查看要求之后,您可以开始创建文档处理模型了。
使用向导创建模型
您可以使用创建自定义模型向导创建文档处理模型。 该向导将指导您完成创建模型以从文档中提取信息的过程。
登录到 Power Apps 或 Power Automate。
在左侧窗格中,选择 ... 更多>AI 中心。
(可选)要将人工智能模型永久保留在菜单上以方便访问,请选择 AI 中心旁边的大头针图标。
在发现 AI 能力下,选择 AI 模型。
选择从文档中提取自定义信息。
选择创建自定义模型。
分步向导将要求您列出要从文档中提取的所有数据,从而引导您完成该过程。
更多信息,请参阅本文的选择文档类型部分。
如果希望使用自己的文档创建模型,请确保至少有五个使用相同布局的示例。 否则,可以使用示例数据来创建模型。
选择训练。
通过选择快速测试来测试模型。
选择文档的类型
在选择文档类型步骤中,选择要构建 AI 模型以自动提取数据的文档类型。 有三个选项:固定模板文档、一般文档和发票。
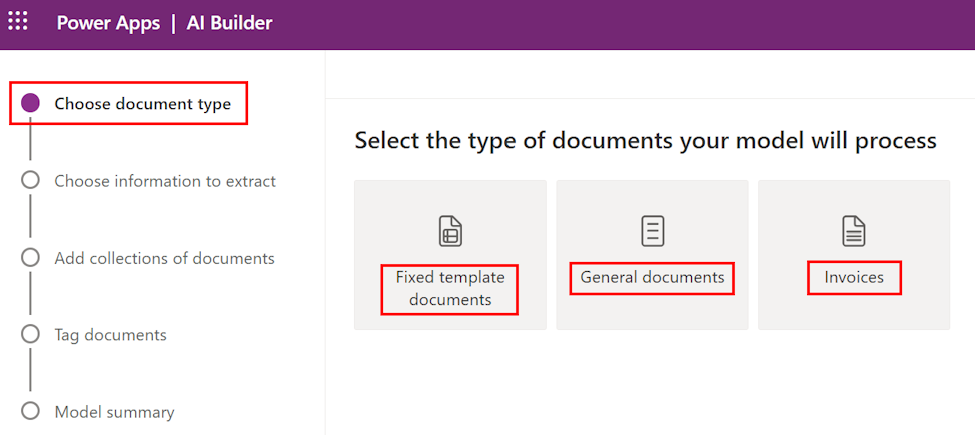
- 固定模板文档:以前称为结构化文档,对于给定的布局,当字段、表格、复选框、签名和其他项目可以在相似的位置找到时,此选项是非常理想的选择。 您可以教该模型从具有不同布局的结构化文档中提取数据。 该模型的训练时间很快。
- 常规文档:以前称为非结构化文档,此选项适用于任何类型的文档,尤其是没有固定结构或格式复杂的文档。 您可以教该模型从具有不同布局的结构化或非结构化文档中提取数据。 该模型功能强大,但训练时间长。
- 发票:通过添加在默认情况下没有提取的新字段或无法正确提取的文档示例来增强预生成发票处理模型的行为。
了解文档智能版本
文档智能模型有两个版本:v4.0 和 v3.1。 模型的版本取决于上次编辑模型的时间。
文档智能 v4.0 - 正式发布(GA)
除了本文中列出的功能外,v4.0 还保留了 v3.1 的所有功能。
- 重叠字段:v4.0 版支持自定义模型中的重叠字段,可让您更有效地从具有复杂布局的文档中提取信息。
- 签名检测:v4.0 版可检测文档中的签名,这对于合同、协议和其他已签名表单尤其有用。
- 表格的置信度得分:v4.0 版为表格及其单元格提供置信度得分。
- OCR 引擎改进:v4.0 改进了光学字符识别 (OCR) 引擎,提高了文本识别准确率,并支持更多文档类型和格式。
文档智能 v3.1 正式发布(GA)
- v3.1 支持经过训练的自定义模型,以识别特定的数据模式,例如唯一的文本字段或结构。
- v3.1 包括自定义模板模型,允许用户根据其文档布局和结构创建模板。
检查模型版本
您可以验证用于训练和发布模型的版本。 为此,请选择设置>发布的模型版本>上次训练的模型版本。
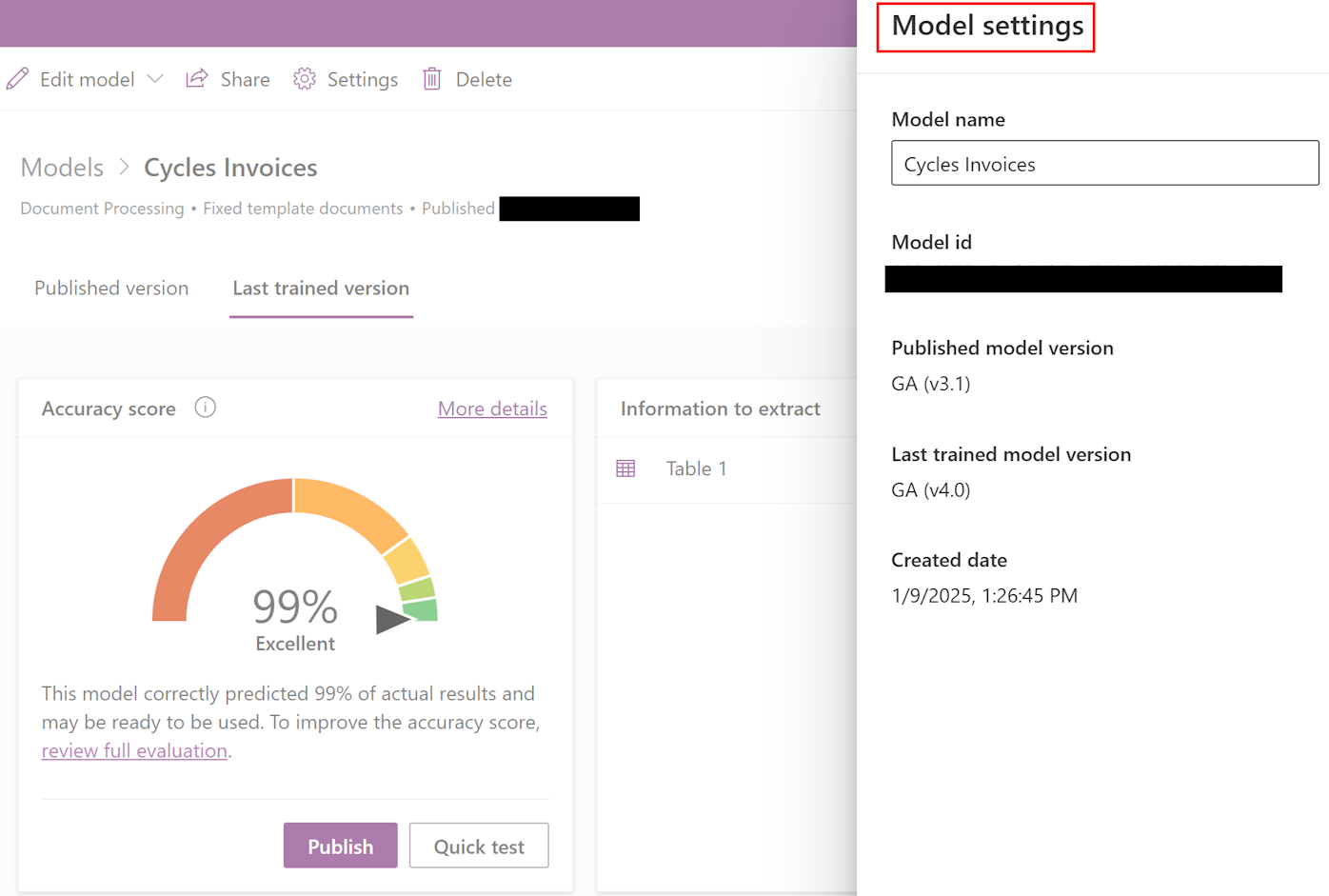
您可以通过编辑、重新训练和发布模型将模型从 v3.1 移动到 v4.0。 无需重新标记和其他特定修改。 更多信息,请参阅文档处理常见问题。
定义要提取的信息
