适用于:![]() Azure Synapse Analytics
Azure Synapse Analytics![]() 分析平台系统 (PDW)
分析平台系统 (PDW)
CREATE TABLE AS SELECT (CTAS)是可用的最重要的T-SQL特性之一。 它是根据 SELECT 语句的输出创建新表的完全并行化操作。 CTAS 是创建表副本最便捷的方法。
例如,使用 CTAS:
- 重新创建具有不同哈希分布列的表。
- 重新创建一个表作为复制表。
- 只在表的某些列上创建列存储索引。
- 查询或导入外部数据。
注意
由于 CREATE TABLE AS SELECT (CTAS)增加了创建表格的能力,本主题尽量避免重复该 CREATE TABLE 主题。 相反,它描述了CTAS和 CREATE TABLE之间的区别。
- Microsoft Fabric 中的仓库支持 CTAS。 查看 Fabric 版本的“作为选择创建表格”条目。
- Azure Synapse Analytics 中的无服务器 SQL 池不支持此语法。
-
CREATE TABLE AS SELECT(CTAS)在 Microsoft Fabric 的仓库中得到支持。 更多信息请参见 本文的Fabric Data Warehouse版本。
语法
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
参数
更多信息请参见 中的论证部分CREATE TABLE。
列选项
column_name [,...n ]
列名不允许使用中提到的CREATE TABLE。 相反,可以为新表提供包含一个或多个列名的可选列表。 新表中的列使用指定的名称。 指定列名时,列表中的列数必须与所选结果中的列数相匹配。 如果未指定任何列名,新的目标表将使用 select 语句结果中的列名。
不能指定任何其他列选项,例如数据类型、排序规则或为 Null 性。 每个属性都派生自 SELECT 语句的结果。 但可以使用 SELECT 语句来更改属性。 有关示例,请参阅使用 CTAS 更改列属性。
表分发选项
有关详情及如何选择最佳分布列,请参阅 中的表格分配选项部分。CREATE TABLE 有关根据实际使用情况或示例查询为表选择分发的建议,请参阅 Azure Synapse SQL 中的分发顾问。
DISTRIBUTION
=
HASH (distribution_column_name)|ROUND_ROBIN |复制
CTAS语句需要分配选项,没有默认值。 这就不同于具有默认值的 CREATE TABLE。
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
根据最多八列的哈希值分配行,允许基表数据更均匀分布,减少数据偏斜并提升查询性能。
注意
- 若要启用该功能,请使用此命令将数据库的兼容性级别更改为 50。 有关设置数据库兼容性级别的详细信息,请参阅 ALTER DATABASE SCOPED CONFIGURATION。 例如:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - 若要禁用多列分布 (MCD) 功能,请运行此命令,将数据库的兼容性级别更改为 AUTO。 例如:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;现有 MCD 表将保持不变,但会变得不可读。 对 MCD 表的查询将返回以下错误:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- 若要重新获得对 MCD 表的访问权限,请再次启用此功能。
- 要将数据加载到 MCD 表中,使用 CTAS 语句,数据源需要是 Synapse SQL 表。
- 不支持 MCD HEAP 目标表上的 CTAS。 请改用 INSERT SELECT 作为将数据加载到 MCD HEAP 表中的解决方法。
- 目前支持使用 SSMS 生成脚本来创建 MCD 表,SSMS 版本 19 除外。
有关详情及如何选择最佳分布列,请参阅 中的表格分配选项部分。CREATE TABLE
有关基于工作负载使用的最佳分发的建议,请参阅 Synapse SQL 分发顾问(预览版)。
表分区选项
即使已对源表进行分区,CTAS 语句也会默认创建一个非分区表。 若要使用 CTAS 语句创建已分区表,必须指定分区选项。
详情请参见 中的 “表划分选项 ”部分 CREATE TABLE。
SELECT 语句
SELECT 语句是 CTAS 和 CREATE TABLE 之间的根本区别。
WITH
common_table_expression
指定临时命名的结果集,这些结果集称为公用表表达式 (CTE)。 有关详细信息,请参阅 WITH common_table_expression (Transact-SQL)。
SELECT
select_criteria
使用 SELECT 语句的结果填充新表。 select_criteria 是 SELECT 语句的主体,用于确定将哪些数据复制到新表中。 有关 SELECT 语句的信息,请参阅 SELECT (Transact-SQL)。
查询提示
用户可以将 MAXDOP 设置为一个整数值,以控制最大并行度。 当 MAXDOP 设置为 1 时,由单线程执行查询。
权限
CTAS 需要 select_criteria 中引用的任何对象的 SELECT 权限。
关于创建表的权限,请参见 中的权限。CREATE TABLE
备注
详情请参见一般性备注。CREATE TABLE
