Hệ thống xử lý luồng
- 11 phút
Các khuôn khổ mà chúng tôi đã xem xét cho đến nay (MapReduce, Spark, GraphLab) đã được thiết kế chủ yếu để thực hiện hàng loạt tính toán. Đầu vào của chúng thường là các tập dữ liệu phân tán lớn, được xử lý trong vài giờ để tạo ra một đầu ra lớn, hữu ích. Việc sử dụng các khuôn khổ này ban đầu bị hạn chế đối với các nhà khoa học và lập trình viên dữ liệu, những người sử dụng chúng cho các truy vấn cụ thể, lớn, nơi độ trễ cao này có thể chấp nhận được. Tuy nhiên, khi việc sử dụng dữ liệu lớn trở nên phổ biến trong các doanh nghiệp, có một sự chuyển dịch sang truy vấn dữ liệu đặc biệt, với độ trễ dự kiến là phút, không phải giờ. Các công cụ như Pig, Hive, Shark và Spark SQL cho phép nhiều doanh nghiệp đặt ra những câu hỏi phức tạp về dữ liệu của họ mà không cần dựa vào một nhóm lớn các lập trình viên được đào tạo chuyên nghiệp. Đám mây đã thúc đẩy việc áp dụng này thêm nữa, cung cấp một nguồn cung cấp linh hoạt các tài nguyên điện toán trong suốt thời gian truy vấn đặc biệt.
Sớm, sự mong đợi của latencies thậm chí còn thấp hơn. Dữ liệu lớn bắt đầu được nhận trong thời gian thực và thường chỉ có giá trị trong một khoảng thời gian ngắn. Ví dụ: công cụ tìm kiếm yêu cầu kết hợp quảng cáo tốt nhất trong vòng mili giây cho mỗi truy vấn; các trang web truyền thông xã hội đã phát hiện các xu hướng và chủ đề xu hướng và thẻ băm, đồng thời các công cụ giám sát hệ thống đã phát hiện các mẫu hình phức tạp trên một số thành phần cơ sở hạ tầng lớn. Để có thể cung cấp độ trễ thấp như vậy, một lớp khung xử lý luồng mới bắt đầu hình thành. Chúng có các yêu cầu và ràng buộc về cơ bản khác với các hệ thống xử lý tương tác và lô của quá khứ.
Điều này dẫn đến sự ra đời của hệ thống xử lý dòng.
Xử lý luồng
Mô hình xử lý dòng áp dụng một chuỗi các thao tác trên mỗi phần tử dữ liệu được phát ra bởi một nguồn dữ liệu đầu vào dài vô hạn. Chuỗi các thao tác thường có đường ống dẫn, làm tăng thêm sự phụ thuộc giữa các thao tác. Trong ứng dụng xử lý, thông tin trạng thái thường được đọc và ghi vào một nguồn dữ liệu nhỏ, nhanh chóng. Đầu ra của một quy trình hoạt động luồng cũng là một luồng dữ liệu. Điều này có thể được sử dụng để kích hoạt các ứng dụng khác, hoặc được đệm và lưu trữ để lưu trữ ổn định. Kiến trúc khái niệm cơ bản của một hệ thống như vậy được thể hiện dưới đây.
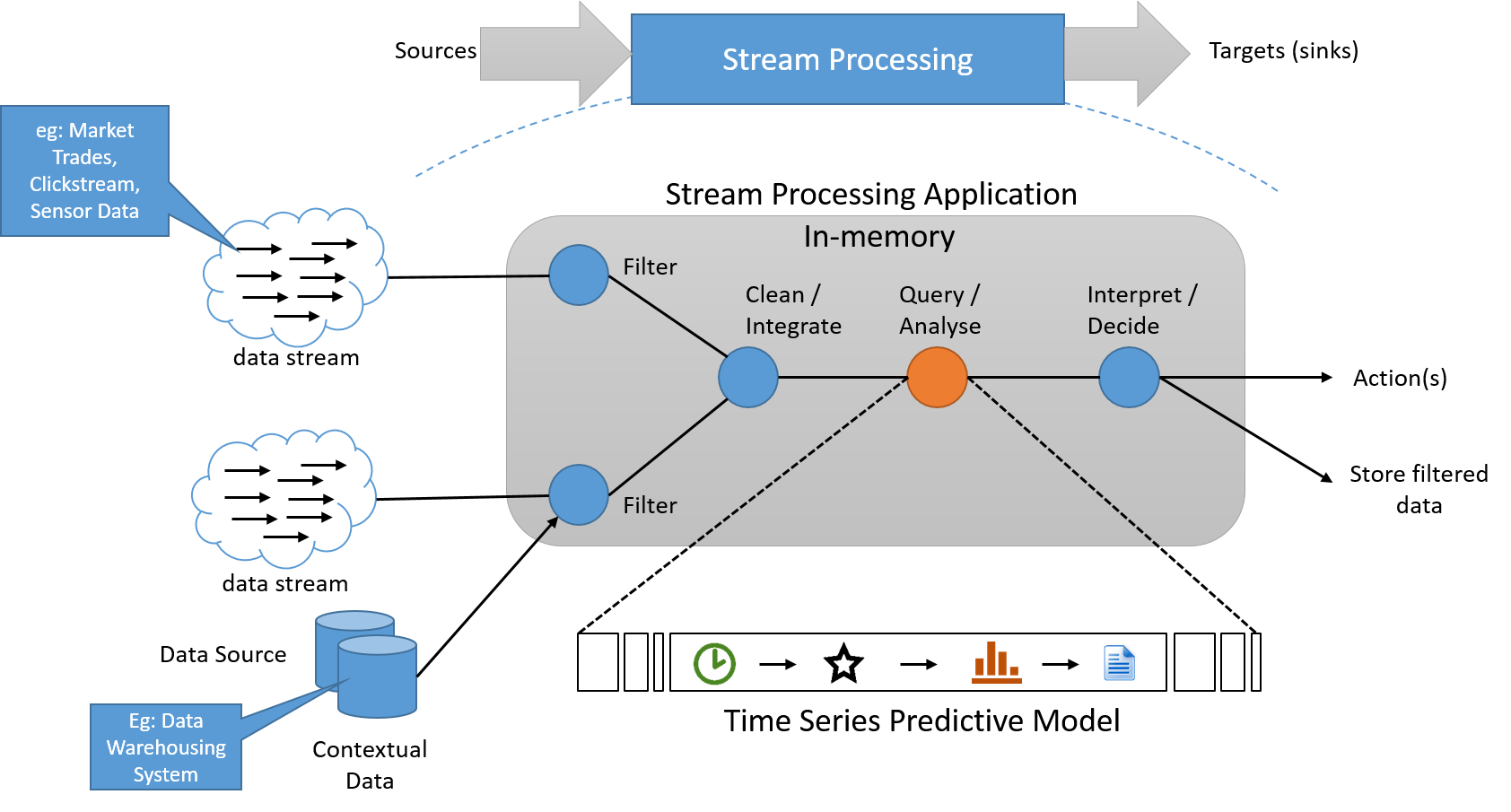
Hình 6: Hệ thống xử lý luồng phải xử lý dữ liệu trong luồng, với một đường ống dẫn riêng biệt để lưu trữ, nếu cần, không nằm trên "đường dẫn quan trọng"
Tám quy tắc để xử lý luồng
Stonebraker et. Al. mô tả tám quy tắc cơ bản cho các hệ thống xử lý luồng.
Quy tắc 1: Giữ cho dữ liệu di chuyển
Một khung xử lý dòng thời gian thực phải có khả năng xử lý thư "trong dòng" mà không cần phải lưu trữ chúng trên đĩa, điều này thêm độ trễ không thể chấp nhận được trên đường dẫn quan trọng. Ngoài ra, các hệ thống này nên được hoạt động (sự kiện hướng) và không thụ động (theo đó các ứng dụng cần phải thăm dò ý kiến kết quả để phát hiện các điều kiện quan tâm).
