你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
若要全面评估生成式 AI 模型和应用程序应用于大量数据集时的性能,可启动评估过程。 此评估过程使用给定数据集测试模型或应用程序,并且使用基于数学的指标和 AI 辅助式指标来量化衡量其性能。 此评估运行提供对应用程序功能和限制的全面见解。
若要进行此评估,可以利用 Azure AI Foundry 门户中的评估功能,这是一个全面的平台,提供用于评估生成式 AI 模型性能和安全性的工具和功能。 在 Azure AI Foundry 门户中,可以记录、查看和分析详细的评估指标。
本文介绍如何使用 Azure AI Foundry UI 中的内置评估指标针对模型或测试数据集创建评估运行。 为了提高灵活性,可以建立自定义评估流,并使用自定义评估功能。 或者,如果你的目标只是执行批处理运行而不进行任何评估,也可以利用自定义评估功能。
先决条件
若要使用 AI 辅助指标运行评估,需要准备好以下各项:
- 以下格式之一的测试数据集:
csv或jsonl。 - Azure OpenAI 连接。 以下其中一种模型的部署:GPT 3.5 模型、GPT 4 模型或 Davinci 模型。 仅在运行 AI 辅助质量评估时需要。
使用内置评估指标创建评估
通过评估运行,可以生成测试数据集中每个数据行的指标输出。 可以选择一个或多个评估指标来评估不同方面的输出。 可以从 Azure AI Foundry 门户中的评估或模型目录页面创建评估运行。 然后,将显示评估创建向导,指导你完成设置评估运行的过程。
从评估页
在可折叠的左侧菜单中,选择“评估”>“+ 新建评估”。

从模型目录页
从可折叠的左侧菜单中,选择“模型目录”> 转到特定模型 > 导航到基准选项卡 >“尝试使用自己的数据”。 此时模型评估面板将打开,供你创建针对所选模型运行的评估过程。

评估目标
从评估页开始评估时,需要先确定评估目标是什么。 通过指定适当的评估目标,我们可以根据应用的特定性质定制评估,确保指标的准确性和相关性。 我们支持两种类型的评估目标:
- 微调模型:你想要评估所选模型和用户定义的提示生成的输出。
- 数据集:模型已在测试数据集中生成输出。

