你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure Container Apps无需管理底层基础结构即可按需访问 GPU。 作为无服务器功能,只需为正在使用的 GPU 付费。 启用此功能后,应用所使用的 GPU 数量会根据应用程序的负载需求而增减。 通过无服务器 GPU,你可以使用自动缩放、优化的冷启动、按秒计费来无缝运行工作负载,并在不使用时缩减到零,从而减少运营开销。
无服务器 GPU 仅支持消费型工作负载配置文件。 仅消耗环境不支持此功能。
注意
必须请求 GPU 配额才能访问 GPU。 可以通过客户支持案例提交 GPU 配额请求。
优点
使用 GPU 时,无服务器 GPU 可让你专注于核心 AI 代码,减少对基础结构的管理,从而加速 AI 开发。 此功能提供 Foundry 模型目录的无服务器 API 与托管计算环境中的模型之间的一种中间层解决方案。
容器应用的无服务器 GPU 支持提供了全面的数据管理,因为数据始终保留在容器的边界内,同时仍然提供一个托管的无服务器平台,用于构建你的应用程序。
在容器应用中使用无服务器 GPU 时,应用将获得以下功能:
缩放到零 GPU:支持 NVIDIA A100 和 NVIDIA T4 GPU 的自动无服务器缩放。
按秒计费:仅为使用的 GPU 计算付费。
内置的数据管理:数据始终保留在容器边界内。
灵活的计算选项:可以在 NVIDIA A100 或 T4 GPU 类型之间进行选择。
用于 AI 开发的中间层:在托管的无服务器计算平台上使用自带模型。
常见方案
以下方案描述了无服务器 GPU 的常见用例。
实时和批处理推理:使用具有快速启动时间、自动缩放和每秒计费模型的自定义开源模型。 无服务器 GPU 非常适用于动态应用程序。 只需为使用的计算付费,应用会自动横向扩展和缩减以满足需求。
机器学习场景:显著加速实现了微调自定义生成式 AI 模型、深度学习、神经网络或大规模数据分析的应用程序。
High-Performance 计算(HPC):在需要复杂计算和模拟的应用程序(如科学计算、财务建模或天气预报)中使用 GPU 作为高计算需求的资源。
呈现和可视化:使用 GPU 加速呈现过程,并在涉及 3D 渲染、图像处理或视频转码的应用程序中启用实时可视化。
大数据分析:GPU 可以加速大规模数据集中的数据处理和分析。
注意事项
使用无服务器 GPU 时,请记住以下事项:
CUDA 版本:无服务器 GPU 支持最新的 CUDA 版本。
支持限制:
- 应用中一次只能有一个容器使用 GPU。 如果应用中有多个容器,则第一个容器可以访问 GPU。
- 多个应用可以共享同一个 GPU 工作负载配置文件,但每个应用都需要自己的副本。
- 不支持多 GPU 副本和部分 GPU 副本。
- 应用程序中的第一个容器将获得对 GPU 的访问权限。
IP 地址:当你将无服务器 GPU 与自己的虚拟网络集成时,每个副本使用一个 IP 地址。
支持的区域
无服务器 GPU 在以下区域中可用:
| 区域 | A100 | T4 |
|---|---|---|
| 澳大利亚东部 | 是的 | 是的 |
| Brazil South | 是的 | 是的 |
| 印度中部 | 否 | 是的 |
| 加拿大中部 | 是的 | 是的 |
| 美国东部 | 是的 | 是的 |
| 法国中部 | 否 | 是的 |
| 意大利北部 | 是的 | 是的 |
| 日本东部 | 否 | 是的 |
| 美国中北部 | 否 | 是的 |
| 美国中南部 | 否 | 是的 |
| 东南亚 | 否 | 是的 |
| 印度南部 | 否 | 是的 |
| 瑞典中部 | 是的 | 是的 |
| 西欧1 | 否 | 是的 |
| 美国西部 | 是的 | 是的 |
| 美国西部 2 | 否 | 是的 |
| 美国西部 3 | 是的 | 是的 |
1 若要在西欧添加 T4 无服务器 GPU 工作负荷配置文件,必须在该区域中创建新的工作负荷配置文件环境。
使用无服务器 GPU
通过 Azure 门户创建容器应用时,可以将容器设置为使用 GPU 资源。
在创建过程的“容器”选项卡中,进行以下设置:
在 “容器资源分配 ”部分下,选中 GPU 复选框。