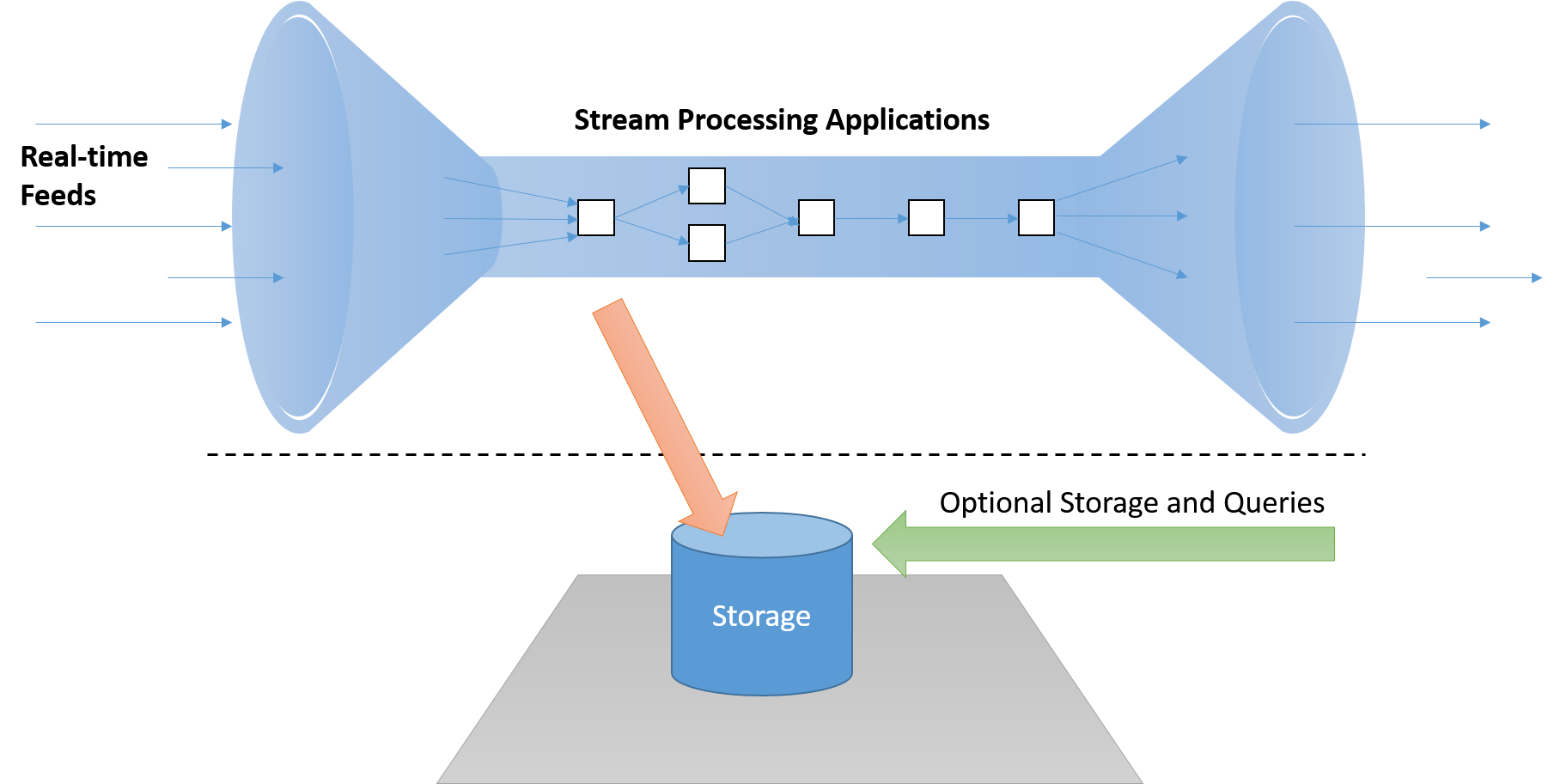
Hình 7: Hệ thống xử lý luồng phải xử lý dữ liệu trong luồng, với một đường ống dẫn riêng biệt để lưu trữ, nếu cần, không nằm trên "đường dẫn quan trọng"
Quy tắc 2: Luồng nên hỗ trợ truy vấn bằng SQL
SQL nổi lên như một tiêu chuẩn quen thuộc và được sử dụng rộng rãi để truy vấn dữ liệu. Tuy nhiên, SQL truyền thống hoạt động trên một lượng dữ liệu cố định, theo đó đến cuối bảng sẽ cho biết truy vấn đã hoàn tất. Trong trường hợp phát trực tuyến, dữ liệu tăng liên tục. Stonebraker et. Al. nhận thức được nhu cầu về một ngôn ngữ StreamSQL, với các cửa sổ trượt dựa trên thời gian biến đổi xác định phạm vi của một truy vấn. Windows có thể được định nghĩa bằng cách sử dụng thời gian, số lượng thông báo hoặc bất kỳ tham số tùy ý nào. Các toán tử bổ sung có thể cần thiết để phối thư từ nhiều dòng.
