Improving interoperability with DOM L3 XPath
As part of our ongoing focus on interoperability with the modern Web, we’ve been working on addressing an interoperability gap by writing an implementation of DOM L3 XPath in the Windows 10 Web platform. Today we’d like to share how we are closing this gap in Project Spartan’s new rendering engine with data from the modern Web.
Some History
Prior to IE’s support for DOM L3 Core and native XML documents in IE9, MSXML provided any XML handling and functionality to the Web as an ActiveX object. In addition to XMLHttpRequest, MSXML supported the XPath language through its own APIs, selectSingleNode and selectNodes. For applications based on and XML documents originating from MSXML, this works just fine. However, this doesn’t follow the W3C standards for interacting with XML documents or exposing XPath.
To accommodate a diversity of browsers, sites and libraries wrap XPath calls to switch to the right implementation. If you search for XPath examples or tutorials, you’ll immediately find results that check for IE-specific code to use MSXML for evaluating the query in a non-interoperable way:
In our new rendering engine, the script engine executes modern Web content, so a plugin-free, native implementation of XPath is required.
Evaluating the Options
We immediately began to cost the work to implement the entire feature. Our options included starting from scratch, integrating MSXML, or porting System.XML, but each of these was too costly for its own reasons. We decided to start implementing a subset of XPath while working on the full implementation at the same time.
In order to know what subset of the standard to support, we used an internal crawler that captured the queries used across hundreds of thousands of the most popular sites on the Web. We found buckets of queries that had the form
- //element1/element2/element3
- //element[@attribute="value"]
- .//*[contains(concat(" ", @class, " "), " classname ")]
Each of these queries maps cleanly to a CSS Selector that could return the same results that would be returned from our performant Selectors API. Specifically, the queries above can be converted to
- element1 > element2 > element3
- element[attribute="value"]
- *.classname
The first native implementation of XPath thus involved supporting queries that can be converted to a CSS selector and exposing the results through the DOM L3 XPath interface objects. Alongside this implementation, we added telemetry to measure the rate of success across broader Web usage, which accounted for the number of successful queries, number of failed queries, and the query string of the first failure.
Our telemetry from internal testing showed that 94% of queries successfully converted to selectors to unblock many Web sites. Of the failures reported through the telemetry, many took the form
- //element[contains(@class, "className")]
- //element[contains(concat(" ", normalize-space(@class), " "), " className ")]
which can both be converted to the selector “element.className.” With these additional changes, the success rate improved to 97%, making our new engine ready for broader usage to support the modern Web.
 |
| Internal telemetry showing Xpath query success rates |
Addressing the Remainder
While this supports the vast majority of the Web, converting XPath queries to Selectors is inherently limited. Additionally, we were still left with the 3% of failing queries that require support of more of XPath’s grammar, such as functions, support for non-element and document nodes, and more complex predicates. Several sites mention various polyfills for XPath, including Mozilla Development Network, for platforms that do not provide adequate support for XPath. One of the polyfills commonly cited is wicked-good-xpath (WGX), which is an implementation of XPath written purely in JavaScript. Running WGX against our internal set of tests across the XPath spec showed 91% compatibility with competitor native implementations. The idea of using WGX as a fallback for the remaining 3% became a compelling bet because it was performant and our tests already measured its functionality against other implementations. Further, wicked-good-xpath is an open source project under the MIT license, and our usage of it would align with our goals to embrace and contribute back to code from the open source community. However, JavaScript had never been used within IE to build this kind of platform feature before.
In order to support WGX without polluting a Web page’s context, we created a separate, isolated script engine dedicated to WGX. With a few modifications to WGX that provide entry points for invoking functions and accessing results, we marshal the data from the page to the isolated engine and evaluate expressions with WGX. With WGX enabled to handle native XPath queries, we see immediate gains from sites missing content in our new engine rendering the modern Web.
 |
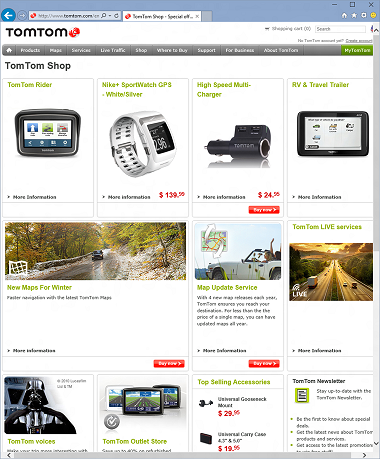 |
Before and after: Available prices for products now appear correctly on tomtom.com |
|
 |
 |
Before and after: Lottery numbers now correctly display where they were previously missing |
|
While browsing the Web with WGX, we found a few bugs that exhibit behavior which diverges from other browsers’ implementations as well as the W3C spec. We plan to make contributions back to the project that make WGX more interoperable with native implementations.
