你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
在使用最先进的模型构建代理和应用时,Azure AI Foundry 操作台提供一个按需无须配置的环境,设计用于在投入生产代码库之前进行快速原型制作、API 探索和技术验证,然后再将一行代码提交到你的生产代码库。
Azure AI Foundry游乐场体验的亮点
Azure AI Foundry实验平台体验的一些亮点包括:
- 代理操场中对评估和跟踪的 AgentOps 支持。
- 适用于聊天和代理操场的“在 VS Code 中打开”功能。 此功能通过自动将终结点和密钥从 Azure AI Foundry 导入 VS Code 来节省时间,以便使用多语言代码示例。
- 适用于 gpt-image-1、Stable Diffusion 3.5 Large 和 Bria 2.3 Fast 模型的图像操场 2.0。
- 音频乐园支持gpt-4o-audio、gpt-4o-transcribe和gpt-4o-mini-tts模型。
- 适用于 Azure OpenAI Sora 的视频操场。

小窍门
在操场登录页面的屏幕截图中,门户的左窗格已被自定义以显示“操场”选项卡。若要了解如何查看左窗格中的其他项目,请参阅自定义左窗格。
作为生产前奏的操场
现代开发涉及在多个系统(API、服务、SDK 和数据模型)之间进行协作,通常是在您准备好完全投入框架、编写测试或启动基础设施之前。 随着软件生态系统的复杂性的增加,需要安全、轻型的环境来验证想法变得至关重要。 场是为了满足这一需求而建造的。
Azure AI Foundry场提供随时可用的环境,并预先安装了所有必要的工具和功能,无需设置项目、管理依赖项或解决兼容性问题。 这些平台可以通过验证 API 行为、更快编写代码、降低试验成本和交付时间、加速集成、优化提示等方式来提升开发人员的开发速度。
游乐场还可以在你有疑问时快速提供清晰的答案,方法是在几秒钟内(而不是几个小时)给予回答,并允许你在承诺进行大规模构建之前测试和验证想法。 例如,操场非常适合快速回答这样的问题:
- 获取所需输出所需的最小提示是什么?
- 在编写完整集成之前,此逻辑是否正常工作?
- 延迟或令牌使用情况如何随不同的配置而变化?
- 在将模型演变为代理之前,哪种模型提供最佳的性价比?
“在 VS Code 中打开”功能
聊天沙盒和代理沙盒允许您在 VS Code 中工作,您可以通过 VS Code 中的 Azure AI Foundry 扩展使用“在 VS Code 中打开”按钮。
在多语言示例代码示例中可用,“在 VS Code 中打开”可自动导入代码示例、API 终结点以及环境中 VS Code 工作区 /azure 的密钥。 借助此功能,可以轻松地从 Azure AI Foundry 门户在 VS Code IDE 中工作。