配置测试数据
输入评估创建向导时,可以从预先存在的数据集中进行选择,也可以上传专门评估的新数据集。 测试数据集需要生成用于评估的模型输出。 测试数据的预览将显示在右窗格中。
选择现有数据集:可以从已建立的数据集集合中选择测试数据集。
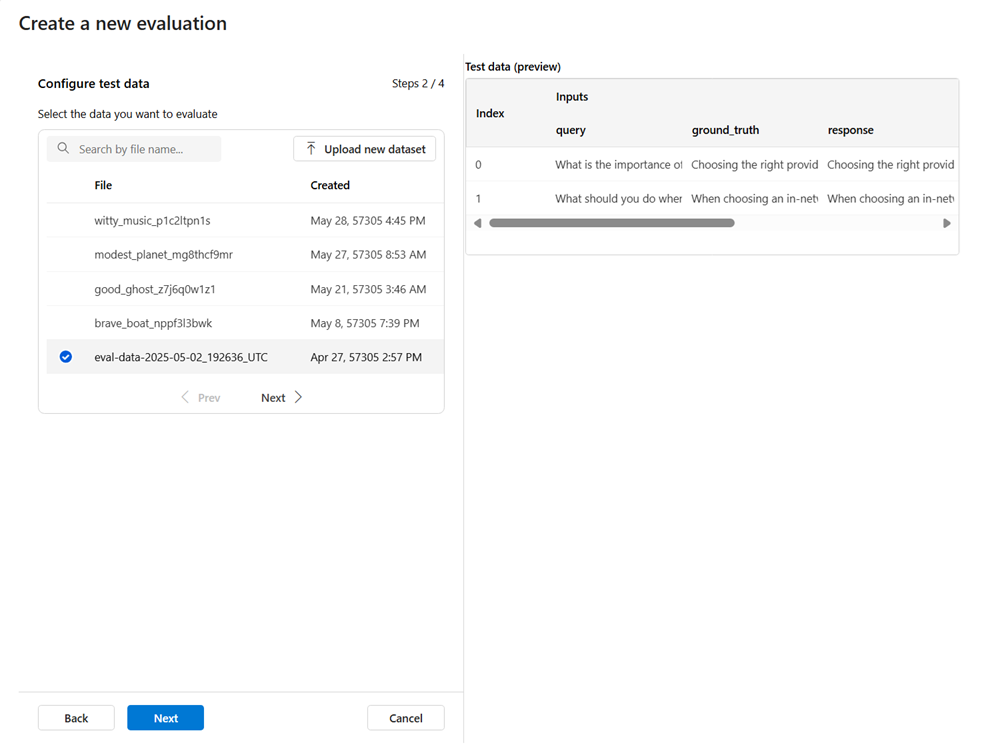
添加新数据集:可以从本地存储上传文件。 我们仅支持
.csv和.jsonl文件格式。 测试数据的预览将显示在右窗格中。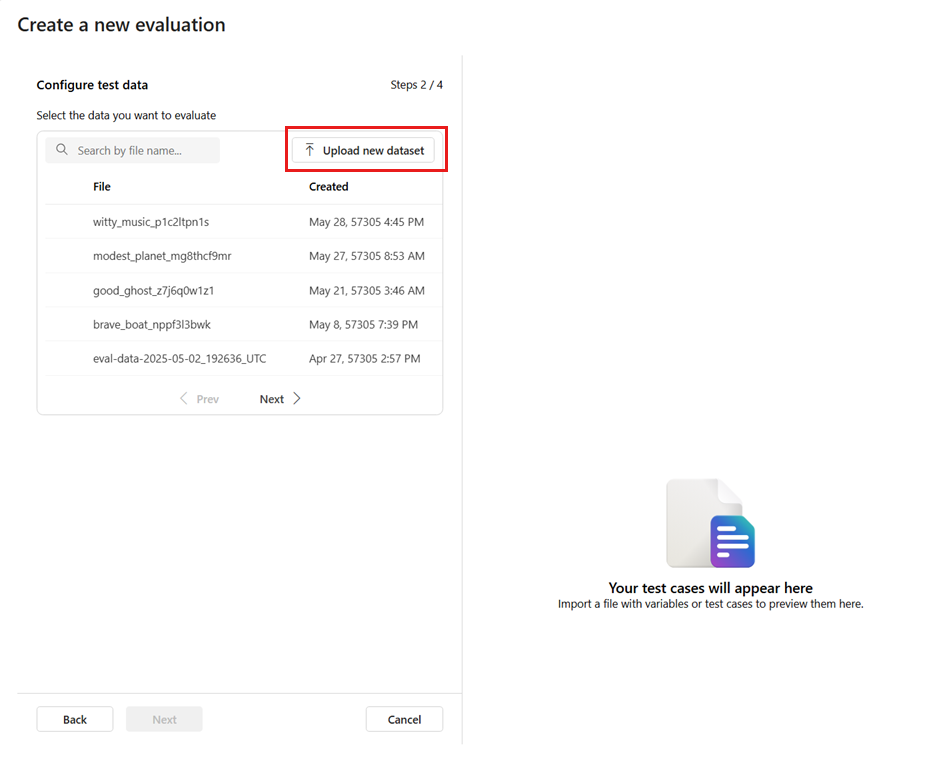


配置测试条件
我们支持 Microsoft 特选的三种指标,以便于你全面评估应用程序:
- AI 质量(AI 辅助):这些指标评估所生成内容的整体质量和连贯性。 若要运行这些指标,需要部署模型作为裁判。
- AI 质量 (NLP):这些 NLP 指标基于数学,同样评估所生成内容的整体质量。 它们通常需要真实数据,但不需要部署模型作为裁判。
- 风险和安全指标:这些指标侧重于识别潜在的内容风险,并确保所生成内容的安全性。

