Tạo tài nguyên dữ liệu
Là một nhà khoa học dữ liệu, bạn muốn tập trung vào các mô hình đào tạo máy học. Mặc dù bạn cần quyền truy nhập vào dữ liệu dưới dạng dữ liệu đầu vào cho mô hình máy học, nhưng bạn không muốn lo lắng về việc bạn cách quyền truy nhập. Để đơn giản hóa việc truy nhập vào dữ liệu bạn muốn làm việc cùng, bạn có thể sử dụng tài nguyên dữ liệu.
Tìm hiểu về tài nguyên dữ liệu
Trong Azure Machine Learning, tài nguyên dữ liệu là các tham chiếu đến vị trí lưu trữ dữ liệu, cách truy nhập và mọi siêu dữ liệu liên quan khác. Bạn có thể tạo tài sản dữ liệu để có quyền truy nhập vào dữ liệu trong kho dữ liệu, dịch vụ lưu trữ Azure, URL công cộng hoặc dữ liệu được lưu trữ trên thiết bị cục bộ của bạn.
Lợi ích của việc sử dụng tài nguyên dữ liệu là:
- Bạn có chia sẻ và sử dụng lại dữ với các thành viên khác trong nhóm để họ không cần nhớ vị trí tệp.
- Bạn có thể truy nhập liền mạch dữ liệu trong quá trình đào tạo mô hình (trên mọi loại điện toán được hỗ trợ) mà không cần lo lắng về chuỗi kết nối hoặc đường dẫn dữ liệu.
- Bạn có thể bản siêu dữ liệu của tài sản dữ liệu.
Có ba loại tài nguyên dữ liệu chính mà bạn có thể sử dụng:
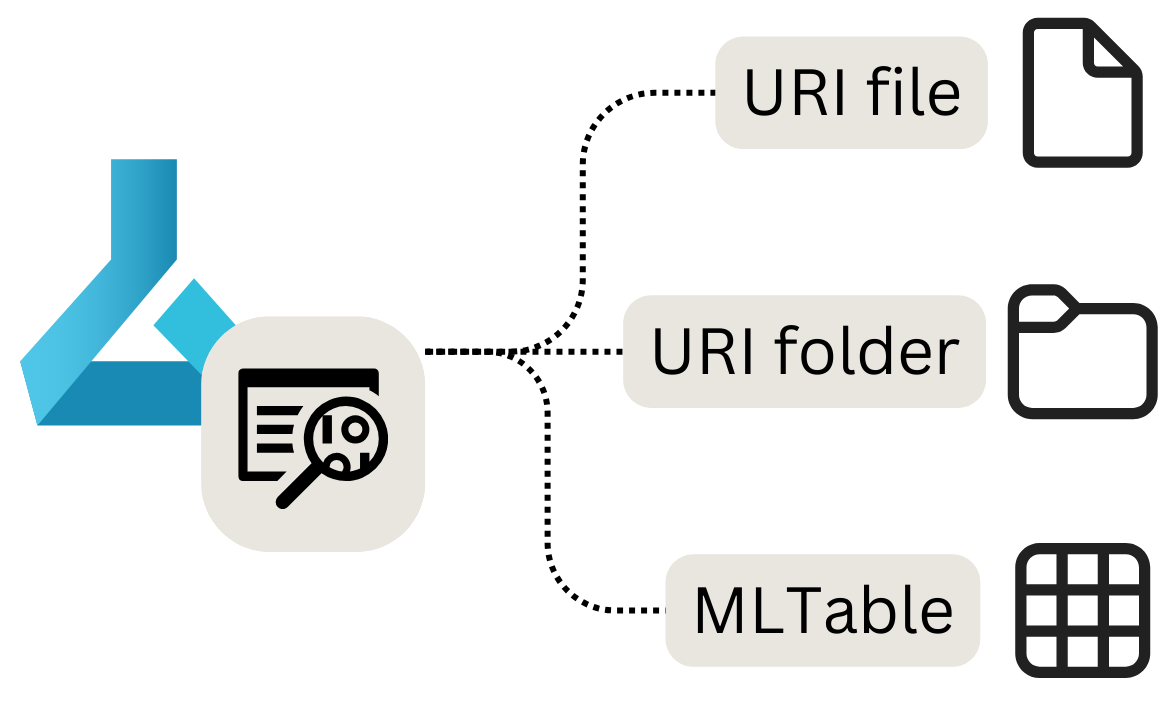
- tệp URI: Trỏ tới một tệp cụ thể.