对于 GPU 类型,请选择 NVIDIA A100 或 NVIDIA T4 选项。
管理无服务器 GPU 工作负载配置文件
无服务器 GPU 在消耗 GPU 工作负载配置文件上运行。 可以像管理任何其他工作负载配置文件一样管理消耗 GPU 工作负载配置文件。 可以使用 CLI 或 Azure 门户来管理工作负荷配置文件。
请求无服务器 GPU 配额
注意
默认情况下,具有企业协议和即用即付客户的客户已启用 A100 和 T4 配额。
需要无服务器 GPU 配额才能访问此功能。 可以通过客户支持案例提交 GPU 配额请求。 打开 GPU 配额请求的支持案例时,请选择以下选项:
在 Azure 门户中打开 New 支持请求表单。
在窗体中输入以下值:
资产 价值 问题类型 选择 “服务和订阅限制”(配额) Subscription 选择订阅。 配额类型 选择“容器应用”。 选择“下一步”。
在“ 其他详细信息 ”窗口中,选择“ 输入详细信息 ”以打开请求详细信息窗口。
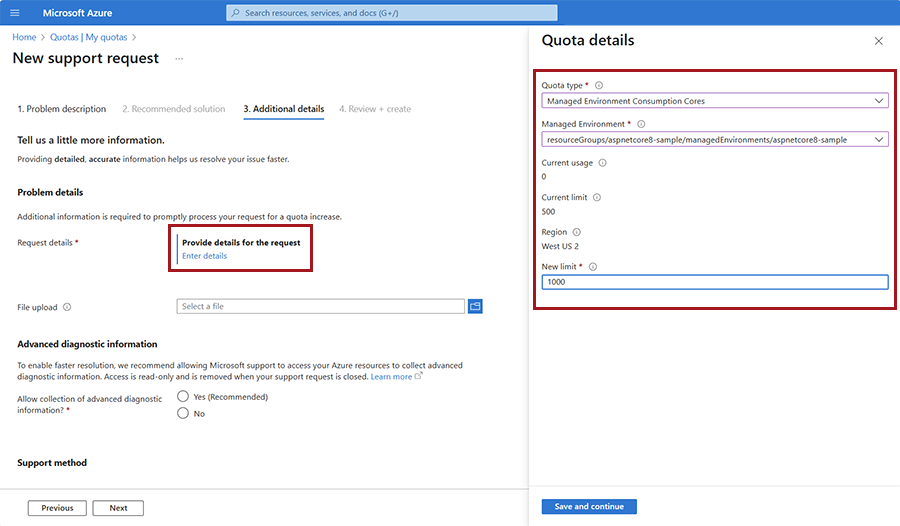
对于“配额类型”,请选择“托管环境消耗 NCA100 Gpu”或“托管环境消耗 T4 Gpu”。 输入其他值。
选择“保存并继续”。
在 “其他详细信息 ”窗口中填写其余相关详细信息。
选择“下一步”。
选择 创建。
改进 GPU 冷启动
可以通过在存储装载中启用工件流式处理和查找大型文件(如大型语言模型)来显著改善冷启动时间。
制品流:Azure 容器注册表提供镜像流功能,可显著加快镜像启动时间。 要使用生成工件流式处理,必须将容器映像托管在高级 Azure 容器注册表中。
存储挂载:通过将大文件存储在与容器应用相关联的 Azure 存储帐户中,减少网络延迟的影响。
将 Foundry 模型部署到无服务器 GPU (预览版)
Azure Container Apps无服务器 GPU 现在支持公共预览版Microsoft Foundry 模型。 Foundry 模型有两个部署选项:
Azure Container Apps无服务器 GPU 提供无服务器 API 与托管计算之间的均衡部署选项,用于部署 Foundry 模型。 此选项是按需的,无服务器缩放在未使用且符合数据驻留需求时可缩减为零。 利用无服务器 GPU,Foundry 模型为您提供灵活性,让您可以运行任何受支持的模型。它支持自动扩展、按秒计费、全面的数据治理,以及开箱即用的企业级网络和安全支持。
支持该类型 MLFLOW 的语言模型。 若要查看模型列表 MLFLOW ,请转到 azureml 注册表中可用的模型列表。 若要查找模型,请使用以下步骤为 MLFLOW 模型添加筛选器:
选择筛选器。
选择“添加筛选器”。
对于筛选器规则,请输入 Type = MLFLOW。
对于 Azure Container Apps 存储库中列出的模型,无需使用以下 CLI 命令生成自己的映像即可将其直接部署到无服务器 GPU:
az containerapp up \
--name <CONTAINER_APP_NAME> \
--location <LOCATION> \
--resource-group <RESOURCE_GROUP_NAME> \
--model-registry <MODEL_REGISTRY_NAME> \
--model-name <MODEL_NAME> \
--model-version <MODEL_VERSION>
对于不在此列表中的任何模型,需要:
从 Azure Container Apps 仓库下载模型图片的 GitHub 模板。
修改 score.py 文件以匹配模型类型。 评分脚本(命名 为 score.py)定义如何与模型交互。 以下示例演示如何 使用自定义 score.py 文件。
生成映像并将其部署到容器注册表。
使用以前的 CLI 命令将模型部署到无服务器 GPU,但指定
--image。 使用--model-registry、--model-name和--model-version参数时,会为你设置关键环境变量,以优化应用的冷启动。
提交反馈
将问题提交到 Azure Container Apps GitHub 存储库。