
Overview
This article discusses the Security planning for the sample Retail-mart application. It shows the architecture, data flow diagram and overlays security weaknesses on the data flows for the example application. These artifacts are intended as examples only, so they are subject to change in accordance with your scenario. Each of the labeled entities in the figures below is accompanied by meta-information, which describes the following items:
- Azure Services
- Data Flow between services
- Threats
- Security controls recommendations
Discretion and resilience are essential qualities for AI models to effectively navigate complex and sensitive tasks, ensuring they can make informed decisions and maintain performance in challenging environments. More details can be found below under the Discretion heading. In addition to the security controls recommended in this plan, you're advised to have robust defense mechanisms implemented using SIEM and SOC tools.
Application overview
Retail-mart is a fictional retail corporation that stands as a symbol of innovation, customer centric, and market leadership in the retail industry. With a rich history spanning several decades, Retail-mart has consistently set the standard for excellence and has become a household name, synonymous with quality and convenience.
Retail-mart operates a diverse range of retail products, catering to the diverse needs of its customers. Whether it's groceries, clothing, jewelry or DIY (Do it yourself) construction products, the convenience stores e-commerce platform provides a seamless shopping experience. Retail-mart has a presence in every facet of the retail landscape.
The company's commitment to customer satisfaction is evident in its dedication to offering the following items:
- Top-notch product.
- Exceptional service.
- A wide array of choices to meet the demands of shoppers from all walks of life.
Retail-mart wants to embrace cutting-edge technologies by using data-driven analytics and AI-driven recommendations enhanced to ensure that customers find exactly what they need.
It's good practice to assess security risks when using Large Language Models (LLMs) in high-risk and autonomous scenarios. LLMs may be biased, fabricate/hallucinate information, have reasoning errors, and struggle at certain tasks. They are susceptible to various type of attacks as explained in this article. Some examples of attacks are prompt injection, jailbreak attacks, and data poisoning attacks.
This security planning will highlight the security risks associated with the sample solution architecture. It will also highlight the security controls that will reduce the likelihood and severity of the security risks.
Diagrams
Architecture diagram
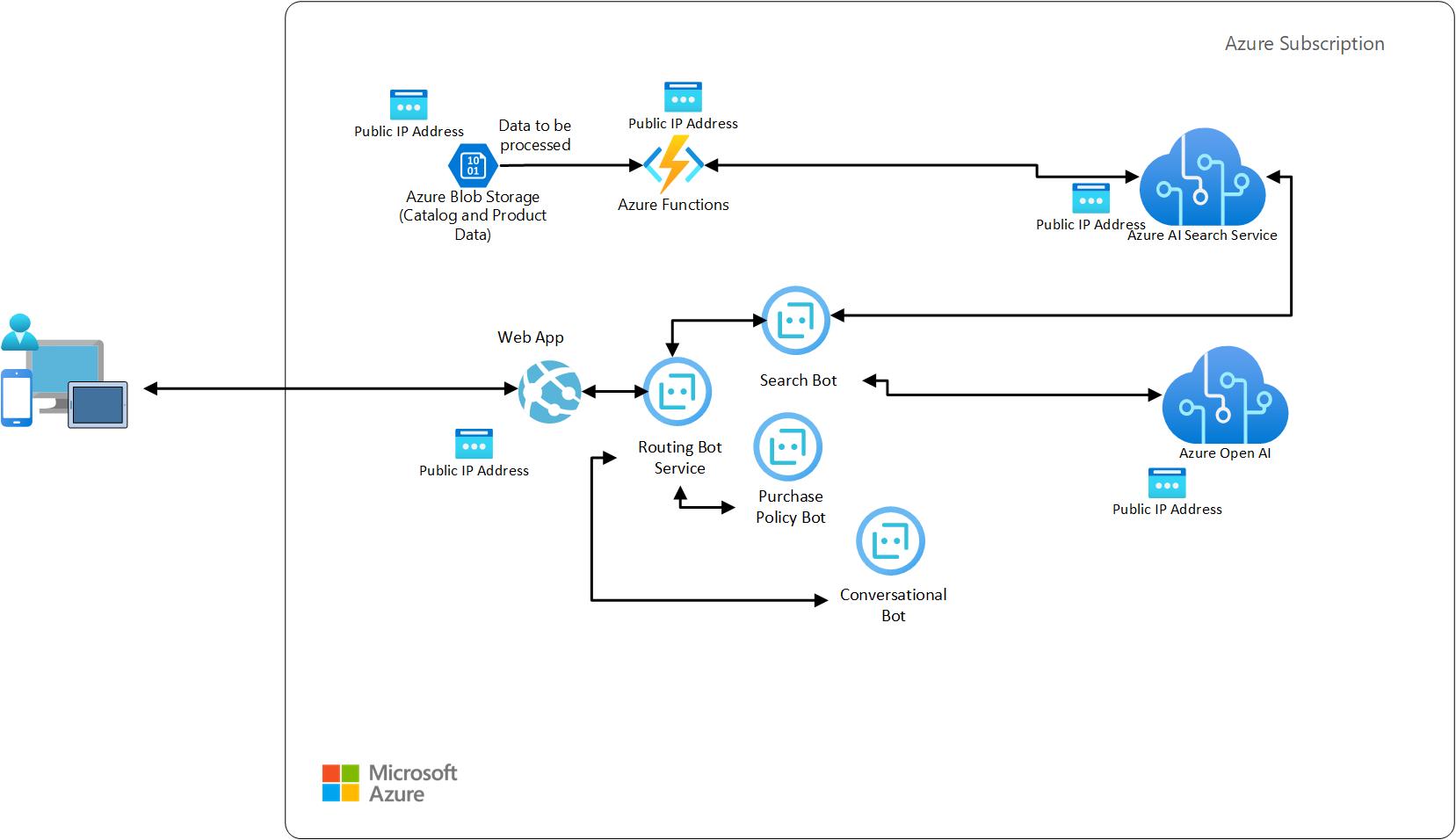 |
|---|
| Figure 1: Architecture Diagram |