- thư mục URI: Trỏ tới một thư mục.
- mltable: Trỏ tới một thư mục hoặc tệp và bao gồm một sơ đồ để đọc dưới dạng dữ liệu dạng bảng.
Ghi
URI là viết tắt của Uniform Resource Identifier và là viết tắt của một vị trí lưu trữ trên máy tính cục bộ của bạn, Azure Blob hoặc Data Lake Storage, vị trí https có sẵn công khai hoặc thậm chí là một kho dữ liệu đính kèm.
Khi nào nên sử dụng tài nguyên dữ liệu
Tài nguyên dữ liệu hữu ích nhất khi thực hiện các tác vụ máy học dưới dạng công việc Học Máy Azure. Là một công việc, bạn có thể chạy một tập lệnh Python lấy đầu vào và tạo đầu ra. Có thể phân tích tài nguyên dữ liệu dưới dạng cả dữ liệu đầu vào hoặc đầu ra của công việc Học Máy Azure.
Chúng ta hãy xem từng loại tài nguyên dữ liệu, cách tạo tài sản dữ liệu và cách sử dụng tài sản dữ liệu trong công việc.
Tạo tài sản dữ liệu tệp URI
Nội dung dữ liệu tệp URI trỏ đến một tệp cụ thể. Azure Machine Learning chỉ lưu trữ đường dẫn đến tệp, nghĩa là bạn có thể trỏ tới bất kỳ loại tệp nào. Khi bạn sử dụng tài sản dữ liệu, bạn xác định cách bạn muốn đọc dữ liệu, điều này phụ thuộc vào loại dữ liệu bạn đang kết nối đến.
Các đường dẫn được hỗ trợ mà bạn có thể sử dụng khi tạo tài sản dữ liệu tệp URI là:
- Cục bộ:
./<path> - Lưu trữ Azure Blob:
wasbs://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Azure Data Lake Storage (Thế hệ 2):
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file> - Kho dữ liệu:
azureml://datastores/<datastore_name>/paths/<folder>/<file>
Quan trọng
Khi bạn tạo tài sản dữ liệu và trỏ đến tệp hoặc thư mục được lưu trữ trên thiết bị cục bộ của mình, một bản sao của tệp hoặc thư mục sẽ được tải lên kho lưu trữ dữ liệu mặc định workspaceblobstore. Bạn có thể tìm thấy tệp hoặc thư mục trong thư LocalUpload mục. Bằng cách tải lên bản sao, bạn vẫn có thể truy cập dữ liệu từ không gian làm việc Azure Machine Learning, ngay cả khi thiết bị cục bộ lưu trữ dữ liệu không khả dụng.
Để tạo tài sản dữ liệu tệp URI, bạn có thể sử dụng mã sau:
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
my_path = '<supported-path>'
my_data = Data(
path=my_path,
type=AssetTypes.URI_FILE,
description="<description>",
name="<name>",
version="<version>"
)
ml_client.data.create_or_update(my_data)
Khi phân tích tài sản dữ liệu tệp URI dưới dạng dữ liệu đầu vào trong công việc Máy học của Azure, trước tiên bạn cần đọc dữ liệu trước khi có thể làm việc với dữ liệu đó.
Hãy tưởng tượng bạn tạo một tập lệnh Python mà bạn muốn chạy dưới dạng một công việc và bạn đặt giá trị của tham số đầu vào input_data là tài sản dữ liệu tệp URI (chỉ đến một tệp CSV). Bạn có thể đọc dữ liệu bằng cách bao gồm mã sau đây trong tập lệnh Python của mình:
import argparse
import pandas as pd
parser = argparse.ArgumentParser()
parser.add_argument("--input_data", type=str)
args = parser.parse_args()
df = pd.read_csv(args.input_data)
print(df.head(10))
Nếu nội dung dữ liệu tệp URI của bạn trỏ đến một loại tệp khác, bạn cần sử dụng mã Python thích hợp để đọc dữ liệu. Ví dụ: nếu thay vì tệp CSV, bạn đang làm việc với tệp JSON, bạn sẽ sử dụng tệp pd.read_json() đó.
Tạo tài sản dữ liệu thư mục URI
Nội dung dữ liệu thư mục URI trỏ tới một thư mục cụ thể. Tính năng này hoạt động tương tự như tài sản dữ liệu tệp URI và hỗ trợ cùng một đường dẫn.