按照以下步骤使用聊天和代理操场中的“在 VS Code 中打开”功能:
选择“试用聊天操场”将其打开。 或者,可以通过在代理操场卡上选择“开始吧”,在代理操场中执行这些步骤。
如果还没有部署,请选择“ 创建新部署 ”并部署模型,例如
gpt-4o-mini。请确保在“部署”框中选中您的部署。
选择 “查看代码 ”以查看代码示例。
选择“ 在 VS Code 中打开 ”,在浏览器窗口的新选项卡中打开 VS Code。
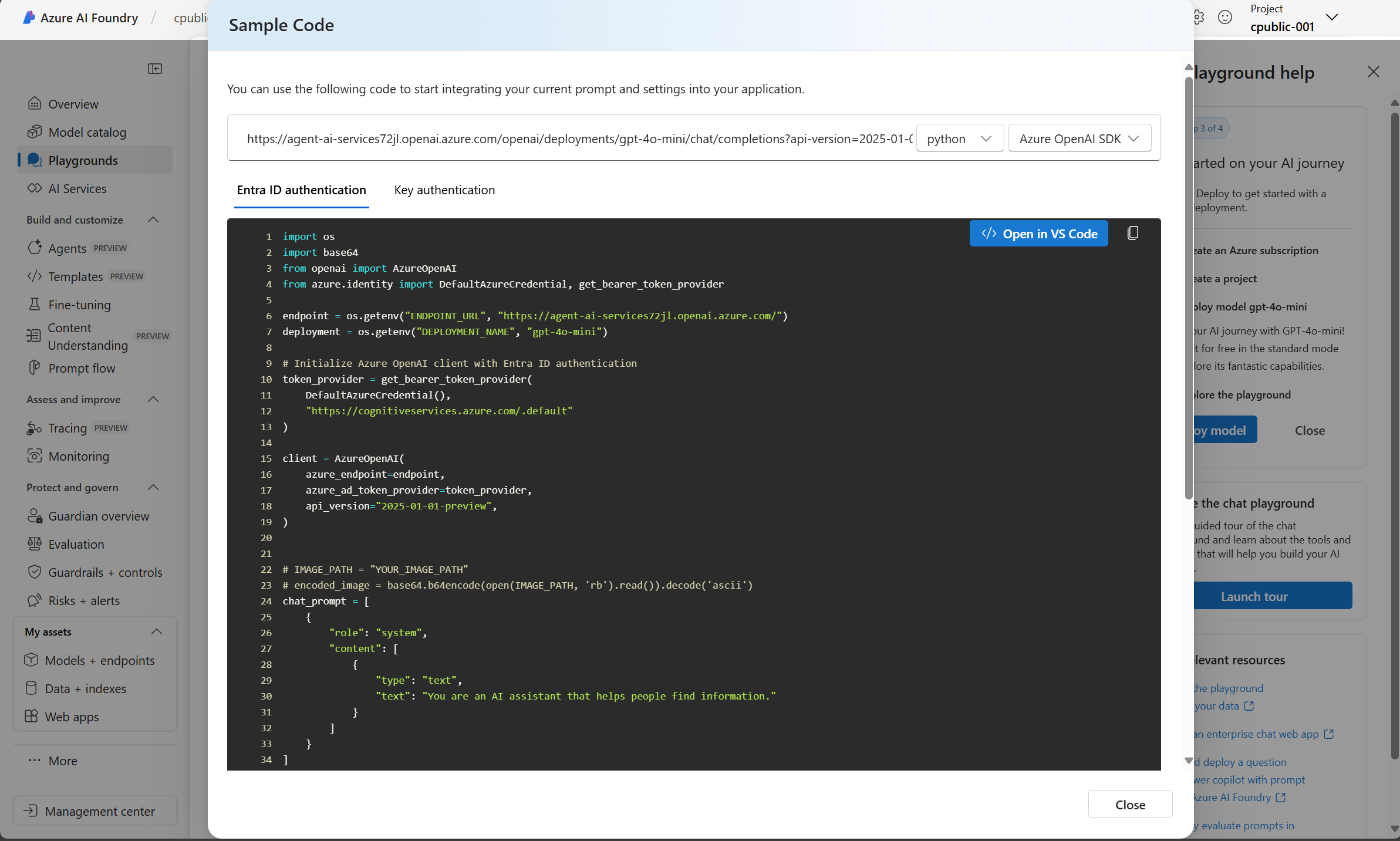
您已被重定向到
/azureVS Code 的环境,在那里代码示例、API 终结点和密钥已从 Azure AI Foundry 实验环境导入。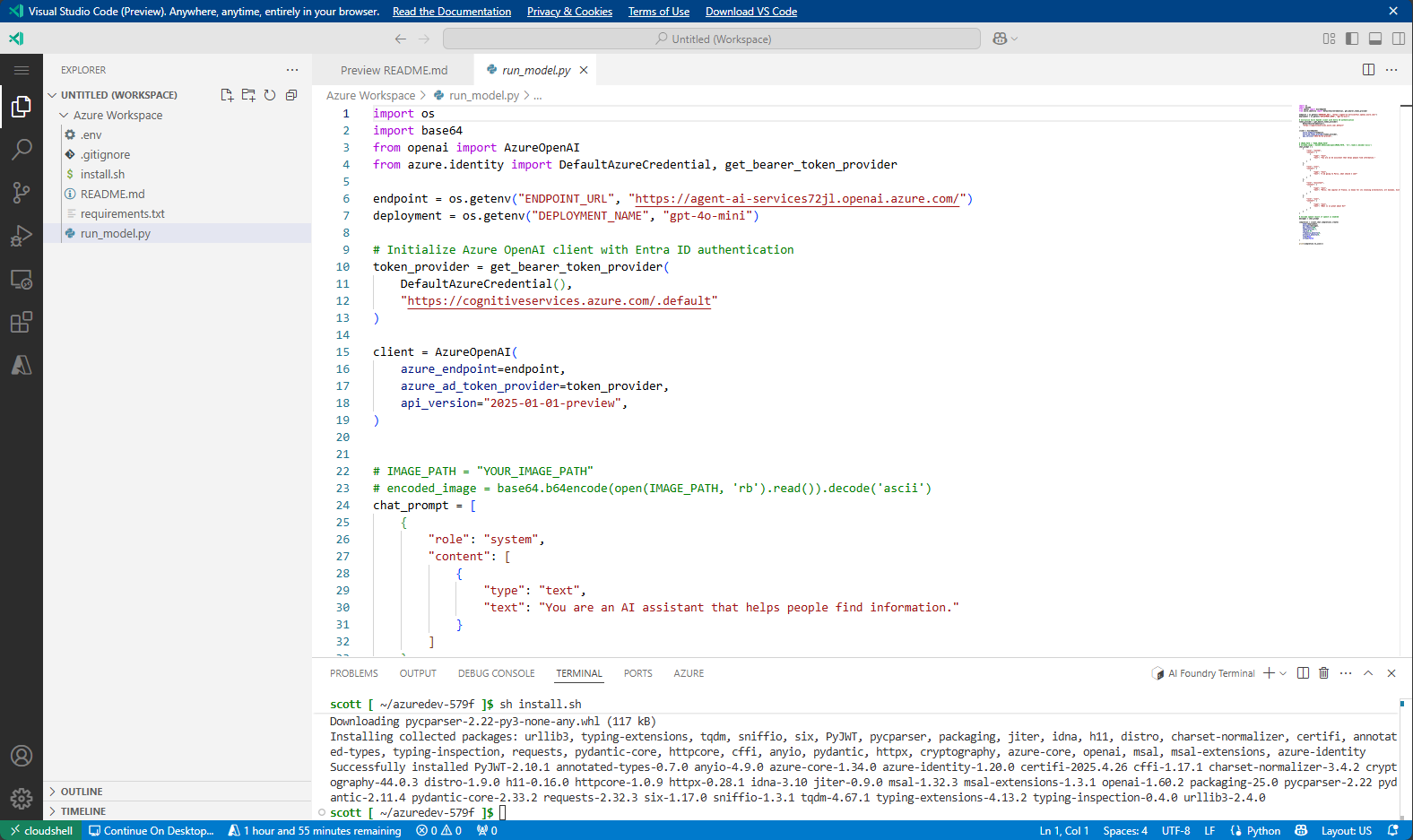
请浏览
READ.ME文件以获取运行模型的说明。在
run_model.py中查看代码示例。查看文件中的相关依赖项
requirements.txt。


代理人的乐园
使用代理场可以浏览、原型和测试代理,而无需运行任何代码。 在此页中,可以快速迭代并试验新的想法。 若要开始使用代理操作区,请参阅 快速入门:创建新的代理。

聊天操场