限制和局限
有关限制和限制的更多细节,请参见 中的“限制与限制”。CREATE TABLE
可以在 Azure Synapse Analytics 支持的任何数据类型的列(字符串列除外)上创建有序的聚集列存储索引。
SET ROWCOUNT (Transact-SQL) 对 CTAS 没有影响。 要实现类似的行为,请使用 TOP (Transact-SQL)。
CTAS 不支持函数
OPENJSON作为语句的SELECT一部分。 作为替代方法,请使用INSERT INTO ... SELECT。 例如:DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
锁定行为
详情请参见 Lock Behavior 中的 CREATE TABLE。
性能
对于哈希分布式表,可使用 CTAS 选择其他分布列,提高联接和聚合性能。 如果目标不是选择其他分布列,那么指定相同的分布列可获得最佳 CTAS 性能,因为这样可以避免重新分布行。
如果使用 CTAS 创建表,并且不考虑性能,则可以指定 ROUND_ROBIN 来避免选定分布列。
若要避免数据在后续查询中发生移动,可指定 REPLICATE,但代价是增加了在每个计算节点上加载表的完整副本所用的存储。
复制表的示例
A. 使用 CTAS 复制表
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
CTAS 最常见的用途之一就是创建表副本,使你可以更改 DDL。 例如,如果最初将表创建为 ROUND_ROBIN,现在希望将其更改为分布在列上的表,则可以使用 CTAS 更改分布列。
CTAS 还可用于更改分区、索引或列类型。
假设你通过指定 HEAP 并使用默认分布类型 ROUND_ROBIN 创建了此表。
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
现在,你想使用聚集列存储索引创建此表的新副本,以便可以利用聚集列存储表的性能。 你还想在 ProductKey 上分布此表(因为预期此列会发生联接)并在联接 ProductKey 期间避免数据移动。 最后,你还想在 OrderDateKey 上添加分区,以便通过删除旧分区来快速删除旧数据。 下面是将旧表复制到新表的 CTAS 语句:
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
最后,可通过重新命名表来交换新表,然后删除旧表。
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
列选项的示例
B. 使用 CTAS 更改列属性
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
本示例使用 CTAS 更改 DimCustomer2 表中多个列的数据类型、为 Null 性和排序规则。
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
最后,可使用 RENAME (Transact-SQL) 切换表名称。 这样就使得 DimCustomer2 成为新表。
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
表分发的示例
C. 使用 CTAS 更改表的分布方法
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
此简单示例介绍如何改变表的分布方法。 为显示执行此操作的机制,它将哈希分布式表更改为轮循机制表,然后将轮循机制表更改回哈希分布式表。 最终的表与原始表相匹配。
大多数情况下,无需将哈希分布式表更改为轮循机制表。 更常见的情况是,可能需要将轮循机制表更改为哈希分布式表。 例如,可能最初将新表加载为轮循机制表,然后将其移到哈希分布式表以提高联接性能。
本示例使用 AdventureWorksDW 示例数据库。 若要加载 Azure Synapse Analytics 版本,请参阅快速入门:使用 Azure 门户在 Azure Synapse Analytics 中创建和查询专用 SQL 池(以前称为 SQL DW)。
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
接下来,将其更改回哈希分布式表。
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. 使用 CTAS 将表转换为复制表
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
此示例适用于将轮循机制表或哈希分布式表转换为复制表。 此特殊示例采用先前进一步改变分布类型的方法。 由于 DimSalesTerritory 是一个维度,而且可能是较小的表,因此可以选择重新创建该表作为复制表,从而避免在联接到其他表时数据发生移动。
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. 使用 CTAS 创建列数较少的表
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
以下示例创建一个名为 myTable (c, ln) 的轮循机制分布式表。 新表仅包含两列。 它使用 SELECT 语句中的列别名作为列名。
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
查询提示的示例