Data Flow Diagram
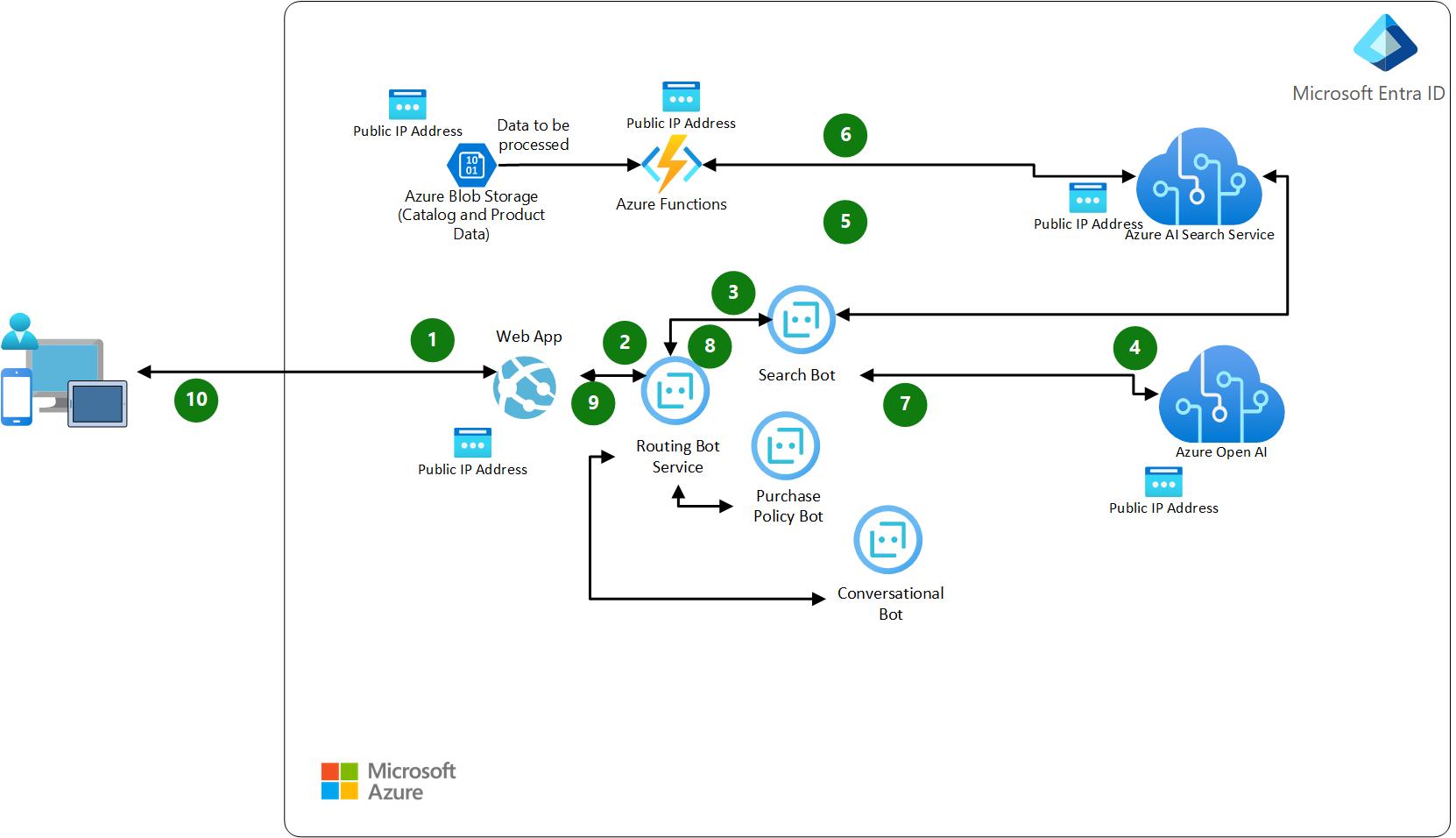 |
|---|
| Figure 2: Data Flow Diagram |
Data Flow Diagram
Scenario - Prompt flow/ prompt inputs requiring search /RAG Pattern Sequence
- User of the chatbot application enters prompt input in chatbot UI
- Request is forwarded to backend application
- Backend application determines the intent of the user input prompt and forwards the request to routing bot service along with derived intent
- Routing microservice forwards the request to search bot service
- Search bot queries Azure AI search to retrieve intent (context) based data
- Search bot service sends the data to Azure OpenAI model for summarization
- Search bot service returns the response to backend application
- Backend application returns the response to user
Data flow attributes
| # | Transport Protocol | Data Classification | Authentication | Authorization | Notes |
|---|---|---|---|---|---|
| 1 | HTTPS | Confidential | Entra ID | Entra Scopes | |
| 2 | HTTPS | Confidential | Entra ID | OAuth Token Exchange for authentication and authorization between the web app and the Azure Bot Service. Use the Direct Line Client SDK or make HTTP calls to the bot's endpoint from webapp by passing authorization token (OAuth token or Direct Line token) in the HTTP headers. Bot Services validates token from Entra Id. If valid, Bot service processes the request; otherwise, it rejects it. | |
| 3 | HTTPS | Confidential | Entra ID | If both bot services are configured to use the Direct Line API, they can exchange Direct Line tokens to authenticate requests. Other option is to use mutual TLS (mTLS) where both bots authenticate each other using certificates. | |
| 4 | HTTPS | Confidential | Entra ID | Configure Azure RBAC (Role-Based Access Control) to allow your bot's managed identity or Azure AD app to access the OpenAI resource. Assign roles like Azure AI Services OpenAI User to the bot's Managed identity. | |
| 5 | HTTPS | Confidential | Entra ID | Configure Azure RBAC (Role-Based Access Control) to allow your bot's managed identity or Entra ID app to access Azure AI search resource. Assign roles like Search Index Data Reader to the bot's Managed Identity. Per-user access over search results (sometimes referred to as row-level security or document-level security) isn't supported through role assignments. As a workaround, create security filters that trim results by user identity, removing documents for which the requestor shouldn't have access. | |
| 6 | HTTPS | Confidential | Entra ID | Managed Identity is the most secure and straightforward way for Azure Functions to authenticate with Azure resources like Azure AI search. Assign roles (Search Service Contributor) for authorized data plane access to Azure AI Search. | |
| 7 | HTTPS | Confidential | Entra ID | Azure RBAC | |