添加测试条件时,将使用不同的指标作为评估的一部分。 可以参考下表,以获取每种场景中支持的指标的完整列表。 有关每个指标定义及其计算方式的详细信息,请参阅 什么是计算器?。
| AI 质量(AI 辅助) | AI 质量 (NLP) | 风险和安全指标 |
|---|---|---|
| 有据性、相关性、连贯性、流畅性、GPT 相似性 | F1 分数,ROUGE,分数,BLEU 分数,GLEU 分数,METEOR 分数 | 自我伤害相关内容、仇恨和不公平内容、暴力内容、性内容、受保护材料、间接攻击 |
运行 AI 辅助质量评估时,必须为计算/评分过程指定 GPT 模型。

AI 质量 (NLP) 指标是基于数学的度量值,用于评估应用程序的性能。 它们通常需要真实数据来进行计算。 ROUGE 是一系列指标。 你可以选择 ROUGE 类型来计算分数。 各种类型的 ROUGE 指标提供多种方式来评估所生成文本的质量。 ROUGE-N 度量所生成文本与参考文本之间 n 元语法的重叠程度。

对于风险和安全指标,无需提供部署。 Azure AI Foundry 门户安全评估后端服务已预配 GPT-4 模型,该模型可生成内容风险严重性分数和推理,使你能够评估应用程序的内容危害。

注释
AI 辅助风险和安全指标由 Azure AI Foundry 安全评估后端服务托管,仅在以下区域提供:美国东部 2、法国中部、英国南部、瑞典中部
谨慎
已加入 Foundry 开发者平台的 Azure OpenAI 用户可享受的向后兼容性:
以前使用 oai.azure.com 管理其模型部署和运行评估的用户,并已载入 Foundry 开发人员平台(FDP)后,使用 ai.azure.com 时将存在一些限制:
首先,用户将无法查看使用 Azure OpenAI API 创建的评估。 相反,若要查看这些内容,用户必须导航回 oai.azure.com。
其次,用户将无法使用 Azure OpenAI API 在 AI Foundry 中运行评估。 相反,这些用户应继续使用 oai.azure.com。 但是,用户可以使用数据集评估创建选项中直接在 AI Foundry(ai.azure.com)中提供的 Azure OpenAI 计算器。 如果部署是从 Azure OpenAI 迁移到 Azure Foundry,则不支持微调模型评估选项。
对于数据集上传 + 自带存储方案,需要满足一些配置要求:
- 帐户身份验证必须是 Entra ID。
- 需要将存储添加到帐户(如果已将其添加到项目中,则会收到服务错误)。
- 用户需要在 Azure 门户中通过访问控制将其项目添加到其存储帐户。
若要详细了解如何在 Azure OpenAI 中心专门使用 OpenAI 评估评分员创建评估,请参阅 如何在 Azure AI Foundry 模型评估中使用 Azure OpenAI
数据映射
评估的数据映射:对于添加的每个指标,必须指定数据集中的数据列与评估中所需的输入相对应。 不同的评估指标需要不同类型的数据输入,以进行准确的计算。
在评估期间,根据关键输入评估模型响应,例如:
- 查询:所有指标都需要
- 上下文:可选
- 真实数据:可选,AI 质量 (NLP) 指标需要
这些映射可确保数据完全符合评估条件。