在选择要提取的信息屏幕上,定义希望训练模型提取的字段、表和复选框。 要开始定义这些内容,请选择 +添加。
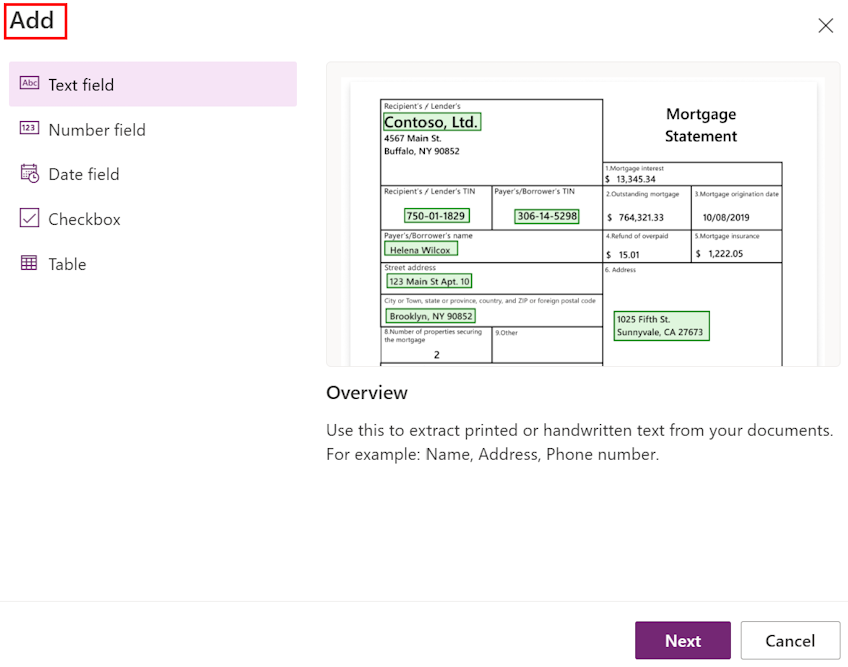
对于每个文本字段,提供要在模型中使用的字段名称。
对于每个数字字段,请提供要在模型中使用的字段名称。
可以将格式句点 (.) 或逗号 (,) 定义为小数分隔符。
对于每个日期字段,提供要在模型中使用的字段名称。
此外,还可以定义格式(年、月、日)、或(月、日、年)、或(日、月、年)。
对于每个复选框,请提供该复选框在模型中使用的名称。
为可以在文档中检查的每个项目定义单独的复选框。
对于每个表,请提供该表的名称。
定义模型应提取的不同列。
备注
自定义发票模型附带有无法编辑的默认字段。
按集合对文档进行分组
