LitwareHR on SSDS - Part III - Data access enhancements 1: caching
In most applications, the distance (in terms of bandwidth and latency) between the store (the database) and the application logic (like the web servers and web services) is usually very small. The connectivity between these two components is usually very reliable and with very high throughput. But because SSDS is on the other side of the cloud, latency and unreliability of the network could hurt the application performance and availability. Not to mention that in a production application, an ISV will very likely pay for each operation submitted against SSDS in addition to the storage he's using.
For all these reasons it is important to consider technical options that would minimize the degree of "chattiness" of the application (for decreased latency) and the total amount of calls made (for latency & for cost).
With this in mind, it is highly likely your app will have a spectrum of information that it deals with, with different levels of longevity and volatility.
If the data is immutable (e.g. reference information, read only, historic records, etc.) then there is a great chance you can aggressively cache it on the client side to avoid further calls. (Notice that "client side" is a relative term: in LitwareHR, the client side for SSDS is the web services layer).
In LitwareHR, for example, Resumes cannot be modified. Someone can submit multiple resumes, but once it is submitted, it is immutable. A perfect candidate then for caching.
To demonstrate this scenario, we included caching capabilities into LitwareHR's data access that can be enabled either programmatically and/or by configuration:
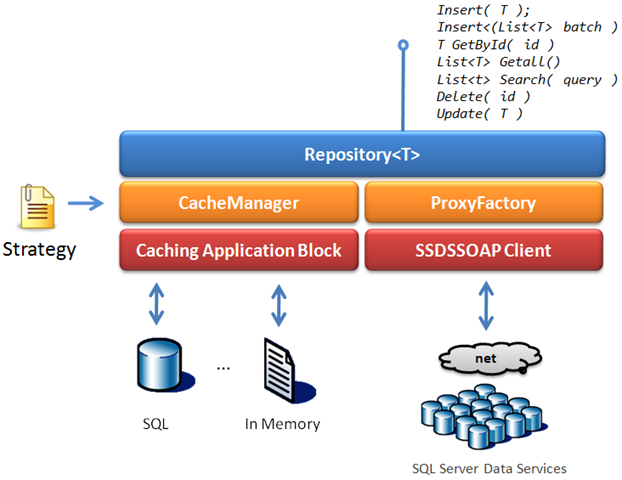
The CacheManager is simply using underneath Enterprise Library's caching block that gives us nice backing store capabilities and some advanced expiration policies.
The Repository will transparently get and store items (entities & full query results). To give the developer extra flexibility and control, entities only marked as "cacheable" (which is done through an interface implementation) are processed with the cache (if one is available). That means of course, that if an entity is not marked as "cacheable", then it will always go against the store, regardless of the existence and availability of a cache.
As an example of how this works, here's a small test. The class Book is an (extensible) entity and is also cacheable.
public class Book : ExtensibleEntity, ICacheableEntity
{
public string Title { set; get; }
public string ISBN { set; get; }
public bool IsCached { set; get;} //This is ICacheableEntity implementation
}
We want to test a Repository for this class and caching behavior:
[TestMethod]
public void ShouldInsertBookGetByIdDelete()
{
using (Repository<Book> rp = new Repository<Book>(tenantId,
new RepositoryCacheManager( "CacheManager",
new SlidingTime( TimeSpan.FromMilliseconds( 3000 )),
true,
false )) )
{
Book bk = new Book { Id = Guid.NewGuid(), Title = "The Aleph", ISBN = "4374834" };
bk.Fields.Add("Author", "J.L.Borges" );
rp.Insert(bk);
Book rbk = rp.GetById(bk.Id);
Assert.IsNotNull(rbk);
Assert.IsTrue(rbk.IsCached);
Assert.AreEqual(bk.Title, rbk.Title);
Assert.AreEqual(bk.Fields["Author"].Value, rbk.Fields["Author"].Value);
Thread.Sleep(3500);
rbk = rp.GetById(bk.Id);
Assert.IsNotNull(rbk);
Assert.IsFalse(rbk.IsCached);
rp.Delete(bk.Id);
Assert.IsNull(rp.GetById(bk.Id));
}
}
Let's see piece by piece how this works:
1- We create a new Repository for Book, using a constructor that takes the tenantid and a CacheManager implementation. This CacheManager takes this arguments:
- The name of the EntLib's cache to use (this translates into the configuration section to use)
- The expiration policy (In the sample, it would be a sliding time of 3 seconds: items in the cache will be invalid after 3 seconds and discarded)
- A boolean for caching entities (true in the example)
- A boolean for caching queries (false in the example)
2- We create a new Book and add some fields, both explicit fields (as defined in the Book class) and an extension field (Author).
3- We insert the Book instance and then retrieve it immediately
4- Because the retrieval (hopefully :-)) will happen before 3 seconds, it should come from the cache (flagged with the IsCached field)
5- We then wait for slightly more than the expiration period (3.5 seconds to be precise) and then retrieve it again. This time, it should come fresh from SSDS, therefore IsCached should be false.
6- We clean up by deleting it
EntLib's underlying implementation has some interesting features we didn't use. For example, you can subscribe to expiration notifications and handle them. You could, for instance, proactively request a a renewal when an item expires proactively keeping your cache up to date.
Comments
Anonymous
March 27, 2008
Eugenio has published the 3rd installment of his article on building the Litware HR application thatAnonymous
April 08, 2008
Dans ce post, Eugenio décrit comment intégrer une couche de persistance dans les nuages (SQLAnonymous
May 06, 2008
More seriously... Eugenio just announced and released on Codeplex the latest drop of LitwareHR. AlthoughAnonymous
May 06, 2008
Microsoft Architecture Strategy Team has just shipped a new version of their LitwareHR Sample ApplicationAnonymous
June 16, 2008
As many of you know, Microsoft has been working on a new version of LitwareHR that uses SQL Server DataAnonymous
June 17, 2008
Zoals een aantal van jullie wellicht weten is Microsoft bezig geweest met een nieuwe versie van LitwareHRAnonymous
October 05, 2008
I have been reading about cloud computing quite a bit.  I found that Microsoft is doing something