Tìm hiểu Spark
Để hiểu rõ hơn về cách xử lý và phân tích dữ liệu bằng Apache Spark trong Azure Databricks, điều quan trọng là phải hiểu kiến trúc cơ bản.
Tổng quan ở mức cao
Từ một cấp độ cao, dịch vụ Azure Databricks khởi chạy và quản lý các cụm Apache Spark trong đăng ký Azure của bạn. Apache Spark cụm là các nhóm máy tính được coi là một máy tính duy nhất và xử lý việc thực hiện các lệnh được phát hành từ máy tính xách tay. Cụm cho phép xử lý dữ liệu được song song hóa trên nhiều máy tính để cải thiện quy mô và hiệu suất. Chúng bao gồm trình điều khiển Spark và nút nhân viên. Nút trình điều khiển gửi công việc đến các nút nhân viên và hướng dẫn họ kéo dữ liệu từ một nguồn dữ liệu được chỉ định.
Trong Databricks, giao diện sổ tay thường là chương trình trình điều khiển. Chương trình trình điều khiển này chứa vòng lặp chính cho chương trình và tạo bộ dữ liệu phân tán trên cụm, sau đó áp dụng các hoạt động cho những tập dữ liệu. Các chương trình trình trình điều khiển truy cập Apache Spark thông qua một đối tượng SparkSession bất kể vị trí triển khai.
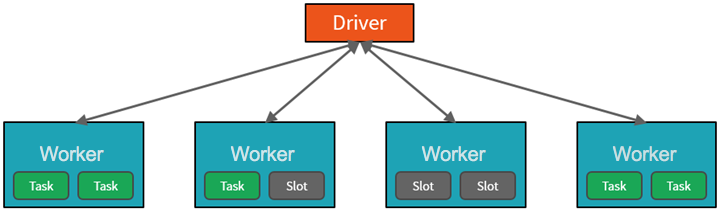
Microsoft Azure quản lý cụm và tự động co giãn cụm khi cần thiết dựa trên mức sử dụng của bạn và cài đặt được sử dụng khi đặt cấu hình cụm. Bạn cũng có thể bật tự động chấm dứt, cho phép Azure chấm dứt cụm sau một số phút không hoạt động cụ thể.
Công việc tạo tia lửa chi tiết
Công việc gửi đến cụm được chia thành nhiều công việc độc lập khi cần thiết. Đây là cách hoạt động được phân phối qua các nút của Cluster. Công việc tiếp tục được chia thành các nhiệm vụ. Đầu vào công việc được phân vùng thành một hoặc nhiều phân vùng. Các phân vùng này là đơn vị làm việc cho mỗi khe cắm. Giữa các tác vụ, phân vùng có thể cần được tổ chức lại và chia sẻ qua mạng.
Bí quyết cho hiệu năng cao của Spark là song song. Co giãn theo chiều dọc (bằng cách thêm tài nguyên vào một máy tính duy nhất) bị giới hạn trong một lượng hữu hạn RAM, Luồng và tốc độ CPU; nhưng các cụm co giãn theo chiều ngang, thêm nút mới vào cụm nếu cần.
Tia lửa song song hóa công việc ở hai cấp độ:
- Cấp độ song song đầu tiên là trình thực thi - một máy ảo Java (JVM) chạy trên một nút nhân viên, thường là một phiên bản cho mỗi nút.
- Mức song song thứ hai là khe - số lượng được xác định bởi số lõi và CPU của mỗi nút.
- Mỗi người thực thi có nhiều khe để giao các nhiệm vụ song song.
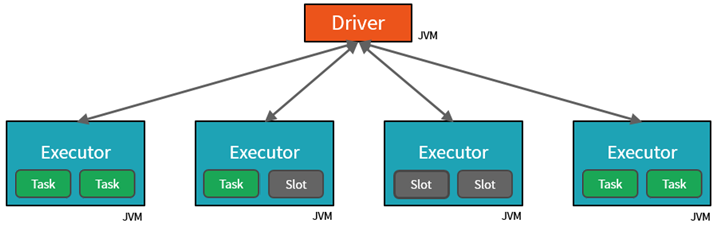
JVM là tự nhiên đa luồng, nhưng một JVM duy nhất, chẳng hạn như một trong những điều phối công việc trên trình điều khiển, có một giới hạn hữu hạn trên. Bằng cách tách công việc thành các tác vụ, trình điều khiển có thể giao đơn vị công việc cho *khe trong các thực thi trên nút nhân viên để thực hiện song song. Ngoài ra, trình điều khiển xác định làm thế nào để phân vùng dữ liệu để nó có thể được phân phối cho xử lý song song. Vì vậy, trình điều khiển gán một phân vùng dữ liệu cho từng tác vụ để mỗi tác vụ biết cần xử lý phần dữ liệu nào. Sau khi bắt đầu, mỗi tác vụ sẽ tải phân vùng dữ liệu được gán cho phân vùng đó.
Công việc và giai đoạn
Tùy thuộc vào công việc đang được thực hiện, có thể yêu cầu nhiều công việc song song. Mỗi công việc được chia thành các giai đoạn. Một tương tự hữu ích là tưởng tượng rằng công việc là xây dựng một ngôi nhà:
- Giai đoạn đầu tiên sẽ là đặt nền tảng.
- Giai đoạn thứ hai sẽ là dựng tường.
- Giai đoạn thứ ba sẽ là để thêm mái nhà.
Cố gắng thực hiện bất kỳ bước nào trong số các bước này không có ý nghĩa và trên thực tế có thể là không thể. Tương tự, Spark chia từng công việc thành các giai đoạn để đảm bảo mọi thứ được thực hiện theo đúng thứ tự.
Mô-đun
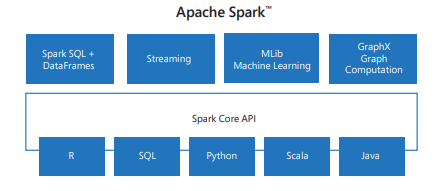
Spark bao gồm các thư viện cho các tác vụ từ SQL đến phát trực tuyến và máy học, làm cho nó trở thành một công cụ cho các tác vụ xử lý dữ liệu. Một số thư viện Spark bao gồm:
- Spark SQL: Để làm việc với dữ liệu có cấu trúc.
- SparkML: Dành cho máy học.
- GraphX: Để xử lý đồ thị.
- Spark Streaming: Để xử lý dữ liệu trong thời gian thực.
Tính tương thích
Tia lửa có thể chạy trên nhiều hệ thống phân tán khác nhau, bao gồm Hadoop YARN, Apache Mesos, Kubernetes hoặc quản lý cụm của riêng Spark. Nó cũng đọc từ và viết cho các nguồn dữ liệu đa dạng như HDFS, Cassandra, HBase và Amazon S3.