Chụp các mẫu hình với mạng thần kinh tái phát
Trong bài trước, chúng tôi đã đề cập đến các biểu diễn ngữ nghĩa phong phú của văn bản. Kiến trúc mà chúng ta đang sử dụng nắm bắt ý nghĩa tổng hợp của các từ trong câu, nhưng nó không tính đến thứ tự của các từ, bởi vì hoạt động tổng hợp theo sau nhúng sẽ loại bỏ thông tin này khỏi văn bản gốc. Bởi vì các mô hình này không thể biểu diễn thứ tự từ, chúng không thể giải quyết các tác vụ phức tạp hoặc mơ hồ hơn như tạo văn bản hoặc trả lời câu hỏi.
Để nắm bắt ý nghĩa của một chuỗi văn bản, chúng tôi sử dụng kiến trúc mạng nơ-ron được gọi là mạng nơ-ron tuần hoàn, hoặc RNN. Khi sử dụng RNN, chúng ta truyền câu của mình qua mạng từng mã thông báo một và mạng tạo ra một số trạng thái, sau đó chúng tôi chuyển lại cho mạng với mã thông báo tiếp theo.
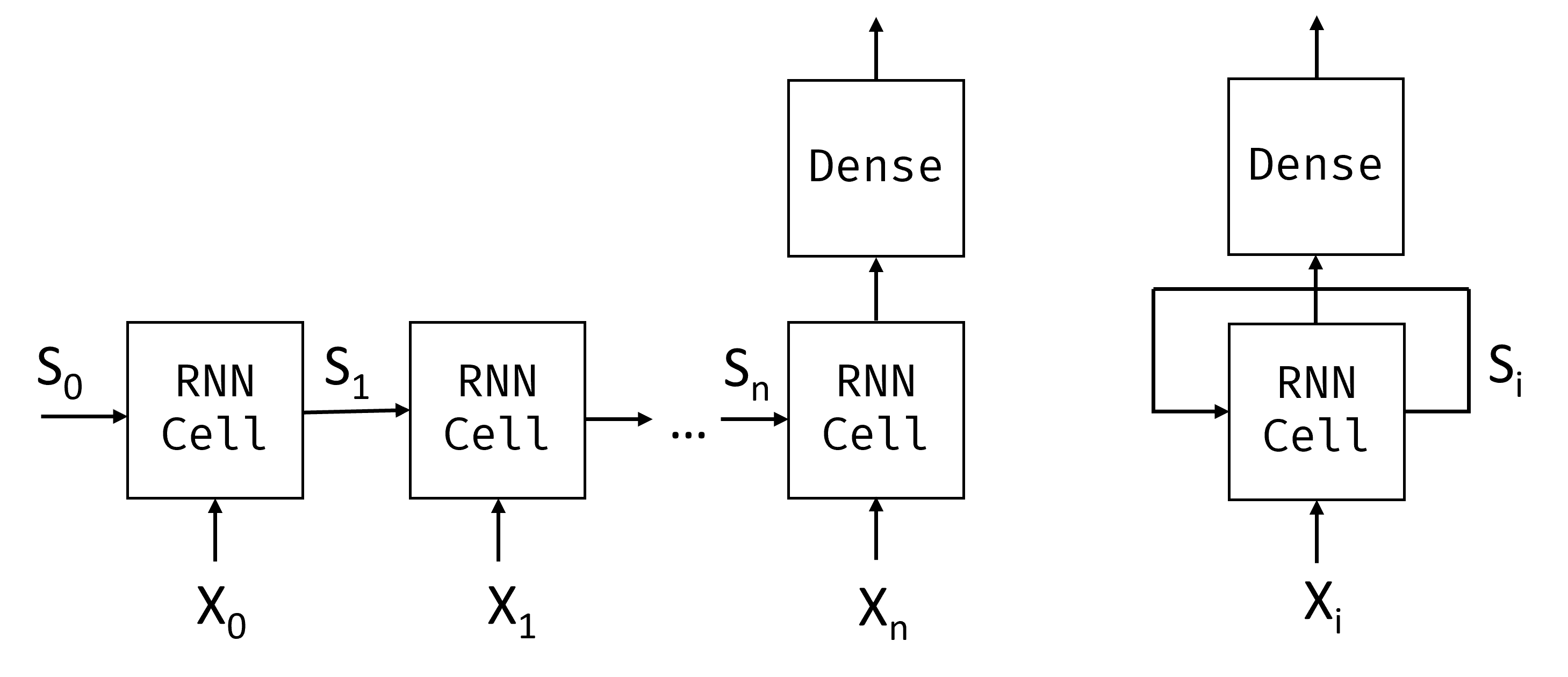
Với trình tự đầu vào của mã thông báo $X_0,\dots,X_n$, RNN tạo ra một chuỗi các khối mạng nơ-ron và đào tạo chuỗi này từ đầu đến cuối bằng cách sử dụng lan truyền ngược. Mỗi khối mạng lấy một cặp $(X_i,S_i)$ làm đầu vào và tạo ra $S_{i+1}$ làm kết quả. Trạng thái cuối cùng $S_n$ hoặc đầu ra $Y_n$ đi vào bộ phân loại tuyến tính để tạo ra kết quả. Tất cả các khối mạng đều có cùng trọng số và được đào tạo từ đầu đến cuối bằng cách sử dụng một lần truyền ngược.
Bởi vì các vectơ trạng thái $S_0,\dots,S_n$ được truyền qua mạng, RNN có thể học các phụ thuộc tuần tự giữa các từ. Ví dụ, khi từ not xuất hiện ở đâu đó trong dãy, nó có thể học cách phủ nhận các phần tử nhất định trong vectơ trạng thái.
