feed.
App telemetry for Databricks Apps is now in Public Preview
May 11, 2026
You can now collect traces, logs, and metrics from your Databricks Apps and persist them to Unity Catalog tables using the OpenTelemetry (OTel) protocol. See Configure telemetry for Databricks Apps.
HIPAA support for the Azure Databricks Add-in for Excel
May 11, 2026
The Azure Databricks Add-in for Excel (Public Preview) is now available for workspaces with HIPAA compliance across all supported regions. See Connect to Azure Databricks from Microsoft Excel.
HubSpot connector (GA)
May 11, 2026
The managed HubSpot connector in Lakeflow Connect is now generally available. The connector allows you to ingest data from HubSpot Marketing Hub into Azure Databricks. See HubSpot connector.
Catalog commits are now generally available
May 8, 2026
Catalog commits are now generally available. Catalog commits expand Unity Catalog managed table interoperability, strengthen Unity Catalog governance capabilities, and unlock new features such as multi-statement, multi-table transactions. When catalog commits are enabled on a Unity Catalog managed Delta table, Unity Catalog becomes the table's system of coordination, brokering access and state across engines. Products that read or write to Unity Catalog managed tables now support catalog commits, including streaming tables, Delta Sharing, Zerobus, Lakeflow Connect, Unity AI Gateway, MLflow, and Lakeflow Jobs triggers. See Catalog commits.
Faster package installs with %uv pip in serverless notebooks
May 7, 2026
You can now use the %uv pip magic command in serverless notebooks on environment version 5 or above as a faster alternative to %pip for Python package management. %uv pip is powered by the uv package manager and shares the same notebook virtual environment as %pip.
See Faster installs with %uv pip.
Standalone pipelines on serverless general compute (Beta)
May 7, 2026
Standalone pipelines, including materialized views and streaming tables, can now be created from a notebook running on serverless general compute. Standalone pipelines (renamed from pipelines on Databricks SQL) can be created using SQL or Python. Standalone pipelines are in Beta. See Requirements for standalone pipelines.
Lakehouse Sync is now available on Azure (Beta)
May 6, 2026
You can now continuously replicate Lakebase Postgres tables into Unity Catalog managed Delta tables using CDC. Lakehouse Sync captures row-level changes and writes them as SCD Type 2 history. No external compute, pipelines, or jobs are required. See Lakebase Change Data Feed.
Block identities from your Azure Databricks account with the account access denylist
May 6, 2026
Use the account access denylist to prevent specific users, groups, or service principals from accessing your Azure Databricks account when automatic identity management is enabled. See Deny identities access to your account.
Outlook managed ingestion connector (Beta)
May 5, 2026
The Outlook connector in Lakeflow Connect is now available in Beta. The connector allows you to ingest email data from Microsoft Outlook into Azure Databricks. See Outlook connector.
Alibaba Cloud Qwen3.5 122B A10B now available as a Databricks-hosted model in Public Preview
May 5, 2026
Model Serving now supports Alibaba Cloud Qwen3.5 122B A10B as a Databricks-hosted model. You can access this model using Foundation Model APIs.
Qwen3.5 122B A10B is available in Public Preview.
Customers are responsible for ensuring their compliance with applicable terms.
AI Runtime 1xH100 accelerator (Beta)
May 5, 2026
AI Runtime now supports the 1xH100 accelerator in Beta. See Hardware options.
GitHub managed ingestion connector (Beta)
May 5, 2026
The GitHub connector in Lakeflow Connect is now available in Beta. The connector allows you to ingest data from GitHub into Azure Databricks. See GitHub connector.
Smartsheet managed ingestion connector (Beta)
May 5, 2026
The Smartsheet connector in Lakeflow Connect is now available in Beta. The connector allows you to ingest data from Smartsheet into Azure Databricks. See Smartsheet connector.
Databricks Runtime 18.2 is now GA
May 4, 2026
Databricks Runtime 18.2 is now generally available. See Databricks Runtime 18.2 and Databricks Runtime 18.2 for Machine Learning.
Lakeflow Pipelines Editor is now generally available
May 4, 2026
The Lakeflow Pipelines Editor is now generally available. The editor offers an agent-first experience with Genie Code for creating, updating, and debugging production pipelines, with your code and Genie Code chat side by side with the pipeline graph and metrics. See Develop and debug ETL pipelines with the Lakeflow Pipelines Editor.
Native data profiling for notebook results tables
May 1, 2026
You can now view profiling statistics for columns in notebook results tables. From a results table, select column headers and click ![]() Open selection details to view profiling statistics. This feature is also available in the new Databricks SQL editor. See Select data.
Open selection details to view profiling statistics. This feature is also available in the new Databricks SQL editor. See Select data.
Community connectors (Beta)
May 1, 2026
Open-source connectors extend Lakeflow Connect to sources without managed connector support. They're built and maintained by the community. Use a registered connector or create your own. See Community connectors in Lakeflow Connect.
Azure UK South now has a dedicated regional control plane
May 1, 2026
Azure UK South now has a dedicated regional control plane in addition to the existing UK West-based control plane. New workspaces created in UK South use the regional control plane and require firewall allowlist entries for the new SCC relay tunnel, Control Plane NAT IPs, Metastore, Log Blob storage, and Event Hubs endpoint. Existing UK South workspaces continue to use the UK West-based control plane and the corresponding UK West values, unless they migrate. See IP addresses and domains for Azure Databricks services and assets.