聊天场是测试 Azure OpenAI、DeepSeek 和 Meta 的最新推理模型的位置。 若要了解有关聊天场的详细信息,请参阅 快速入门:在 Azure AI Foundry 门户中使用聊天场。
对于所有推理模型,聊天场提供了一个思想链摘要下拉列表,使你能够查看模型在共享输出之前如何思考其响应。

音频乐园
音频场(预览版)允许将文本转语音和听录功能与 Azure OpenAI 中的最新音频模型配合使用。
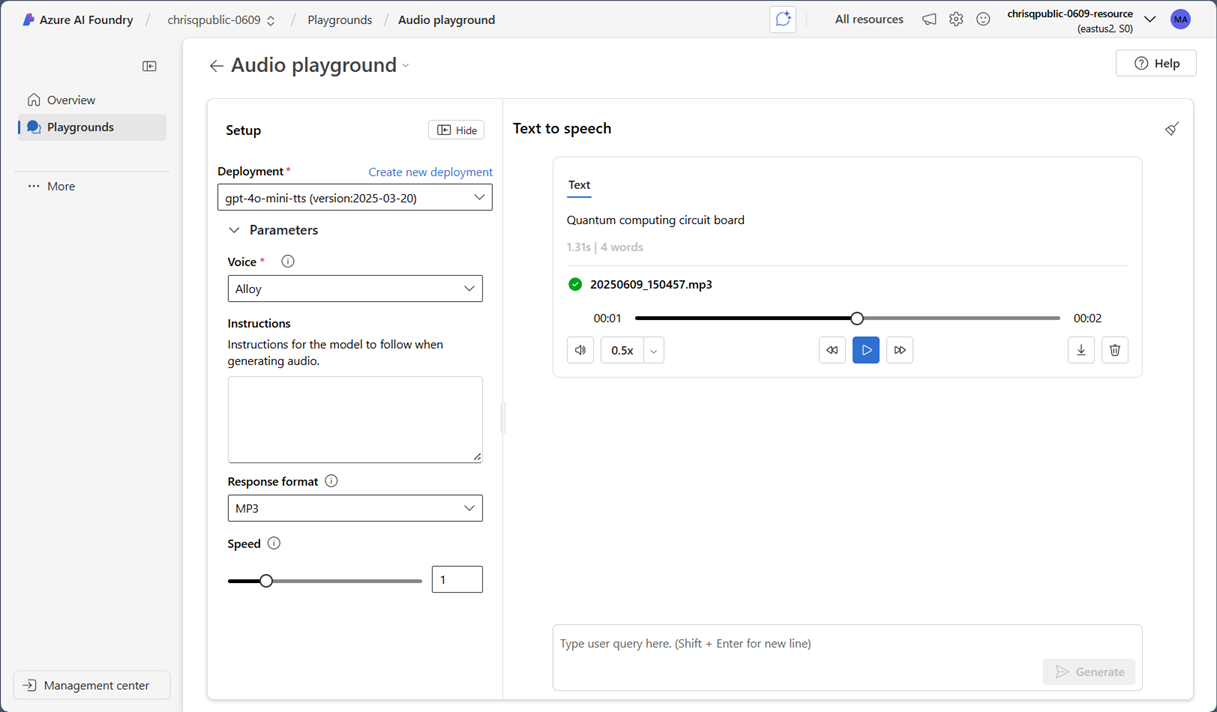
按照以下步骤尝试文本转语音功能:
选择 试用音频试验场 来打开它。
如果还没有部署,请选择“ 创建新部署 ”并部署模型,例如
gpt-4o-mini-tts。确保在“部署”框中选择您的部署项目。
输入文本提示。
调整模型参数,如语音和响应格式。
选择“ 生成 ”以接收包含播放、回退、向前、调整速度和音量的播放控件的语音输出。
将音频文件下载到本地计算机。

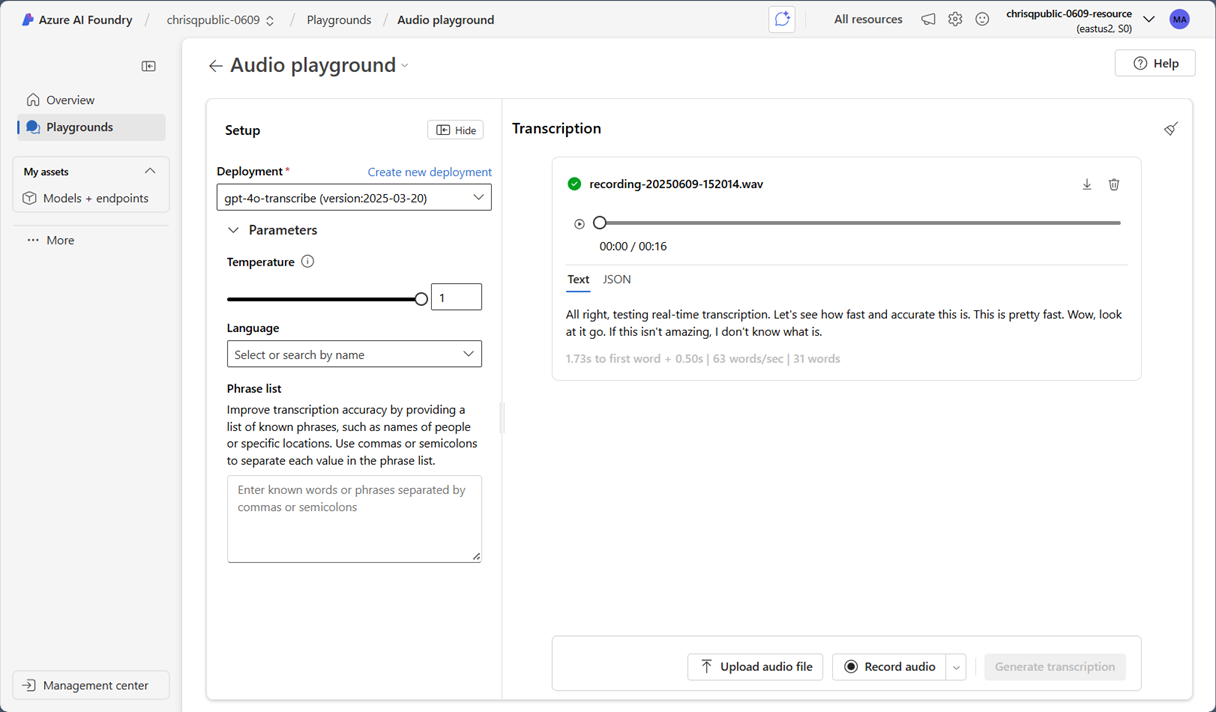
按照以下步骤尝试听录功能:
如果还没有部署,请选择“ 创建新部署 ”并部署模型,例如
gpt-4o-transcribe。(可选)将短语列表作为文本机制包含在一起,以指导音频输入。
通过上传一个音频文件或从提示栏中录制音频来输入音频文件。
选择 “生成听录 ”以将音频输入发送到模型,并接收文本和 JSON 格式的转录输出。