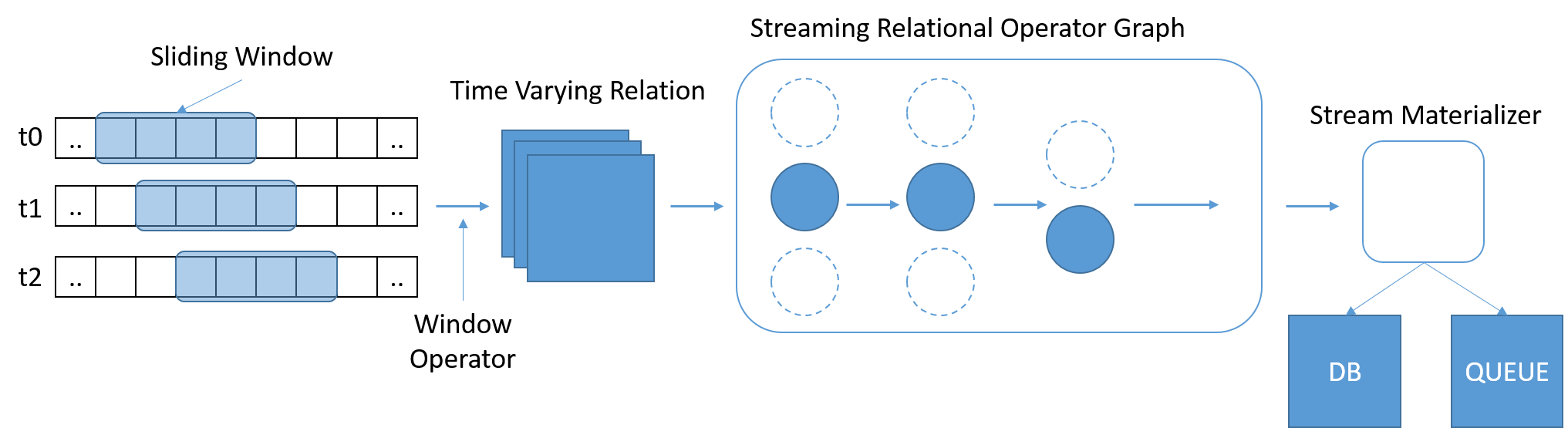
Hình 8: StreamSQL nên xử lý các tập hợp con của dữ liệu và cho phép các mối quan hệ được thể hiện qua các cửa sổ
Quy tắc 3: Xử lý các khi không hoàn chỉnh luồng
Trong các hệ thống thời gian thực, dữ liệu có thể bị mất, đến muộn hoặc đến không theo thứ tự. Hệ thống xử lý dòng không thể chờ vô hạn cho dữ liệu, nhưng cũng có thể không có tính linh hoạt để bỏ qua hoặc bỏ lỡ bất kỳ dữ liệu nào. Các hệ thống như vậy phải kiên cường chống lại các khi không hoàn chỉnh luồng, với các cơ chế như thời gian chờ có thể đặt cấu hình và "thời gian chậm trễ", trong thời gian đó có thể được chấp nhận đến muộn.