| 8 | HTTPS | Confidential | Entra ID | Azure RBAC | |
| 9 | HTTPS | Confidential | Entra ID | Azure RBAC | |
| 10 | HTTPS | Confidential | Entra ID | Azure RBAC |
Threat map
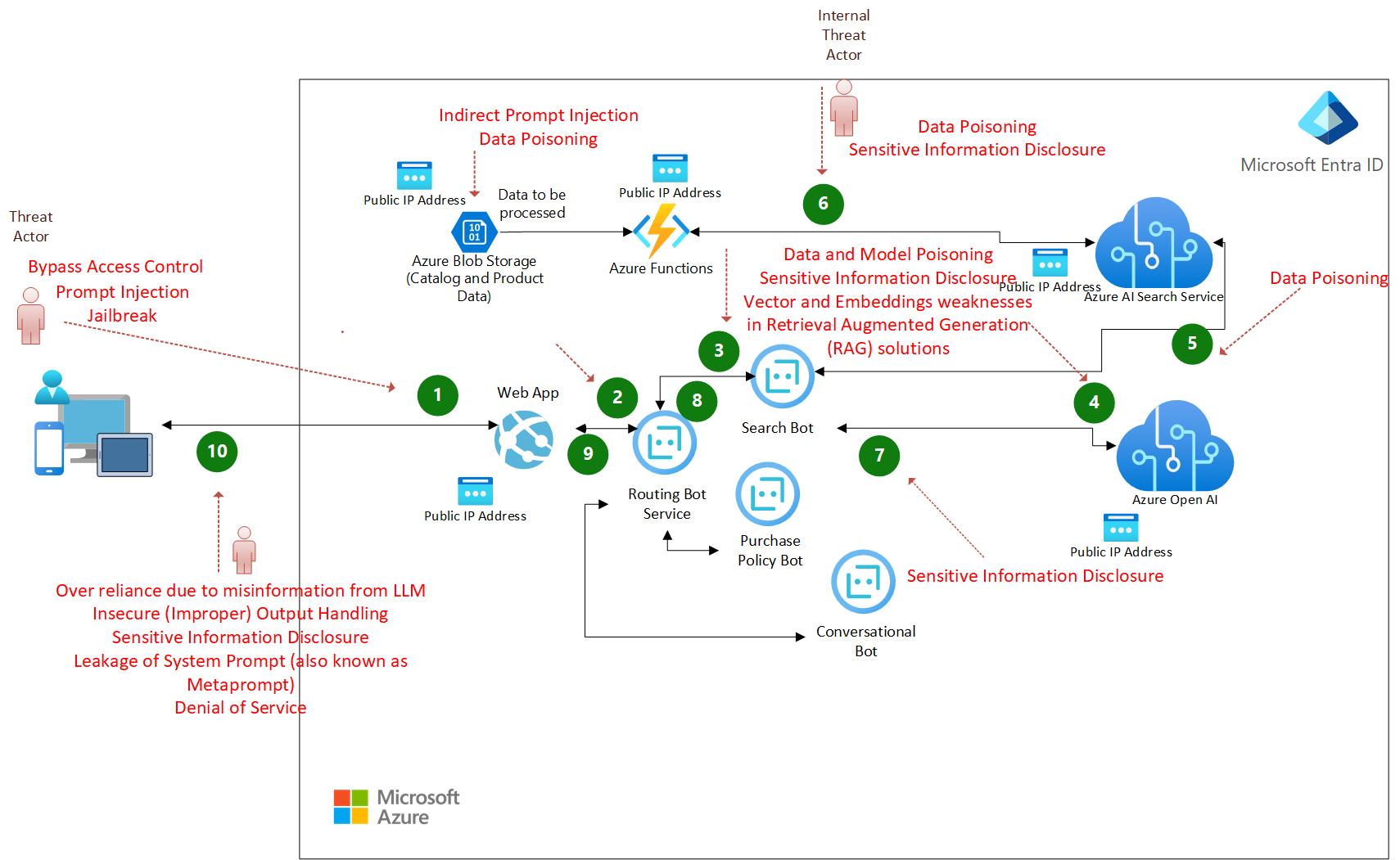 |
|---|
| Figure 3: Threat Map |
Threat properties
Threat #1: Prompt Injection
Principle: Confidentiality, integrity, availability
Threat: Users can modify the system-level prompt restrictions to "jailbreak" the LLM and overwrite previous controls in place. The modification to input prompt can be either intentional (that is, a malicious actor deliberately crafting a prompt to exploit the model) or unintentional (that is, a user inadvertently providing input that triggers unexpected behavior). Because the solution has untreated flaws, an attacker can create harmful input to make LLMs do unintended actions without knowing it. There are two types of prompt injection direct and indirect. Direct prompt injections, also known as jail breaking, occur when an attacker alters the behavior of the model in unintended or unexpected ways. The attacker can also overwrite or reveal the underlying system prompt. Jail breaking allows attackers to exploit backend systems.
Indirect prompt injections occur when LLM accepts input from external sources like websites or files. Attackers may embed a prompt injection in the external content.
Affected Asset(s) Chat Bot Service, Routing Microservice, Conversational Microservice, Azure OpenAI Model, Search API RAG Microservice.
Mitigation:
- Enforce least privilege control on LLM access to backend systems.
- Segregate external content from user prompts and limit the influence when untrusted content is used.
- Monitor user input prompt and LLM output to check that responses are as expected.
- Maintain fine user control on decision-making capabilities by LLM Model Explainability and Interpretability.
- All products and services must encrypt data in transit using approved cryptographic protocols and algorithms.
- Use Azure AI Content Safety Service for filtering prompt inputs and its responses. Consider Input Limitations for Azure Content Safety service when using it for content safety of your generative AI solution.
- Use TLS to encrypt all HTTP-based network traffic. Use other mechanisms, such as IPSec, to encrypt non-HTTP network traffic that contains customer or confidential data.
- Use only TLS 1.2 or TLS 1.3. Use ECDHE-based ciphers suites and NIST curves. Use strong keys. Enable HTTP Strict Transport Security. Turn off TLS compression and do not use ticket-based session resumption.
- Use Azure AI Foundry safety and security evaluations to systematically assess and improve your generative AI application before deploying it to production.
- Conduct adversarial testing and attack simulations.
