GitHub Copilot Mô hình Ngôn ngữ Lớn (LLM)
GitHub Copilot được hỗ trợ bởi các Mô hình Ngôn ngữ Lớn (LLM) để hỗ trợ bạn viết mã liền mạch. Trong đơn vị này, chúng tôi tập trung vào sự hiểu biết sự tích hợp và tác động của LLM trong GitHub Copilot. Hãy xem lại các chủ đề sau:
- LLMs là gì?
- Vai trò của LLM trong GitHub Copilot và nhắc nhở
- Tinh chỉnh LLMs
- Tinh chỉnh LoRA
LLMs là gì?
Mô hình Ngôn ngữ Lớn (LLM) là các mô hình trí tuệ nhân tạo được thiết kế và được đào tạo để hiểu, tạo ra và thao tác với ngôn ngữ con người. Các mô hình này được hài lòng với khả năng xử lý một loạt các tác vụ liên quan đến văn bản, nhờ vào lượng lớn dữ liệu văn bản mà chúng được đào tạo. Dưới đây là một số khía cạnh cốt lõi để hiểu về LLM:
Khối lượng dữ liệu đào tạo
LLMs được tiếp xúc với lượng lớn văn bản từ các nguồn khác nhau. Sự tiếp xúc này trang bị cho họ một sự hiểu biết rộng rãi về ngôn ngữ, ngữ cảnh và sự intricacies liên quan đến các hình thức giao tiếp khác nhau.
Hiểu theo ngữ cảnh
Chúng nổi trội trong việc tạo văn bản phù hợp và mạch văn bản theo ngữ cảnh. Khả năng hiểu ngữ cảnh của họ cho phép họ đóng góp có ý nghĩa, có thể là hoàn thành câu, đoạn văn hoặc thậm chí tạo ra toàn bộ tài liệu theo ngữ cảnh phù hợp.
Máy học và tích hợp AI
LLMs được căn cứ trong máy học và các nguyên tắc trí tuệ nhân tạo. Họ là những mạng lưới thần kinh có hàng triệu, thậm chí hàng tỷ thông số được tinh chỉnh trong quá trình đào tạo để hiểu và dự đoán văn bản một cách hiệu quả.
Linh hoạt
Các mô hình này không giới hạn ở một loại văn bản hoặc ngôn ngữ cụ thể. Chúng có thể được điều chỉnh và tinh chỉnh để thực hiện các tác vụ chuyên biệt, làm cho chúng linh hoạt cao và áp dụng trên các lĩnh vực và ngôn ngữ khác nhau.
Vai trò của LLM trong GitHub Copilot và nhắc nhở
GitHub Copilot sử dụng LLM để cung cấp các đề xuất mã theo ngữ cảnh. LLM không chỉ xem xét các tập tin hiện tại mà còn mở các tập tin và tab khác trong IDE để tạo ra hoàn thành mã chính xác và có liên quan. Phương pháp tiếp cận linh động này đảm bảo các đề xuất tùy chỉnh, cải thiện năng suất của bạn.
Tinh chỉnh LLMs
Tinh chỉnh là một quy trình quan trọng cho phép chúng tôi điều chỉnh các mô hình ngôn ngữ lớn được đặt sẵn (LLM) cho các tác vụ hoặc tên miền cụ thể. Nó liên quan đến việc đào tạo mô hình trên một tập dữ liệu nhỏ hơn, cụ thể theo nhiệm vụ, được gọi là tập dữ liệu mục tiêu, trong khi sử dụng kiến thức và các tham số thu được từ một tập dữ liệu lớn pretrained, được gọi là mô hình nguồn.
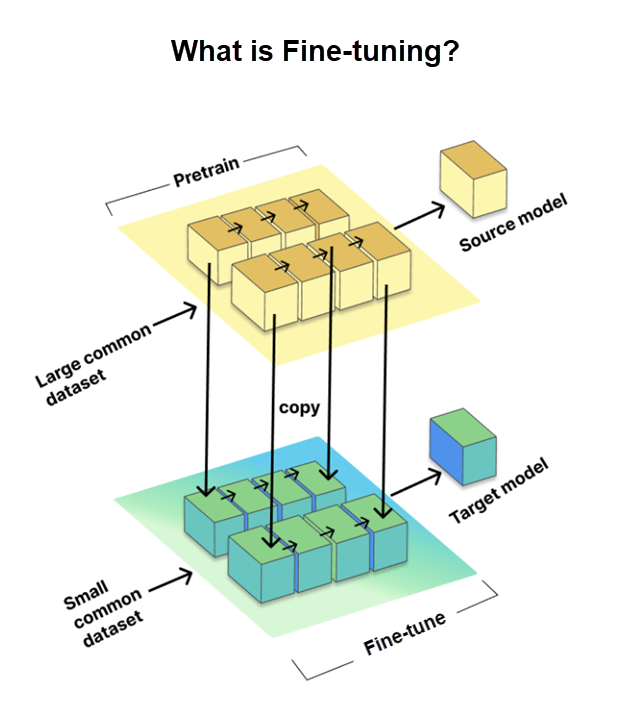
Tinh chỉnh là điều kiện cần thiết để điều chỉnh LLM cho các tác vụ cụ thể, nâng cao hiệu suất của chúng. Tuy nhiên, GitHub đã đi một bước xa hơn bằng cách sử dụng phương pháp tinh chỉnh LoRA, mà chúng tôi thảo luận tiếp theo.
Tinh chỉnh LoRA
Tinh chỉnh đầy đủ truyền thống có nghĩa là để đào tạo tất cả các bộ phận của một mạng lưới thần kinh, có thể chậm và phụ thuộc rất nhiều vào tài nguyên. Nhưng LoRA (Low-Rank thích ứng) tinh chỉnh là một lựa chọn thông minh. Nó được sử dụng để làm cho các mô hình ngôn ngữ lớn được kiểm tra trước (LLM) hoạt động tốt hơn cho các tác vụ cụ thể mà không làm lại tất cả các khóa đào tạo.
Dưới đây là cách thức hoạt động của LoRA:
- LoRA thêm các bộ phận có thể đào tạo nhỏ hơn cho mỗi lớp của mô hình được đặt trước, thay vì thay đổi mọi thứ.
- Mô hình ban đầu vẫn giữ nguyên, giúp tiết kiệm thời gian và tài nguyên.
Điều gì tuyệt vời về LoRA:
- Nó đánh bại các phương pháp thích ứng khác như bộ điều hợp và tinh chỉnh tiền tố.
- Nó giống như nhận được kết quả tuyệt vời với ít bộ phận di chuyển hơn.
Nói một cách đơn giản, loRA tinh chỉnh là làm việc thông minh hơn, không khó hơn, để làm cho LLMs tốt hơn cho các yêu cầu mã hóa cụ thể của bạn khi sử dụng Copilot.