F. 在 CREATE TABLE AS SELECT (CTAS) 中使用查询提示
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
此查询显示在 CTAS 语句中使用查询联接提示的基本语法。 提交查询后,Azure Synapse Analytics 在为每个单独的分布生成查询计划时应用哈希联接策略。 有关哈希联接查询提示的详细信息,请参阅 OPTION 子句 (Transact-SQL)。
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
外部表的示例
G. 使用 CTAS 从 Azure Blob 存储导入数据
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
若要从外部表导入数据,请使用 CREATE TABLE AS SELECT 从外部表进行选择。 从外部表选择数据到 Azure Synapse Analytics 中的语法与从常规表中选择数据的语法相同。
以下示例针对 Azure Blob 存储帐户中的数据定义外部表。 然后,它使用 CREATE TABLE AS SELECT 从外部表进行选择。 这样会从 Azure Blob 存储文本分隔文件导入数据,并将数据存储到新的 Azure Synapse Analytics 表中。
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. 使用 CTAS 从外部表导入 Hadoop 数据
适用范围:Analytics Platform System (PDW)
若要从外部表导入数据,只需使用 CREATE TABLE AS SELECT 从外部表进行选择。 从外部表选择数据到 Analytics Platform System (PDW) 中的语法与从常规表中选择数据的语法相同。
以下示例针对 Hadoop 群集定义外部表。 然后,它使用 CREATE TABLE AS SELECT 从外部表进行选择。 这样会从 Hadoop 文本分隔文件导入数据,并将数据存储到新的 Analytics Platform System (PDW) 表中。
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
使用 CTAS 替换 SQL Server 代码的示例
使用 CTAS 解决某些不支持的功能。 除了能够在数据仓库上运行代码之外,通过重写现有代码来使用 CTAS 通常还可以提高性能。 这是因为采用了完全并行化设计。
注意
尽量考虑“CTAS 优先”。 如果你认为可以使用 CTAS 解决问题,那么这通常是解决问题的最佳方法(即使你会因此编写更多数据)。
I. 使用 CTAS 而不是 SELECT..INTO
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
SQL Server 代码通常借助 SELECT..INTO 来使用 SELECT 语句的结果填充表。 这是 SQL Server SELECT..INTO 语句的一个例子。
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
Azure Synapse Analytics 和并行数据仓库不支持此语法。 本示例显示如何将之前的 SELECT..INTO 语句重写为 CTAS 语句。 你可以选择 CTAS 语法中描述的任何 DISTRIBUTION 选项。 本示例使用 ROUND_ROBIN 分布方法。
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. 使用 CTAS 简化 merge 语句
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
使用 CTAS 可以替换(至少部分替换)Merge 语句。 可以将 INSERT 和 UPDATE 合并为一个语句。 在第二个语句中需要关闭任何已删除的记录。
UPSERT 的示例如下:
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. 显式声明数据类型和输出是否可为 null
适用范围:Azure Synapse Analytics 和 Analytics Platform System (PDW)
将 SQL Server 代码迁移到 Azure Synapse Analytics 时,可能会遇到这种类型的编码模式:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
你可能会本能地认为应将此代码迁移到 CTAS,这无疑是正确的。 但是,这里有一个隐含的问题。
以下代码不会生成相同的结果:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
注意,“结果”列会沿用表达式的数据类型和为 Null 性值。 稍有不慎,可能就会导致值存在细微差异。
请尝试以下示例:
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
为结果存储的值不相同。 由于在其他表达式中使用了结果列中保留的值,因此差异会更大。
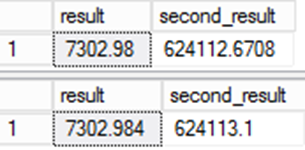
这对于数据迁移非常重要。 尽管第二个查询看起来更准确,但仍有一个问题。 该数据与源系统相比有所不同,会导致迁移过程出现完整性问题。 这是一种“错误”答案实际上为正确答案的罕见情况!