- Use human approval (human in the loop) for high-risk actions.
- Design specific instructions through metaprompts/system prompts/system messages to limit model's role, capabilities, and limitations for context adherence, limiting responses to specific tasks or topics, and restrict the model to ignore attempts to modify system prompts/system prompt templates/metaprompts. Step-by-step authoring best practices
- Refer OWASP LLM security risk guidance for prompt injection
- Use Azure Content Safety Custom Category to filter scenario-based content filtering.
- Implement Azure Content Safety Containers that lets you use a subset of Azure AI Content Safety in your own environment to meet specific data governance requirements.
Threat #2: Sensitive Information Disclosure
Principle: Confidentiality, Privacy
Threat:
LLM applications have the potential to reveal sensitive information, proprietary algorithms, or other confidential details through their output. This revelation can produce the following results such as:
- Unauthorized access to sensitive data causing data breach or ransomware.
- Unauthorized assess to Personal Identifiable Information (PII) leading to privacy violations.
Affected asset(s) Web application, Non-Search Microservice, Search API RAG Microservice, Conversational Microservice, Browser
- Unauthorized access to sensitive data causing data breach or ransomware.
Mitigation:
- Integrate adequate data sanitization and scrubbing techniques to prevent user data from entering the training model data.
- Implement robust input validation and sanitization methods to identify and filter out potential malicious inputs. These methods will prevent the model from being poisoned when enriching the model with data. They also prevent poisoning if fine-tuning a model.
- Anything that is deemed sensitive in the fine-tuning data has the potential to be revealed to a user. Therefore, apply the rule of least privilege. Do not train the model on information that the highest-privileged user can access. This information may be displayed to a lower-privileged user.
- Access to external data sources (orchestration of data at runtime) should be limited.
- Apply strict access control methods to external data sources and a rigorous approach to maintaining a secure supply chain.
- Redact PII data from logs using tools like Microsoft Presidio
- Implement least-privilege access control for all components and services.
- Monitor data access and user activity including privileged access management across your generative AI solution.
- Build network and access security controls for all outbound operations, especially write operations.
- Use Microsoft Purview to protect sensitive data across clouds, apps, and devices.
- Encrypt sensitive data so that it is rendered difficult to exploit even when compromised by an adversary.