Quy tắc 4: Tạo ra các kết quả có thể dự đoán
Kết quả của bất kỳ hệ thống xử lý luồng nào phải được xác định và có thể lặp lại bằng cách phát lại luồng. Điều này đặc biệt khó khăn khi hệ thống đang hoạt động trên nhiều dòng đồng thời hoặc khi thư đến không theo thứ tự. Thư phải được sản xuất theo thứ tự thời gian tăng dần, bất kể thời gian đến của họ. Thuộc tính này cũng cho phép dung sai lỗi, bằng cách làm cho nó hợp lý để phát lại dòng khi xử lý không thành công.
Quy tắc 5: Tích hợp trạng thái đã lưu trữ
Các ứng dụng xử lý luồng thường phải kết hợp hiện tại với quá khứ. Ví dụ: khi đề xuất quảng cáo cho người dùng, công cụ tìm kiếm phải kết hợp thông tin hiện tại về cụm từ tìm kiếm và trạng thái hiện tại của thị trường quảng cáo, với thông tin trước đây về thói quen nhấp chuột của người dùng. Tích hợp trạng thái được lưu trữ và dữ liệu phát trực tuyến cũng cho phép chuyển đổi liền mạch, theo đó thuật toán có thể được kiểm tra trên dữ liệu lịch sử và sau đó chuyển sang luồng trực tiếp khi nó hoạt động thỏa đáng. Dữ liệu phải được lưu trữ trong cùng một không gian địa chỉ hệ thống như ứng dụng, có thể sử dụng cơ sở dữ liệu được nhúng, để cho phép sử dụng ngôn ngữ thống nhất xử lý dữ liệu được lưu trữ và phát trực tuyến.
Quy tắc 6: Đảm bảo tính khả dụng cao
Hệ thống xử lý luồng hoạt động theo thời gian thực và thường không thể chịu đựng được việc khôi phục khởi động lại. Những hệ thống này phải cho phép chuyển đổi nóng sang một bản sao lưu hoặc bóng đổ, mà phải được đồng bộ hóa thường xuyên với chính. Tính toàn vẹn của dữ liệu phải được đảm bảo, phù hợp với quy tắc 4.
Quy tắc 7: Hỗ trợ phân vùng và tự động xác định tỷ lệ
Xử lý phân phối là mô hình hoạt động tiêu chuẩn cho tất cả các hệ thống lớn như vậy. Kiến trúc xử lý luồng tốt nên không chặn và khai thác kiến trúc đa luồng hiện đại. Hơn nữa, nó sẽ có thể tự xử lý việc xác định tỷ lệ ra hoặc trong hệ thống bằng cách thêm hoặc loại bỏ các máy, dựa trên khối lượng dữ liệu tăng hoặc giảm hoặc dựa trên việc xử lý sự chậm trễ hoặc phức tạp. Ngoài ra, nó phải tự động và minh bạch thực hiện cân bằng tải trên các máy có sẵn. Người dùng cuối không cần phải xử lý bất kỳ sự phức tạp nào trong số này.
Quy tắc 8: Đảm bảo thiết bị có thể cập nhật
Tất cả các cấu phần hệ thống nên được thiết kế để có hiệu suất cao, với một số lượng tối thiểu các hoạt động diễn ra ngoài lõi. Hệ thống phải được kiểm tra và đánh giá chuẩn dựa trên khối lượng công việc mục tiêu và mục tiêu lưu lượng và độ trễ phải được xác thực.
Sự phát triển của các công cụ xử lý dòng
Cực quang (2002) là một trong những hệ thống xử lý dòng suối sớm nhất, cũng được phát triển bởi Stonebraker và cộng sự tại Đại học MIT và Brown. Aurora xử lý các vấn đề xử lý dòng như là một đồ thị hướng dẫn acyclic (DAG).
Đầu vào luồng là một chuỗi các bộ không liên kết (1,2, ...,n) theo thời gian, dòng từ ngược dòng (bắt đầu) đến hạ lưu (đầu ra). Có thể xây dựng toàn bộ ứng dụng bằng cách thêm các kết hợp khác nhau của các hộp xử lý và nối kết vẽ giữa chúng. Aurora là một hệ thống đơn nút, thiếu nhiều yêu cầu về khả năng mở rộng của một công cụ xử lý dòng. Một phiên bản mới của Aurora tên là Aurora* (2003) đã được tạo ra để kết hợp nhiều nút Aurora qua mạng. Vì vậy, khả năng mở rộng đã đạt được bằng cách phân vùng các giai đoạn khác nhau của công việc xử lý dòng trên các nút vật lý khác nhau. Cuối cùng, dự án Medusa (2003) đã thêm hỗ trợ liên kết cho Aurora, cho phép nhiều người dùng cộng tác và chia sẻ.