Our new rendering engine now has support for XPath to run the modern Web to enable more functionality and show more content for our customers. With data-driven development from the modern Web, we landed on a data-driven outcome of a low-cost and performant implementation on existing technologies and standards as well as open source code. Grab the latest flight of the Windows 10 Technical Preview to try for yourself! You can reach us with feedback via the Internet Explorer Platform Suggestion Box on UserVoice, @IEDevChat on Twitter, and in the comments below.
– Thomas Moore, Software Engineer, Internet Explorer Platform
Comments
Anonymous
March 19, 2015
How long do you expect it will take to implement fully?Anonymous
March 19, 2015
Sadly I wished you had gone with option 3 - implement System.Xml ... Anyway it's your browser and its your codebase, not much say us outsiders can have .. unless ofcourse it was opensourced, which it isn't .. sigh ...Anonymous
March 19, 2015
The comment has been removedAnonymous
March 19, 2015
Really? This is how you're deciding to implement XPath natively in the browser? By converting XPath expressions to CSS selectors? For many of us waiting years and years for Microsoft to finally have a real, built-in XPath implementation so that we can query the builtin, visual DOM, this profoundly disappointing. Why not System.Xml. Or, geez, just do what everyone else does and use libxml2? It would be interesting to hear why these approaches were "too costly for [their] own reasons". Even with the modern Chakra engine, wgx is just not going to perform the same as native code on what you consider to be outlier expressions. Unfortunately, for some us trying to serve corporate customers, I have a feeling that your outlier expressions are what we use every day:
- predicate expressions containing 'namespace-uri()' and other "more obscure" operations around namespaces (yes, XHTML5 is alive and well, thank you)
- path expressions containing arithmetic operators
- path expressions containing parent ('..') location steps
- path expressions containing nested predicates There are a host of others. If I had wanted to use XPath expressions that could be more or less easily translated into CSS selectors, I would've just used... CSS selectors. For the more complex ones, I would've just used wgx myself. As I've tried to explain to the folks at Google many times, there are literally millions of web pages that you're never going to find by doing 'telemetry' out on the wider web. Because they're behind a corporate firewall and you'll never see them. So doing 'telemetry' to drive your use cases is useless - please stop. This is more true for Microsoft than Google, in that Microsoft serves the enterprise customer much, much more. This makes me much less interested in moving forward with any projects involving Project Spartan. How very disappointing.
- Bill
Anonymous
March 19, 2015
The comment has been removedAnonymous
March 19, 2015
The implementation has two parts. XPath that can be readily converted to CSS gets that treatment. XPath that can't goes the JS path, which is actually quite zippy itself. Both together, plus bug fixes, is quite solid. And WGX is very economical.Anonymous
March 19, 2015
I agree completely with Bill (William Edney). This is very disappointing to hear. Just because you scour the internet for a "representative sample" of what is used has no real bearing on what is used on private intranets everyday! I do hope this is not the ongoing mentality for your team?Anonymous
March 20, 2015
The comment has been removedAnonymous
March 20, 2015
The comment has been removedAnonymous
March 20, 2015
"We decided to start implementing a subset of XPath while working on the full implementation at the same time" So the full, non polyfill implementation is still happening, for all you 'disappointed' folks...Anonymous
March 20, 2015
Very clever solution IMO. Good example of true engineer's thinking. I've translated this article to Russian, habrahabr.ru/.../253595Anonymous
March 20, 2015
@SnarkMaiden - I read that sentence too, but I didn't come away with the same impression as you. If this is indeed a temporary step, and Microsoft plans on implementing the full XPath (at least 1.0) spec, in a way which is as performant as other browser platforms (which leverage C-based libraries), then of course my comments above no longer apply and I will retract them.
- Bill
Anonymous
March 20, 2015
@NumbStill .... Spartan / EdgeHTML.dll / Chakra.dll <== this is meant to be the modern x-plat (in windows) web stack, this will be with us for the next decade ... Take no shortcuts when implementing features, have a single library across ALL of modern windows for XML .. If that's System.XML then so be it ... BUT implement that and use it everywhere across MS ... .... grrr... shakes fist at the decision makers within MSAnonymous
March 22, 2015
I believe System.Xml cannot be used as a single library, because it is .NET and not native code (Internet Explorer is native code), so that is out of the picture. Do you have other solutions (beside MSXML, apparently, because they would have used it if it fit)? Keep in mind that you need to plug XPath into different document model objects, whether it is the XML DOM, SVG DOM, HTML DOM or whatever, across all of the operating system (as you suggest). This makes the implementation unoptimized for the specific case and optimized for the general case, which is probably not good enough for every case. Anyway, we are really speculating here. If it were that important, I am sure they would have implemented it natively.Anonymous
April 02, 2015
Because Google Code is shutting down, I just moved the project to GitHub: github.com/.../wicked-good-xpath Happy to know our project was helpful!