Xác định kế hoạch truy vấn có vấn đề
Các CSDL cách tiếp cận điển hình thực hiện để khắc phục sự cố hiệu suất truy vấn liên quan đến việc xác định truy vấn có vấn đề trước tiên, thường là truy vấn tiêu thụ nhiều tài nguyên hệ thống nhất, sau đó truy xuất kế hoạch thực thi của nó. Có hai kịch bản chính. Một kịch bản là truy vấn thực hiện một cách nhất quán kém. Điều này có thể do các vấn đề khác nhau, chẳng hạn như ràng buộc tài nguyên phần cứng (mặc dù điều này thường không ảnh hưởng đến một truy vấn đơn chạy riêng lẻ), cấu trúc truy vấn tối ưu phụ, thiết đặt tương thích với cơ sở dữ liệu, thiếu chỉ mục hoặc lựa chọn kế hoạch kém của trình tối ưu hóa truy vấn. Kịch bản thứ hai là truy vấn thực hiện tốt trong một số thực thi nhưng kém ở những người khác. Sự không nhất quán này có thể là do các yếu tố như dữ liệu lệch trong truy vấn được tham số hóa, có kế hoạch hiệu quả cho một số thực thi và một kế hoạch thực thi kém cho những người khác. Các yếu tố phổ biến khác bao gồm chặn, trong đó truy vấn chờ một truy vấn khác hoàn tất để có quyền truy nhập vào bảng hoặc cạnh nhau về phần cứng.
Hãy khám phá từng kịch bản trong số này chi tiết hơn.
Ràng buộc phần cứng
Ràng buộc phần cứng thường không kê khai trong khi thực thi truy vấn đơn nhưng trở nên rõ ràng khi tải sản xuất khi luồng CPU và bộ nhớ bị giới hạn. Cpu contention có thể được phát hiện bằng cách quan sát bộ đếm hiệu suất màn hình '% xử lý thời gian', đo lường mức sử dụng CPU máy chủ. Trong SQL Server, loại SOS_SCHEDULER_YIELDvà CXPACKET có thể cho biết áp lực CPU. Hiệu suất hệ thống lưu trữ kém có thể làm chậm thậm chí thực thi truy vấn đơn được tối ưu hóa. Hiệu suất lưu trữ được theo dõi tốt nhất ở cấp Disk Seconds/ReadDisk Seconds/Writeđộ hệ điều hành bằng cách sử dụng các bộ đếm giám sát hiệu suất và đo thời gian hoàn thành thao tác I/O. SQL Server ghi lại hiệu suất lưu trữ kém nếu I/O mất nhiều hơn 15 giây. Việc chờ PAGEIOLATCH_SH cao trong SQL Server có thể cho biết các sự cố về hiệu suất lưu trữ. Hiệu suất phần cứng thường được đánh giá sớm trong quá trình khắc phục sự cố do dễ dàng đánh giá.
Hầu hết các vấn đề về hiệu suất cơ sở dữ liệu đều bắt nguồn từ các mẫu truy vấn tối ưu phụ, có thể gây áp lực quá mức lên phần cứng. Ví dụ: thiếu chỉ mục có thể dẫn đến áp lực cpu, bộ nhớ và bộ nhớ bằng cách truy xuất nhiều dữ liệu hơn mức cần thiết. Chúng tôi khuyên bạn nên giải quyết và tinh chỉnh các truy vấn tùy chỉnh phụ trước khi giải quyết sự cố phần cứng. Tiếp theo, chúng ta sẽ xem điều chỉnh truy vấn.
Cấu trúc truy vấn tùy chỉnh phụ
Các cơ sở dữ liệu quan hệ hoạt động tốt nhất khi thực hiện các thao tác dựa trên tập hợp, thao tác với dữ liệu (INSERT, UPDATE, và DELETESELECT) trong tập hợp, tạo ra một giá trị đơn lẻ hoặc một tập kết quả. Giải pháp thay thế là xử lý dựa trên hàng, sử dụng con trỏ hoặc trong khi vòng lặp, làm tăng chi phí tuyến tính với số hàng bị ảnh hưởng- quy mô có vấn đề khi khối lượng dữ liệu tăng lên.