集合是一组共享相同布局的文档。 应创建与您希望模型处理的文档布局同样多的集合。 例如,如果您正在构建一个 AI 模型来处理来自两个不同供应商的发票,每个供应商都有自己的发票模板,请创建两个集合。
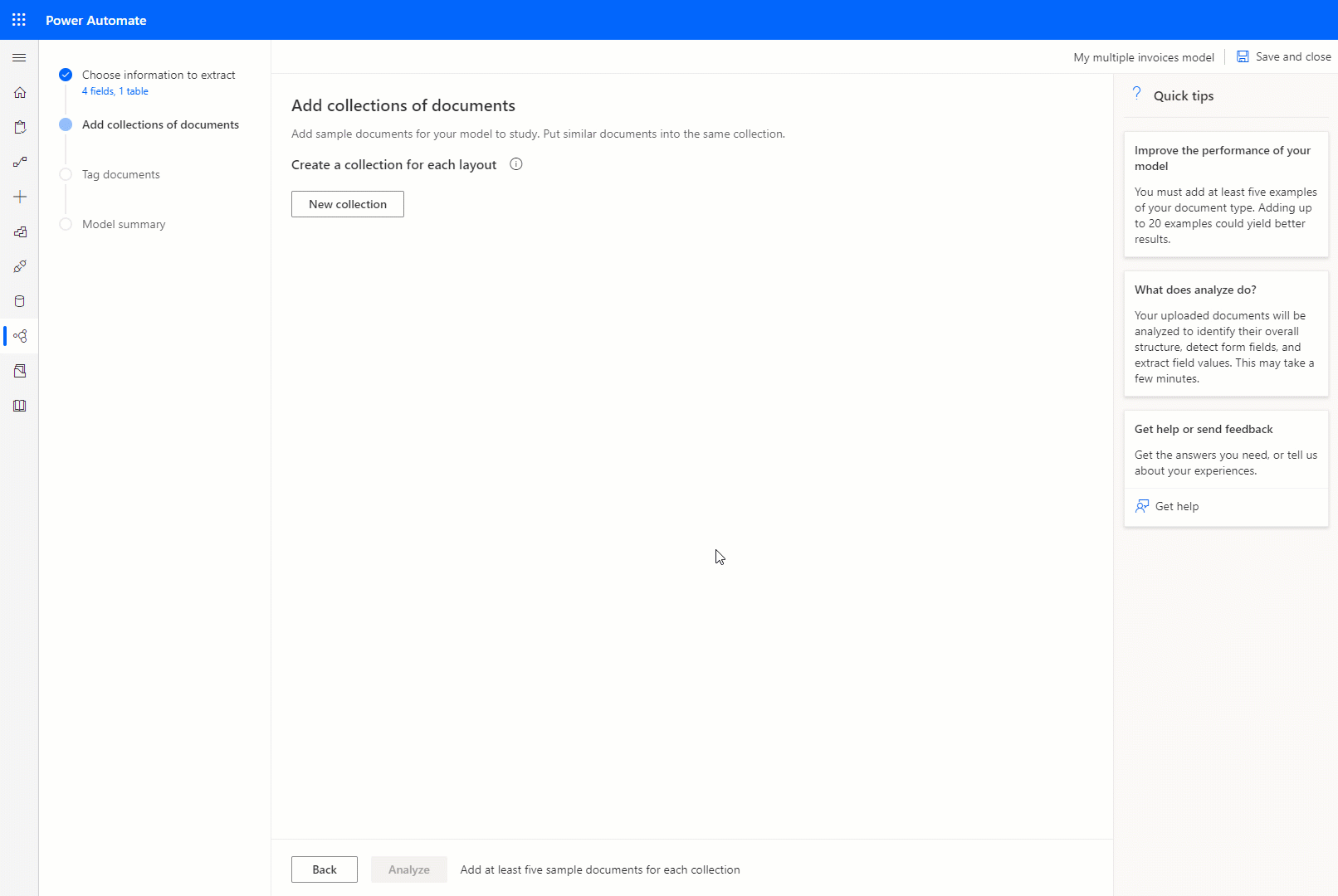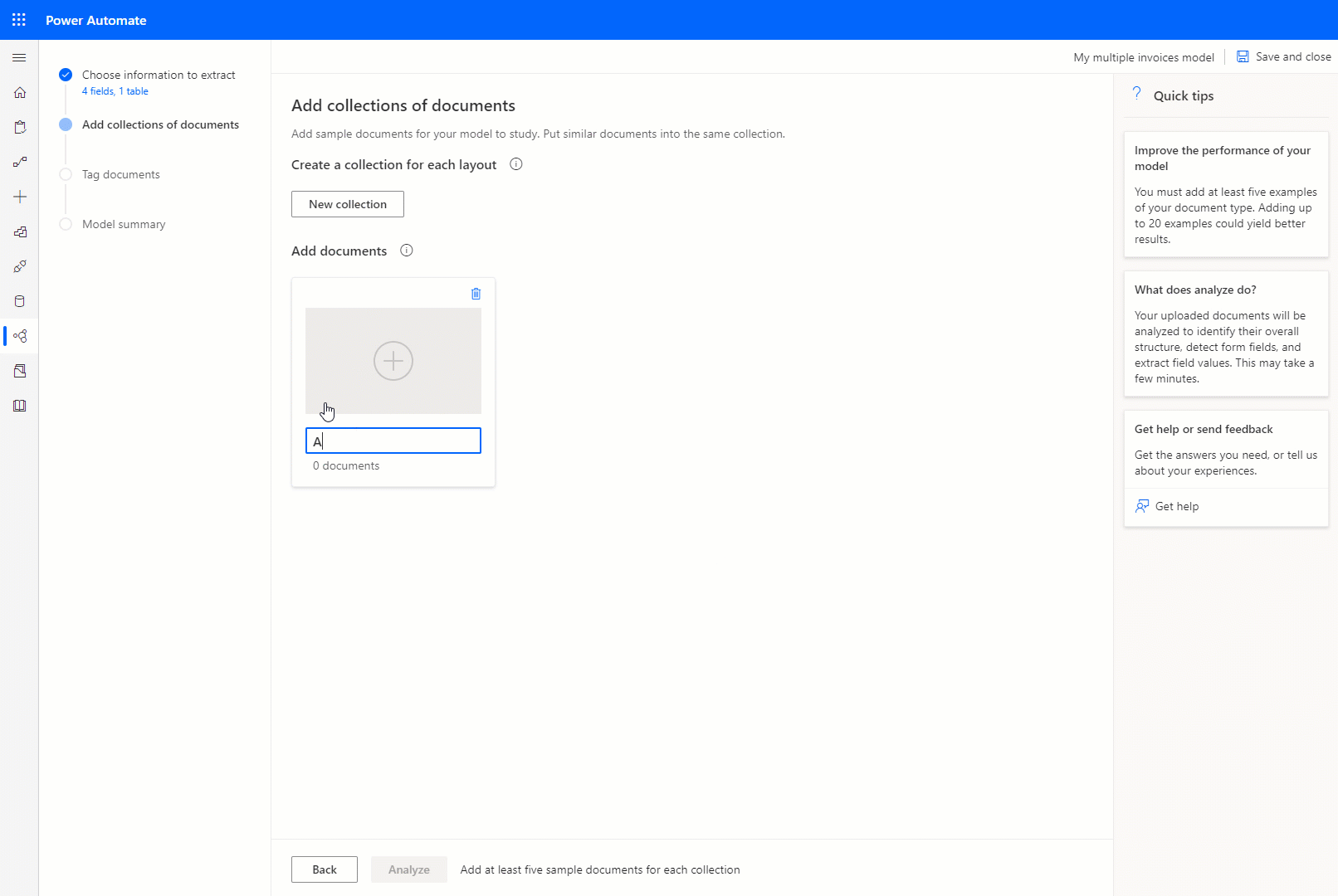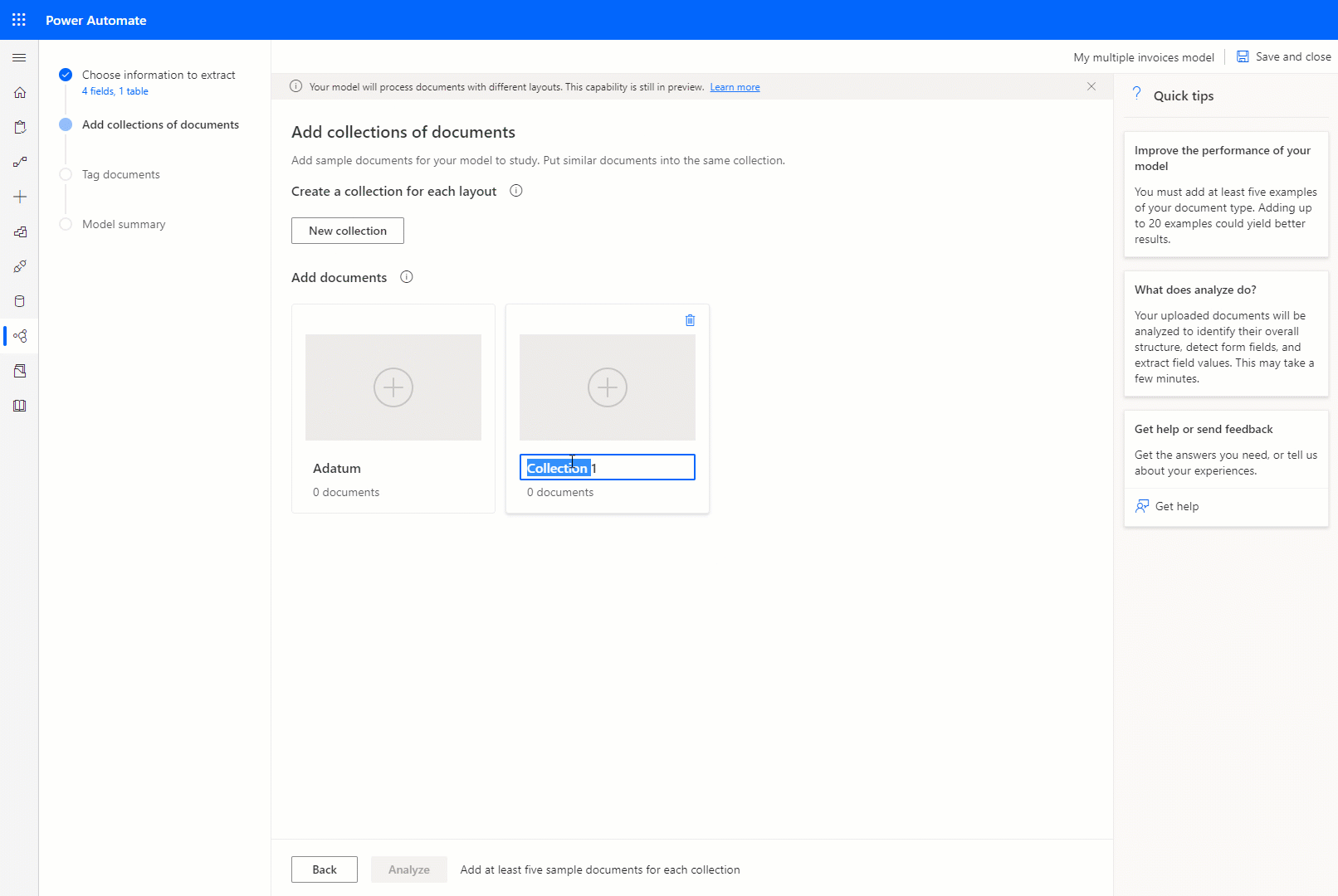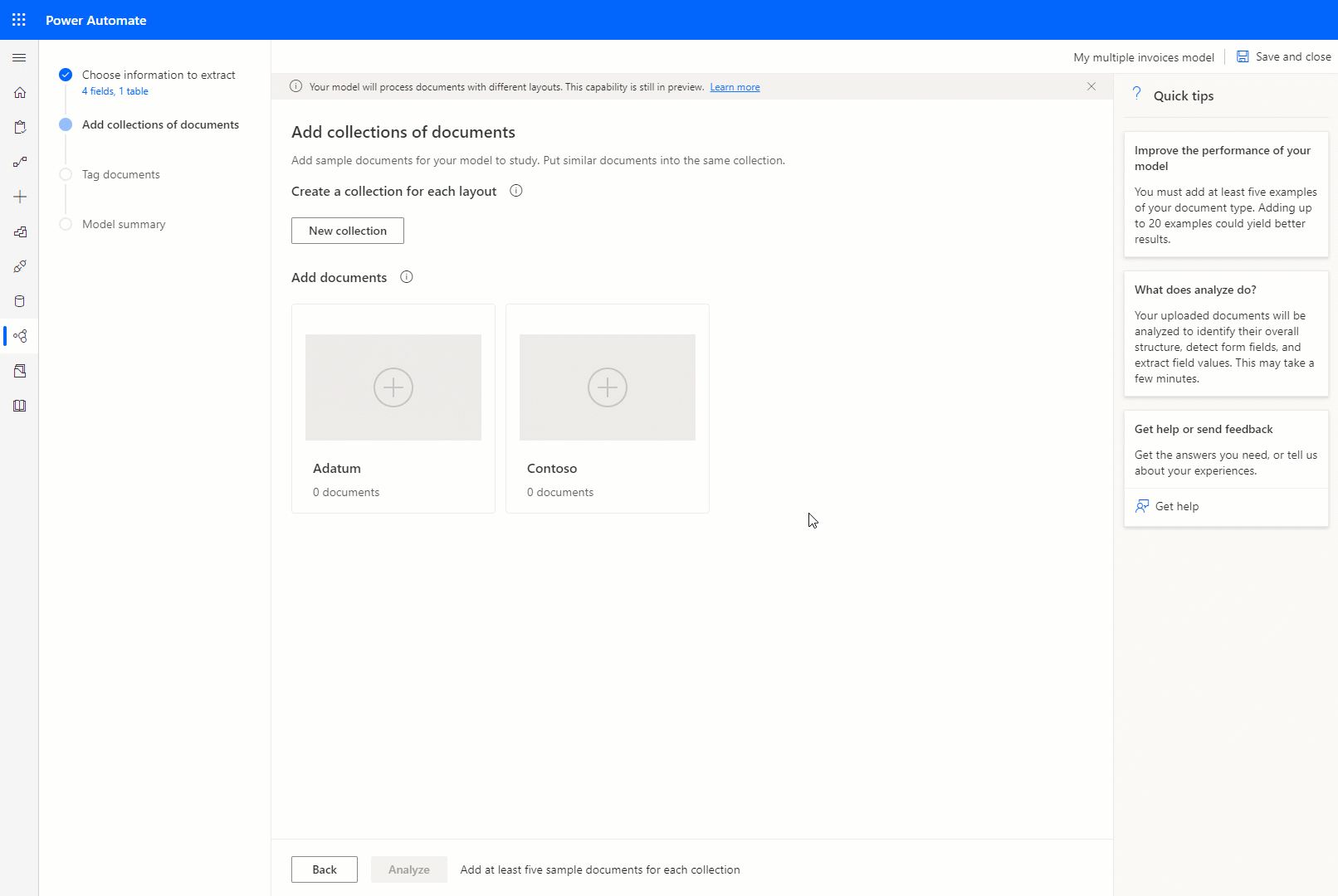
对于创建的每个集合,您需要为每个集合至少上载五个示例文档。 接受 JPG、PNG 和 PDF 格式的文件。
备注
每个模型最多可以创建 200 个集合。