Bên trong, mỗi ô RNN chứa hai ma trận trọng lượng: $W_H$ và $W_I$, và thiên vị $b$. Ở mỗi bước RNN, cho đầu vào $X_i$ và trạng thái đầu vào $S_i$, trạng thái đầu ra được tính là $S_{i+1} = f(W_H\times S_i + W_I\times X_i+b)$, trong đó $f$ là hàm kích hoạt (thường là $\tanh$).
Lưu ý
Với các vấn đề như tạo văn bản hoặc dịch máy, chúng tôi cũng muốn nhận được một số giá trị đầu ra ở mỗi bước RNN. Trong trường hợp này, cũng có một ma trận khác $W_O$ và đầu ra được tính là $Y_i=f(W_O\times S_{i+1}+b_O)$, trong đó $S_{i+1}$ là trạng thái cập nhật từ bước hiện tại.
Hãy xem các mạng nơ-ron lặp lại có thể giúp chúng ta phân loại tập dữ liệu tin tức của mình như thế nào với mã sau:
import tensorflow as tf
import keras
import tensorflow_datasets as tfds
import numpy as np
# We are going to be training pretty large models. In order not to face errors, we need
# to set tensorflow option to grow GPU memory allocation when required
physical_devices = tf.config.list_physical_devices('GPU')
if len(physical_devices)>0:
tf.config.set_memory_growth(physical_devices[0], True)
dataset = tfds.load('ag_news_subset')
ds_train = dataset['train']
ds_test = dataset['test']
Khi đào tạo các mô hình lớn, việc phân bổ bộ nhớ GPU có thể trở thành một vấn đề. Chúng tôi cũng có thể cần thử nghiệm với các kích thước minibatch khác nhau để dữ liệu phù hợp với bộ nhớ GPU của chúng tôi, nhưng quá trình đào tạo đủ nhanh. Nếu bạn đang chạy mã này trên máy GPU của riêng mình, bạn có thể thử nghiệm điều chỉnh kích thước lô nhỏ để tăng tốc độ đào tạo.
