适用于: SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
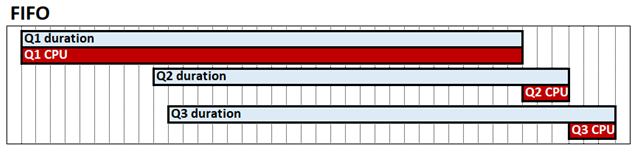
查询交错是一种表格模式系统配置,可在高并发场景中提高查询性能。 默认情况下,Analysis Services 表格引擎在 CPU 方面采用先出先出(FIFO)方式工作。 例如,使用 FIFO 时,如果收到一个资源昂贵且可能速度缓慢的存储引擎的查询,接着是两个相对快速的查询,那么这些快速查询可能会被阻塞,等待昂贵的查询完成。 下图显示了此行为,其中显示了 Q1、Q2 和 Q3 作为相应的查询、它们的持续时间和 CPU 时间。
查询交错与 短查询偏差 允许并发查询共享 CPU 资源,这意味着快速查询不会被慢速查询阻塞。 完成所有三个查询所需的时间仍然大致相同,但在我们的示例中,Q2 和 Q3 直到结束都没有被阻塞。 短查询偏差意味着快速查询,由给定时间点已消耗的 CPU 数定义的快速查询可以分配比长时间运行的查询更高的资源比例。 在下图中,Q2 和 Q3 查询被视为 快速 且分配的 CPU 数超过 Q1。
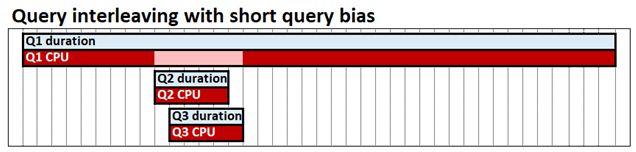
查询交错旨在对隔离运行的查询产生很少或没有性能影响;单个查询仍可以使用与 FIFO 模型一样多的 CPU。
重要注意事项
在确定查询交错是否适合你的方案之前,请记住以下几点:
- 查询交错仅适用于导入模型。 它不会影响 DirectQuery 模型。
- 查询交错技术仅考虑由 VertiPaq 存储引擎查询消耗的 CPU。 它不适用于公式引擎运算。
- 单个 DAX 查询可能会导致多个 VertiPaq 存储引擎查询。 根据存储引擎查询使用的 CPU,DAX 查询被视为 快速 或 缓慢 。 DAX 查询是度量单位。
- 默认情况下,刷新操作受到查询交错的保护。 长时间运行的刷新操作与长时间运行的查询在分类方式上有所不同。
Configure
若要配置查询交错,请设置 Threadpool\SchedulingBehavior 属性。 可以使用以下值指定此属性:
| 价值 | Description |
|---|---|
| -1 | 自动。 引擎将选择队列类型。 |
| 0 (SSAS 2019 的默认值) | 首先,先出(FIFO)。 |
| 1 | 短查询偏向。 当引擎承受压力时,会逐渐限制长时间运行的查询,以优先处理快速查询。 |
| 3(Azure AS、Power BI、SSAS 2022 及更高版本默认值) | 快速取消的短查询偏差。 改进了高并发方案中的用户查询响应时间。 仅适用于 Azure AS、Power BI、SSAS 2022 及更高版本。 |
目前,只能使用 XMLA 设置 ScheduleBehavior 属性。 在 SQL Server Management Studio 中,以下 XMLA 代码片段将 ScheduleBehavior 属性设置为 1,短查询偏差。
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ThreadPool\SchedulingBehavior</Name>
<Value>1</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
重要
需要重启服务器实例。 在 Azure Analysis Services 中,必须暂停并恢复服务器,才能有效地重启。
其他属性
在大多数情况下,ScheduleBehavior 是唯一需要设置的属性。 以下附加属性的默认设置在大多数情况下针对短查询偏差都有效,但如有需要,可进行更改。 除非通过设置 SchedulingBehavior 属性启用查询交错,否则以下属性 不起作用。
ReservedComputeForFastQueries - 设置 快速 查询的保留逻辑核心数。 所有查询都被认为是 快速 的,直到它们腐烂,因为它们已经用完了一定数量的 CPU。 ReservedComputeForFastQueries 是介于 0 和 100 之间的整数。 默认值为 75。
ReservedComputeForFastQueries 的度量单位是核心的百分比。 例如,在具有 20 个核心的服务器上,当服务器参数值为 80 时,尝试为快速查询保留 16 个核心(而不执行刷新操作)。 ReservedComputeForFastQueries 向上舍入到最接近的整数核心数。 建议不要将此属性值设置为低于 50。 这是因为快速查询可能被剥夺,并且与功能的整体设计相反。
DecayIntervalCPUTime - 一个整数,表示查询在衰减之前花费的 CPU 时间(以毫秒为单位)。 如果系统处于 CPU 压力之下,则衰减的查询仅限于未为快速查询保留的剩余核心。 默认值为 60,000。 这表示 1 分钟的 CPU 时间,而不是经过的日历时间。
