What is contextualization in Azure IoT Data Processor Preview?
Important
Azure IoT Operations Preview – enabled by Azure Arc is currently in PREVIEW. You shouldn't use this preview software in production environments.
See the Supplemental Terms of Use for Microsoft Azure Previews for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability.
Contextualization adds information to messages in a pipeline. Contextualization can:
- Enhance the value, meaning, and insights derived from the data flowing through the pipeline.
- Enrich your source data to make it more understandable and meaningful.
- Make it easier to interpret your data and facilitates more accurate and effective decision making.
For example, the temperature sensor in your factory sends a data point that reads 250 °F. Without contextualization, it's hard to derive any meaning from this data. However, if you add context such as "The temperature of the oven asset during the morning shift was 250 °F," the value of the data increases significantly as you can now derive useful insights from it.
Contextualized data provides a more comprehensive picture of the operations, helping you make more informed decisions. The contextual information enriches the data making data analysis easier. It helps you optimize processes, enhance efficiency, and reduce downtime.
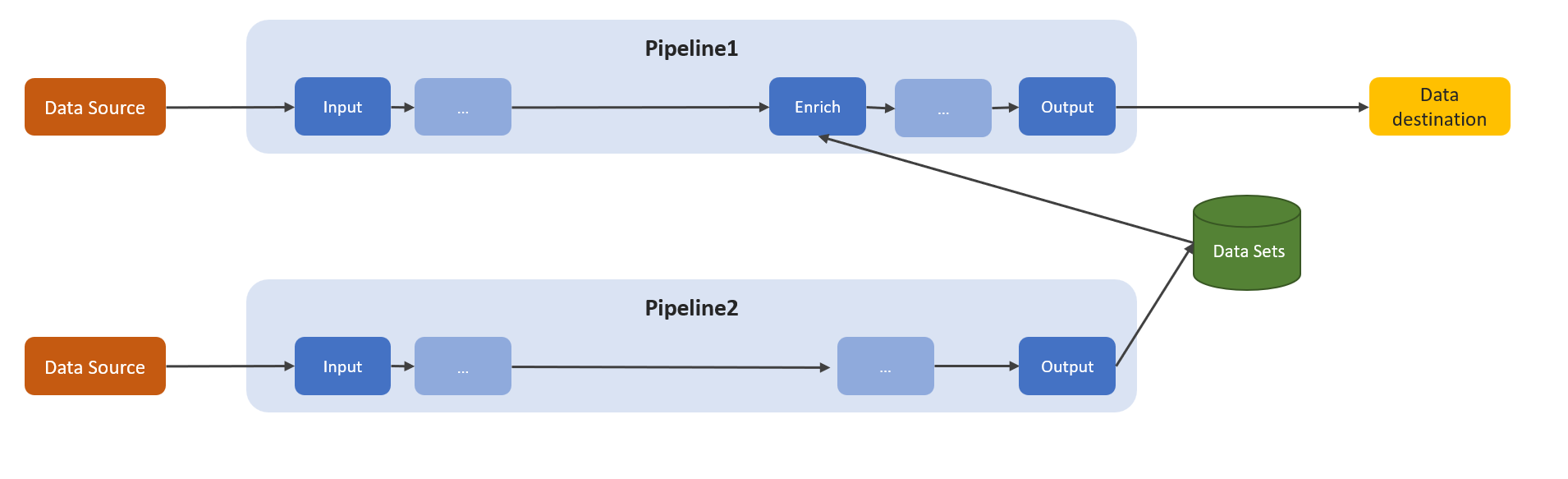
Message enrichment
An Azure IoT Data Processor Preview pipeline contextualizes data by enriching the messages that flow through the pipeline with previously stored reference data. Contextualization uses the built-in reference data store. You can break the process of using the reference data store within a pipeline into three steps:
Create and configure a dataset. This step creates and configures your datasets within the reference data store. The configuration includes the keys to use for joins and the reference data expiration policies.
Ingest your reference data. After you configure your datasets, the next step is to ingest data into the reference data store. Use the output stage of the reference data pipeline to feed data into your datasets.
Enrich your data. In an enrich stage, use the data stored in the reference data store to enrich the data passing through the Data Processor pipeline. This process enhances the value and relevance of the data, providing you with richer insights and improved data analysis capabilities.
Related content
Phản hồi
Sắp ra mắt: Trong năm 2024, chúng tôi sẽ dần gỡ bỏ Sự cố với GitHub dưới dạng cơ chế phản hồi cho nội dung và thay thế bằng hệ thống phản hồi mới. Để biết thêm thông tin, hãy xem: https://aka.ms/ContentUserFeedback.
Gửi và xem ý kiến phản hồi dành cho