视频游乐场
视频游乐场(预览版)是一个快速迭代的环境,旨在探索、优化和验证生成视频工作流,专为需要将想法转化为具有精确控制和速度的原型的开发人员设计。 该操场提供了一个低摩擦接口,用于测试提示结构、评估运动精准度、跨帧评估模型一致性,以及跨模型比较输出,而无需编写模板代码或浪费计算周期。 这也是首席产品官和工程副总裁的出色演示界面。
所有模型终结点都与 Azure AI 内容安全集成。 因此,在视频平台上展示之前,会筛选掉有害和不安全的图像。 如果文本提示和视频生成由内容审查策略标记,则会收到警告通知。
可以使用视频互动区与 Azure OpenAI Sora 模型配合。
小窍门
请参阅 Azure OpenAI Sora 视频操场 60 秒短视频和 DevBlog,了解如何转换企业就绪用例(按行业)。
按照以下步骤使用视频游乐场:
谨慎
由于数据隐私,生成的视频将保留 24 小时。 将视频下载到本地计算机以延长保留期。
选择“试用视频操场”将其打开。
如果还没有部署,请从主页右上角选择“ 立即部署 ”并部署
sora模型。在视频操场的主页上,受到按“行业”筛选整理的预建提示的启发。 在此处,你可以全屏观看视频,并复制提示以据此构建。
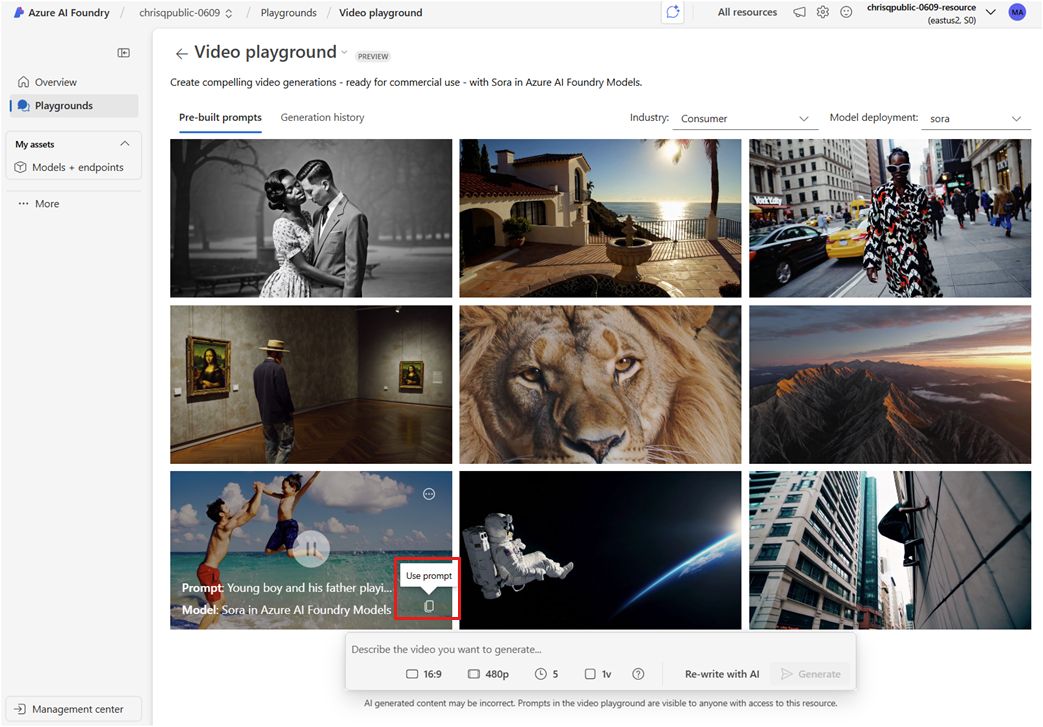