Borealis (2005) là phần mở rộng tiếp theo của dự án Aurora, bổ sung hỗ trợ cho tính khả dụng cao bằng cách sử dụng sao chép hoạt động. Các bản sao đã được đồng bộ hóa cẩn thận để cung cấp tính nhất quán của dữ liệu.
Apache Storm (2011) là một công cụ xử lý luồng phát triển bởi X. Ở đây, các nút xử lý (Bolts) có thể đăng ký dòng từ các nguồn khác nhau (Spouts), do đó cho phép một mô hình thuê bao đơn giản của tính toán. Storm cung cấp khả năng xử lý tin nhắn được đảm bảo, bất kể lỗi nút và cho phép ngữ nghĩa chính xác một lần để đảm bảo rằng dữ liệu không bị đếm dưới hay quá mức. Apache S4 (2011) là một hệ thống đăng ký tương tự được phát triển tại Yahoo!. Nó là đối xứng, theo nghĩa là tất cả các nút đều bình đẳng và không có điều khiển tập trung, với hy vọng làm cho nó có thể mở rộng. S4 không hỗ trợ tự động thêm hoặc loại bỏ các nút vào và ra khỏi cụm đang chạy. Apache Samza (2013) là một hệ thống đa thuê bao trong khuôn này mà chúng tôi sẽ khám phá chi tiết hơn.
Storm, Samza và S4 tuân theo mô hình phát trực tuyến truyền thống, được gọi là xử lý bản ghi tại một thời điểm. Trong mô hình này, các toán tử trạng thái xử lý bản ghi đến, sử dụng dữ liệu mới để sửa đổi trạng thái nội bộ và sau đó phát ra các bản ghi mới. Lỗi khoan dung và phục hồi được thực hiện bằng cách sao chép, hoặc bằng cách làm cho nhiều bản sao của các yếu tố xử lý hoặc bằng cách đệm và lưu trữ các bản sao lưu của tin nhắn ngược dòng, và gửi lại chúng downstream, trong trường hợp không thành công. Ngoài ra, khi bố trí của DAG phát triển phức tạp hơn, thật khó để đảm bảo tính nhất quán trên các đường dẫn khác nhau. Cuối cùng, việc kết hợp các khuôn khổ này với hệ thống hàng loạt là không tầm thường và thường được thực hiện bằng cách sử dụng kiến trúc Lambda (được thảo luận sau này).
Một cách tiếp cận khác để thiết kế hệ thống xử lý luồng được cung cấp bởi Spark Streaming (2012), cung cấp "vi phân lô". Phân lô vi chuyển đổi tính toán luồng thành một tập hợp các tính toán cực kỳ nhanh, với độ trễ từ hàng trăm mili giây đến vài giây. Với chi phí tăng độ trễ, điều này làm cho nó dễ dàng hơn để cung cấp khả năng chịu lỗi và ngữ pháp chính xác một lần trên kết quả của mỗi micro-batch.
Chọn khuôn khổ chính xác để sử dụng cho một nhiệm vụ là một yếu tố của độ trễ dự kiến, khả năng chịu lỗi, và bảo đảm chuyển phát tin nhắn, cũng như kỹ năng của người dùng và chi phí phát triển mong muốn. Trong đơn vị tiếp theo, chúng ta sẽ khám phá nội bộ của các khuôn khổ này chi tiết hơn, bằng cách nghiên cứu Apache Samza.
Kiểm tra kiến thức của bạn
Phản hồi
Trang này có hữu ích không?
Không
Cần trợ giúp về chủ đề này?
Bạn muốn thử sử dụng Ask Learn để làm rõ hoặc hướng dẫn bạn về chủ đề này?