- Refer OWASP LLM security guidance for sensitive information disclosure
- Monitor data access and user activity including privileged access management across your generative AI solution. Use Azure AI Foundry safety and security evaluations to systematically assess and improve your generative AI application before deploying it to production.
Threat #3: Supply chain Vulnerabilities
Principle: Confidentiality, Integrity, and Availability
Threat: An attacker can exploit vulnerabilities in open source/third party packages used in generative AI development and consumption.
This threat occurs due to vulnerabilities in software components, training data, ML models or deployment platforms.
Affected asset(s) Vulnerabilities in the open-source/third party packages used for and during generative AI platform and application development could lead to an attacker exploitation of those vulnerabilities.
Mitigation:
- Use Azure Artifacts to publish and control feeds for generative AI application development that will lower the risk of supply chain vulnerability.
- Carefully vet data sources and suppliers, including T&Cs (Terms and Conditions) and their privacy policies, only using trusted suppliers. Ensure adequate and independently audited security is in place.
- Verify that model operator policies align with your data protection policies. That is, your data is not used for training their models. Microsoft Data, privacy, and security[https://learn.microsoft.com/en-us/legal/cognitive-services/openai/data-privacy?tabs=azure-portal#see-also] Similarly, seek assurances and legal mitigation against using copyrighted material from model maintainers.
- System and Services Acquisition control family that is part of NIST SP 800-53 control baseline provides control coverage for supply chain risk assessments.
- LLM-Insecure Plugin Design provides information on the LLM-aspects of Insecure Plugin design you should test against to mitigate risks from using third-party plugins.
- Maintain an up-to-date inventory of components using a Software Bill of Materials (SBOM) to ensure you have an up-to-date, accurate, and signed inventory preventing tampering with deployed packages. SBOMs can be used to detect and alert new, zero-day vulnerabilities quickly. Refer Secure Supply Chain Consumption Framework S2C2F to follow recommended guidance on processes and tools to adopt to help establish a secure open source software (OSS) ingestion pipeline.
- At the time of writing, SBOMs do not cover models, their artifacts, and datasets. If your LLM application uses its own model, you should use MLOps best practices. Use platforms offering secure model repositories with data, model, and experiment tracking.
- Use model and code signing when using external models and suppliers.
- Implement anomaly detection and adversarial robustness tests on supplied models and data to detect tampering and poisoning.
- Implement sufficient monitoring to cover component and environment vulnerabilities scanning, use of unauthorized plugins, and out-of-date components, including the model and its artifacts.
- Implement a patching policy to mitigate vulnerable or outdated components. Ensure the application relies on a maintained version of APIs and the underlying model.
- Regularly review and audit supplier Security and Access, ensuring no changes in their security posture or T&Cs.
- OpenSSF Scorecard can help developers assess the risks associated with each code check-in. It can also help them make informed decisions about accepting the security risks, evaluating alternative solutions, or making improvements.
- Refer to Azure and NIST SP 800-161
- Look up your AI model in the AI Risk Database. Enter the model name or URL in the search bar of the homepage.
Threat #4: Data and Model Poisoning
Principle: Confidentiality, Integrity and Availability
Threat Data poisoning can target different stages of the LLM lifecycle, including pre-training (learning from general data), fine-tuning (adapting models to specific tasks), and embedding (converting text into numerical vectors). It occurs when pre-training, fine-tuning, or embedding data is manipulated to introduce vulnerabilities, backdoors, or biases.
Artificial Intelligence models distributed through shared public repositories or open-source platforms can carry security and safety risks beyond data poisoning, such as malware embedded through techniques like malicious pickling[https://hiddenlayer.com/innovation-hub/pickle-strike/], which can execute harmful code when the model is loaded.
Affected asset(s) Chat Bot Service, Routing Microservice, Conversational Microservice, Azure OpenAI Model, Search API RAG Microservice
Mitigation:
- Implement strong access controls to limit unauthorized access to LLM model hosting platform, code repositories and training environments.
- Restrict the LLMs access to network resources, internal services and APIs.
- Regularly monitor and audit access logs and activities related to LLM model repositories. Monitoring and auditing will help detect and respond to any suspicious activities.
- Automate security of MLOps and DevOps deployment with governance, tracking and approval workflows.
- Track data origin and transformations using ML-BOM tools like OWASP CycloneDX.
- Rate Limit API calls where applicable.
- Use approved algorithms, which include AES-256, AES-192, or AES-128.
- Isolate the network for development and production environments. Use Azure Network Isolation Architecture and isolation modes for AI Foundry and Machine Learning Studio
- Store user-provided information in a vector database, allowing adjustments to that data; possibly through fine-tuning without re-training the entire model.
- Rely on Retrieval-Augmented Generation (RAG) and grounding techniques to reduce risks of hallucinations.
- Refer to frameworks and standards like MITRE ATLAS and OWASP Top 10 for LLM during design phase to influence key solution decisions.
- Look up your AI model in the AI Risk Database. Enter the model name or URL in the search bar of the homepage. List and review te risks within the context of your organization.
- Test model robustness with red team testing using adversarial techniques to assess and minimize the impact of data
Threat #5: Insecure (Improper) Output Handling
Principle: Confidentiality
Threat: Insufficient scrutiny of LLM output, unfiltered acceptance of the LLM output could lead to unintended code execution.