复制提示会将它粘贴到提示栏中。 调整关键控件(例如纵横比或分辨率),以深入了解特定的模型响应能力和约束。
选择“ 生成 ”以基于复制的提示生成视频。
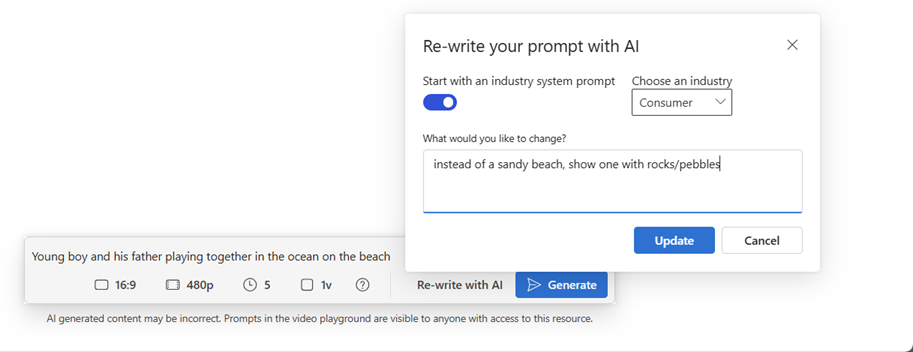
通过“使用 AI 改写”功能,用 gpt-4o 改写文本提示语法。
打开“ 开始使用行业系统提示 ”功能,选择行业,并指定原始提示所需的更改。
选择 “更新 ”以更新提示,然后选择“ 生成 ”以创建新视频。
转到“生成历史记录”选项卡,以网格或列表视图的形式查看生成。 选择视频时,请以全屏模式打开它们以完全沉浸。 直观地观察提示调整或参数更改前后的输出。
在全屏模式下,编辑提示并提交以重新生成。
在全屏模式下或通过悬停在视频上时显示的选项按钮,将视频下载到本地计算机、查看视频生成信息标记、查看代码或删除视频。
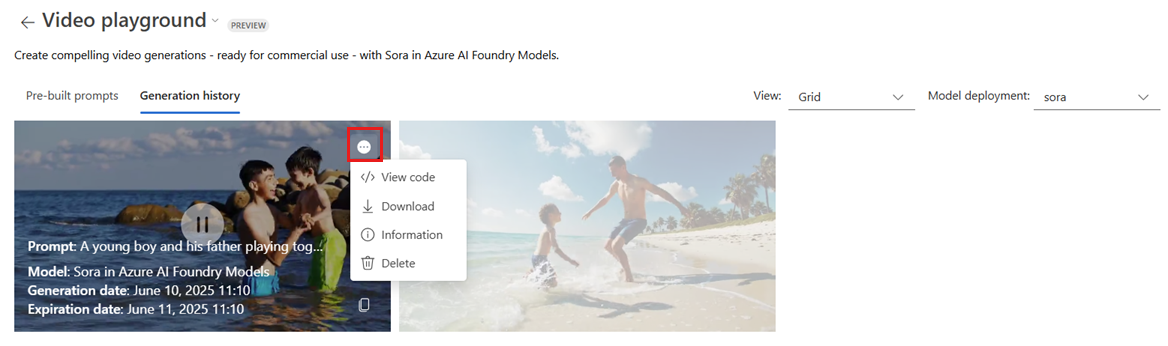
从选项菜单中选择“ 查看代码 ”,以多种语言查看视频代系的上下文示例代码,包括 Python、JavaScript、C#、JSON、Curl 和 Go。
通过将代码示例复制到 VS Code,将代码示例移植到生产环境。



在视频游乐场中进行试验时需要验证的内容
如果在计划生产工作负载时使用视频操场,可以探索并验证以下属性:
提示到运动的转换
- 视频模型是否以逻辑和时态意义的方式解释我的提示?
- 动作是否与描述的行动或场景一致?
帧一致性
- 字符、对象和样式是否在帧之间保持一致?
- 是否存在视觉伪影、抖动或不自然的切换?
场景控件
- 我如何控制场景构图、主体行为或相机角度?
- 是否可以控制场景转换或背景环境?
长度和计时
- 不同的提示结构如何影响视频长度和节奏?
- 视频感觉太快、太慢还是太短?
多模式输入集成
- 提供引用图像、姿势数据或音频输入时会发生什么情况?
- 是否可以生成与给定画外音口型同步的视频?
处理后需求
- 在需要编辑工具之前,我可以期望哪种级别的原始保真度?
- 在投入生产使用视频之前,是否需要对其进行升级、稳定或润色?
延迟和性能
- 为不同的提示类型或分辨率生成视频需要多长时间?
- 生成 5 秒与生成 15 秒剪辑的成本效益权衡是什么?
图像操场
图像操场非常适合那些构建图像生成流程的开发人员。 此实验平台是一个功能齐全的受控环境,旨在开展高保真试验,并专为特定模型的 API 生成和编辑图像而设计。
小窍门
请参阅 gpt-image-1 图像操场 60 秒短视频和我们的 DevBlog,以了解如何转换企业就绪用例(按行业)
可以将图像操场用于以下模型:
- 来自 Azure OpenAI 的 gpt-image-1。
- 来自 Stability AI 的 Stable Diffusion 3.5 Large、Stable Image Core、Stable Image Ultra。
- 来自 Bria AI 的 Bria 2.3 Fast。
按照以下步骤使用图像操场:
- 选择 “试用图像游乐场” 以打开它。
- 如果还没有部署,请选择“ 创建新部署 ”并部署模型,例如
gpt-image-1。 - 从预生成的文本提示开始:选择一个选项以开始使用自动填充提示栏的预生成文本提示。
- 在模型部署后浏览模型 API 特定的生成控件: 调整关键控件(例如变体数、质量、强度),以深刻理解特定的模型响应能力和约束。
- 网格视图中的并排观察:以直观方式观察提示调整或参数更改前后的输出。
- 使用 API 工具进行转换:使用文本转换进行图像修复可用于 gpt-image-1。 使用图像修复选择来更改原始图像的各个部分。 使用文本提示指定更改。
- 使用多语言代码示例移植到生产: 通过“查看代码”使用 Python、Java、JavaScript、C# 代码示例。 图像沙盒是您在 VS Code 中进行开发工作的起点。
在图像操场中进行试验时要验证的内容
通过使用图像沙盒,可以在计划生产工作负荷时浏览并验证以下内容:
提示有效性
- 此提示为企业用例生成哪种类型的视觉输出?
- 我的语言可以有多具体或抽象,从而取得好的结果?
- 模型是否准确理解“超现实主义”或“网络朋克”等样式引用?
风格一致性
- 如何在多个图像中维护相同的字符、样式或主题?
- 是否可以使用最小偏移循环访问同一基本提示的变体?
参数优化
- 更改模型参数(例如指导因子、种子、步数等)会带来什么影响?
- 如何平衡创造力与提示保真度?
模型比较
- 结果在模型之间有何差异(例如,SDXL 与 DALL?E)?
- 哪个模型在处理现实人脸与艺术创作时表现更好?
合成控件
- 如果使用空间约束(如边界框或修补蒙版),将会发生什么情况?
- 能否引导模型走向特定布局或焦点?
输入变体
- 提示措辞或结构中的细微变化如何影响结果?
- 提示对称性、特定相机角度或情感的最佳方法是什么?
集成就绪情况
- 此图像是否满足产品 UI 的约束(纵横比、分辨率、内容安全)?
- 输出是否符合品牌准则或客户期望?