Để tạo tài sản dữ liệu thư mục URI với Python SDK, bạn có thể sử dụng mã sau:
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
my_path = '<supported-path>'
my_data = Data(
path=my_path,
type=AssetTypes.URI_FOLDER,
description="<description>",
name="<name>",
version='<version>'
)
ml_client.data.create_or_update(my_data)
Khi phân tích tài sản dữ liệu thư mục URI dưới dạng dữ liệu nhập trong công việc Máy học của Azure, trước tiên bạn cần đọc dữ liệu trước khi có thể làm việc với dữ liệu đó.
Hãy tưởng tượng bạn tạo một tập lệnh Python mà bạn muốn chạy như một công việc và bạn đặt giá trị của tham số đầu vào input_data là tài sản dữ liệu thư mục URI (chỉ đến nhiều tệp CSV). Bạn có thể đọc tất cả các tệp CSV trong thư mục và ghép nối chúng, điều bạn có thể làm bằng cách bao gồm mã sau đây trong tập lệnh Python của mình:
import argparse
import glob
import pandas as pd
parser = argparse.ArgumentParser()
parser.add_argument("--input_data", type=str)
args = parser.parse_args()
data_path = args.input_data
all_files = glob.glob(data_path + "/*.csv")
df = pd.concat((pd.read_csv(f) for f in all_files), sort=False)
Tùy thuộc vào loại dữ liệu bạn đang làm việc, mã mà bạn sử dụng để đọc tệp có thể thay đổi.
Tạo tài sản dữ liệu MLTable
Tài nguyên dữ liệu MLTable cho phép bạn trỏ đến dữ liệu dạng bảng. Khi bạn tạo tài sản dữ liệu MLTable, bạn chỉ định định nghĩa sơ đồ để đọc dữ liệu. Khi sơ đồ đã được xác định và lưu trữ cùng với tài sản dữ liệu, bạn không phải xác định cách đọc dữ liệu khi sử dụng sơ đồ.
Vì vậy, bạn muốn sử dụng một tài sản dữ liệu MLTable khi lược đồ của dữ liệu của bạn là phức tạp hoặc thay đổi thường xuyên. Thay vì thay đổi cách đọc dữ liệu trong mọi tập lệnh sử dụng dữ liệu, bạn chỉ phải thay đổi dữ liệu trong chính nội dung dữ liệu đó.
Khi bạn xác định sơ đồ khi tạo tài sản dữ liệu MLTable, bạn cũng có thể chọn chỉ xác định một tập hợp con của dữ liệu.
Đối với một số tính năng nhất định trong Azure Machine Learning, chẳng hạn như Học Máy Tự động, bạn cần sử dụng tài sản dữ liệu MLTable, vì Azure Machine Learning cần biết cách đọc dữ liệu.
Để xác định sơ đồ, bạn có thể bao gồm tệp MLTable trong cùng một thư mục với dữ liệu bạn muốn đọc. Tệp MLTable bao gồm đường dẫn trỏ đến dữ liệu bạn muốn đọc và cách đọc dữ liệu:
type: mltable
paths:
- pattern: ./*.txt
transformations:
- read_delimited:
delimiter: ','
encoding: ascii
header: all_files_same_headers
Mẹo
Tìm hiểu thêm về cách tạo tệp MLTable và chuyển đổi nào bạn có thể đưa vào tệp.
Để tạo tài sản dữ liệu MLTable với Python SDK, bạn có thể sử dụng mã sau đây:
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
my_path = '<path-including-mltable-file>'
my_data = Data(
path=my_path,
type=AssetTypes.MLTABLE,
description="<description>",
name="<name>",
version='<version>'
)
ml_client.data.create_or_update(my_data)
Khi phân tích cú pháp tài sản dữ liệu MLTable dưới dạng dữ liệu đầu vào đến tập lệnh Python mà bạn muốn chạy dưới dạng công việc Học Máy Azure, bạn có thể đưa vào mã sau đây để đọc dữ liệu:
import argparse
import mltable
import pandas
parser = argparse.ArgumentParser()
parser.add_argument("--input_data", type=str)
args = parser.parse_args()
tbl = mltable.load(args.input_data)
df = tbl.to_pandas_dataframe()
print(df.head(10))
Một cách tiếp cận phổ biến là chuyển đổi dữ liệu dạng bảng thành khung dữ liệu Gấu trúc. Tuy nhiên, bạn cũng có thể chuyển đổi dữ liệu sang khung dữ liệu Spark nếu điều đó phù hợp hơn với khối lượng công việc của bạn.