ReservedComputeForProcessing - 设置每个处理(数据刷新)操作的预留逻辑核心数。 属性值是介于 0 和 100 之间的整数,默认值为 75 表示。 该值表示由 ReservedComputeForFastQueries 属性确定的核心百分比。 值为 0(零)表示处理作受到与查询相同的查询交错逻辑的约束,因此可以衰减。
虽然未执行任何处理作,但 ReservedComputeForProcessing 不起作用。 例如,如果值为 80,则具有 20 个核心的服务器上的 ReservedComputeForFastQueries 为快速查询保留 16 个核心。 如果值为 75,ReservedComputeForProcessing 将保留 16 个核心中的 12 个用于刷新操作,在处理操作运行为 CPU 密集型任务时留出 4 个核心用于快速查询。 如下面的“衰减查询”部分所述,其余 4 个核心(不保留用于快速查询或处理操作)在空闲时仍将用于快速查询和处理。
这些附加属性位于 ResourceGovernance 属性节点下。 在 SQL Server Management Studio 中,以下示例 XMLA 代码片段将 DecayIntervalCPUTime 属性设置为低于默认值的值:
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ResourceGovernance\DecayIntervalCPUTime</Name>
<Value>15000</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
衰减查询
本节中所述的约束仅适用于系统处于 CPU 压力之下时。 例如,如果单个查询是给定时间在系统中运行的唯一一个查询,则可以使用所有可用核心,而不管它是否已衰减。
每个查询可能需要许多存储引擎作业。 当池中用于衰变查询的核心可用时,计划程序将基于经过的日历时间检查最早运行的查询,以查看它是否已用完其 最大核心权利 (MCE)。 如果没有,则执行其下一个作业。 如果是,则会评估下一个最早的查询。 MCE 查询取决于它已经使用的衰减间隔数。 对于使用的每个衰减间隔,MCE 会根据下表中显示的算法减少。 这一过程一直持续到查询完成、超时或 MCE 缩减为单个核心。
在以下示例中,系统有 32 个核心,并且系统的 CPU 面临压力。
ReservedComputeForFastQueries 为 60 (60%)。
- 为快速查询保留 20 个核心(19.2 个舍入)。
- 其余 12 个核心用于处理过时的查询。
DecayIntervalCPUTime 为 60,000 (CPU 时间 1 分钟)。
只要查询未超时或完成,查询的生命周期可能如下所示:
| 阶段 | 状态 | 执行/计划 | MCE |
|---|---|---|---|
| 0 | 快速 | MCE 是 20 个核心(保留用于快速查询)。 查询以 FIFO 方式在 20 个保留核心之间执行其他 快速 查询。 CPU 时间的衰减间隔已用完 1 分钟。 |
20 = MIN(32/2˄0,20) |
| 1 | 腐烂 | MCE 设置为 12 个核心(12 个尚未保留用于快速查询的可用核心)。 作业根据 MCE 的可用性执行。 CPU 时间的衰减间隔已用完 1 分钟。 |
12 = MIN(32/2˄1, 12) |
| 2 | 腐烂 | MCE 设置为 8 个核心(32 个核心总数的四分之一)。 作业根据 MCE 的可用性执行。 CPU 时间的衰减间隔已用完 1 分钟。 |
8 = MIN(32/2^2, 12) |
| 3 | 腐烂 | MCE 设置为 4 个核心。 作业根据 MCE 的可用性执行。 CPU 时间的衰减间隔已用完 1 分钟。 |
4 = MIN(32/2˄3, 12) |
| 4 | 腐烂 | MCE 设置为 2 个核心。 作业根据 MCE 的可用性执行。 CPU 时间的衰减间隔已用完 1 分钟。 |
2 = 最小值(32/2˄4, 12) |
| 5 | 腐烂 | MCE 设置为 1 个处理核。 作业根据 MCE 的可用性执行。 衰减区间不适用,因为查询状态已降至最低点。 由于已达到至少 1 个核心,因此没有进一步衰减。 |
1 = MIN(32/2˄5, 12) |
如果系统处于 CPU 压力之下,将为每个查询分配不超过其 MCE 的核心数。 如果所有核心当前都由各自 MCE 中的查询使用,则其他查询将等到核心可用为止。 当核心可用时,会根据经过的日历时间选取最早的已授权查询。 MCE 是一种受到压力限制的机制;它不保证随时可用的核心数量。