Insecure Output Handling occurs when there is insufficient validation, sanitization, and handling of the LLM outputs, which are passed downstream to other components and systems. Since LLM-generated content can be controlled by prompt input, this behavior is like providing users with indirect access to more functionality.
Affected asset(s) Web application, Non-Search Microservice, Search API RAG Microservice, Conversational Microservice, Browser.
Mitigation:
- Treat the model as any other system/component. Adopt a zero-trust approach. Apply proper input validation on responses coming from the model to backend functions.
- Follow the best practices to ensure effective input validation and sanitization.
- Encode model output back to users to mitigate undesired code execution by JavaScript or Markdown.
- Use Azure AI Content Safety Filters for filtering user prompt inputs and LLM responses.
- Refer to OWASP LLM security security risk guidance for improper output handling
- Use Azure AI Foundry safety and security evaluations to systematically assess and improve your generative AI application before deploying it to production.
Threat #6 : Excessive Agency
Principle: Confidentiality, Integrity, Availability
Threat: An LLM-based system is often granted a degree of ability (agency) to call functions or interface with other systems via extensions (sometimes referred to as tools, skills or plugins by different vendors) to undertake actions in response to a prompt. The decision of which extension to invoke may be delegated to an LLM ‘agent’ to dynamically determine based on input prompt or LLM output. 5. Refer OWASP LLM security risk guidance for improper output handling Affected asset(s) Chat Bot Service, Routing Microservice, Conversational Microservice, Azure OpenAI Model, Search API RAG microservice
Mitigation:
- Reduce the number of extensions to minimum necessary.
- Limit the functions of an extension to only required functionality.
- Do not design or code open-ended extensions.
- Minimize the permissions to the extension.
- Execute extensions with user context for scenarios where target resource access or action has to be authorized based on scope of access configured for authenticated user.
- Implement human-in-the-loop to approve high-impact actions in a downstream system triggered from plugin or agent.
- Use sanitization of inputs to LLM and outputs from LLM.
- Use SAST (Static Application Security Testing) and DAST (Dynamic Application Security Testing) in DevOps pipeline.
- Azure Safety and Security Evaluations using SDK or AI Foundry
Threat #7 : Leakage of System Prompt (also known as Metaprompt)
Principle: Confidentiality, Integrity, Availability
Threat:
An attacker interacts with an LLM in a method that results in discovery of the system prompt that was crafted to steer the behavior of the model. Sometimes the system prompt may contain sensitive information that was not intended to be revealed. As these prompts are used to influence the response from the model for groundedness, safety and security, hence it is important that they are secured from unauthorized access or leakage.
It is important to note that the system prompt should not be considered a secret. The system prompt should also not be used as a security control. Accordingly, sensitive data such as credentials, connection strings, etc. should not be contained within the system prompt language.
For example, the system prompt of the application reveals information on internal decision-making processes of a retail giant chat bot that should be kept confidential. This information allows attackers to gain insights into how the application works, which could allow attackers to exploit weaknesses or bypass controls in the application. A chatbot for the scenario described may have its system prompt reveal information like >”The Transaction limit is set to $500 AUD per day for a authenticated user. The Total Shopping Amount for a user is $1000″. This information allows the attackers to bypass the security controls in the application like doing transactions more than the set limit or bypassing the total amount.
Affected asset(s) Chat Bot Service, Routing Microservice, Conversational Microservice, Azure OpenAI Model, Search API RAG Microservice
Mitigation:
- Separate system prompts and sensitive data by avoiding using user roles, permissions, API keys etc. in the system prompt.
- Implement continuous evaluation of model responses using Azure Evaluations SDK or Azure AI Foundry
- Enforce access control, network security for the solution.
- Use Microsoft Defender for Cloud AI workload threat protection.
Threat #8 : Denial Of Service
Threat:
An attacker interacts with an LLM in a method that consumes an exceptionally large amount of resources. It results in a decline in the quality of service for them and other users. The one being attacked can potentially incur high resource costs. This attack can also be due to vulnerabilities in the supply chain.
Affected asset(s) Chat Bot Service, Routing Microservice, Conversational Microservice, Azure OpenAI GPT Model (GPT 3.5 model in this scenario), Search API RAG Microservice
Mitigation:
- Implement input validation and sanitization to ensure user input adheres to defined limits and filters out any malicious content.
- Cap resource use per request or step, so that requests involving complex parts execute more slowly.
- Enforce API rate limits to restrict the number of requests an individual user or IP address can make within a specific time frame.
- Limit the following counts:
- The number of queued actions.
- The number of total actions in a system reacting to LLM responses.
- Continuously monitor the resource utilization of the LLM to identify abnormal spikes or patterns that may indicate a DoS attack.
- Set strict input limits based on the LLM's context window to prevent overload and resource exhaustion.
- Promote awareness among developers about potential DoS vulnerabilities in LLMs and provide guidelines for secure LLM implementation.
- All services within the Azure Trust Boundary must authenticate all incoming requests, including requests coming from the same network. Proper authorization should also be applied to prevent unnecessary privileges.
- Whenever available, use Azure Managed Identities to authenticate services. Service Principals may be used if Managed Identities are not supported.
- External users or services may use Username + Passwords, Tokens, or Certificates to authenticate, provided these credentials are stored on Azure Key Vault or any other vault solution.