Lưu ý
Một số phiên bản nhất định của trình điều khiển nVidia được biết là không giải phóng bộ nhớ sau khi đào tạo mô hình. Chúng tôi đang chạy một số ví dụ trong đơn vị này và nó có thể khiến bộ nhớ cạn kiệt trong một số thiết lập nhất định, đặc biệt nếu bạn đang thực hiện thử nghiệm của riêng mình. Nếu bạn gặp phải một số lỗi bất thường khi bắt đầu đào tạo mô hình, bạn có thể muốn khởi động lại môi trường Python của mình.
batch_size = 16
embed_size = 64
Bộ phân loại RNN đơn giản
Trong trường hợp RNN đơn giản, mỗi đơn vị tuần hoàn là một mạng tuyến tính đơn giản, nhận một vectơ đầu vào và vectơ trạng thái, và tạo ra một vectơ trạng thái mới. Trong Keras, điều này có thể được biểu diễn bằng SimpleRNN lớp.
Mặc dù chúng ta có thể truyền trực tiếp các mã thông báo được mã hóa một nóng đến lớp RNN, nhưng đây không phải là một ý tưởng hay vì tính chiều cao của chúng. Do đó, chúng ta sẽ sử dụng một lớp nhúng để giảm chiều của các vectơ từ, tiếp theo là một lớp RNN và cuối cùng là Dense một bộ phân loại.
Lưu ý
Trong trường hợp có chiều không quá cao, ví dụ như khi sử dụng mã hóa cấp ký tự, có thể hợp lý khi chuyển mã thông báo được mã hóa một nóng trực tiếp vào ô RNN.
# We use a smaller vocabulary (20,000) here than in previous units because
# RNN models have more parameters per token, and a smaller vocabulary
# helps keep training time and memory usage manageable.
vocab_size = 20000
vectorizer = keras.layers.TextVectorization(max_tokens=vocab_size)
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, embed_size),
keras.layers.SimpleRNN(16),
keras.layers.Dense(4,activation='softmax')
])
model.summary()
Chạy mã này sẽ tạo ra kết quả sau:
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ text_vectorization │ (None, None) │ 0 │
│ (TextVectorization) │ │ │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ embedding (Embedding) │ (None, None, 64) │ 1,280,000 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ simple_rnn (SimpleRNN) │ (None, 16) │ 1,296 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 4) │ 68 │
└──────────────────────────────┴───────────────────────────┴───────────────┘
Total params: 1,281,364 (4.89 MB)
Trainable params: 1,281,364 (4.89 MB)
Non-trainable params: 0 (0.00 B)
Lưu ý
Chúng ta đang sử dụng một lớp nhúng chưa được đào tạo ở đây để đơn giản, nhưng để có kết quả tốt hơn, chúng ta có thể sử dụng một lớp nhúng được đào tạo trước bằng cách sử dụng Word2Vec, như được mô tả trong bài trước. Sẽ là một bài tập tốt để bạn điều chỉnh mã này để hoạt động với các nhúng được đào tạo trước.
Bây giờ chúng ta hãy đào tạo RNN của chúng ta. RNN nói chung rất khó đào tạo, bởi vì một khi các tế bào RNN được mở ra dọc theo chiều dài trình tự, số lượng lớp kết quả liên quan đến quá trình lan truyền ngược là lớn. Do đó, chúng ta cần chọn một tốc độ học nhỏ hơn và đào tạo mạng trên một tập dữ liệu lớn hơn để tạo ra kết quả tốt. Quá trình này có thể mất khá nhiều thời gian, vì vậy việc sử dụng GPU được ưu tiên hơn.
Để tăng tốc độ mọi thứ, chúng tôi sẽ chỉ đào tạo mô hình RNN trên các tiêu đề tin tức, bỏ qua mô tả. Bạn có thể thử đào tạo với mô tả và xem liệu bạn có thể lấy mô hình để đào tạo hay không.
def extract_title(x):
return x['title']
def tupelize_title(x):
return (extract_title(x),x['label'])
print('Training vectorizer')
vectorizer.adapt(ds_train.take(2000).map(extract_title))
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize_title).batch(batch_size),validation_data=ds_test.map(tupelize_title).batch(batch_size))
Lưu ý
Độ chính xác có thể thấp hơn ở đây, bởi vì chúng tôi chỉ đào tạo về các tiêu đề tin tức.