有关每个指标的特定数据映射要求的指导,请参阅表中提供的信息:
查询和响应指标要求
| 指标 | 查询 | 响应 | 上下文 | 基本事实 |
|---|---|---|---|---|
| 真实性 | 必需:Str | 必需:Str | 必需:Str | 无 |
| 一致性 | 必需:Str | 必需:Str | 无 | 无 |
| 流畅度 | 必需:Str | 必需:Str | 无 | 无 |
| 相关性 | 必需:Str | 必需:Str | 必需:Str | 无 |
| GPT 相似性 | 必需:Str | 必需:Str | 无 | 必需:Str |
| F1 分数 | 无 | 必需:Str | 无 | 必需:Str |
| BLEU 分数 | 无 | 必需:Str | 无 | 必需:Str |
| GLEU 分数 | 无 | 必需:Str | 无 | 必需:Str |
| METEOR 分数 | 无 | 必需:Str | 无 | 必需:Str |
| ROUGE 分数 | 无 | 必需:Str | 无 | 必需:Str |
| 自我伤害相关内容 | 必需:Str | 必需:Str | 无 | 无 |
| 仇恨和不公平内容 | 必需:Str | 必需:Str | 无 | 无 |
| 暴力内容 | 必需:Str | 必需:Str | 无 | 无 |
| 性内容 | 必需:Str | 必需:Str | 无 | 无 |
| 受保护的材料 | 必需:Str | 必需:Str | 无 | 无 |
| 间接攻击 | 必需:Str | 必需:Str | 无 | 无 |
- 查询:查找特定信息的查询。
- 响应:模型针对查询生成的响应。
- 上下文:生成响应所依据的源(即真实文档)。
- 真实数据:用户/人类针对查询以真实答案提供的响应。
查看并完成
完成所有必需的配置后,可以为评估提供可选名称。 然后,可以查看并选择“提交”来提交评估运行。

微调模型评估
若要为所选模型部署创建新的评估,可以使用 GPT 模型生成示例问题,也可以从已建立的数据集集合中进行选择。

为微调模型配置测试数据
设置用于评估的测试数据集。 此数据集将发送到模型以生成评估响应。 有两个选项可用于配置测试数据:
- 生成示例问题
- 使用现有数据集(或上传新数据集)
生成示例问题
如果没有现成可用的数据集,并且想要使用小型示例运行评估,请选择要基于所选主题评估的模型部署。 我们支持 Azure OpenAI 模型和其他与标准部署兼容的开放模型,例如 Meta LIama 和 Phi-3 系列模型。 主题可帮助你根据感兴趣的领域定制生成的内容。 查询和响应是实时生成的,可以选择根据需要重新生成它们。

使用数据集
还可以从已建立的数据集集合中进行选择,或上传新数据集。

选择评估指标
之后,您可以点击“下一步”来配置测试标准。 在选择条件时,会添加指标,并且您需要将数据集的列映射到评估所需的字段。 这些映射可确保数据完全符合评估条件。 选择所需的测试条件后,可以查看评估,可以选择更改评估的名称,然后选择 “提交 ”以提交评估运行并转到评估页以查看结果。

注释
创建评估运行后,生成的数据集将保存到项目的 Blob 存储。
查看和管理评估器库中的评估器
评估器库是一个中心位置,在其中可以查看评估器的详细信息和状态。 你可以查看和管理 Microsoft 特选的评估器。
评估器库还会启用版本管理。 你可以比较不同的工作版本,根据需要还原以前的版本,并更轻松地与他人协作。
若要在 Azure AI Foundry 门户中使用评估器库,请转到项目的“评估”页面并选择“评估器库”选项卡。

可以选择评估器名称以查看更多详细信息。 可以查看名称、说明和参数,并检查与评估器关联的任何文件。 下面是 Microsoft 特选评估器的一些示例:
- 对于 Microsoft 特选的性能和质量评估器,可以在详细信息页面上查看注释提示。 可以通过根据 Azure AI 评估 SDK 中的数据和目标更改参数或条件,将这些提示适应自己的用例。 例如,可以选择“Groundedness-Evaluator”,并查看展示如何计算指标的 Prompty 文件。
- 对于 Microsoft 特选的风险和安全性评估器,可以查看指标的定义。 例如,可以选择“Self-Harm-Related-Content-Evaluator”,并了解其含义以及 Microsoft 如何确定此安全性指标的各种严重性级别。
相关内容
详细了解如何评估生成式 AI 应用程序: