Phân loại là gì?
nhị phân phân loại với hai loại. Ví dụ, chúng tôi có thể ghi nhãn bệnh nhân là không tiểu đường hoặc bệnh tiểu đường.
Dự đoán lớp được thực hiện bằng cách xác định xác xác suất cho mỗi lớp có thể là một giá trị từ 0 (không thể) đến 1 (nhất định). Tổng xác suất cho tất cả các lớp luôn là 1, vì bệnh nhân chắc chắn là bệnh tiểu đường hoặc không tiểu đường. Vì vậy, nếu xác suất dự đoán của bệnh nhân tiểu đường là 0,3, thì có xác suất tương ứng là 0,7 mà bệnh nhân không bị tiểu đường.
Giá trị ngưỡng, thường là 0,5, được dùng để xác định lớp được dự đoán. Nếu nhóm (trong trường hợp này là bệnh tiểu đường) có xác suất dự đoán lớn hơn ngưỡng, thì dự đoán phân loại tiểu đường.
Đào tạo và đánh giá mô hình phân loại
Phân loại là một ví dụ về kỹ thuật máy học được giám sát của, có nghĩa là kỹ thuật này dựa trên dữ liệu bao gồm các giá trị tính năng đã biết và các giá trị nhãn biết. Trong ví dụ này, các giá trị tính năng là các phép đo chẩn đoán cho bệnh nhân và các giá trị nhãn là phân loại bệnh tiểu đường hoặc tiểu đường. Thuật toán phân loại được sử dụng để khớp một tập hợp con dữ liệu vào một hàm có thể tính xác suất cho mỗi nhãn lớp từ các giá trị tính năng. Dữ liệu còn lại được sử dụng để đánh giá mô hình bằng cách so sánh các dự đoán nó tạo ra từ các tính năng với các nhãn lớp đã biết.
Một ví dụ đơn giản
Chúng ta hãy khám phá một ví dụ để giúp giải thích các nguyên tắc chính. Giả sử chúng tôi có dữ liệu bệnh nhân sau đây, bao gồm một tính năng duy nhất (mức đường huyết) và nhãn lớp 0 cho bệnh nhân tiểu đường, 1 cho bệnh tiểu đường.
| Blood-Glucose | Tiểu đường |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 115 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
Chúng tôi sử dụng tám quan sát đầu tiên để đào tạo một mô hình phân loại, và chúng tôi bắt đầu bằng cách vẽ tính năng đường huyết (x) và nhãn bệnh tiểu đường dự đoán (y).
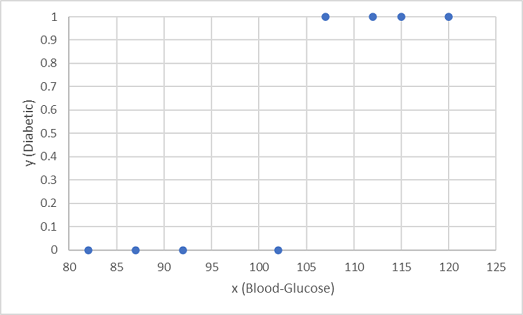
Những gì chúng ta cần là một hàm tính toán giá trị xác suất cho y dựa trên x (nói cách khác, chúng ta cần hàm f(x) = y). Bạn có thể nhìn thấy từ biểu đồ mà bệnh nhân có mức đường trong máu thấp là tất cả không tiểu đường, trong khi bệnh nhân có mức đường trong máu cao hơn là bệnh tiểu đường. Nó có vẻ như cao hơn mức độ glucose trong máu, nhiều khả năng đó là một bệnh nhân tiểu đường, với điểm inflection đang ở đâu đó giữa 100 và 110. Chúng ta cần khớp một hàm tính toán giá trị từ 0 đến 1 cho y các giá trị này.
Một hàm như vậy là hậu, tạo thành một đường cong hình sigmoidal (S).
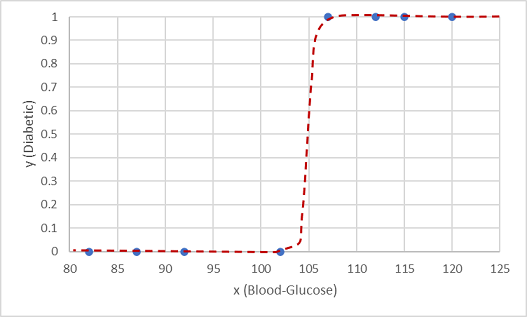
Bây giờ chúng ta có thể sử dụng hàm để tính toán giá trị xác suất y là dương, nghĩa là bệnh nhân tiểu đường, từ bất kỳ giá trị nào của x bằng cách tìm điểm trên đường hàm của x. Chúng tôi có thể đặt giá trị ngưỡng là 0,5 làm điểm cắt cho dự đoán nhãn lớp.
Chúng ta hãy kiểm tra nó với hai giá trị dữ liệu mà chúng ta giữ lại.
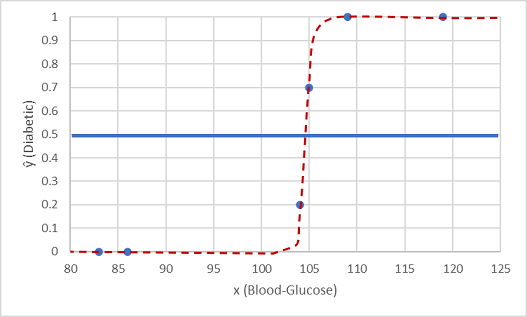
Điểm được vẽ bên dưới đường ngưỡng cho kết quả là lớp dự đoán bằng 0 (không phải bệnh tiểu đường) và các điểm trên đường này được dự đoán là 1 (tiểu đường).
Bây giờ chúng ta có thể so sánh các dự đoán nhãn (, hoặc "y-hat"), dựa trên hàm logistic được đóng gói trong mô hình, với các nhãn lớp thực tế (y).
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |