生成 AI 代理并使用 Databricks Apps 进行部署。 Databricks Apps 提供对代理代码、服务器配置和部署工作流的完全控制。 当你需要自定义服务器行为、基于 git 的版本控制或本地 IDE 开发时,此方法是理想的方法。
要求
在工作区中启用 Databricks 应用。 请参阅 设置 Databricks Apps 工作区和开发环境。
步骤 1. 克隆代理应用模板
开始使用 Databricks 应用模板存储库中的预生成代理模板。
本教程使用 agent-openai-agents-sdk 模板,其中包括:
- 使用 OpenAI 代理 SDK 创建的代理
- 适用于代理应用的基础代码,包含会话 REST API 和交互式聊天 UI。
- 使用 MLflow 评估代理的代码
选择以下路径之一以设置模板:
工作区 UI
使用工作区 UI 安装应用模板。 这会安装应用并将其部署到工作区中的计算资源。 然后,可以将应用程序文件同步到本地环境,以便进一步开发。
在 Databricks 工作区中,单击“ + 新建>应用”。
单击 代理>代理 - OpenAI 代理 SDK。
使用名称
openai-agents-template创建新的 MLflow 试验,并完成设置的其余部分以安装模板。创建应用后,单击应用 URL 以打开聊天 UI。
创建应用后,将源代码下载到本地计算机以对其进行自定义:
在“同步文件”下复制第一个命令
在本地终端中,运行复制的命令。
从 GitHub 克隆
若要从本地环境开始,请克隆代理模板存储库并打开 agent-openai-agents-sdk 目录:
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
步骤 2. 了解代理应用程序
代理模板演示了具有这些关键组件的生产就绪体系结构。 打开以下部分,了解有关每个组件的更多详细信息:

打开以下部分,了解有关每个组件的更多详细信息:
MLflow AgentServer
处理具有内置跟踪和可观测性的代理请求的异步 FastAPI 服务器。
AgentServer 提供/invocations用于查询代理的终结点,并自动管理请求路由、日志记录和错误处理。
ResponsesAgent 接口
Databricks 建议使用 MLflow ResponsesAgent 来生成代理。
ResponsesAgent 允许使用任何第三方框架生成代理,然后将其与 Databricks AI 功能集成,实现可靠的日志记录、跟踪、评估、部署和监视功能。

若要了解如何创建ResponsesAgent,请参阅MLflow 文档中的示例 - 用于模型服务的 ResponsesAgent。
ResponsesAgent 提供以下优势:
高级代理功能
- 多代理支持
- 流式处理输出:以较小的区块流式传输输出。
- 全面的工具呼叫消息历史记录:返回多个消息,包括中间工具呼叫消息,以提高质量和聊天管理。
- 工具调用确认支持
- 长期运行工具的支持
简化的开发、部署和监视
-
使用任何框架创作代理:使用
ResponsesAgent接口封装任何现有代理,以便与 AI Playground、代理评估和代理监控实现开箱即用的兼容性。 - 类型化创作接口:使用类型化的 Python 类编写代理代码,受益于 IDE 和笔记本自动完成。
-
自动跟踪:MLflow 自动跟踪你的
predict和predict_stream函数,聚合流式响应,以便更轻松地评估和显示。 -
与 OpenAI
Responses架构兼容:请参阅 OpenAI:响应与 ChatCompletion。
-
使用任何框架创作代理:使用
OpenAI 代理 SDK
该模板使用 OpenAI 代理 SDK 作为聊天管理和工具业务流程的代理框架。 可以使用任何框架开发代理。 关键是使用 MLflow ResponsesAgent 接口对你的代理进行包装。
MCP (模型上下文协议) 服务器
该模板连接到 Databricks MCP 服务器,使代理能够访问工具和数据源。 请参阅 Databricks 上的模型上下文协议(MCP)。
使用 AI 编码助手创作代理
Databricks 建议您使用 AI 编码助手(如 Claude、Cursor 和 Copilot)来编写代理。 使用提供的代理技能,在/.claude/skills中,并使用AGENTS.md文件,来帮助 AI 助手了解项目结构、可用工具和最佳做法。 代理可以自动读取这些文件来开发和部署 Databricks 应用。
高级创作主题
流式响应
流式处理响应
流式处理允许代理以实时区块形式发送响应,而不是等待完整的响应。 要实现ResponsesAgent的流式处理,请依次发出一系列增量事件,最后再发出一个完成事件。
-
发出增量事件:发送多个具有相同的
item_id的output_text.delta事件,以实时流式传输文本区块。 -
通过完成事件结束:发送最终
response.output_item.done事件,其item_id与增量事件相同,包含完整的最终输出文本。
每个 delta 事件将一段文本流式传输到客户端。 最终完成事件包含完整的响应文本,并指示 Databricks 执行以下作:
- 使用 MLflow 跟踪代理的输出
- AI 网关推理表中的聚合流式响应
- 在 AI Playground UI 中显示完整的输出
流式处理错误传播
Mosaic AI 在使用 databricks_output.error 中的最后一个令牌进行流式处理时传递所遇到的任何错误。 由调用客户端来正确处理和显示此错误。
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
自定义输入和输出
自定义输入和输出
某些方案可能需要其他代理输入,例如 client_type ,或 session_id检索源链接等输出,这些源链接不应包含在聊天历史记录中供将来交互使用。
对于这些方案,MLflow ResponsesAgent 原生支持字段 custom_inputs 和 custom_outputs。 上面的框架示例中可以通过 request.custom_inputs 访问自定义输入。
代理评估评审应用不支持为具有其他输入字段的代理呈现跟踪信息。
在 AI实验空间和审核应用中提供custom_inputs
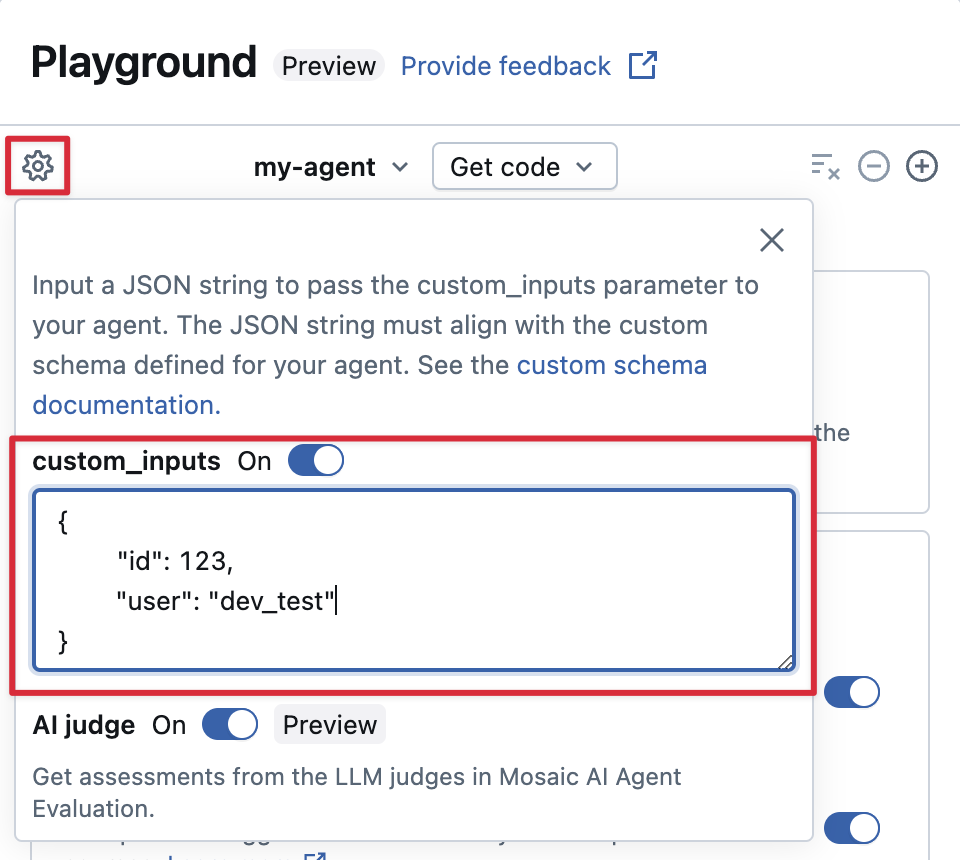
如果代理使用 custom_inputs 字段接受其他输入,则可以在 AI Playground 和 评审应用中手动提供这些输入。
在 AI 操场或代理评审应用中,选择齿轮图标
 。
。启用自定义输入。
提供与代理定义的输入架构匹配的 JSON 对象。
自定义检索器架构
自定义检索器架构
AI 代理通常使用检索器从矢量搜索索引查找和查询非结构化数据。 例如检索器工具,请参阅 将代理连接到非结构化数据。
使用 MLflow RETRIEVER 范围在代理中跟踪这些检索器,以启用 Databricks 产品功能,包括:
- 在 AI Playground UI 中自动显示检索到的源文档的链接
- 在代理评估中自动运行检索有据性和相关性判断
注意
Databricks 建议使用 Databricks AI Bridge 包提供的检索器工具,例如 databricks_langchain.VectorSearchRetrieverTool 和 databricks_openai.VectorSearchRetrieverTool,因为它们已符合 MLflow 检索器架构。 请参阅使用 AI Bridge 在本地开发矢量搜索检索工具。
如果代理包含使用自定义架构的检索器范围,请在代码中定义代理时调用 mlflow.models.set_retriever_schema 。 这会将检索器的输出列映射到 MLflow 的预期字段(primary_key、text_column、doc_uri)。
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is an open-source platform, purpose-built to assist machine learning practitioners...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: A Tool for Managing the Machine Learning Lifecycle'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
注意
在评估检索器的性能时,该 doc_uri 列尤为重要。
doc_uri 是检索器返回的文档的主要标识符,使你可以将它们与地面真相评估集进行比较。 请参阅评估集(MLflow 2)。
步骤 3. 在本地运行代理应用
设置本地环境:
安装
uv(Python 包管理器)、nvm(节点版本管理器)和 Databricks CLI:-
uv安装 -
nvm安装 - 运行以下命令以使用 Node 20 LTS:
nvm use 20 -
databricks CLI安装
-
将目录更改为
agent-openai-agents-sdk文件夹。运行提供的快速入门脚本以安装依赖项、设置环境并启动应用。
uv run quickstart uv run start-app
在浏览器中,转到 http://localhost:8000 开始与代理聊天。
步骤 4. 配置身份验证
代理需要身份验证才能访问 Databricks 资源。 Databricks Apps 提供两种身份验证方法:
应用授权(默认值)
应用授权使用 Azure Databricks 自动为应用创建的服务主体。 所有用户共享相同的权限。
向 MLflow 试验授予权限:
- 单击应用主页上的 “编辑 ”。
- 导航到 “配置” 步骤。
- 在 “应用资源 ”部分中,添加具有
Can Edit权限的 MLflow 试验资源。
对于其他资源 (矢量搜索、Genie 空格、服务终结点),请在 “应用资源 ”部分以相同的方式添加它们。
有关更多详细信息,请参阅 应用授权 。
用户授权
用户授权允许代理处理每个用户的个人权限。 如果需要每个用户的访问控制或审核线索,请使用此功能。
将此代码添加到代理:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside predict or predict_stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
重要:在predict或predict_stream函数中初始化get_user_workspace_client(),而不是在应用启动期间。 仅当处理请求时,用户凭据才存在。
配置范围: 在 Databricks 应用 UI 中添加授权范围,以定义代理可以代表用户访问的 API。
有关完整的设置说明,请参阅 用户授权 。
步骤 5. 评估代理
该模板包括代理评估代码。 有关详细信息,请参阅 agent_server/evaluate_agent.py。 通过在终端中运行以下命令来评估代理响应的相关性和安全性:
uv run agent-evaluate
步骤 6。 将代理部署到 Databricks 应用
配置身份验证后,将代理部署到 Databricks。 确保已安装并配置 Databricks CLI 。
如果在本地克隆了存储库,请在部署该存储库之前创建 Databricks 应用。 如果通过工作区 UI 创建了应用,请跳过此步骤,因为已配置应用和 MLflow 试验。
databricks apps create agent-openai-agents-sdk将本地文件同步到工作区。 请参阅 “部署应用”。
DATABRICKS_USERNAME=$(databricks current-user me | jq -r .userName) databricks sync . "/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk"部署 Databricks 应用。
databricks apps deploy agent-openai-agents-sdk --source-code-path /Workspace/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk
若要将来更新代理,请同步并重新部署代理。
步骤 7. 查询已部署的代理
用户使用 OAuth 令牌查询已部署的代理。 Databricks Apps 不支持个人访问令牌(PAT)。
使用 Databricks CLI 生成 OAuth 令牌:
databricks auth login --host <https://host.databricks.com>
databricks auth token
使用令牌查询代理:
curl -X POST <app-url.databricksapps.com>/invocations \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
局限性
仅支持中型和大型计算大小。 请参阅 配置 Databricks 应用的计算大小。