- For authorization, use Azure RBAC and conditional access policies to segregate duties. Grant only the least amount of access to perform an action at a particular scope.
- To maximize your application's uptime, plan ahead to maintain business continuity and prepare for disaster recovery. Azure AI Foundry which is built upon Azure Machine Learning Architecture can be one of the services that can be used in this scenario.
- Plan for a multi-regional deployment of Azure AI Foundry and associated resources.
- Maximize chances to recover logs, notebooks, docker images, and other metadata.
- Design for high availability of your solution.
- Initiate a failover to another region.
- Test resiliency of your application by planning for business continuity and failover testing.
Threat #9 : Over reliance due to misinformation from LLM
Principle: Responsible AI; AI response causing emotional, mental or physical harm to consumer of LLM-generated responses.
Threat: Over reliance can occur when an end user who is the consumer of LLM response trusts LLM produced erroneous response. The LLM usually provides information in an authoritative manner.
Affected asset(s) 17. Test resiliency of your application by planning for business continuity and failover testing.
Mitigation:
- Regularly monitor and review the LLM outputs. Use self-consistency or voting techniques to filter out inconsistent text. Comparing multiple model responses for a single prompt can better judge the quality and consistency of output.
- Cross-check the LLM output with trusted external sources. This extra layer of validation can help ensure the information from LLM-generated responses is not off-topic.
- Enhance the model with fine-tuning or embeddings to improve output quality. Generic pre-trained models are more likely to produce inaccurate information compared to tuned models in a particular domain. Techniques such as prompt engineering, parameter efficient tuning (PET), full model tuning, and chain of thought prompting can be employed for this purpose.
- Implement automatic validation mechanisms that can cross-verify the generated output against known facts or data. This cross-verification can provide an extra layer of security and mitigate the risks associated with hallucinations.
- Break down complex tasks into manageable subtasks and assign them to different agents. This break down not only helps in managing complexity, but it also reduces the chances of hallucinations.
- Communicate the risks and limitations associated with using LLMs. These risks include potential for information inaccuracies. Effective risk communication can prepare users for potential security issues and help them make informed decisions.
- Build APIs and user interfaces that encourage responsible and safe use of LLMs. Use measures such as content filters, user warnings about potential inaccuracies, and clear labeling of AI-generated content.
- When using LLMs in development environments, establish secure coding practices and guidelines to prevent the integration of possible vulnerabilities.
- Educate users so that they understand the implications of using the LLM outputs directly without any validation.
Threat #10: Vector and embeddings weaknesses in retrieval augmented generation (RAG) solutions
Principle: Confidentiality, Integrity and Availability
Threat RAG is a technique to enhance contextual relevance of model responses by grounding its response based on required knowledge sources. It is popular for developing context based AI solutions as it eliminates an LLM system’s expensive retraining or fine-tuning phase. Weaknesses in how vectors and embeddings are generated, stored, or retrieved can be exploited by malicious actions (intentional or unintentional) to inject harmful content, manipulate model outputs, or access sensitive information.
Affected asset(s) Chat Bot Service, Routing Microservice, Conversational Microservice, Azure OpenAI Model, Search API RAG Microservice
Mitigation:
- Implement fine grained access control and permission-aware vector and embeddings storage.
- Restrict the LLMs access to network resources, internal services and APIs.
- Regularly monitor and audit access logs and activities related to LLM model repositories. Monitoring and auditing will help detect and respond to any suspicious activities.
- Automate security of MLOps and DevOps deployment with governance, tracking and approval workflows.
- Validate data pipelines and scan data sources for malware. Microsoft Defender for Cloud can scan data sources for malicious content.
- All customer or confidential data must be encrypted before being written to non-volatile storage media (encrypted at-rest).
- Use approved algorithms, which include AES-256, AES-192, or AES-128.
- Use data discovery and classification to prevent scenarios where sensitive and non-sensitive datasets could be combined accidentally.
- Implement authentication and authorization with the source of data to ensure data is accepted only from trusted and verified sources.
Threat #11: Model Theft
Principle: Confidentiality, Integrity and Availability
Threat Users can modify the system-level prompt restrictions to "jailbreak" the LLM and overwrite previous controls in place.
This threat arises when one of the following actions happens to the proprietary LLM models:
- Compromised.
- Physically stolen.
- Copied.
- Weights and parameters are extracted to create a functional equivalent.
Affected asset(s) Chat Bot Service, Routing Microservice, Conversational Microservice, Azure OpenAI Model, Search API RAG Microservice
Mitigation:
- Implement strong access controls to limit unauthorized access to LLM model hosting platform, code repositories and training environments.
- Restrict the LLMs access to network resources, internal services and APIs.
- Regularly monitor and audit access logs and activities related to LLM model repositories. Monitoring and auditing will help detect and respond to any suspicious activities.
- Automate security of MLOps and DevOps deployment with governance and tracking and approval workflows.
- Rate Limiting API calls where applicable.
- All customer or confidential data must be encrypted before being written to non-volatile storage media (encrypted at-rest).
- Use approved algorithms, which include AES-256, AES-192, or AES-128.
- Use Azure AI Content Safety Service to filter user input prompt and LLM output for malicious content.