Phát hiện việc sử dụng các phép toán dựa trên hàng với con trỏ hoặc vòng WHILE rất quan trọng, nhưng có các kiểu chống SQL Server khác để nhận dạng. Các hàm có giá trị bảng (TVFs), đặc biệt là TVFs đa tuyên bố, gây ra các mẫu kế hoạch thực thi có vấn đề trước SQL Server 2017. Nhà phát triển thường sử dụng TVFs nhiều câu lệnh để thực thi nhiều truy vấn trong một hàm duy nhất và tổng hợp kết quả thành một bảng duy nhất. Tuy nhiên, việc sử dụng TVFs có thể dẫn đến các hình phạt về hiệu suất.
SQL Server có hai loại TVFs: nội tuyến và đa câu lệnh. TVFs nội tuyến được coi như các chế độ xem, trong khi TVFs nhiều câu lệnh được coi như bảng trong quá trình xử lý truy vấn. Vì TVFs là động và thiếu thống kê, SQL Server sử dụng số hàng cố định để ước tính chi phí kế hoạch truy vấn. Điều này có thể phù hợp với số lượng hàng nhỏ nhưng không hiệu dụng với hàng nghìn hoặc hàng triệu hàng.
Một kiểu chống khác là việc sử dụng các hàm vô hướng, có các vấn đề thực thi và ước tính tương tự. Microsoft đã thực hiện những cải tiến hiệu suất đáng kể với Xử lý Truy vấn Thông minh, trong mức độ tương thích 140 và 150.
Khả năng SARGability
Thuật ngữ SARGable trong cơ sở dữ liệu quan hệ tham chiếu đến một vị từ (WHERE mệnh đề) được định dạng để sử dụng chỉ mục để tăng tốc độ thực thi truy vấn. Các vị từ trong định dạng đúng được gọi là 'Đối số Tìm kiếm' hoặc SARG. Trong SQL Server, sử dụng SARG có nghĩa là trình tối ưu hóa định trị bằng cách sử dụng chỉ mục không bao gồm trên cột được tham chiếu trong SARG cho thao tác SEEK , thay vì quét toàn bộ chỉ mục hoặc bảng để truy xuất giá trị.