我们发现这两种结果之间出现这种差异的原因是隐式类型转换。 在第一个示例中,表定义了列定义。 插入行时会发生隐式类型转换。 在第二个示例中未发生隐式类型转换,因为表达式定义列的数据类型。 另请注意,第二个示例中的列已定义为可为 Null 的列,而第一个示例中并未如此。 在第一个示例中创建表时,显式定义了列的为 Null 性。 在第二个示例中,将它留给表达式,在默认情况下会产生 NULL 定义。
若要解决这些问题,必须在 SELECT 语句的 CTAS 部分中显式设置类型转换和为 Null 性。 在创建表的部分无法设置这些属性。
此示例演示如何修复代码:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
请注意,在此示例中:
- 可能使用了 CAST 或 CONVERT。
- 使用了 ISNULL 而不是 COALESCE 强制为 Null 性。
- ISNULL 是最外层的函数。
- ISNULL 的第二个部分是常量,即
0。
注意
为正确设置为 Null 性,请务必使用 ISNULL 而不是 COALESCE。
COALESCE 不是确定性函数,因此表达式的结果将始终可以为 NULL。
ISNULL 则不同。 它是确定性的。 因此,当 ISNULL 函数的第二部分是常数或文本时,结果值将为 NOT NULL。
该提示不仅有助于确保计算的完整性。 它对于表格分区切换也很重要。 试想根据实际情况定义此表:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
但值字段是一个计算表达式,不是源数据的一部分。
若要创建分区数据集,请考虑以下示例:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
该查询将会顺利运行。 尝试执行分区切换时,将出现问题。 表定义不匹配。 若要使表定义匹配,需对 CTAS 进行修改。
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
因此,你会发现类型一致性和维持 CTAS 上的为 Null 性属性是优秀工程设计的最佳做法。 它有助于保持计算的完整性,而且还可确保实现分区切换。
L. 创建有序聚集列存储索引,同时将 MAXDOP 设为 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
相关内容
CREATE TABLE AS SELECT (CTAS)是可用的最重要的T-SQL特性之一。 它是根据 SELECT 语句的输出创建新表的完全并行化操作。 CTAS 是创建表副本最便捷的方法。
例如,在 Microsoft Fabric 中的仓库中使用 CTAS,可以:
- 使用源表的某些列创建表副本。
- 创建一个表,该表是联接其他表的查询的结果。
有关在 Microsoft Fabric 中的仓库上使用 CTAS 的详细信息,请参阅使用 Transact-SQL 将数据引入仓库。
注意
由于 CREATE TABLE AS SELECT (CTAS)增加了创建表的能力,该主题尽量避免重复CREATE TABLE主题。 相反,它描述了CTAS和 CREATE TABLE之间的区别。
语法
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
) WITH (CLUSTER BY [ ,... n ])
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
参数
有关常见参数的详细信息,请参见 Microsoft Fabric 的 CREATE TABLE 中的参数。
其中 (群集 由 [ ,...n])
CLUSTER BY Fabric Data Warehouse 中的数据聚类条款要求至少指定一个列用于数据聚类,最多四列。
更多信息请参见 Fabric Data Warehouse 中的数据聚类。
SELECT 语句
该 SELECT 陈述是CTAS和 CREATE TABLE之间的根本区别。
精选 select_criteria
用语句的结果 SELECT 填充新表。
select_criteria 是确定哪些数据要复制到新表的语句正文 SELECT 。 有关账单的信息 SELECT ,请参见 SELECT(Transact-SQL)。
注意
在 Microsoft Fabric 中,不允许在 CTAS 中使用变量。
权限
CTAS 需要 select_criteria 中引用的任何对象的 SELECT 权限。
关于创建表的权限,请参见 中的权限。CREATE TABLE
备注
详情请参见一般性备注。CREATE TABLE
限制和局限
SET ROWCOUNT (Transact-SQL) 对 CTAS 没有影响。 要实现类似的行为,请使用 TOP (Transact-SQL)。
详情 请参 见 CREATE TABLE。
锁定行为
详情请参见 Lock Behavior 中的 CREATE TABLE。
复制表的示例
有关在 Microsoft Fabric 中使用仓库的 CTAS 的详细信息,请参阅 使用 Transact-SQL 在 Microsoft Fabric 中将数据引入仓库。
A. 使用 CTAS 更改列属性
本示例使用 CTAS 更改 DimCustomer2 表中多个列的数据类型和为 Null 性。
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. 使用 CTAS 创建列数较少的表
以下示例创建名为 myTable (c, ln) 的表。 新表仅包含两列。 它使用 SELECT 语句中的列别名作为列名。
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. 使用 CTAS 而不是 SELECT..INTO
SQL Server 代码通常借助 SELECT..INTO 来使用 SELECT 语句的结果填充表。 这是 SQL Server SELECT..INTO 语句的一个例子。
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
本示例显示如何将之前的 SELECT..INTO 语句重写为 CTAS 语句。
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. 使用 CTAS 简化 merge 语句
使用 CTAS 可以替换(至少部分替换)Merge 语句。 可以将 INSERT 和 UPDATE 合并为一个语句。 在第二个语句中需要关闭任何已删除的记录。
UPSERT 的示例如下:
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
D. 创建带有数据聚类的表
使用以下命令创建新表 CREATE TABLE AS SELECT (CTAS),并指定数据聚类列:
CREATE TABLE nyctlc_With_DataClustering
WITH (CLUSTER BY (lpepPickupDatetime))
AS SELECT * FROM nyctlc;
更多信息请参见 Fabric Data Warehouse 中的数据聚类。