Xem lại các chuỗi biến
Hãy nhớ rằng TextVectorization lớp sẽ tự động đệm các chuỗi có độ dài thay đổi trong một lô nhỏ với mã thông báo pad. Hóa ra những token đó cũng tham gia vào quá trình đào tạo và chúng có thể làm phức tạp sự hội tụ của mô hình.
Có một số cách tiếp cận mà chúng tôi có thể thực hiện để giảm thiểu số lượng đệm. Một trong số đó là sắp xếp lại tập dữ liệu theo độ dài trình tự và nhóm tất cả các trình tự theo kích thước. Điều này có thể được thực hiện bằng cách sử dụng chức năng ( tf.data.bucket_by_sequence_length xem tài liệu).
Một cách tiếp cận khác là sử dụng mặt nạ. Trong Keras, một số lớp hỗ trợ đầu vào bổ sung cho biết mã thông báo nào cần được tính đến khi đào tạo. Để kết hợp masking vào mô hình của chúng ta, chúng ta có thể bao gồm một layer riêng biệt Masking (docs) hoặc chúng ta có thể chỉ định mask_zero=True tham số của layer của chúng ta Embedding .
Lưu ý
Khi sử dụng mask_zero=True, chỉ mục mã thông báo 0 được coi là khoảng đệm và không phải là một mục từ vựng hợp lệ. Điều này có nghĩa là tất cả các chỉ số từ vựng được dịch chuyển một. Lớp TextVectorization đã dự trữ chỉ số 0 cho phần đệm theo mặc định, vì vậy điều này hoạt động liền mạch khi cả hai được sử dụng cùng nhau.
def extract_text(x):
return x['title']+' '+x['description']
def tupelize(x):
return (extract_text(x),x['label'])
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size,embed_size,mask_zero=True),
keras.layers.SimpleRNN(16),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),validation_data=ds_test.map(tupelize).batch(batch_size))
Bây giờ chúng ta đang sử dụng masking, chúng ta có thể đào tạo mô hình trên toàn bộ tập dữ liệu tiêu đề và mô tả.
LSTM: Trí nhớ ngắn hạn dài hạn
Một trong những vấn đề chính của RNN là biến mất gradient. RNN có thể dài và có thể gặp khó khăn trong việc truyền gradient trở lại lớp đầu tiên của mạng trong quá trình lan truyền ngược. Khi điều này xảy ra, mạng không thể tìm hiểu mối quan hệ giữa các token ở xa. Một cách để tránh vấn đề này là giới thiệu quản lý trạng thái rõ ràng bằng cách sử dụng cổng. Hai kiến trúc phổ biến nhất giới thiệu cổng là bộ nhớ ngắn hạn dài (LSTM) và đơn vị lặp lại có cổng (GRU). Chúng tôi đề cập đến LSTM ở đây.

Mạng LSTM được tổ chức theo cách tương tự như RNN, nhưng có hai trạng thái được chuyển từ lớp này sang lớp khác: trạng thái thực tế $c$ và vectơ ẩn $h$. Tại mỗi đơn vị, vectơ ẩn $h_{t-1}$ được kết hợp với đầu vào $x_t$ và cùng nhau kiểm soát những gì xảy ra với trạng thái $c_t$ và đầu ra $h_{t}$ thông qua các cổng. Mỗi cổng có kích hoạt sigmoid (đầu ra trong phạm vi $[0,1]$), có thể được coi là mặt nạ bit khi nhân với vectơ trạng thái. LSTM có các cổng sau (từ trái sang phải trên hình trên, theo quy ước từ blog của Olah):
- quên cổng xác định thành phần nào của vectơ $c_{t-1}$ chúng ta cần quên và thành phần nào đi qua.
- cổng đầu vào xác định lượng thông tin từ vectơ đầu vào và vectơ ẩn trước đó sẽ được kết hợp vào vectơ trạng thái.