Secrets inventory
An ideal architecture would contain zero secrets. Credential-less options like managed identities should be used whenever possible. Where secrets are required, it's important to track them for operational purposes by maintaining a secrets inventory.
| Name | What is it? | Where does it live? | How was it generated? | What's the rotation strategy? | Does it cause downtime? | How does the secret get distributed to consumers? | What’s the secret’s lifespan? |
|---|---|---|---|---|---|---|---|
Appendix
Discretion
AI should be a responsible and trustworthy custodian of any information to which it has access. As humans, we will undoubtedly assign a certain level of trust in our AI relationships. At some point, these agents will talk to other agents or other humans on our behalf.
Designing controls that limit access to data is more important to establish trust in AI. Inline to this thought process, it is also equally important that LLM outputs align with the Microsoft Responsible AI principles.
Resilience
The system should be able to identify abnormal behaviors and prevent manipulation or coercion outside of the normal boundaries of acceptable behavior in relation to the AI system and the specific task. These behaviors are caused by new types of attacks specific to the AI/ML space.
Systems should be designed to resist inputs that would otherwise conflict with local laws, ethics and community values. This means providing AI with the capability to determine when an interaction is going “off script.” Integrity.
Hence, it is important to spruce up the defense mechanisms for the early detection of anomalies. AI-based applications can then fail safely while maintaining Business continuity.
Security principles
- Confidentiality refers to the objective of keeping data private or secret. In practice, it's about controlling access to data to prevent unauthorized disclosure.
- Integrity is about ensuring that data has not been tampered with and, therefore, can be trusted. It is correct, authentic, and reliable.
- Availability means that networks, systems, and applications are up and running. It ensures that authorized users have timely reliable access to resources when they are needed.
- Privacy relates to activities that focus on individual users' rights.
Microsoft Zero Trust Principles
Verify explicitly. Always authenticate and authorize based on all available data points. These data points include user identity, location, device health, service or workload, data classification, and anomalies.
Use least privileged access. Limit user access with just-in-time and just-enough-access (JIT/JEA), risk-based adaptive policies, and data protection to help secure both data and productivity.
Assume breach. Minimize blast radius and segment access. Verify end-to-end encryption. Use analytics to get visibility, drive threat detection, and improve defense.
Microsoft Data Classification Guidelines
| **Classification | Description |
|---|---|
| Sensitive | Data that is to have the most limited access and requires a high degree of integrity. Typically, it is data that will do the most damage to the organization should it be disclosed. Personal data (including PII) falls into this category. Personal data includes any identifier, such as name, identification number, location data, online identifier. It also includes data related to one or more of the following factors specific to the identity of the individual: physical, psychological, genetic, mental, economic, cultural, social. |
| Confidential | Data that might be less restrictive within the company but might cause damage if disclosed. |
| Private | Private data is compartmental data that might not do the company damage. This data must be kept private for other reasons. Human resources data is one example of data that can be classified as private. |
| Proprietary | Proprietary data is data that is disclosed outside the company on a limited. It also includes data that contains information that could reduce the company's competitive advantage, such as the technical specifications of a new product. |
| Public | Public data is the least sensitive data used by the company and would cause the least harm if disclosed. This data could be anything from data used for marketing to the number of employees in the company. |
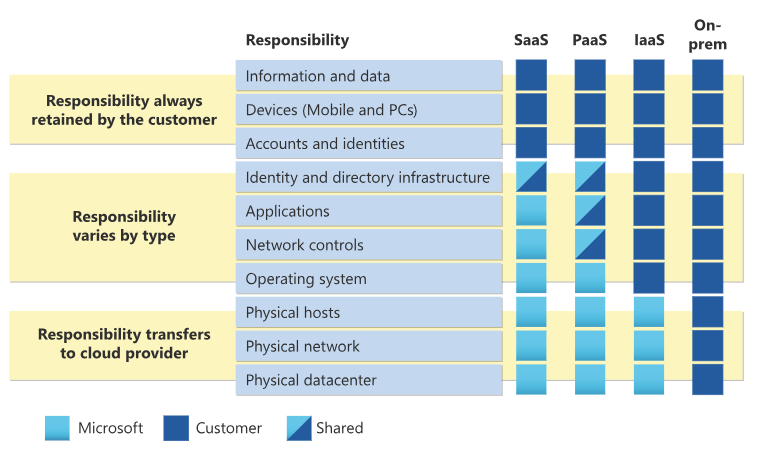
Shared Responsibility Model in the Azure Cloud
For all cloud deployment types, customers own their data and identities. They are responsible for protecting the security of their data and identities, on-premises resources, and the cloud components they control. The customer-controlled cloud components vary by service type.
Regardless of the type of deployment, customer always retains the following responsibilities:
- Data
- Endpoints
- Account
- Access management
For more information
- Moderation - OpenAI API
- Azure AI Content Moderator
- Azure AI Content Safety
- Security Bug Reports
- AI Security Risk Assessment
- Azure AI Security Risk Assessment
- MITRE Adversarial ML Threat Matrix
- OWASP AI Security and Privacy Guide
- Azure ML Prompt Flow
- Deck and Go Dos Responsible AI at Microsoft
- Mitigating Skeleton Key, a new type of generative AI jailbreak technique
- Staying Ahead of threat actors in the age of AI