Sự hiện diện của SARG không đảm bảo việc sử dụng chỉ mục cho SEEK. Thuật toán chi phí của trình tối ưu hóa vẫn có thể xác định rằng chỉ mục là quá tốn kém, đặc biệt là nếu SARG đề cập đến một tỷ lệ phần trăm lớn các hàng trong một bảng. Sự vắng mặt của SARG có nghĩa là trình tối ưu hóa sẽ không đánh giá SEEK trên chỉ mục không bao gồm.
Ví dụ về các biểu thức không thể SARGable LIKE bao gồm những biểu thức có mệnh đề sử dụng ký tự đại diện ở đầu chuỗi, chẳng hạn như WHERE lastName LIKE '%SMITH%'. Các vị từ không SARGable khác xảy ra khi sử dụng các hàm trên một cột, chẳng hạn như WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'. Các truy vấn này thường được xác định bằng cách kiểm tra kế hoạch thực thi để quét chỉ mục hoặc bảng mà tìm kiếm sẽ xảy ra theo cách khác.
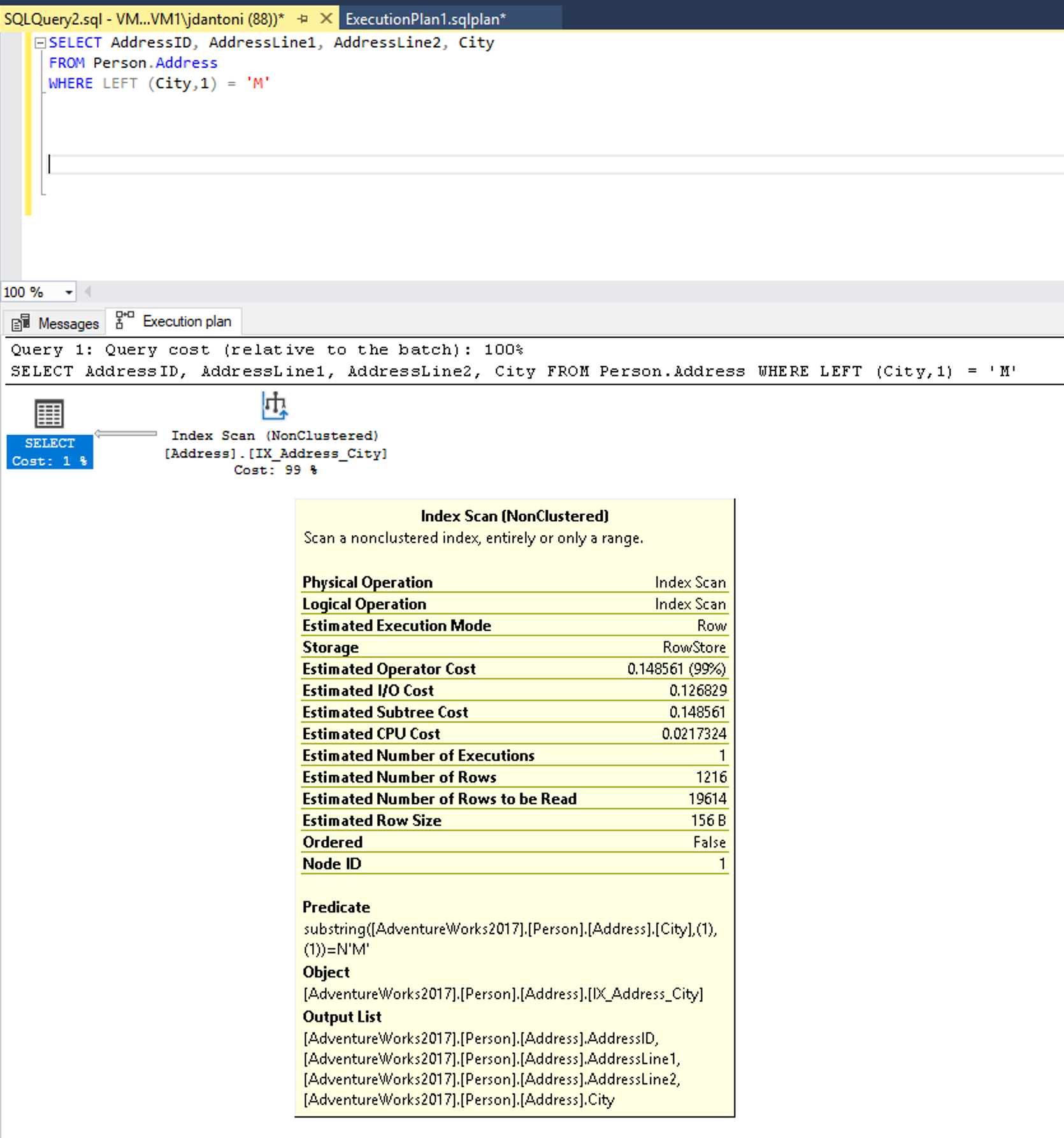
Có một chỉ mục trên cột Thành phố đang được sử dụng trong WHERE mệnh đề của truy vấn và trong khi nó đang được sử dụng trong kế hoạch thực thi này ở trên, bạn có thể thấy chỉ mục đang được quét, có nghĩa là toàn bộ chỉ mục đang được đọc. Hàm LEFT trong vị ngữ làm cho biểu thức này không thể SARGable. Trình tối ưu hóa sẽ không đánh giá bằng cách sử dụng tìm kiếm chỉ mục trên cột Thành phố .
Truy vấn này có thể được viết để sử dụng một vị từ có thể SARGable. Sau đó, trình tối ưu hóa sẽ đánh giá SEEK trên chỉ mục trên cột Thành phố . Toán tử tìm kiếm chỉ mục, trong trường hợp này, sẽ đọc một tập hợp các hàng nhỏ hơn.
