Trực quan hóa dữ liệu
Một trong những cách trực quan nhất để phân tích kết quả của truy vấn dữ liệu là trực quan hóa chúng dưới dạng biểu đồ. Sổ tay trong Azure Databricks cung cấp khả năng lập biểu đồ trong giao diện người dùng và khi chức năng đó không cung cấp những gì bạn cần, bạn có thể sử dụng một trong nhiều thư viện đồ họa Python để tạo và hiển thị trực quan hóa dữ liệu trong sổ tay.
Sử dụng biểu đồ sổ tay dựng sẵn
Khi bạn hiển thị khung dữ liệu hoặc chạy truy vấn SQL trong sổ tay Spark trong Azure Databricks, kết quả sẽ được hiển thị bên dưới ô mã. Theo mặc định, kết quả được kết xuất dưới dạng bảng, nhưng bạn cũng có thể xem kết quả dưới dạng trực quan hóa và tùy chỉnh cách biểu đồ hiển thị dữ liệu, như minh họa ở đây:
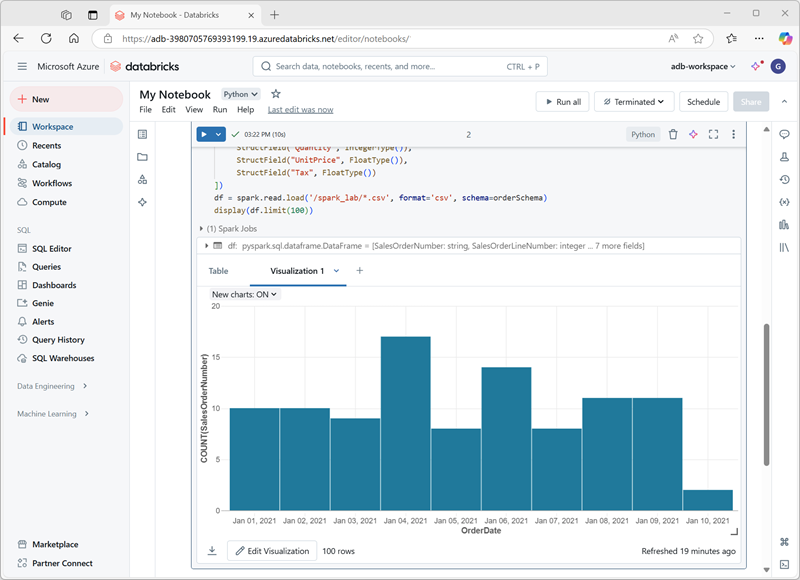
Chức năng trực quan hóa tích hợp sẵn trong sổ tay rất hữu ích khi bạn muốn nhanh chóng tóm tắt dữ liệu một cách trực quan. Khi bạn muốn có thêm quyền kiểm soát cách dữ liệu được định dạng hoặc để hiển thị các giá trị mà bạn đã tổng hợp trong truy vấn, bạn nên cân nhắc sử dụng gói đồ họa để tạo trực quan hóa của riêng mình.
Sử dụng gói đồ họa trong mã
Có nhiều gói đồ họa mà bạn có thể sử dụng để tạo trực quan hóa dữ liệu trong mã. Đặc biệt, Python hỗ trợ một lựa chọn lớn của các gói; hầu hết trong số họ được xây dựng trên cơ sở thư viện Matplotlib . Đầu ra từ thư viện đồ họa có thể được kết xuất trong sổ tay, giúp dễ dàng kết hợp mã để kiểm nhập và thao tác dữ liệu với trực quan hóa dữ liệu nội tuyến và các ô đánh dấu để cung cấp chú thích.
Ví dụ: bạn có thể sử dụng mã PySpark sau đây để tổng hợp dữ liệu từ dữ liệu sản phẩm giả thuyết được khám phá trước đó trong mô-đun này và sử dụng Matplotlib để tạo biểu đồ từ dữ liệu tổng hợp.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Thư viện Matplotlib yêu cầu dữ liệu nằm trong khung dữ liệu Pandas chứ không phải khung dữ liệu Spark, vì vậy phương pháp toPandas được sử dụng để chuyển đổi nó. Sau đó mã sẽ tạo ra một hình với kích cỡ được chỉ định và vẽ biểu đồ thanh với một số cấu hình thuộc tính tùy chỉnh trước khi hiển thị biểu đồ kết quả.
Biểu đồ được mã tạo ra sẽ trông giống như hình ảnh sau đây:
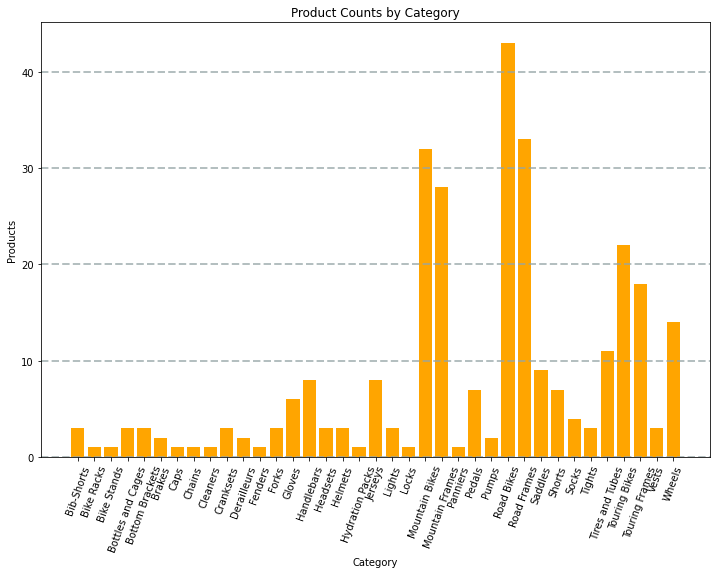
Bạn có thể sử dụng thư viện Matplotlib để tạo ra nhiều loại biểu đồ; hoặc nếu được ưu tiên, bạn có thể sử dụng các thư viện khác như Seaborn để tạo ra các biểu đồ tùy chỉnh cao.
Lưu ý
Các thư viện Matplotlib và Seaborn có thể đã được cài đặt trên cụm Databricks, tùy thuộc vào Databricks Runtime cho cụm. Nếu không, hoặc nếu bạn muốn sử dụng một thư viện khác chưa được cài đặt, bạn có thể thêm nó vào cụm. Xem Thư viện cụm trong tài liệu Azure Databricks để biết chi tiết.