- cổng đầu ra lấy vectơ trạng thái mới và quyết định thành phần nào của nó sẽ được sử dụng để tạo vectơ ẩn mới $h_t$.
Các thành phần của trạng thái $c$ có thể được coi là cờ có thể được bật và tắt. Ví dụ, khi chúng ta bắt gặp cái tên Alice trong dãy số, chúng ta đoán rằng nó đề cập đến một người phụ nữ và giương cao lá cờ trong trạng thái nói rằng chúng ta có một danh từ nữ trong câu. Khi chúng ta tiếp tục gặp các từ và Tom, chúng ta sẽ giương cờ nói rằng chúng ta có một danh từ số nhiều. Do đó, bằng cách thao tác trạng thái, chúng ta có thể theo dõi các thuộc tính ngữ pháp của câu.
Mặc dù cấu trúc bên trong của một ô LSTM có thể trông phức tạp, nhưng Keras ẩn việc triển khai này bên trong LSTM lớp, vì vậy điều duy nhất chúng ta cần làm trong ví dụ trên là thay thế lớp lặp lại:
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, embed_size),
keras.layers.LSTM(8),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),validation_data=ds_test.map(tupelize).batch(batch_size))
Lưu ý
Đào tạo LSTM cũng chậm và bạn có thể không tăng nhiều độ chính xác khi bắt đầu đào tạo. Bạn có thể cần tiếp tục đào tạo trong một thời gian để đạt được độ chính xác tốt.
RNN hai chiều và đa lớp
Trong các ví dụ của chúng tôi cho đến nay, các mạng lặp lại hoạt động từ đầu một chuỗi cho đến khi kết thúc. Điều này cảm thấy tự nhiên đối với chúng ta vì nó đi theo cùng một hướng mà chúng ta đọc hoặc nghe lời nói. Tuy nhiên, đối với các tình huống yêu cầu truy cập ngẫu nhiên vào trình tự đầu vào, sẽ hợp lý hơn nếu chạy tính toán lặp lại theo cả hai hướng. RNN cho phép tính toán theo cả hai hướng được gọi là RNN hai chiều và chúng có thể được tạo bằng cách bọc lớp lặp lại bằng một lớp đặc biệt Bidirectional .
Lưu ý
Lớp tạo Bidirectional hai bản sao của lớp bên trong nó và đặt go_backwards thuộc tính của một trong những bản sao đó thành True, làm cho nó đi theo hướng ngược lại dọc theo chuỗi.
Mạng tuần hoàn, một chiều hoặc hai chiều, nắm bắt các mẫu trong một trình tự và lưu trữ chúng vào các vectơ trạng thái hoặc trả về chúng dưới dạng đầu ra. Như với các mạng tích chập, chúng ta có thể xây dựng một lớp lặp lại khác sau lớp đầu tiên để nắm bắt các mẫu cấp cao hơn, được xây dựng từ các mẫu cấp thấp hơn được trích xuất bởi lớp đầu tiên. Điều này dẫn chúng ta đến khái niệm RNN nhiều lớp, bao gồm hai hoặc nhiều mạng tuần hoàn, trong đó đầu ra của lớp trước được chuyển sang lớp tiếp theo dưới dạng đầu vào.
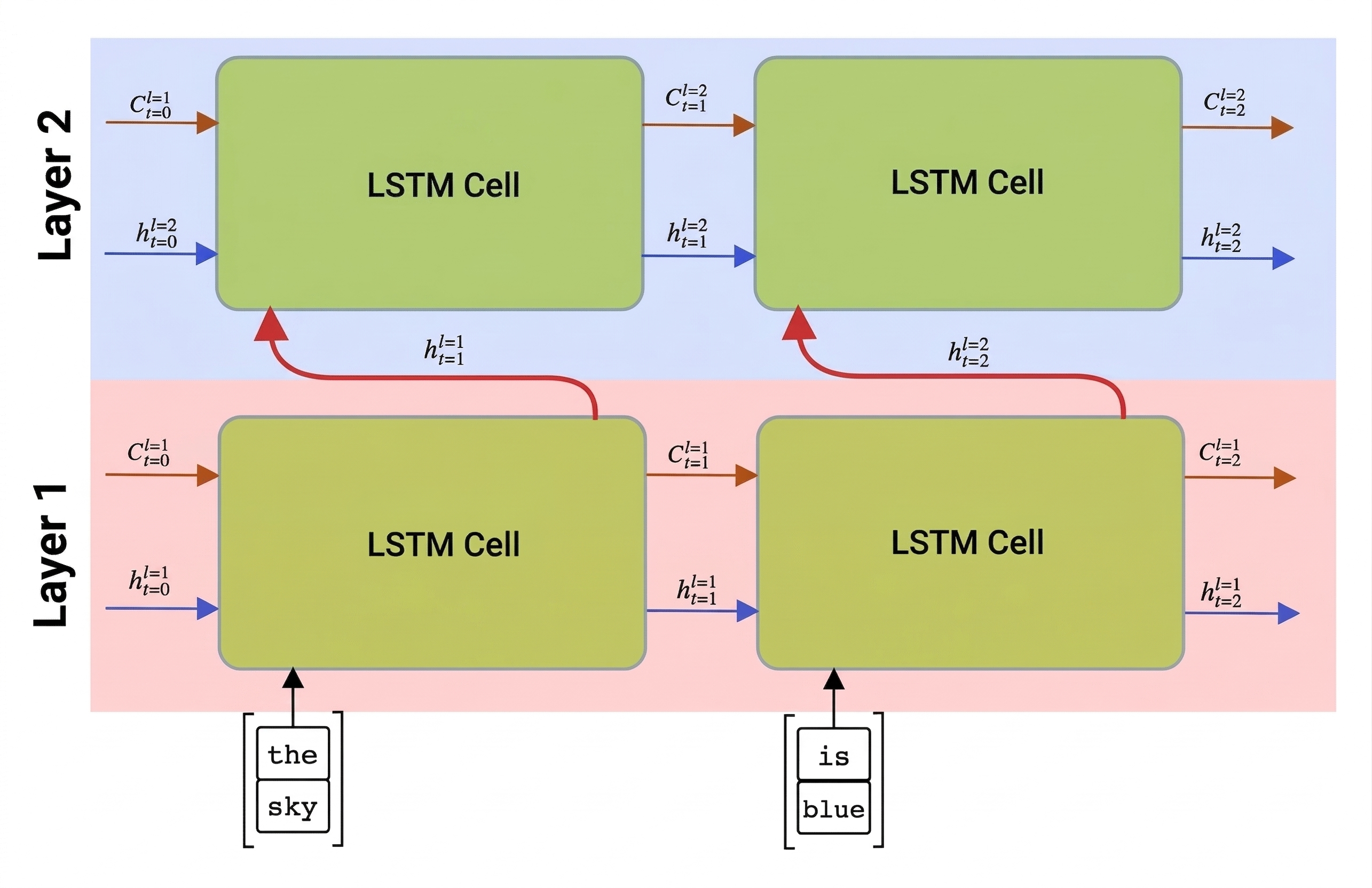
Hình ảnh từ bài đăng này về LSTM nhiều lớp của Fernando López.
Keras làm cho việc xây dựng các mạng này trở thành một nhiệm vụ dễ dàng, bởi vì bạn chỉ cần thêm nhiều lớp lặp lại vào mô hình. Đối với tất cả các lớp ngoại trừ lớp cuối cùng, chúng ta cần chỉ định return_sequences=True tham số, bởi vì chúng ta cần lớp trả về tất cả các trạng thái trung gian, chứ không chỉ trạng thái cuối cùng của tính toán lặp lại.
Mã sau đây triển khai LSTM hai chiều hai lớp cho bài toán phân loại của chúng ta.
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, 128, mask_zero=True),
keras.layers.Bidirectional(keras.layers.LSTM(64,return_sequences=True)),
keras.layers.Bidirectional(keras.layers.LSTM(64)),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),
validation_data=ds_test.map(tupelize).batch(batch_size))