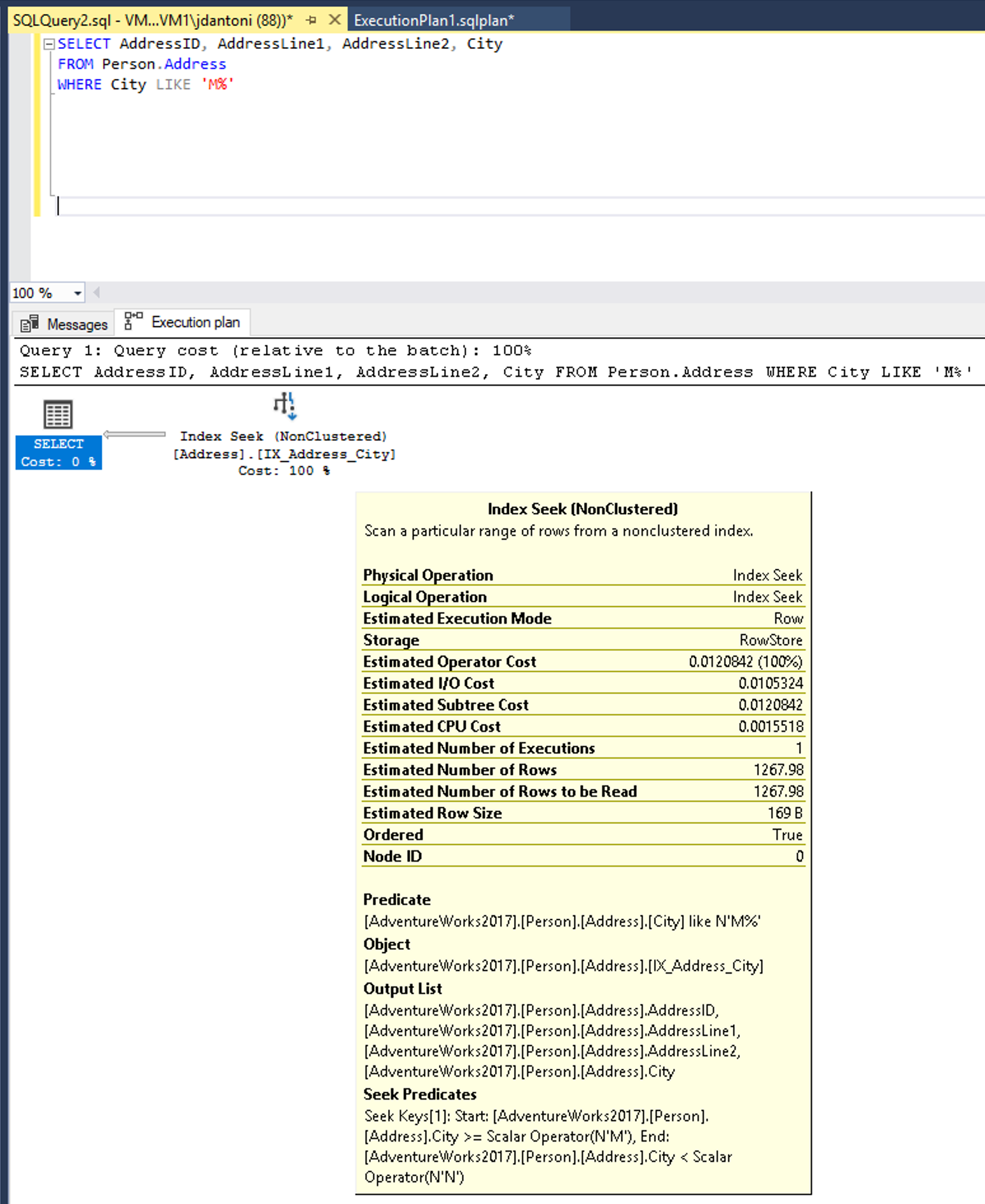
Thay đổi LEFT hàm thành kết LIKE quả trong một tìm kiếm chỉ mục.
Ghi
Từ LIKE khóa, trong ví dụ này, không có ký tự đại diện ở bên trái, vì vậy từ khóa này đang tìm kiếm các thành phố bắt đầu bằng M. Nếu nó là "hai mặt" hoặc bắt đầu với một ký tự đại diện ('%M%' hoặc '%M') thì nó sẽ không thể SARGable. Thao tác tìm kiếm được ước tính trả về 1.267 hàng, hoặc khoảng 15% ước tính cho truy vấn với vị từ không SARGable.
Một số kiểu chống phát triển cơ sở dữ liệu khác đang xử lý cơ sở dữ liệu như một dịch vụ chứ không phải là lưu trữ dữ liệu. Sử dụng cơ sở dữ liệu để chuyển đổi dữ liệu sang JSON, thao tác với các chuỗi hoặc thực hiện các tính toán phức tạp có thể dẫn đến việc sử dụng CPU quá mức và độ trễ tăng. Truy vấn tìm cách truy xuất tất cả các bản ghi rồi thực hiện tính toán trong cơ sở dữ liệu có thể dẫn đến việc sử dụng IO và CPU quá mức. Tốt nhất, bạn nên sử dụng cơ sở dữ liệu cho các thao tác truy nhập dữ liệu và các cấu trúc cơ sở dữ liệu được tối ưu hóa như tổng hợp.
Thiếu chỉ mục
Các vấn đề hiệu suất phổ biến nhất đối với người quản trị cơ sở dữ liệu bắt nguồn từ việc thiếu chỉ mục hữu ích, khiến công cụ đọc nhiều trang hơn mức cần thiết để trả về kết quả truy vấn. Trong khi chỉ mục tiêu thụ tài nguyên (ảnh hưởng đến hiệu suất ghi và không gian tiêu thụ), lợi nhuận hiệu suất của họ thường lớn hơn chi phí tài nguyên bổ sung. Các kế hoạch thực thi với những vấn đề này có thể được xác định bởi toán tử truy vấn Quét Chỉ mục Liên cụm hoặc kết hợp Tìm Kiếm Chỉ mục Chưa bao gồm và Tra cứu Khóa, cho biết các cột bị thiếu trong chỉ mục hiện có.
Công cụ cơ sở dữ liệu giúp bằng cách báo cáo chỉ mục bị thiếu trong kế hoạch thực thi. Tên và chi tiết của chỉ mục được đề xuất có sẵn thông qua dạng xem quản lý động sys.dm_db_missing_index_details. Các DMV khác như và sys.dm_db_index_usage_stats làm sys.dm_db_index_operational_stats nổi bật việc sử dụng các chỉ mục hiện có.
Việc thả chỉ mục không sử dụng có thể hợp lý. Thiếu DMV chỉ mục và cảnh báo kế hoạch nên là điểm bắt đầu để điều chỉnh truy vấn. Điều quan trọng là phải hiểu các truy vấn chính và xây dựng chỉ mục để hỗ trợ các truy vấn đó. Không nên tạo tất cả các chỉ mục bị thiếu mà không đánh giá chúng trong ngữ cảnh.
Thống kê thiếu và không cập nhật
Hiểu rõ tầm quan trọng của thống kê cột và chỉ mục đối với trình tối ưu hóa truy vấn là rất quan trọng. Cũng cần phải nhận dạng các điều kiện có thể dẫn đến thống kê lỗi thời và cách sự cố này có thể biểu hiện trong SQL Server. Azure SQL cung cấp mặc định để đặt thống kê tự động cập nhật thành BẬT. Trước SQL Server 2016, hành vi mặc định của thống kê autoupdate là không cập nhật thống kê cho đến khi số lượng sửa đổi đối với cột trong chỉ mục bằng khoảng 20% số hàng trong bảng. Hành vi này có thể dẫn đến sửa đổi dữ liệu quan trọng thay đổi hiệu suất truy vấn mà không cập nhật số liệu thống kê, dẫn đến kế hoạch tối ưu phụ dựa trên số liệu thống kê lỗi thời.
Trước SQL Server 2016, cờ theo dõi 2371 có thể được sử dụng để thay đổi số lượng sửa đổi bắt buộc thành giá trị động, do đó khi bảng của bạn tăng lên, tỷ lệ phần trăm sửa đổi hàng cần thiết để kích hoạt cập nhật thống kê giảm. Các phiên bản mới hơn của SQL Server, Cơ sở dữ liệu Azure SQL và Phiên bản được Quản lý azure SQL hỗ trợ hành vi này theo mặc định. Chức năng quản sys.dm_db_stats_properties lý động hiển thị số liệu thống kê lần trước được cập nhật và số sửa đổi kể từ lần cập nhật gần nhất, cho phép bạn nhanh chóng xác định số liệu thống kê có thể cần cập nhật thủ công.
Lựa chọn trình tối ưu hóa kém
Trong khi trình tối ưu hóa truy vấn thực hiện tốt công việc tối ưu hóa hầu hết các truy vấn, có một số trường hợp cạnh trong đó trình tối ưu hóa dựa trên chi phí có thể đưa ra các quyết định có ảnh hưởng không được hiểu đầy đủ. Có nhiều cách để giải quyết vấn đề này bao gồm sử dụng gợi ý truy vấn, gắn cờ theo dõi, bắt buộc kế hoạch thực thi và các điều chỉnh khác để đạt được kế hoạch truy vấn ổn định và tối ưu. Microsoft có một nhóm hỗ trợ có thể giúp khắc phục các trường hợp này.
Trong ví dụ dưới đây từ cơ sở dữ liệu AdventureWorks2017 , một gợi ý truy vấn đang được sử dụng để yêu cầu trình tối ưu hóa cơ sở dữ liệu luôn sử dụng tên thành phố Seattle. Gợi ý này sẽ không đảm bảo kế hoạch thực thi tốt nhất cho tất cả các giá trị thành phố, nhưng nó có thể dự đoán được. Giá trị của 'Seattle' cho sẽ @city_name chỉ được sử dụng trong quá trình tối ưu hóa. Trong khi thực hiện, giá trị được cung cấp thực tế (‘Ascheim’) được sử dụng.
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Như đã thấy trong ví dụ, truy vấn sử dụng gợi ý (mệnh đề #D0) để yêu cầu trình tối ưu hóa sử dụng một giá trị biến cụ thể để xây dựng kế hoạch thực thi.
Tham số sniffing
SQL Server lưu các kế hoạch thực thi truy vấn vào bộ đệm ẩn để dùng sau này. Vì quy trình truy xuất kế hoạch thực thi dựa trên giá trị băm của truy vấn, văn bản truy vấn phải giống nhau cho mỗi lần thực hiện truy vấn cho kế hoạch lưu trong bộ đệm ẩn được sử dụng. Để hỗ trợ nhiều giá trị trong cùng một truy vấn, nhiều nhà phát triển sử dụng các tham số, đi qua các quy trình được lưu trữ, như trong ví dụ sau đây:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Các truy vấn cũng có thể được tham số hóa rõ ràng bằng cách sử dụng thủ tục sp_executesql. Tuy nhiên, tham số hóa rõ ràng của truy vấn riêng lẻ được thực hiện thông qua ứng dụng với một số biểu mẫu (tùy thuộc vào API) của PREPARE và EXECUTE. Khi công cụ cơ sở dữ liệu thực hiện truy vấn đó lần đầu tiên, nó sẽ tối ưu hóa truy vấn dựa trên giá trị ban đầu của tham số, trong trường hợp này là 42. Hành vi này, được gọi là tham số sniffing, cho phép giảm khối lượng công việc tổng thể của các truy vấn biên dịch trên máy chủ. Tuy nhiên, nếu có dữ liệu lệch, hiệu suất truy vấn có thể khác nhau rất nhiều.
Ví dụ: một bảng có 10 triệu bản ghi và 99% trong số các bản ghi đó có ID là 1 và 1% còn lại là các số duy nhất, hiệu suất được dựa trên ID được sử dụng ban đầu để tối ưu hóa truy vấn. Hiệu năng biến động dữ liệu này biểu thị độ lệch dữ liệu và không phải là vấn đề vốn có với việc đánh hơi tham số. Hành vi này là một vấn đề hiệu suất khá phổ biến mà bạn nên được nhận thức. Bạn nên hiểu các tùy chọn để giảm bớt sự cố. Có một vài cách để giải quyết vấn đề này, nhưng mỗi cách đều đi kèm với sự cân bằng:
- Sử dụng gợi
RECOMPILEý trong truy vấn của bạn hoặcWITH RECOMPILEtùy chọn thực thi trong các thủ tục được lưu trữ của bạn. Gợi ý này khiến truy vấn hoặc thủ tục được biên dịch lại mỗi khi nó được thực hiện, mà sẽ làm tăng mức sử dụng CPU trên máy chủ nhưng sẽ luôn luôn sử dụng giá trị tham số hiện tại. - Bạn có thể sử dụng gợi
OPTIMIZE FOR UNKNOWNý truy vấn. Gợi ý này khiến trình tối ưu hóa chọn không đánh hơi tham số và so sánh giá trị với biểu đồ tần suất dữ liệu cột. Tùy chọn này sẽ không giúp bạn có được kế hoạch tốt nhất có thể nhưng sẽ cho phép kế hoạch thực thi nhất quán. - Viết lại thủ tục hoặc truy vấn của bạn bằng cách thêm lô-gic xung quanh các giá trị tham số để chỉ RECOMPILE cho các tham số phiền hà đã biết. Trong ví dụ dưới đây, nếu tham số SalesPersonID là NULL, truy vấn được thực hiện với
OPTION (RECOMPILE).
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Ví dụ này là một giải pháp tốt nhưng nó đòi hỏi một nỗ lực phát triển khá lớn và sự hiểu biết vững chắc về phân phối dữ liệu của bạn. Yêu cầu bảo trì khi dữ liệu thay đổi.